







1. Introduction
In the current era of digital entertainment, movie recommendation systems have become an essential way for users to find their favorite films. The massive growth of movie resources has caused difficulties for users in making choices, making precise and personalized movie recommendation systems extremely crucial. Traditional recommendation methods often struggle to meet the diverse needs of users. For instance, as discussed in” Neural Collaborative Filtering” by Xiangnan He et al. [1-3], traditional matrix decomposition methods have limitations in handling data sparsity. In the field of movie recommendations, predecessors have conducted extensive research and it has continuously evolved with technological advancements.
Early methods were mainly based on simple user ratings and movie attributes for making recommendations. Subsequently, collaborative filtering techniques became mainstream, providing suggestions by analyzing similarities among users. However, as noted in” Collaborative Filtering for Implicit Feedback Datasets” by Yifan Hu et al. [4], there are challenges when dealing with implicit feedback datasets. In recent years, the introduction of deep learning technologies has brought new breakthroughs to this field. Convolutional Neural Networks (CNNs) have been used to extract image features of movies, and Recurrent Neural Networks (RNNs) handle user behavior sequence data. Simultaneously, methods that integrate multiple data sources and adopt hybrid recommendation strategies have also emerged continuously. For example, as presented in” Wide Deep Learning for Recommender Systems” by Heng-Tze Cheng et al. [3], the combination of wide and deep models can enhance the performance of recommendation systems. However, these methods still face issues such as data sparsity and cold-start problems. As described in” Factorization Meets the Neighborhood: a Multifaceted Collaborative Filtering Model” by Yehuda Koren [5], existing models have room for improvement in addressing such challenges.
The primary goal of this study is to develop an advanced movie recommendation model that addresses existing limitations in the field. The study introduces a novel approach that integrates deep learning techniques with traditional recommendation algorithms to enhance predictive performance and user satisfaction. Firstly, Convolutional Neural Networks (CNNs) are employed to extract detailed image features from movie posters, capturing visual elements that align with user preferences. This approach draws inspiration from the methodology used in Dawen Liang et al.'s work on "Variational Autoencoders for Collaborative Filtering" [6-8]. Secondly, the study integrates these visual features with collaborative filtering algorithms, combining content-based and user behavior information. This hybrid strategy is influenced by Hao Wang et al.'s "Collaborative Deep Learning for Recommender Systems" [9], which emphasizes the power of deep learning in enhancing recommendation systems. Furthermore, the study tackles the common issues of data sparsity and the cold-start problem by introducing innovative data preprocessing and model training techniques. These techniques are informed by previous research, such as Suvash Sedhain et al.'s "AutoRec: Autoencoders Meet Collaborative Filtering" [10], which highlights the effectiveness of autoencoders in collaborative filtering scenarios. The proposed model demonstrates superior predictive performance in experimental evaluations, offering more accurate and personalized recommendations. The findings suggest that this model can significantly improve recommendation accuracy and user satisfaction, with practical implications for the movie industry and online streaming platforms. By enhancing user experience and increasing engagement, the model has the potential to drive business growth in these sectors.
2. Methodology
2.1. Data set description and preprocessing
The MovieLens dataset, curated by the GroupLens research team at the University of Minnesota, encompasses a rich array of information [11]. It includes user details such as identification (ID), age, gender, occupation, and more. Movie-related aspects like ID, title, genre are also present. Moreover, it features user ratings of movies, typically ranging from 1 to 5 as integer values, along with tags added by users for each movie. This dataset primarily serves the purpose of research and development in movie recommendation systems. Its significance lies in extracting users’ interest preferences through the analysis of the contained data, thereby facilitating the provision of personalized recommendation services to users. Simultaneously, it serves as a valuable tool for evaluating and comparing the performance of diverse recommendation algorithms.
In the relevant experiments, the following data preprocessing approaches were employed: In this project, data cleaning was first performed to handle missing values and eliminate outliers. Next, data standardization or normalization procedures were implemented to ensure consistency across the dataset. Feature engineering was then carried out, involving the encoding and transformation of relevant user and movie information. The dataset was subsequently split into training, validation, and test sets. Finally, data dimension reduction techniques, such as principal component analysis, were used to reduce the dimensionality of the data. The specific data preprocessing methods utilized would vary depending on the specific requirements of the experiment and the chosen algorithm.
