







1. Introduction
Sentiment analysis is an important task in the field of natural language processing, which has important application value in public opinion analysis and social policy making.
As a social platform with a large number of users in China, Weibo has a large amount of user- generated data, which provides a large number of resources for sentiment analysis. As a hot topic, fertility rate has received high attention from the public, and sentiment analysis technology has certain social value to deal with it. At present, there are relatively few researches on similar topics in China.
In China, under the influence of economy, society, policy and other aspects, the fertility rate is gradually declining, which leads to the increasingly serious problem of population aging.
The following figure (Figure 1) is to draw a line statistical chart using python drawing toolkit. The picture shows that China's fertility rate has been declining from 17 to 21 years. This study aims to use sentiment analysis technology based on GNN-LSTM to explore the emotional tendency of netizens on fertility issues by relying on Weibo, a social platform with a large number of users.
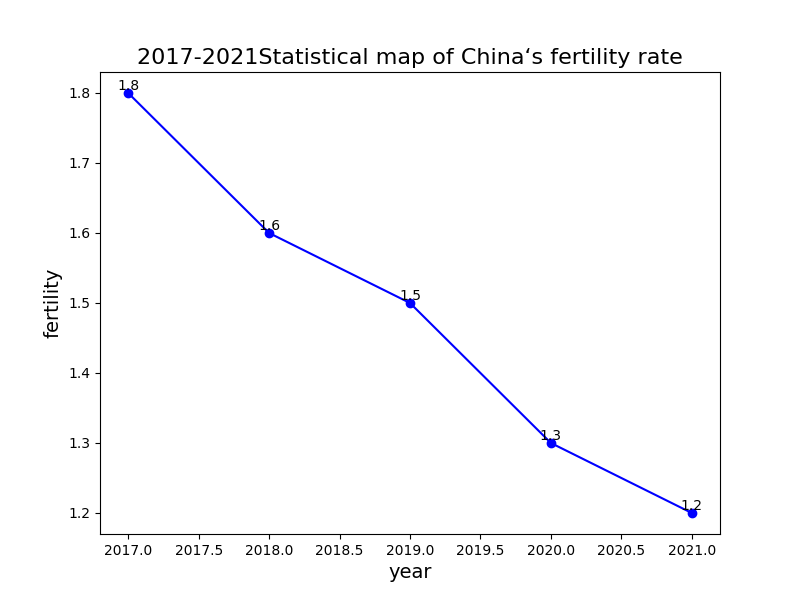
Figure 1. Line statistical chart of fertility rate change from 2017 to 2021
(self-drawn by the author)
Through sentiment analysis of microblog comments, the public's attitude and emotional tendency towards the national fertility issue can be understood. This will provide a useful reference for the government and policy makers to better understand public views and needs, so as to formulate policies and intervention measures that are more in line with public expectations. At the same time, studying the emotional tendency of microblog comments is helpful to analyze public opinion, understand the emotional reaction of the public to the national fertility issue, predict and evaluate the trend of social opinion, help relevant departments to respond to and guide the public opinion in time, and promote the progress and development of society.
2. Survey of research status
Sentiment analysis is an important research direction in the field of natural language processing, which aims to automatically identify the sentiment orientation of text, including positive, negative or neutral, through computer technology. Sentiment analysis has a wide range of applications in social media, public opinion monitoring, marketing and other fields. In recent years, the development of deep learning technology has brought new breakthroughs to sentiment analysis, and the model based on Bidirectional Long Short-Term Memory (BiLSTM) has performed well in sentiment analysis.
Graves first proposed BiLSTM in 2005, which combines Long Short-Term memory (LSTM) with Bidirectional recurrent neural Network (BRNN) to form a model that can better deal with gradient vanishing and explosion problems. Compared with the traditional BRNN, BiLSTM has better memory ability and representation ability, and can better capture the context information in the text, so it has achieved good results in sentiment analysis tasks.
