







1. Introduction
Target detection is a fundamental area within computer vision, focused on the identification and localization of objects in visual data, such as images or videos. This capability is critical across various domains, including autonomous driving, medical imaging, surveillance, and robotics. The significance of target detection stems from its ability to improve the interpretation of visual information, which facilitates real-time decision-making and enhances automation processes. With the continuous progression of technology, there is a growing need for highly accurate and efficient target detection systems. This demand has spurred significant research and development efforts. This paper provides a comprehensive overview of target detection methods, exploring their underlying principles, structural frameworks, applications, and potential future directions.
The landscape of target detection has experienced substantial evolution, moving from traditional methods to modern approaches driven by deep learning. Initial techniques, such as edge detection, template matching, and feature extraction, set the foundation for more sophisticated methods. The introduction of deep learning has dramatically transformed the field, giving rise to powerful models like Convolutional Neural Networks (CNN), Region-based Convolutional Neural Networks (R-CNN), You Only Look Once (YOLO), and Single Shot MultiBox Detector (SSD). These innovations have markedly enhanced the precision of object detection processes.
The R-CNN model, initially developed by Girshick et al., represented a breakthrough by significantly boosting object localization and classification accuracy through the use of CNN to generate region proposals from images [1]. Fast R-CNN, a subsequent evolution of R-CNN, further optimized the process by merging region proposal generation and classification into a single network, thereby improving speed and efficiency [2]. Building upon these advancements, Faster R-CNN introduced Region Proposal Networks (RPN) to automate the generation of region proposals, achieving near real-time object detection performance [3].
A major shift in the field was introduced with YOLO, a model designed by Redmon et al., marked a significant turning point in object detection by framing the task as a regression problem. This approach enabled the model to predict bounding boxes and class probabilities directly from entire images in a single step [4,5]. This innovative approach led to significant gains in efficiency, making it particularly well-suited for real-time use. Similarly, the SSD model proposed a unified framework for detecting objects at various scales, balancing the need for speed with accuracy [6]. Recent progress in the field includes the development of RetinaNet, which introduced focal loss to manage class imbalance more effectively, reaching leading performance levels in dense object detection scenarios [7]. Another key development is Mask R-CNN, which builds upon Faster R-CNN by adding a component to predict segmentation masks, thereby enabling instance segmentation [8]. EfficientDet, a scalable and efficient object detection model, has also emerged as a leading approach by optimizing both accuracy and computational demands [9].
This study provides an in-depth analysis of the current advancements in target detection [10], with a focus on several key areas: 1) an in-depth review and summary of the foundational concepts and background relevant to target detection; 2) a critical analysis of the core technologies that underpin modern target detection methods, including their principles and underlying frameworks; 3) a comparative evaluation of the experimental performance of major detection techniques; 4) an assessment of the strengths and weaknesses of these technologies, alongside a discussion on their future development prospects and potential applications; and 5) a conclusion that synthesizes the findings and offers an outlook on the field's trajectory.
The importance of this research lies in its potential to shape the future direction of target detection, offering valuable insights for both academic inquiry and practical implementation. The paper is structured as follows: Chapter 2 explores the fundamental concepts and principles of target detection methods; Chapter 3 provides a detailed analysis of experimental results; and Chapter 4 concludes with a summary of key findings and a discussion of future directions in the field.
2. Methodology
2.1. Dataset description and preprocessing
Choosing the appropriate datasets and their preprocessing is a fundamental step in object detection research. This study reviews popular datasets, particularly highlighting their sources, contents, intended uses, and preprocessing methods. The Common Objects in Context (COCO) dataset [11], widely adopted in the research community for assessing object detection models, consists of over 200,000 images labeled across 80 different object categories. It provides an extensive benchmark for evaluating model performance in realistic scenarios. Preprocessing for the COCO dataset typically involves resizing images to a standardized format (e.g., 512x512 pixels), normalizing pixel intensities, and applying various data augmentation techniques like flipping, rotation, and scaling to ensure robustness and generalizability in the training process.
2.2. Proposed approach
This study examines the strengths and limitations of different object detection models, focusing on CNN, R-CNN, and YOLO. The proposed approach begins with data preprocessing, followed by feature extraction using a CNN-based backbone. The extracted features are subsequently fed into either R-CNN or YOLO modules, depending on the specific model configuration, to generate object detection predictions. This pipeline, as depicted in Figure 1, showcases the step-by-step processing of data through various phases, each contributing to the model's overall accuracy and efficiency. By integrating CNN with advanced detection frameworks like R-CNN and YOLO, this study provides an in-depth evaluation of these models, emphasizing their distinct advantages in handling diverse object detection challenges.
