







1. Introduction
1.1. Background
Social media has become an indispensable part of the digital era, its rapid development and widespread usage profoundly altering people's lifestyles, social behaviors, and information dissemination methods. From the earliest forms of electronic mail and instant messaging tools to contemporary platforms like Facebook, Instagram, and Twitter, social media has established a vast network for information exchange on a global scale.
The evolution of social media owes much to the proliferation of the internet, the ubiquity of mobile devices, and advancements in technologies such as cloud computing. These advancements enable users to conveniently access and share information anytime and anywhere, thus fueling the rapid expansion of social media. Today, social media has become an integral aspect of people's lives, with both individuals and enterprises leveraging it as a crucial platform for communication and marketing.
On social media platforms, users express their opinions, emotions, and attitudes through various forms of content such as text, images, and videos. Emotional expression constitutes a significant component of social media, as users engage in communication, interaction, and dialogue by expressing their emotions. However, with the proliferation of social media and the explosive growth of information volume, effectively understanding and analyzing this information has become increasingly critical.[1]
Sentiment analysis, as a form of artificial intelligence technology, aims to identify and analyze emotional states from various forms of data such as text, speech, and images. In the context of social media, sentiment analysis assists in better understanding and grasping emotional expressions on social media, thereby providing users with more personalized services and experiences. Consequently, against the backdrop of the rapid development and widespread adoption of social media, sentiment analysis has emerged as a significant research domain with extensive application prospects and profound societal significance.
1.2. Definition of Social Media Sentiment Analysis
Social media sentiment analysis is a discipline utilizing natural language processing and machine learning techniques, primarily aimed at identifying and analyzing users' emotional states from textual data on social media platforms.[2] In this process, we endeavor to comprehend and grasp the emotional inclinations expressed by users on social media, including positivity, negativity, or neutrality, as well as the degree of emotional expression and classification of emotions. This analytical approach involves techniques such as semantic understanding of textual data, sentiment classification, and emotional quantification, all with the aim of unveiling users' emotional needs, interests, and social behaviors on social media.
1.3. Applications of Social Media Sentiment Analysis on Social Media Platforms
Social media sentiment analysis finds widespread applications across various domains, including but not limited to marketing, public opinion monitoring, and user sentiment understanding.[3] These applications not only assist businesses in understanding consumer demands and optimizing products and services but also aid governments and organizations in better understanding public opinion and improving policies and services.
Social media sentiment analysis plays a significant role in marketing. By analyzing users' emotional expressions on social media, businesses can understand users' attitudes and evaluations towards products and services, thereby adjusting marketing strategies and enhancing product design to improve market competitiveness. For example, an e-commerce platform can utilize sentiment analysis to gauge whether users' evaluations of a particular product are positive, thereby tailoring promotional and marketing activities to boost sales.
Social media sentiment analysis also finds extensive applications in public opinion monitoring. Governments, businesses, and organizations can monitor emotional expressions on social media to promptly identify and address negative information and public opinion events, thereby safeguarding their reputation and interests. For instance, government departments can analyze user comments and feedback on social media to understand public attitudes and opinions towards specific policies or events, providing references for policy adjustments and decision-making.
Social media sentiment analysis also helps businesses and organizations better understand users' emotional needs and behavioral characteristics, thus providing more personalized and high-quality services. For example, an online education platform can utilize sentiment analysis to understand students' preferences and comprehension levels regarding course content, thereby adjusting teaching methods and content to enhance teaching effectiveness.
1.4. Objectives and Significance
The objective of this study is to address specific problems or challenges in the field of social media sentiment analysis through machine learning methods. In the context of today's social media inundated with vast amounts of textual data, manually analyzing the emotional states of this data is a time-consuming and labor-intensive task. Therefore, the goal of this paper is to develop an automated sentiment analysis system capable of rapidly and accurately identifying and analyzing users' emotional inclinations on social media. By employing machine learning methods, we aim to enhance the accuracy and efficiency of sentiment analysis, thus better meeting users' needs.