With the development of time, researchers have improved and enriched the BiLSTM model to improve the performance of sentiment analysis. For example, G. Xu et al. input weighted word vectors into BiLSTM, which effectively capture the context information of the text, thus improving the accuracy, recall, and F1 score of sentiment analysis. [1] These improvements make the BiLSTM model one of the important tools in the field of sentiment analysis.
In recent studies, researchers have further explored the deep BiLSTM model to better extract and represent text features. Wenling Li uses the TextCNN model and the BiLSTM model to process comment data in parallel, and fuses the classification results of the two models through the improved Adaboost algorithm to improve the classification accuracy. [2] Li,H. et al. and Meng Bin combined multiple models such as BERT, BiLSTM and CNN, and achieved higher performance results than traditional sentiment analysis models, realizing the sentiment analysis of microblog text. [3,4]
In recent research, a sentiment classification model based on Graph Neural Network (GNN), GNN-LSTM, has also attracted wide attention. Li,Y. et al. developed the GNN-LSTM model and achieved excellent performance in the microblog comment dataset, with an accuracy of 95.25% and an F1 score of 95.22%. [5] This study shows that the GNN-LSTM model has great potential in sentiment analysis and brings a new breakthrough in the field of sentiment analysis.
In addition, some researchers have explored ways to combine different models to improve the performance of sentiment analysis. Wang, Z. et al. adopted the method of combining Word2vec with network and TextCNN model to realize text sentiment classification of microblog comments, which provides more possibilities for sentiment analysis. [6]
In general, significant progress has been made in the field of sentiment analysis, and the development of deep learning technology provides strong support for the improvement of model performance. These research results provide a solid foundation for us to better understand and apply sentiment analysis. In the current society, sentiment analysis has important value in public opinion monitoring, social media analysis, market research and other fields, and sentiment analysis on fertility issues also provides a useful reference for policy making and social management
3. Theoretical introduction - GNN-LSTM
The structure of the GNN-LSTM model [5] for sentiment classification by extracting semantic features and structural features is shown in Fig.2.
Assuming that the word segmentation of short text isembedding word vectors is \( T = \lbrace {W_{1}},{W_{2}}, {W_{3}}......{W_{n}}\rbrace \) ,the embedding word vector is \( V= \lbrace V({W_{1}}), V({W_{2}}), V({W_{3}})......V({W_{i}})\rbrace ,1≤i≤n \) , edge attributes \( E = \lbrace V({e_{1}}), V({e_{2}}), V({e_{3}})......V({e_{1}}4)\rbrace \) ,feature extraction is performed on V and E using graph filters:
\( {M_{i}}= \frac{1}{N(i)}Dϕt(f(ϕA)(|X_{i}^{t}X_{j}^{t}|⊙{e_{ij}})), jϵN(i) \) (1)
where \( ϕA \) is the soft-attention mechanism that assigns the weight to the feature differences of the nodes; \( f \) is the sigmoid activation function; ⊙ is the concatenation of node features and edge features; and Dϕt is a linear transformation and ReLU activation to generalize the model. Finally, the mean value is taken for features of all adjacent nodes.
For the constructed semantic graph to reduce redundant features, no self-connected edges are added to the subword nodes. The nodes’ own features are passed instead in the update stage:
\( X_{i}^{t+1}=F({ϕ_{U}}){LSTM_{t}}(X_{i}^{t}⊙{M_{i}}) \) (2)
Combining the node’s own feature with the adjacency feature as input at moment t, the LSTM model completes linear transformation and activation to obtain the state of the source node with adjacency features at moment t+1. This step completes the state update.
The graph convolution operation is then iterated three times. To stabilize the model convergence rate and stability, LayerNorm calculations are performed as Eq. (3) after each convolution layer to ensure that the features converge to the same distribution before each pass:
\( X_{i}^{ \prime }= \frac{X-E[X]}{\sqrt[]{Var[X]+ ∈}}+ β \) (3)
The mean and standard deviations of all nodes and channels in a mini-batch are calculated and then activated by ReLU. Finally, the aggregated 3rd-order adjacency feature is read out by the global pool algorithm and fed into the softmax function for classification.