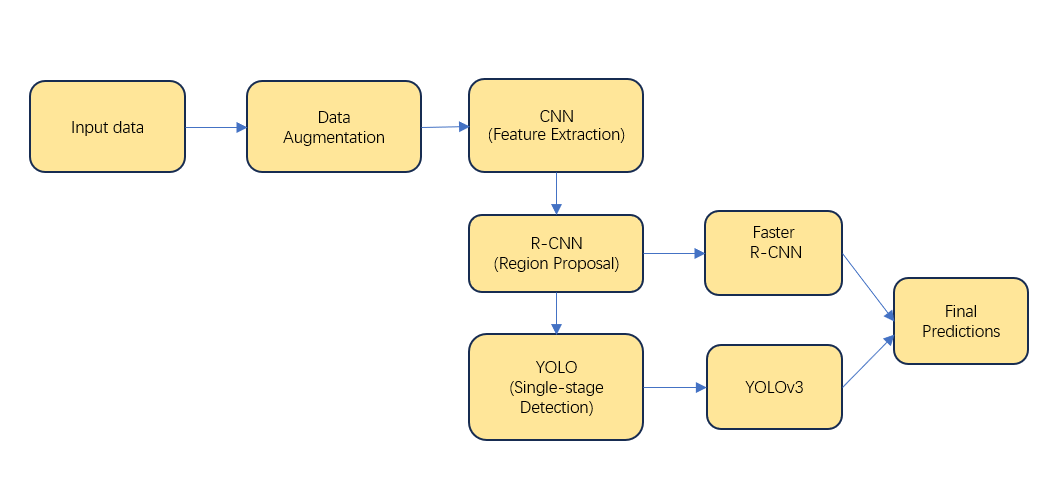
Figure 1. The pipeline of the study.
2.2.1. CNNs. CNN are a foundational element in contemporary object detection systems, recognized for their exceptional ability to learn and represent complex hierarchical features from visual data. CNN are particularly effective at capturing spatial hierarchies within images, ranging from simple edge detection to recognizing complex semantic structures, which are crucial for accurate object recognition. In this research, the ResNet50 architecture is utilized, a deep neural network composed of 50 layers that incorporates residual connections. These connections help in mitigating the vanishing gradient problem, thus enabling the training of deeper, more robust networks [12]. The features extracted by ResNet50 are essential for the subsequent detection stages, as they provide a rich and detailed representation of the input data.
The CNN backbone processes input images through several convolutional layers. Each convolutional layer is usually followed by a pooling layer and nonlinear activation functions, such as Rectified Linear Unit (ReLU), to introduce complexity and enhance the model's ability to learn intricate patterns. These operations produce feature maps that serve as input to object detection modules such as R-CNN or YOLO, which further refine and interpret the detection results. The layered structure of CNN allows them to detect objects across various scales, making them indispensable for challenging detection tasks.
2.2.2. R-CNN. R-CNNs object detection by introducing an innovative approach by introducing a novel method that integrates region proposal generation with object classification. The initial R-CNN model employed an algorithm that selectively identifies regions of interest, which are then fed into a CNN to extract features for object classification and adjust their bounding boxes for accuracy. This method, however, was computationally intensive because a CNN had to be run independently on each proposed region [13].
To mitigate these computational challenges, Fast R-CNN and Faster R-CNN were developed. Fast R-CNN streamlined the process by integrating region proposal generation and classification within a single network (see in Figure 2), greatly reducing computational time [2]. Building on this, Faster R-CNN incorporated RPNs, which generate region proposals as an integral part of the network, allowing for end-to-end training [3]. In this study, Faster R-CNN is chosen for its ability to balance detection speed and accuracy. The CNN backbone (e.g., ResNet50) extracts features from the entire image, which are then used by the RPN to generate region proposals. These proposals are subsequently classified and refined to produce the final detection outcomes.