2. Exploratory Data Analysis
2.1. Data Description and Preprocessing
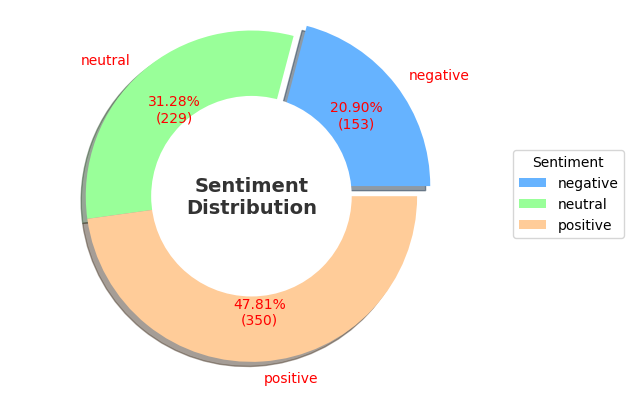
The dataset utilized in this study encompasses post data from three major social media platforms (Instagram, Facebook, Twitter), totaling 736 posts. The distribution of sentiments is illustrated in Figure 1: there are 350 posts classified as positive sentiment, 153 as negative sentiment, and 229 as neutral sentiment. Additionally, the dataset comprises rich features, including text content, sentiment labels, timestamps, user information, platform sources, tags, repost counts, likes counts, posting country, year, month, date, and hour. These features furnish an ample information foundation for subsequent exploratory data analysis and sentiment analysis.
|
Figure 1. Distribution of Sentiments |
2.2. Analysis of Common Vocabulary for Each Sentiment
An analysis is conducted on the common vocabulary in posts categorized as positive, negative, and neutral sentiments. These common terms aid in better understanding the themes and focal points of users under each emotional state. The specific analysis results are as follows:
Positive Sentiment: Common terms in posts with positive sentiment include "joy," "friend," "laughter," "new," "challenge," and "life." These terms reflect themes users may focus on in a positive emotional state, such as friendship, joy, and new life challenges.
Neutral Sentiment: Common terms in posts with neutral sentiment include "new," "explore," "excitement," "life," "beautiful," and "night." These terms indicate themes users may focus on in a neutral emotional state, such as exploring new things, the beauty of life, and nighttime activities.
Negative Sentiment: Common terms in posts with negative sentiment include "despair," "lost," "emotion," "feel," "bitter," and "storm." These terms reflect difficulties and negative emotions users may encounter in a negative emotional state, such as despair, loss, and anger.
Figure 2 presents word cloud visualizations further illustrating these common terms, highlighting their frequencies across different sentiment categories.
|
|
|
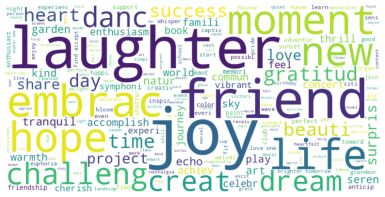
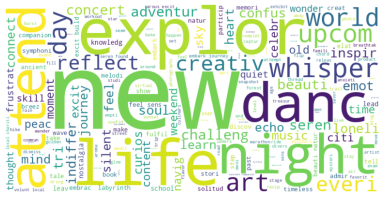

Figure 2. Word Cloud Visualization of Positive, Neutral, and Negative Sentiments
3. PassiveAggressiveClassifier Model
3.1. Model Overview
The PassiveAggressiveClassifier (PAC) is a classification algorithm based on online learning, particularly suitable for large-scale data and streaming data classification tasks.[4] Its name derives from its two distinct behavioral modes, passive and aggressive, depending on the algorithm's performance on each instance.
The PAC algorithm is adept at handling streaming data, where data sources continuously generate new samples, which may be substantial in size. Compared to traditional batch processing algorithms, the PAC algorithm consumes less memory and trains faster.[5]
The fundamental idea of the PAC algorithm is online learning, meaning the algorithm updates the model with each sample it processes. It updates model parameters by applying a loss function to each instance to adapt to new data. During training, the PAC algorithm adjusts the model weights based on the classification results of samples to better accommodate the new data distribution.[6]
Due to its characteristic of updating model parameters based on instance classification results, the PAC algorithm performs admirably in handling non-stationary data and dynamic datasets. Moreover, it can adapt to noisy data and incompletely labeled data, endowing it with high robustness and generalization capability in practical applications.[7]
3.2. Algorithm Principles
The PassiveAggressive algorithm is an online learning algorithm designed to address binary classification problems. Its basic principle is to classify new data samples based on their features through online learning and update model parameters according to the prediction results to adapt to the new data distribution.