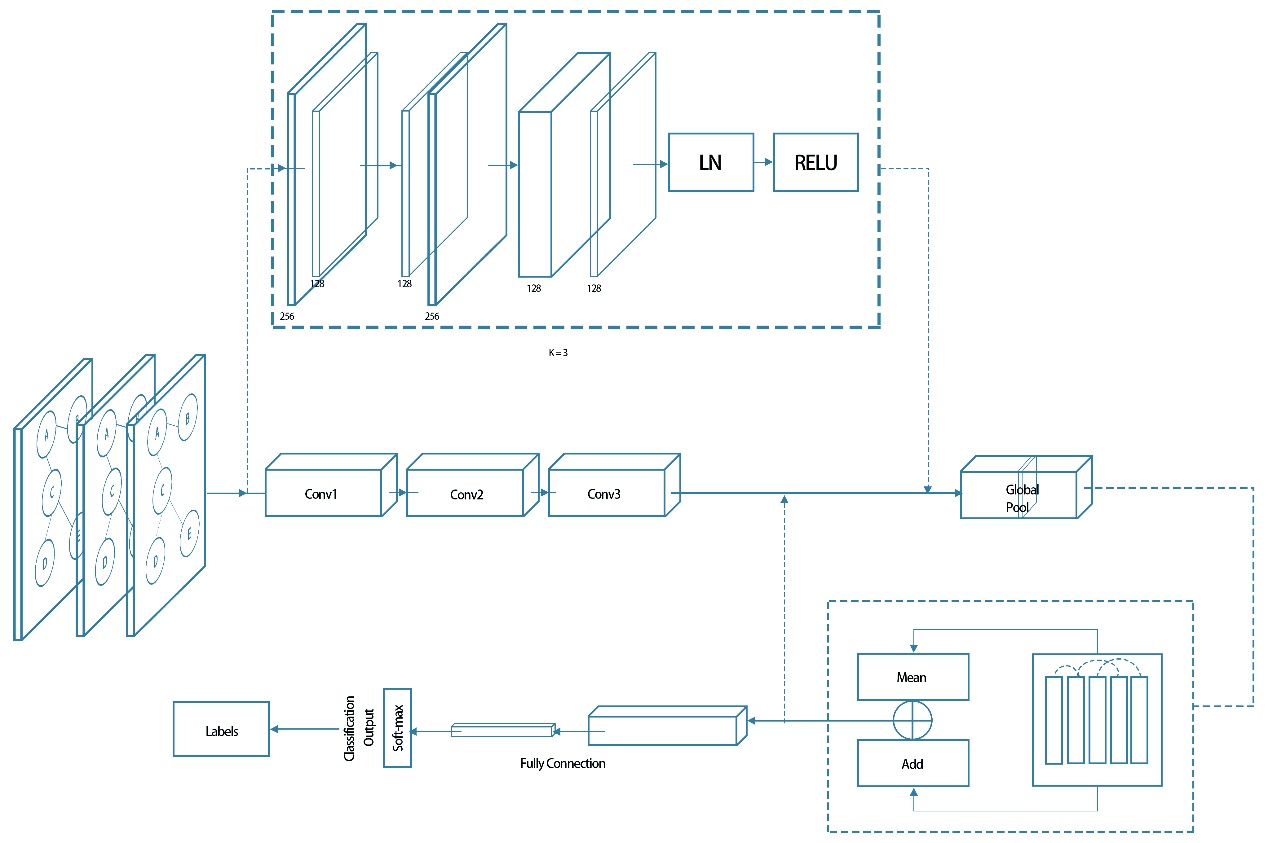
Figure 2. Structure diagram of GNN-LSTM[5]
The structure of GNN-LSTM model. It mainly includes three convolution layers with LN and RELU. The global feature is obtained by global pool function. The layer of global pool is constructed by mean function and adding function.