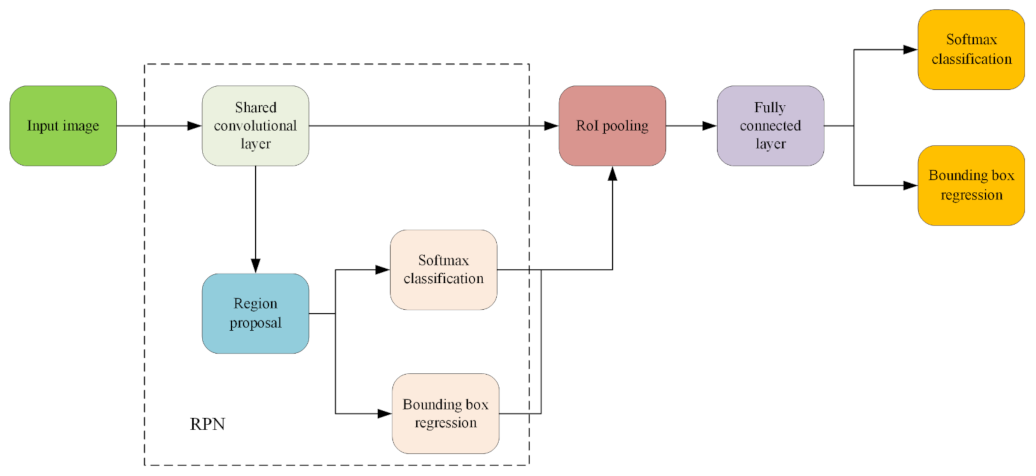
Figure 2. Basic network framework of faster R-CNN.
2.2.3. YOLO. The YOLO model introduces a unique approach to object detection, treating the task as a single regression problem. Unlike multi-stage models like R-CNN, YOLO analyzes the entire image in a single pass, simultaneously generating predictions for bounding boxes and class probabilities. This design allows YOLO to achieve real-time detection speeds, which is particularly beneficial for applications like live surveillance.
YOLO partitions the input image into a grid and, for each section, generates a specific number of bounding box predictions along with their respective class scores. The one-stage detection process of YOLO results in exceptionally fast performance, although it might sacrifice some accuracy when compared to more intricate, multi-stage models such as Faster R-CNN. In this research, the YOLOv3 model is utilized, which offers improvements over previous iterations by employing a deeper network (Darknet-53) and incorporating multi-scale predictions, enhancing its capacity to detect smaller objects. YOLOv3 processes the feature maps obtained from the CNN backbone in a single forward pass (see in Figure 3), balancing the need for speed with a reasonable level of detection accuracy.
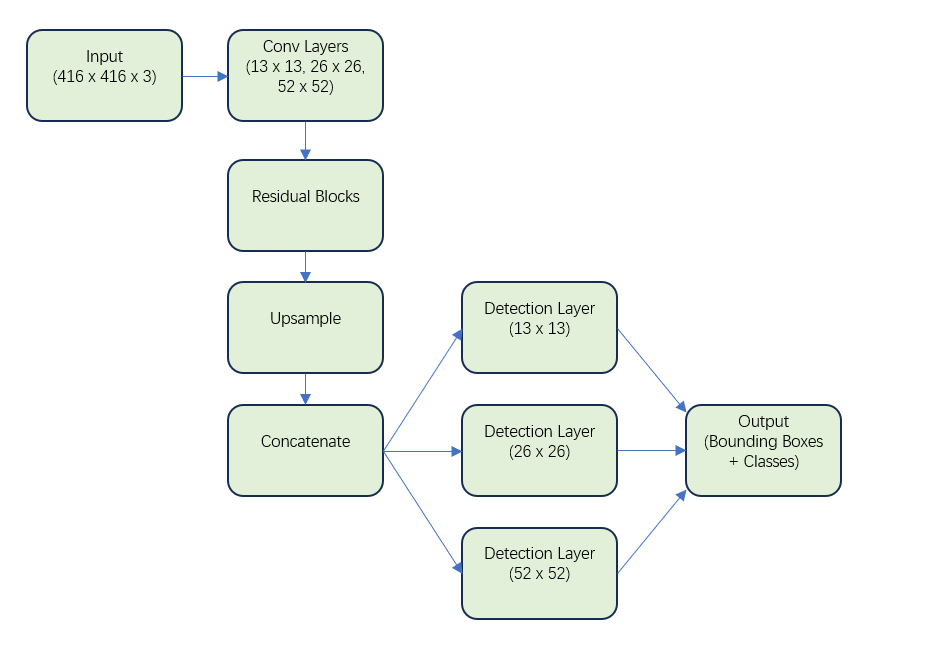
Figure 3. The network of YOLOv3.
3. Result and Discussion
3.1. Analysis of results
The performance of various object detection algorithms as presented in table 1 demonstrates significant variations in accuracy as measured by the mean Average Precision (mAP). Notably, YOLOv3 shows a marked improvement over its predecessor, YOLOv2, indicating advancements in the model's architecture that enhance its detection capabilities.
Table 1. Performance comparison of object detection models.