In the PassiveAggressive algorithm, suppose we have an input vector x and its corresponding target label y. The goal is to predict category y using the input vector x. The basic idea of the algorithm is to update model parameters after observing each instance (x, y) based on the difference between the predicted result and the actual label.
Specifically, the PassiveAggressive algorithm computes the predicted label y^ for instance x and updates the model parameters based on the difference between the predicted result y^ and the actual label y. The updating manner depends on whether the instance is classified correctly and the degree of classification.
If instance x is classified correctly, i.e., y^=y, there is no need for significant adjustments to the model parameters. At this point, the algorithm remains "passive," making minimal changes to the model parameters.
If instance x is misclassified, i.e., y≠y, adjustments to the model parameters are required to better adapt to the new data distribution. In this case, the algorithm adopts an "aggressive" strategy, adjusting the model parameters to some extent to make the predicted result closer to the actual label.
The parameter updating formula in the PassiveAggressive algorithm is as follows:
\( {w_{t+1}}={w_{t}}+α\cdot y\cdot x \)
Where wt is the model parameters at time step t, α is the learning rate (controlling the speed of parameter updates), y is the true label of the instance, and x is the feature vector of the instance.[8]
By continuously observing new data samples and updating model parameters, the PassiveAggressive algorithm can adapt to the new data distribution, thus demonstrating good performance on dynamic datasets and large-scale data.
3.3. Characteristics and Advantages
The PassiveAggressiveClassifier model possesses the following characteristics and advantages compared to other classification algorithms:
Online Learning: PassiveAggressiveClassifier is an online learning algorithm capable of dynamically updating model parameters while continuously receiving new data.[9] Unlike traditional batch processing algorithms, PassiveAggressiveClassifier does not require loading the entire dataset into memory for training, making it efficient for handling large-scale data.
Strong Adaptability: PassiveAggressiveClassifier exhibits strong adaptability to unstable data and dynamic datasets. Due to its online learning nature, the model can promptly adjust parameters to accommodate data changes, resulting in robustness and generalization capability.
Low Memory Consumption: Due to the nature of the PassiveAggressiveClassifier algorithm, which does not necessitate loading the entire dataset into memory for training, it incurs low memory consumption.[10] This advantage makes the algorithm particularly advantageous for handling large-scale data, especially in scenarios with limited memory resources.
Fast Training Speed: PassiveAggressiveClassifier algorithm typically demonstrates rapid training speed, particularly suitable for streaming data classification tasks. Thanks to its online learning nature, the model can immediately classify new data and update parameters, thus facilitating swift training processes.
Smaller Parameter Size: PassiveAggressiveClassifier models typically feature a smaller parameter size, resulting in relatively less space occupancy in memory. This characteristic enables the algorithm to be deployed and applied in resource-constrained environments.
In summary, the PassiveAggressiveClassifier model boasts advantages such as online learning, strong adaptability, low memory consumption, fast training speed, and smaller parameter size. These attributes render it highly effective in handling large-scale data and dynamic datasets, particularly suitable for streaming data classification tasks.
4. Experiment and Results
4.1. Data Processing and Feature Extraction
The data preparation phase aims to prepare the dataset for training and testing. Firstly, feature variables (X) and target variables (y) are extracted from the data frame. In this experiment, textual data is stored in a column named 'Clean_Text,' and sentiment labels are stored in a column named 'Sentiment.'
To evaluate the model's performance, the dataset is split into training and testing sets. The training set is used to train the model parameters, while the testing set is used to evaluate the model's performance. In this experiment, the dataset is split into an 80% training set and a 20% testing set, ensuring similar distributions of training and testing data. Additionally, a random seed (random_state) is set to ensure the reproducibility of the splitting results.
The feature selection and processing phase aim to transform textual data into numerical features usable by the model. The TF-IDF (Term Frequency-Inverse Document Frequency) vectorizer is utilized to extract features from textual data. TF-IDF is a commonly used text feature extraction method that transforms textual data into sparse matrices, representing the importance of each vocabulary term in each document.
4.2. Experimental Setup
At this stage, the PassiveAggressiveClassifier is chosen as the classifier, with the maximum number of iterations (max_iter) set to 50 and the random seed (random_state) set to 42.