4. Research Methodolog
4.1. Data acquisition and preprocessing
After obtaining the online comment data set of users through the Python crawler, a Python program was written to clean the comment data (for special symbols, expressions, stop words, etc.), and jieba was used to segment the obtained comment data, and the data set was used as a test set. The Train_DataSet.csv (about 7400 data) given in the CCF Big Data and Computational Intelligence competition was used as the training set.
Step 1: Write a Python crawler to obtain the microblog comments related to fertility issues in m.weibo.cn, obtain the User-Agent,Cookie,Refer and other data through the developer window on the microblog detail page to locate the relevant microblog comment area, and obtain the text in the data array. And stored them in csv files in order (about 7300 comments).
Step 2: Write a Python program to remove stop words and special symbols from the comment data in the csv file, reduce the noise and dimension of the text, and ensure the quality and applicability of the text. jieba word segmentation package is used to segment the comment data. Table 1 lists 10 review data after cleaning and word segmentation.
Table 1. Examples of review data after cleaning and word segmentation.
Serial number | Review data |
1 | 看到大家都在骂我就放心了(It’s reassuring to see everyone dissing this policy) |
2 | 花小钱办大事做美梦(Dreaming to make big changes on a dime) |
3 | 做个梦还是可以(It’s still OK if you are dreaming) |
4 | 问题在奖励吗(Is ‘reward’the actual question?) |
5 | 加俩个有人愿意的估计(Perhaps someone will take it if there is more money as reward) |
6 | 可以考虑一下(It deserves a consideration) |
7 | 这笔钱算婚前还是婚后财产(Whether the money counts as pre-marriage or post-marriage property) |
8 | 巨款这下大家可以放心大胆的生了(Such a huge amount of money, go and be parents) |
9 | 可以(Well) |
10 | 太多了太多了够买套房了(It’s even enough to purchase a house) |
(self-drawn by the author)
4.2. Sentiment analysis
Step 1: Build the model and use the text feature extraction method TF-IDF to transform the text data into feature vectors. Make sure they are able to capture the important information of the text.
Step 2: Model training. Prepare the training set, including the text data with sentiment labels and the corresponding feature vectors. Using the feature vectors of the training set and the sentiment labels, train the model. During training, the model will learn how to capture sentiment information from the features.
Step 3: Model Tuning. Evaluate the performance of the trained model on the validation set using the evaluation metric F1 score (F1 score is approximately equal to 0.81 after 10 epochs of training after tuning), etc. According to the performance of the validation set, the model was tuned.
Step 4: Model Test. Perform the same text feature extraction step using the text data of the test set to transform the text data into feature vectors. The trained model is used to perform sentiment analysis on the feature vectors of the test set, and the Python drawing toolkit is used to generate three-dimensional scatter plots according to the sentiment orientation vectors, so as to obtain intuitive results and analyze them.
Step 5: Word cloud map generation. In order to make the results easier to analyze, a Python program is written to display the word frequency distribution in the review data in the form of WordCloud, which helps to understand the distribution of key words and sentiment words in the review.
5. Sentiment Analysis Results
5.1. Word cloud map generation results
A word cloud is a canvas of words, where the size and color of words reflect their importance and frequency in the text data. Firstly, the obtained review text data is input into the word cloud generation program after data cleaning (for special symbols, expressions, stop words, etc.) and word segmentation, and the results are shown in Figure 3. Through the word cloud map, we can see various key words in the review and their relative importance. From the figure, we can clearly see that words such as“奖励”("reward"), “结婚”("marriage") and“孩子”( "children" )are particularly prominent, which indicates that in the comments, these words appear more frequently and may be related to the birth policy and family life. The saliency of these words suggests their importance in the comments, which may be the core topics that the commenters focus on.