No | Algorithm | Input | mAP |
1 | YOLO | 448 | 66.4% |
2 | YOLOv2 | 416 | 76.8% |
3 | Faster RCNN | 512 | 73.2% |
4 | SSD | 513 | 79.8% |
5 | DSSD | 513 | 81.5% |
6 | YOLOv3 | 416 | 79.26% |
The data shows that YOLOv3's mAP is 79.26%, positioning it competitively among other high-performance models like SSD and Deconvolutional Single Shot Detector (DSSD). Despite operating with a smaller input dimension similar to YOLOv2, YOLOv3 demonstrates efficient use of computational resources without substantially compromising detection quality. The enhancements in YOLOv3, particularly in handling varying object sizes through its multi-scale predictions, likely contribute to its improved mAP. Even with a smaller input size compared to models like SSD and DSSD, YOLOv3 achieves close performance levels, underscoring its efficiency and robust design.
3.2. Discussion of methodological insights and future directions
The comparison of these object detection models provides crucial insights into the trade-offs between input resolution, computational efficiency, and accuracy. Models with larger input sizes, such as SSD and DSSD, tend to achieve higher accuracy but may require more computational resources, which could limit their deployment in real-time applications. YOLOv3’s balance between input size and accuracy makes it an attractive option for applications needing fast and reasonably accurate detections. Its ability to maintain high accuracy with relatively lower input resolution highlights the potential for optimizations that do not overly tax computational resources.
Future research could explore further enhancements in the architecture of models like YOLOv3, particularly in optimizing the trade-offs between speed, accuracy, and computational demands. Innovations in network design, such as the integration of more efficient convolutional operations or advanced training techniques like automated machine learning (AutoML), could lead to more robust models capable of operating under a broader range of conditions and applications. Moreover, exploring hybrid approaches that combine the strengths of two-stage detector and one-stage detectors (like YOLO for their speed) could yield models that are both fast and highly accurate—a significant advancement for critical applications such as autonomous driving and real-time anomaly detection in security systems.
In conclusion, while current technologies have achieved remarkable successes, the continuous evolution of object detection algorithms will likely unlock new capabilities and applications, pushing the boundaries of what is computationally feasible and practically applicable in various domains.
4. Conclusion
This study provides a deep exploration into the rapidly evolving field of target detection, a crucial element of computer vision. The research focused on the analysis and synthesis of the latest methodologies and technologies that drive modern object detection systems. A thorough examination of key detection models, particularly CNN, R-CNN and YOLO, was conducted to elucidate their operational mechanisms and performance metrics. The study involved an extensive review and practical evaluation of state-of-the-art object detection models using the COCO dataset. The findings demonstrate that YOLOv3, despite its lower input resolution, performs competitively in terms of mAP when compared to models with higher resolutions, highlighting significant advancements in both efficiency and design. The extensive experiments conducted confirmed that improvements in multi-scale processing and network architecture have notably enhanced detection accuracy and speed. Looking ahead, future research will focus on further improving the computational efficiency and accuracy of detection models. This will involve integrating and refining techniques such as network pruning and advanced convolutional methods to develop more streamlined models capable of faster processing times without compromising accuracy.
References
[1]. Girshick R Donahue J Darrell T & Malik J 2014 Rich feature hierarchies for accurate object detection and semantic segmentation In Proceedings of the IEEE conference on computer vision and pattern recognition pp 580-587
[2]. Girshick R 2015 Fast R-CNN In Proceedings of the IEEE international conference on computer vision pp 1440-1448
[3]. Ren S He K Girshick R & Sun J 2015 Faster R-CNN: Towards real-time object detection with region proposal networks In Advances in neural information processing systems vol 39 no 6 pp 91-99
[4]. Redmon J Divvala S Girshick R & Farhadi A 2016 You Only Look Once: Unified, Real-Time Object Detection In Proceedings of the IEEE conference on computer vision and pattern recognition pp 779-788
[5]. Redmon J & Farhadi A 2018 YOLOv3: An Incremental Improvement arXiv preprint:1804.02767
[6]. Liu W Anguelov D Erhan D Szegedy C Reed S Fu C Y & Berg A C 2016 SSD: Single Shot MultiBox Detector In European conference on computer vision pp 21-37
[7]. Lin T Y Goyal P Girshick R He K & Dollar P 2017 Focal Loss for Dense Object Detection In Proceedings of the IEEE international conference on computer vision pp 2980-2988
[8]. He K Gkioxari G Dollar P & Girshick R 2017 Mask R-CNN In Proceedings of the IEEE international conference on computer vision pp 2961-2969
[9]. Tan M Pang R & Le Q V 2020 EfficientDet: Scalable and Efficient Object Detection In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition pp 10781-10790
[10]. Zou Z Shi Z Guo Y & Ye J 2023 Object detection in 20 years: A survey Proceedings of the IEEE vol 111 no 3 pp 257-276
[11]. Lin T Y Maire M Belongie S Hays J Perona P Ramanan D & Zitnick C L 2014 Microsoft COCO: Common objects in context In European conference on computer vision pp 740-755
[12]. He K Zhang X Ren S & Sun J 2016 Deep residual learning for image recognition In Proceedings of the IEEE conference on computer vision and pattern recognition pp 770-778
[13]. Girshick R Donahue J Darrell T & Malik J 2014 Rich feature hierarchies for accurate object detection and semantic segmentation In Proceedings of the IEEE conference on computer vision and pattern recognition pp 580-587
Cite this article
Qin,T. (2024). Advancements in Target Detection: A Comparative Analysis of Deep Learning Models for Real-Time Applications. Applied and Computational Engineering,81,141-147.