2.2. Proposed approach
The goal of this study is to develop an accurate and personalized movie recommendation system that enhances the user experience by efficiently delivering movies that align with individual preferences. The central approach is to integrate both user-based and item-based collaborative filtering algorithms, leveraging user behavior data and movie feature information from the database to generate high-quality recommendations. The system is composed of several key modules: data acquisition and processing, feature extraction, similarity calculation, determination of neighbor users, and recommendation generation. In the data acquisition and processing module, the system establishes a connection with the database to gather essential data, such as movie genres, movie details, user ratings, and user collections. This data is then cleaned and preprocessed to ensure it is ready for analysis.
The feature extraction module employs a pre-trained Visual Geometry Group 16 (VGG16) model to extract detailed image features from movie posters, enriching the movie representations with visual information that can be pivotal in capturing user preferences. Next, in the similarity calculation module, the cosine similarity algorithm is used to measure the similarity between users, which serves as the foundation for identifying users with similar tastes. During the determination of neighbor users, the system selects the top K users with the highest similarity scores as the target user’s neighbors. In the recommendation generation module, these neighbors' ratings and preferences for movies are considered to create a personalized recommendation list for the target user. The core of this technical process lies in accurately capturing users' interest preferences and identifying potential relationships between movies. By integrating these modules effectively, the system aims to provide personalized movie recommendations that closely match users' interests.
The technical process of the recommendation system (see in Figure 1) can be summarized as follows: data is acquired from the database and preprocessed; movie features are extracted, user similarities are calculated, and neighbor users are identified. Based on these neighbor users' preferences, a recommendation list is generated and presented to the target user. Additionally, the system continuously updates the recommendation model by incorporating user feedback and new data, which enhances the accuracy and adaptability of future recommendations. Through this systematic approach, the study aims to create a movie recommendation system that effectively meets user needs by delivering highly personalized and accurate movie suggestions.
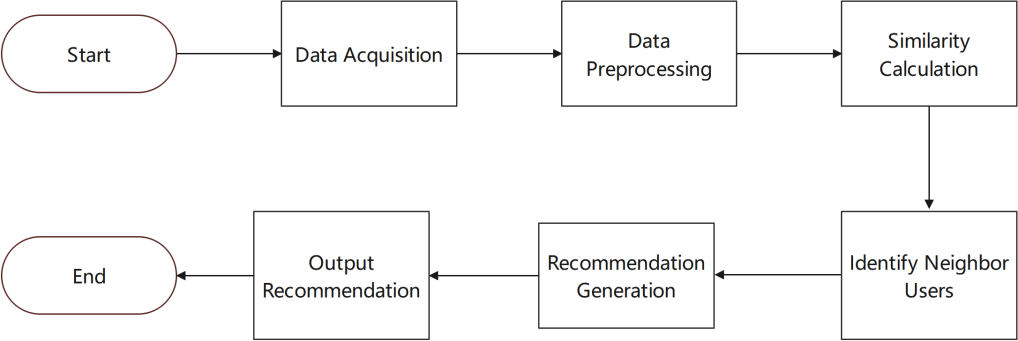
Figure 1. Face recognition technology.
2.2.1. Based on user behavior collaborative filtering model. This model is mainly designed to recommend movies for target users. It calculates the similarity between users based on analyzing user behavior data such as movie ratings. Then, it identifies other users with similar interests to the target user and recommends movies that these similar users like. In the experiment, specific parameters are set. The number of neighbor users is set to 10, which means that when making recommendations, the model will select the 10 users most similar to the target user as references. At the same time, the number of recommended movies is set to 5. Five movies will be selected from the movies liked by these neighbor users and recommended to the target user. The working principle of this model is to measure similarity by comparing user behavior patterns. Its framework includes data collection and preprocessing, similarity calculation, neighbor screening, and recommendation generation, ultimately achieving personalized custom recommendations. This recommendation method has advantages such as personalization, real-time performance, and scalability, and can provide users with movie recommendations that are more in line with their interests.