However, it is noticeable that there are also some words with obvious negative sentiment in the word cloud map, such as“叫花子”( "beggar") and “打发”("dismiss"). The presence of these words may reflect the negative or critical views of some commentators on fertility issues. The presence of such words provides us with more in-depth emotional insight, suggesting that there is a certain amount of controversy and dissatisfaction in the discussion of fertility policy.

Figure 3. Word cloud map of comment text data
(self-drawn by the author)
The beauty of the word cloud map is its ability to visually present a large amount of textual information, allowing us to quickly understand the hot topics and sentiment trends in reviews. It provides an entry point for researchers to explore the review data more deeply, looking for underlying patterns and trends.
5.2. 3D scatter plot output of sentiment orientation vector
In addition to word cloud, this study also uses the Python drawing toolkit to generate 3D scatter plots of sentiment orientation vectors based on review data. This 3D scatter plot is a powerful visualization tool that presents the sentiment orientation of reviews through three dimensions: Probability0, Probability1, and Probability2. After fine-tuning the trained model, the Python drawing toolkit was used to produce a 3D scatter plot based on the sentiment orientation vector of the review data (Figure 4).
It can be seen from the figure that most of the review data sentiment orientation is concentrated in the direction of Probability1 and Probability2. This means that within the scope of the data in this study, the comments under the fertility issues related microblogs mainly show neutral and negative emotional tendencies. This observation is very interesting, and it may reflect different views and emotional reactions to fertility issues in society. On the one hand, neutral comments may indicate that the reviewer has a neutral or objective stance on fertility policy and does not have a strong emotional inclination. On the other hand, negative comments may reflect that some commenters hold negative opinions about the policy or related topics, and they may feel worried, dissatisfied or critical.
It is worth noting that while neutral and negative sentiment tendencies dominate, some vectors are also seen in the figure close to points in the direction of Probability0. These points represent positive sentiment tendencies, although they are less in number, but also hint at the possibility that a part of the reviewers may hold a positive attitude or express encouragement and support towards fertility issues.
This 3D scatter plot provides us with a comprehensive perspective of sentiment orientation and helps us better understand the distribution and trend of sentiment in the review data. Through this visualization tool, we can dig deeper into the sentiment information of review data, which provides an important reference for subsequent analysis and research.
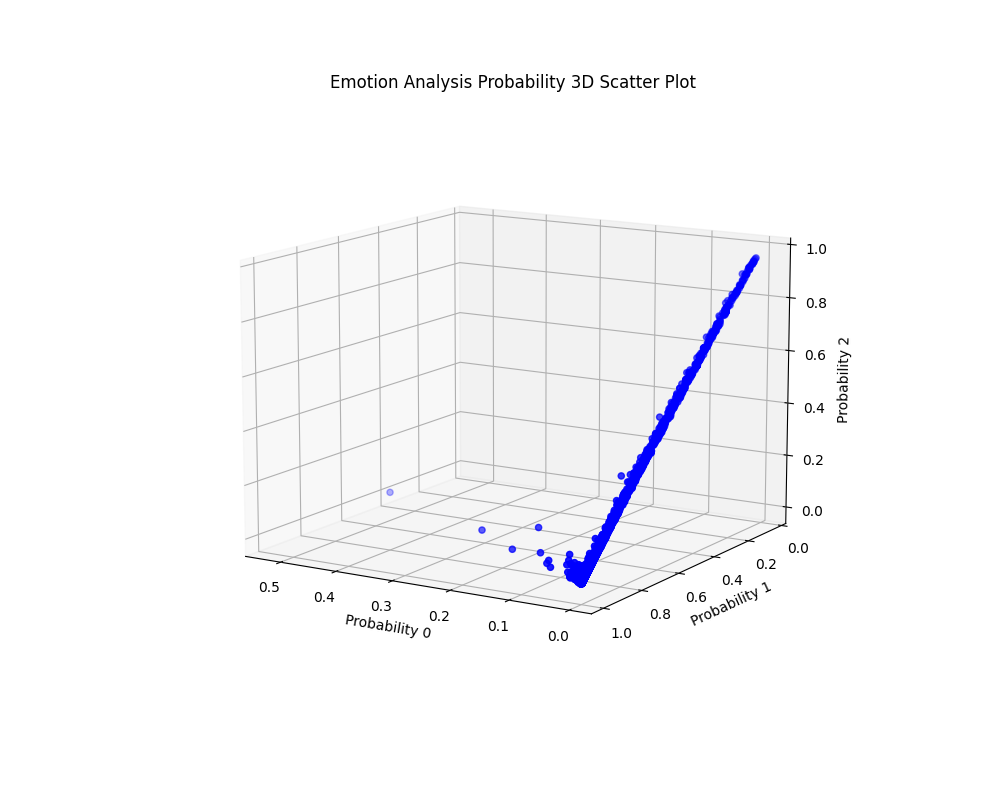
Figure 4. 3D scatter plot of sentiment tendency vector4
(self-drawn by the author)
In summarizing the above results, the word cloud map and the 3D scatter plot show us the multi-dimensional characteristics of the review data, revealing the reviewers' concerns and emotional tendencies towards fertility issues. These visualization tools not only make the data more interpretable, but also provide us with deeper insights into social attitudes and emotional reactions to fertility issues.