4.3. Model Performance Evaluation Metrics
Following model training, the performance is evaluated using the testing set. Firstly, the model predicts on the testing set, then calculates classification metrics such as accuracy, precision, recall, and F1-score. These metrics comprehensively assess the model's performance across different categories. In this experiment, the model achieves an accuracy of 0.714 on the testing set, along with a detailed classification report containing precision, recall, and F1-score for each category.
4.4. Results Analysis and Discussion
Upon reviewing the data from the Classification Report, it's observed that the model demonstrates high precision and recall for the negative sentiment category on the training set, reaching 0.79 and 0.81, respectively, indicating good performance in identifying negative sentiments. However, for the neutral sentiment category, precision and recall are relatively lower at 0.73 and 0.55, possibly due to the ambiguous and complex nature of neutral sentiments, leading to poorer performance in identifying neutral sentiments. On the testing set, the model's performance remains stable overall. Although precision and recall for the neutral sentiment category are relatively lower, performance in other categories is acceptable. Considering all metrics, the model achieves an accuracy of 0.714 on the testing set, indicating reasonable overall performance.
The model's parameter settings significantly impact its performance. For instance, in this experiment, setting the maximum number of iterations (max_iter) to 50 affects the convergence speed and performance stability of the model. Adjusting the value of max_iter may influence the model's performance, necessitating further experimentation and evaluation. Additionally, exploring adjustments to parameters of the TF-IDF vectorizer, such as the maximum number of features (max_features), could optimize the model's performance.
5. Conclusion
This study aims to explore relevant issues in sentiment analysis on social media platforms, using the PassiveAggressiveClassifier model as the basis for analyzing and modeling post data from platforms like Instagram, Facebook, and Twitter. Initially, the dataset is loaded, preprocessed, and subjected to feature engineering to enhance data usability. Subsequently, the PassiveAggressiveClassifier model is employed for sentiment analysis of posts, followed by performance evaluation. Through analysis of the model's performance on both training and testing sets, it's observed that the model excels in identifying negative sentiments but faces challenges in classifying neutral sentiments. Finally, discussions and analyses are conducted on the model's advantages, limitations, and potential areas for improvement.
In future research and practice, sentiment analysis on social media presents many promising directions and challenges. Continuous improvement of model performance is crucial, achieved through parameter adjustments, exploration of new feature engineering methods, and the investigation of alternative classification algorithms for the PassiveAggressiveClassifier model. Furthermore, expanding the dataset is essential, with efforts directed toward collecting more diverse and representative social media data to cater to various sentiment analysis tasks in different scenarios and contexts. Additionally, there are numerous unexplored applications of sentiment analysis on social media, such as social opinion monitoring, government decision support, and personalized recommendation systems, offering solutions to practical issues and delivering more value to society and businesses. Looking ahead, challenges such as multimodal sentiment analysis, cross-lingual sentiment analysis, privacy protection, and data ethics may arise in the field of sentiment analysis on social media. Therefore, further exploration and research in these areas are needed to advance and refine sentiment analysis technology on social media, providing more beneficial support and assistance to people's lives and work.
References
[1]. Bello-Orgaz, G., Jung, J.J. and Camacho, D., 2016. Social big data: Recent achievements and new challenges. Information Fusion, 28, pp.45-59.
[2]. Yue, L., Chen, W., Li, X., Zuo, W. and Yin, M., 2019. A survey of sentiment analysis in social media. Knowledge and Information Systems, 60, pp.617-663.
[3]. Ravi, K. and Ravi, V., 2015. A survey on opinion mining and sentiment analysis: tasks, approaches and applications. Knowledge-based systems, 89, pp.14-46.
[4]. Rohera, D., Shethna, H., Patel, K., Thakker, U., Tanwar, S., Gupta, R., Hong, W.C. and Sharma, R., 2022. A taxonomy of fake news classification techniques: Survey and implementation aspects. IEEE Access, 10, pp.30367-30394.
[5]. Dhar, S., Guo, J., Liu, J., Tripathi, S., Kurup, U. and Shah, M., 2021. A survey of on-device machine learning: An algorithms and learning theory perspective. ACM Transactions on Internet of Things, 2(3), pp.1-49.