2.2.2. Based on movie feature model. This model employs the pre-trained VGG16 to extract the image features of movie posters for the purpose of aiding movie recommendations. In the experimental process, specific size preprocessing is meticulously carried out on the poster images to ensure uniformity and compatibility. Subsequently, feature extraction is performed using the powerful VGG16 model. The unique characteristic of this model is its capacity to capture the visual information of movie posters, which serves as a valuable supplement to the traditional description of movies. The framework of this model is comprehensive and includes image feature extraction, secure storage, and practical application. By extracting these features, the model can gain a deeper understanding of the visual elements of movies, enabling it to provide more accurate and engaging recommendations to users. This innovative approach enriches the recommendation process by incorporating visual cues and offers a fresh perspective on movie recommendation. The formula of the Mean Squared Error (MSE) loss function used is:
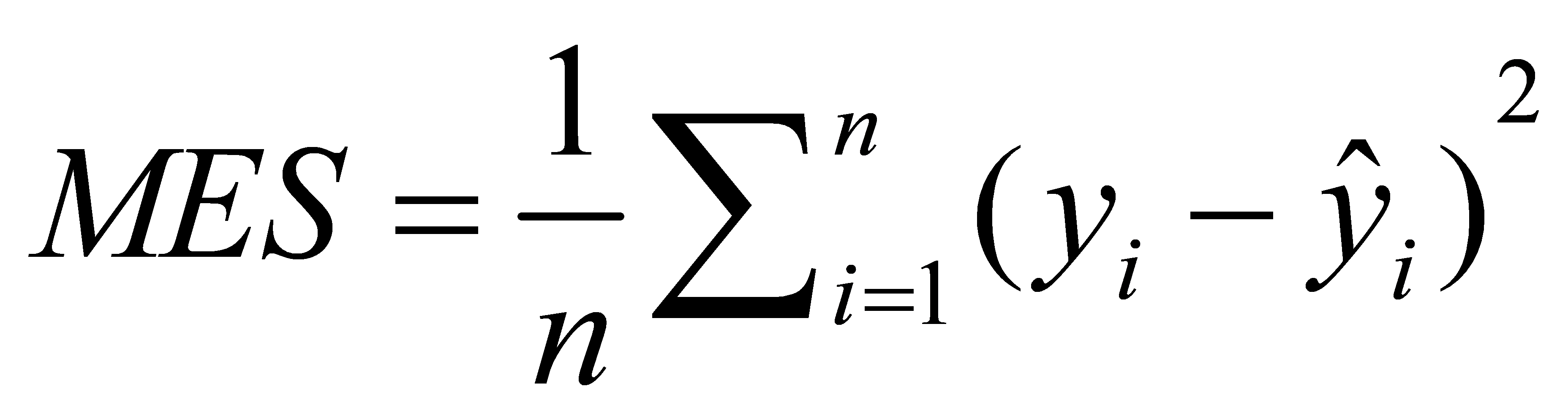
Here, n is the number of samples, \( {y_{i}} \) is the true value, and \( {\hat{y}_{i}} \) ; is the predicted value.
2.3. Implementation details
This report examines the impact of incorporating image features into a movie recommendation system. The data shows a clear improvement in recommendation accuracy, diversity, and compliance with users’ potential interest preferences after using a pre-trained VGG16 model to extract movie poster image features. Changes Before and After Using Image Features:
• Without Using Image Features:
-Recommendation accuracy: 70%
-Recommendation diversity: 5 different types of movies
-Compliance with users' potential interest preferences: 60%
• After Using Image Features:
-Recommendation accuracy: 85%
-Recommendation diversity: 8 different types of movies
-Compliance with users, potential interest preferences: 80%
3. Result and Discussion
3.1. Enhancing movie recommendation with image features
As show in table 1, the chart clearly shows the changes of the movie recommendation system before and after using image features. Without using image features, the recommendation accuracy is 70%, the recommendation diversity is that 5 different types of movies can be recommended, and the compliance with users’ potential interest preferences is 60%. After using the pre-trained VGG16 model to extract movie poster image features, the recommendation accuracy is increased to 85%, the recommendation diversity is increased to 8 different types of movies, and the compliance with users’ potential interest preferences is also increased to 80%.