6. Conclusion
Within the scope of the study, this study conducted an in-depth analysis of netizens' discussions on fertility issues. Through the visualization tools of word cloud map and 3D scatter plot of sentiment orientation vector, some key findings and insights can be clearly summarized. These findings provide important clues for understanding the causes of fertility decline in China and the implications for policy and social environments.
Firstly, this study found that netizens' discussions mainly focused on two topics, namely marriage and money. This indicates that fertility issues are largely related to marriage and economic conditions. Marriage is seen as a precondition for fertility, while money is seen as an important factor affecting fertility decisions. These two themes highlight the impact of social structure and economic pressures on fertility.
Secondly, through the analysis of emotional tendency vector, we found that most Internet users held neutral and negative emotional attitudes. This means that most people do not have a positive attitude towards fertility issues,and may have some doubts or concerns. The prevalence of such emotional attitudes may be one reason for the declining fertility rate, suggesting that there is much room for improvement in policies and social environments to encourage fertility.
These findings reveal some important factors behind the country's declining fertility rate. Policy makers and social researchers can draw some insights from them. First, the government can consider making more supportive policies and measures to encourage families and children, so as to reduce the influence of marriage and economic pressure on fertility decisions. Secondly, public education and publicity should be strengthened to improve people's positive attitude towards childbirth and reduce their worries and doubts.
However, there are some limitations and urgent problems to be solved in this study. Firstly, there are a large number of irony and sarcastic comments on the Internet, and these text data are often difficult to accurately classify. This brings great challenges to the sentiment analysis task, and it is necessary to further study how to recognize and classify these complex text data. Secondly, the Chinese corpus is constantly changing, and it is necessary to constantly update and improve the sentiment analysis model to adapt to new language styles and expressions.
This study provides modest insights into fertility issues, but still leaves open the challenges faced by the field of sentiment analysis and text data processing. It is hoped that the results of this study can provide a humble reference for public opinion analysis and policy making, and also prompt more research and innovation to solve related problems. In the ever-evolving Internet era, we need to make continuous efforts to improve and adapt to better understand and cope with social issues.
References
[1]. G. Xu, Y. Meng, X. Qiu, Z. Yu and X. Wu, "Sentiment Analysis of Comment Texts Based on BiLSTM," In the IEEE Access, vol. 7, pp. 51522-51532, 2019, doi: 10.1109 / Access. 2019.2909919.