[6]. Gupta, R. and Roughgarden, T., 2016, January. A PAC approach to application-specific algorithm selection. In Proceedings of the 2016 ACM Conference on Innovations in Theoretical Computer Science (pp. 123-134).
[7]. Liu, J., Shen, Z., He, Y., Zhang, X., Xu, R., Yu, H. and Cui, P., 2021. Towards out-of-distribution generalization: A survey. arXiv preprint arXiv:2108.13624.
[8]. Lu, J., Zhao, P. and Hoi, S.C., 2016. Online passive-aggressive active learning. Machine learning, 103, pp.141-183.
[9]. Lobo, J.L., Del Ser, J., Bifet, A. and Kasabov, N., 2020. Spiking neural networks and online learning: An overview and perspectives. Neural Networks, 121, pp.88-100.
[10]. Ali, M. and Tariq, B., 2022. COMSATS University Islamabad.
Cite this article
Wang,Z.;Li,R. (2024). Advancements in social media sentiment analysis: A study utilizing the PassiveAggressiveClassifier model. Applied and Computational Engineering,71,150-156.
Data availability
The datasets used and/or analyzed during the current study will be available from the authors upon reasonable request.
Disclaimer/Publisher's Note
The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of EWA Publishing and/or the editor(s). EWA Publishing and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content.
About volume
Volume title: Proceedings of the 6th International Conference on Computing and Data Science
© 2024 by the author(s). Licensee EWA Publishing, Oxford, UK. This article is an open access article distributed under the terms and
conditions of the Creative Commons Attribution (CC BY) license. Authors who
publish this series agree to the following terms:
1. Authors retain copyright and grant the series right of first publication with the work simultaneously licensed under a Creative Commons
Attribution License that allows others to share the work with an acknowledgment of the work's authorship and initial publication in this
series.
2. Authors are able to enter into separate, additional contractual arrangements for the non-exclusive distribution of the series's published
version of the work (e.g., post it to an institutional repository or publish it in a book), with an acknowledgment of its initial
publication in this series.
3. Authors are permitted and encouraged to post their work online (e.g., in institutional repositories or on their website) prior to and
during the submission process, as it can lead to productive exchanges, as well as earlier and greater citation of published work (See
Open access policy for details).
References
[1]. Bello-Orgaz, G., Jung, J.J. and Camacho, D., 2016. Social big data: Recent achievements and new challenges. Information Fusion, 28, pp.45-59.
[2]. Yue, L., Chen, W., Li, X., Zuo, W. and Yin, M., 2019. A survey of sentiment analysis in social media. Knowledge and Information Systems, 60, pp.617-663.
[3]. Ravi, K. and Ravi, V., 2015. A survey on opinion mining and sentiment analysis: tasks, approaches and applications. Knowledge-based systems, 89, pp.14-46.
[4]. Rohera, D., Shethna, H., Patel, K., Thakker, U., Tanwar, S., Gupta, R., Hong, W.C. and Sharma, R., 2022. A taxonomy of fake news classification techniques: Survey and implementation aspects. IEEE Access, 10, pp.30367-30394.
[5]. Dhar, S., Guo, J., Liu, J., Tripathi, S., Kurup, U. and Shah, M., 2021. A survey of on-device machine learning: An algorithms and learning theory perspective. ACM Transactions on Internet of Things, 2(3), pp.1-49.
[6]. Gupta, R. and Roughgarden, T., 2016, January. A PAC approach to application-specific algorithm selection. In Proceedings of the 2016 ACM Conference on Innovations in Theoretical Computer Science (pp. 123-134).
[7]. Liu, J., Shen, Z., He, Y., Zhang, X., Xu, R., Yu, H. and Cui, P., 2021. Towards out-of-distribution generalization: A survey. arXiv preprint arXiv:2108.13624.
[8]. Lu, J., Zhao, P. and Hoi, S.C., 2016. Online passive-aggressive active learning. Machine learning, 103, pp.141-183.
[9]. Lobo, J.L., Del Ser, J., Bifet, A. and Kasabov, N., 2020. Spiking neural networks and online learning: An overview and perspectives. Neural Networks, 121, pp.88-100.
[10]. Ali, M. and Tariq, B., 2022. COMSATS University Islamabad.