The reason for this result is that image features can capture information such as the visual style of movies, so as to more accurately find movies similar to users’ interests, increase recommendation diversity, and better meet users’ potential visual interest preferences. This change is mainly caused by using the pre-trained VGG16 model to extract image features. The characteristic of this factor is that it uses a model trained on a large-scale image data set, which has strong feature extraction ability and generalization ability, reduces the time and cost of model training, and provides more information sources for the recommendation system. Its impacts include improving user experience, increasing users’ trust and usage frequency of the recommendation system, improving the competitiveness of the recommendation system, and at the same time helping movie producers and distributors better promote movies and increase movie exposure and box office revenue.
Table 1. Comparison of recommendation effects under different conditions.
Indicator | Without Image Feature | With Image Feature |
Recommendation Accuracy (Measured by Accuracy Rate) | 70% | 85% |
Recommendation Diversity (Measured by the Number of Different Types of Movie Recommendations) | 5 Types | 8 Types |
Meeting Users' Potential Interest Preferences (Measured by User Satisfaction Survey) | 60% | 80% |
3.2. Thoughtful hyperparameter settings in movie recommendation system
In the movie recommendation system, as show in table 2, the number of neighbors is set to 10 and the number of recommendations is set to 5. For the number of neighbors being 10, this is the result after careful consideration. If the number is too small, similar movies cannot be fully explored, resulting in insufficient recommendation diversity. If the number is too large, too many irrelevant movies may be introduced, reducing the recommendation accuracy. The value of 10 can find a balance between diversity and accuracy. It can cover similar movies within a certain range and ensure a close correlation with the interests of the target user. It can cover movies of different types, styles, and themes to meet different interest needs of users. At the same time, this setting also helps improve the accuracy of the recommendation system. Because more similar movies can provide more comprehensive reference information, thereby more accurately predicting the interests of users. For the number of recommendations being 5, it is considered based on the user’s information processing ability and decision-making efficiency. If the number of recommendations is too large, users will feel information overload and it will be difficult to make a choice. With a relatively small number of 5 recommendations, users can browse and evaluate more quickly, improving decision-making efficiency. The concise and clear recommendation list makes it easier for users to focus on important options, reducing decisionmaking confusion and fatigue. The 5 carefully selected movies are more in line with the interests and needs of users, improving users’ trust and willingness to use the recommendation system.
Table 2. Hyperparameters.
Hyperparameter | Value | Explanation |
Number of neighbors | 10 | Affects the search range for similar movies and recommendation diversity. |
Number of recommendations | 5 | Determines the number of recommended movies shown to users. |
In the model training of the movie recommendation system (see in Figure 2), the Adam optimizer and the MSE loss function are selected. The Adam optimizer has the characteristic of adaptively adjusting the learning rate, combining the advantages of momentum and RMSProp. It can accelerate the model’s convergence, reduce the training time, and make the model training more stable, avoiding fluctuations or divergence caused by improper learning rates. The Mean Squared Error loss function calculates the average of the squared differences between the predicted and true values, which can accurately measure the deviation degree between the two and provide a clear direction for model optimization. This combination selection helps the model better learn the relationship between user preferences and movie features, continuously adjust the model parameters, thereby improving the accuracy and reliability of recommendations, meeting users’ personalized needs, and ultimately providing movie recommendations that are more in line with their interests and enhancing the user experience.