[2]. wen-ling li. Sentiment analysis method based on weibo comments research [D]. Yanbian university, 2021. The DOI: 10.27439 /, dc nki. Gybdu. 2021.000058.
[3]. Li, H.: Ma, Y.: Ma, Z. Zhu, H. Weibo Text Sentiment Analysis Based on BERT and Deep Leaming. Appl. Sci. 2021, 11.
[4]. MENG Bin. Research on sentiment analysis of microblog comments of public security events based on deep learning [D]. Liaocheng university, 2022. DOI: 10.27214 /, dc nki. Glcsu. 2022.000233.
[5]. Li, Y., & Li, N. (2022). Sentiment Analysis of Weibo Comments Based on GraphNeuralNetwork. IEEEAccess, 10234723 510. https://doi.org/10.1109/ACCESS.2022.3154107
[6]. Wang, Z., Wang, M., Shen, H., & Han, Y. (2022). Application of Sentiment Classification of Weibo Comments Based on TextCNN Model. Proceedings - 2022 International Conference on Computer Network, Electronic and Automation, ICCNEA 2022, 223-228. https://doi.org/10.1109/ICCNEA57056.2022.00057
Cite this article
Qiao,Y. (2024). Sentiment analysis of Sina microblog comments related to fertility issues based on GNN-LSTM model. Applied and Computational Engineering,45,251-258.
Data availability
The datasets used and/or analyzed during the current study will be available from the authors upon reasonable request.
Disclaimer/Publisher's Note
The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of EWA Publishing and/or the editor(s). EWA Publishing and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content.
About volume
Volume title: Proceedings of the 4th International Conference on Signal Processing and Machine Learning
© 2024 by the author(s). Licensee EWA Publishing, Oxford, UK. This article is an open access article distributed under the terms and
conditions of the Creative Commons Attribution (CC BY) license. Authors who
publish this series agree to the following terms:
1. Authors retain copyright and grant the series right of first publication with the work simultaneously licensed under a Creative Commons
Attribution License that allows others to share the work with an acknowledgment of the work's authorship and initial publication in this
series.
2. Authors are able to enter into separate, additional contractual arrangements for the non-exclusive distribution of the series's published
version of the work (e.g., post it to an institutional repository or publish it in a book), with an acknowledgment of its initial
publication in this series.
3. Authors are permitted and encouraged to post their work online (e.g., in institutional repositories or on their website) prior to and
during the submission process, as it can lead to productive exchanges, as well as earlier and greater citation of published work (See
Open access policy for details).
References
[1]. G. Xu, Y. Meng, X. Qiu, Z. Yu and X. Wu, "Sentiment Analysis of Comment Texts Based on BiLSTM," In the IEEE Access, vol. 7, pp. 51522-51532, 2019, doi: 10.1109 / Access. 2019.2909919.
[2]. wen-ling li. Sentiment analysis method based on weibo comments research [D]. Yanbian university, 2021. The DOI: 10.27439 /, dc nki. Gybdu. 2021.000058.
[3]. Li, H.: Ma, Y.: Ma, Z. Zhu, H. Weibo Text Sentiment Analysis Based on BERT and Deep Leaming. Appl. Sci. 2021, 11.
[4]. MENG Bin. Research on sentiment analysis of microblog comments of public security events based on deep learning [D]. Liaocheng university, 2022. DOI: 10.27214 /, dc nki. Glcsu. 2022.000233.
[5]. Li, Y., & Li, N. (2022). Sentiment Analysis of Weibo Comments Based on GraphNeuralNetwork. IEEEAccess, 10234723 510. https://doi.org/10.1109/ACCESS.2022.3154107
[6]. Wang, Z., Wang, M., Shen, H., & Han, Y. (2022). Application of Sentiment Classification of Weibo Comments Based on TextCNN Model. Proceedings - 2022 International Conference on Computer Network, Electronic and Automation, ICCNEA 2022, 223-228. https://doi.org/10.1109/ICCNEA57056.2022.00057