Data availability
The datasets used and/or analyzed during the current study will be available from the authors upon reasonable request.
Disclaimer/Publisher's Note
The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of EWA Publishing and/or the editor(s). EWA Publishing and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content.
About volume
Volume title: Proceedings of the 2nd International Conference on Machine Learning and Automation
© 2024 by the author(s). Licensee EWA Publishing, Oxford, UK. This article is an open access article distributed under the terms and
conditions of the Creative Commons Attribution (CC BY) license. Authors who
publish this series agree to the following terms:
1. Authors retain copyright and grant the series right of first publication with the work simultaneously licensed under a Creative Commons
Attribution License that allows others to share the work with an acknowledgment of the work's authorship and initial publication in this
series.
2. Authors are able to enter into separate, additional contractual arrangements for the non-exclusive distribution of the series's published
version of the work (e.g., post it to an institutional repository or publish it in a book), with an acknowledgment of its initial
publication in this series.
3. Authors are permitted and encouraged to post their work online (e.g., in institutional repositories or on their website) prior to and
during the submission process, as it can lead to productive exchanges, as well as earlier and greater citation of published work (See
Open access policy for details).
References
[1]. Girshick R Donahue J Darrell T & Malik J 2014 Rich feature hierarchies for accurate object detection and semantic segmentation In Proceedings of the IEEE conference on computer vision and pattern recognition pp 580-587
[2]. Girshick R 2015 Fast R-CNN In Proceedings of the IEEE international conference on computer vision pp 1440-1448
[3]. Ren S He K Girshick R & Sun J 2015 Faster R-CNN: Towards real-time object detection with region proposal networks In Advances in neural information processing systems vol 39 no 6 pp 91-99
[4]. Redmon J Divvala S Girshick R & Farhadi A 2016 You Only Look Once: Unified, Real-Time Object Detection In Proceedings of the IEEE conference on computer vision and pattern recognition pp 779-788
[5]. Redmon J & Farhadi A 2018 YOLOv3: An Incremental Improvement arXiv preprint:1804.02767
[6]. Liu W Anguelov D Erhan D Szegedy C Reed S Fu C Y & Berg A C 2016 SSD: Single Shot MultiBox Detector In European conference on computer vision pp 21-37
[7]. Lin T Y Goyal P Girshick R He K & Dollar P 2017 Focal Loss for Dense Object Detection In Proceedings of the IEEE international conference on computer vision pp 2980-2988
[8]. He K Gkioxari G Dollar P & Girshick R 2017 Mask R-CNN In Proceedings of the IEEE international conference on computer vision pp 2961-2969
[9]. Tan M Pang R & Le Q V 2020 EfficientDet: Scalable and Efficient Object Detection In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition pp 10781-10790
[10]. Zou Z Shi Z Guo Y & Ye J 2023 Object detection in 20 years: A survey Proceedings of the IEEE vol 111 no 3 pp 257-276
[11]. Lin T Y Maire M Belongie S Hays J Perona P Ramanan D & Zitnick C L 2014 Microsoft COCO: Common objects in context In European conference on computer vision pp 740-755
[12]. He K Zhang X Ren S & Sun J 2016 Deep residual learning for image recognition In Proceedings of the IEEE conference on computer vision and pattern recognition pp 770-778
[13]. Girshick R Donahue J Darrell T & Malik J 2014 Rich feature hierarchies for accurate object detection and semantic segmentation In Proceedings of the IEEE conference on computer vision and pattern recognition pp 580-587