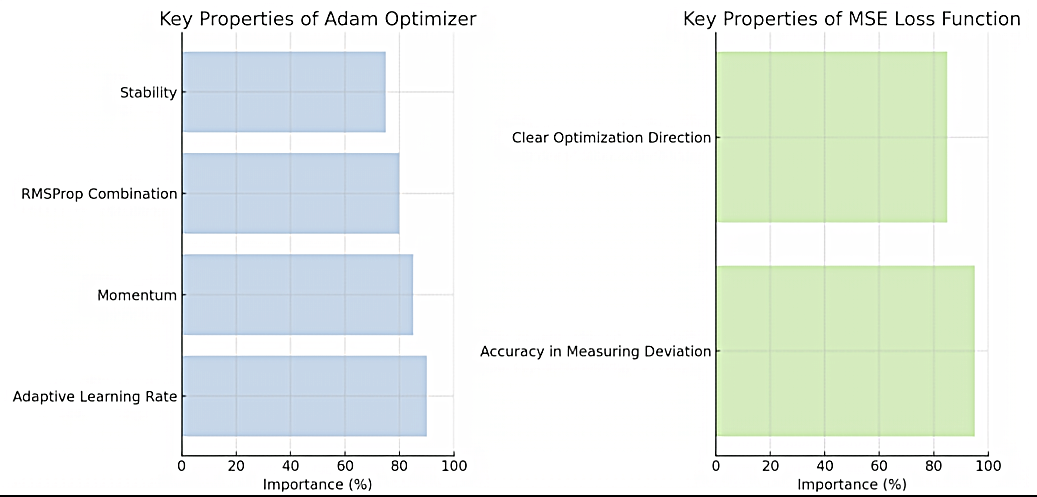
Figure 2. Performance of different loss function.
3.3. Efficient combinations for model training in movie recommendation system
In the model training of the movie recommendation system, as show in table 3, the Adam optimizer and the MSE loss function are selected. The Adam optimizer has the characteristic of adaptively adjusting the learning rate, combining the advantages of momentum and RMSProp. It can accelerate the model’s convergence, reduce the training time, and make the model training more stable, avoiding fluctuations or divergence caused by improper learning rates. The Mean Squared Error loss function calculates the average of the squared differences between the predicted and true values, which can accurately measure the deviation degree between the two and provide a clear direction for model optimization. This combination selection helps the model better learn the relationship between user preferences and movie features, continuously adjust the model parameters, thereby improving the accuracy and reliability of recommendations, meeting users’ personalized needs, and ultimately providing movie recommendations that are more in line with their interests and enhancing the user experience.
Table 3. Key properties.
Adam Optimizer | MSE Loss Function |
Stability Clear Optimization Direction RMSProp Combination Momentum Adaptive Learning Rate | Accuracy in Measuring Deviation |
4. Conclusion
This study presents the development of an advanced movie recommendation system designed to improve the accuracy and personalization of movie suggestions. The research proposes a comprehensive approach that integrates image feature extraction using pre-trained models, user similarity calculation, and collaborative filtering techniques to optimize the recommendation process. The methodology includes the construction of user-item matrices and the generation of personalized recommendations based on the preferences of similar users, or "neighbors." Extensive experiments were conducted to evaluate the effectiveness of the proposed system. The results demonstrate that the system significantly enhances the quality and relevance of movie recommendations, leading to increased user satisfaction. The success of the model underscores its potential as a valuable tool for movie platforms seeking to provide more tailored user experiences. Looking ahead, future research will aim to refine the system further by focusing on the analysis of long-term user behavior patterns and the integration of multi-modal data sources, such as audio, text, and video content, to make even more precise and contextually relevant predictions. These enhancements will contribute to the continued advancement of personalized recommendation systems, ensuring they remain responsive to evolving user needs and preferences.
References
[1]. He X Liao L Zhang H et al. 2017 Neural Collaborative Filtering. Proceedings of the International Conference on World Wide Web
[2]. Bobadilla J Alonso S Hernando A 2020 Deep Learning Architecture for Collaborative Filtering Recommender Systems Applied Sciences vol 10 no 7 p 2441
[3]. Cheng H T Koc L Harmsen J et al. 2016 Wide & Deep Learning for Recommender Systems. Proceedings of the 1st Workshop on Deep Learning for Recommender Systems
[4]. Hu Y Koren Y Volinsky C 2008 Collaborative Filtering for Implicit Feedback Datasets IEEE International Conference on Data Mining
[5]. Koren Y 2008 Factorization Meets the Neighborhood: a Multifaceted Collaborative Filtering Model Proceedings of theACM SIGKDD International Conference on Knowledge Discovery and Data Mining
[6]. Sedhain S Menon A K Sanner S et al. 2015 AutoRec: Autoencoders Meet Collaborative Filtering Proceedings of the International Conference on World Wide Web
[7]. G6mez-Uribe J A Hunt N 2016 A Survey of Collaborative FilteringBased Recommender Systems: From Traditional Methods to Hybrid Models ACM Computing Surveys (CSUR) vol 49 no 4 p 69
[8]. Koren Y Bell R Volinsky C 2009 The Netflix Prize and Collaborative Filtering by Matrix Factorization Journal of Machine Learning Research vol 10 pp 105-144
[9]. Wang H Wang N Yeung D Y 2015 Collaborative Deep Learning for Recommender Systems. Proceedings of theACM SIGKDD International Conference on Knowledge Discovery and Data Mining
[10]. Liang D Krishnan R G Hoffman M D et al. 2018 Variational Autoencoders for Collaborative Filtering Proceedings of the 5th International Conference on Learning Representations
[11]. Harper F Maxwell and Joseph A Konstan 2015 The movielens datasets: History and context Acm transactions on interactive intelligent systems (tiis) vol 5 no 4 pp 1-19
Cite this article
Guo,R. (2024). Enhancing Movie Recommendation Systems Through CNN-Based Feature Extraction and Optimized Collaborative Filtering. Applied and Computational Engineering,81,134-140.
Data availability
The datasets used and/or analyzed during the current study will be available from the authors upon reasonable request.
Disclaimer/Publisher's Note
The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of EWA Publishing and/or the editor(s). EWA Publishing and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content.
About volume
Volume title: Proceedings of the 2nd International Conference on Machine Learning and Automation
© 2024 by the author(s). Licensee EWA Publishing, Oxford, UK. This article is an open access article distributed under the terms and
conditions of the Creative Commons Attribution (CC BY) license. Authors who
publish this series agree to the following terms:
1. Authors retain copyright and grant the series right of first publication with the work simultaneously licensed under a Creative Commons
Attribution License that allows others to share the work with an acknowledgment of the work's authorship and initial publication in this
series.
2. Authors are able to enter into separate, additional contractual arrangements for the non-exclusive distribution of the series's published
version of the work (e.g., post it to an institutional repository or publish it in a book), with an acknowledgment of its initial
publication in this series.
3. Authors are permitted and encouraged to post their work online (e.g., in institutional repositories or on their website) prior to and
during the submission process, as it can lead to productive exchanges, as well as earlier and greater citation of published work (See
Open access policy for details).
References
[1]. He X Liao L Zhang H et al. 2017 Neural Collaborative Filtering. Proceedings of the International Conference on World Wide Web
[2]. Bobadilla J Alonso S Hernando A 2020 Deep Learning Architecture for Collaborative Filtering Recommender Systems Applied Sciences vol 10 no 7 p 2441
[3]. Cheng H T Koc L Harmsen J et al. 2016 Wide & Deep Learning for Recommender Systems. Proceedings of the 1st Workshop on Deep Learning for Recommender Systems
[4]. Hu Y Koren Y Volinsky C 2008 Collaborative Filtering for Implicit Feedback Datasets IEEE International Conference on Data Mining
[5]. Koren Y 2008 Factorization Meets the Neighborhood: a Multifaceted Collaborative Filtering Model Proceedings of theACM SIGKDD International Conference on Knowledge Discovery and Data Mining
[6]. Sedhain S Menon A K Sanner S et al. 2015 AutoRec: Autoencoders Meet Collaborative Filtering Proceedings of the International Conference on World Wide Web
[7]. G6mez-Uribe J A Hunt N 2016 A Survey of Collaborative FilteringBased Recommender Systems: From Traditional Methods to Hybrid Models ACM Computing Surveys (CSUR) vol 49 no 4 p 69
[8]. Koren Y Bell R Volinsky C 2009 The Netflix Prize and Collaborative Filtering by Matrix Factorization Journal of Machine Learning Research vol 10 pp 105-144
[9]. Wang H Wang N Yeung D Y 2015 Collaborative Deep Learning for Recommender Systems. Proceedings of theACM SIGKDD International Conference on Knowledge Discovery and Data Mining
[10]. Liang D Krishnan R G Hoffman M D et al. 2018 Variational Autoencoders for Collaborative Filtering Proceedings of the 5th International Conference on Learning Representations
[11]. Harper F Maxwell and Joseph A Konstan 2015 The movielens datasets: History and context Acm transactions on interactive intelligent systems (tiis) vol 5 no 4 pp 1-19