







1. Introduction
Numerous industries, including artificial intelligence, finance, and healthcare, are being impacted by machine learning. Machine learning has evolved to handle the massive volumes of data generated in the current digital era, after initially focusing on small-scale data and straightforward algorithms. This shift has necessitated a change of more complicated models capable of real time data processing, leading to the rise of distributed and parallel machine learning approaches [1]. With datasets continuing to grow, these methods address the increasing need for processing power and efficiency. Distributed machine learning, which spreads data and computation across multiple machines, makes it possible to process larger datasets than would be feasible on a single machine. This method is particularly beneficial in scenarios where data is too large to be stored on a single server or when privacy concerns dictate that data remains decentralized [2]. In contrast, tasks in parallel machine learning are divided into smaller, independent units that can be processed in parallel. This approach reduces computation time and enhances efficiency, making it ideal for high-performance computing environments [3].
Recent developments in parallel and distributed machine learning have greatly expanded their use to include a variety of fields. In the case of distributed machine learning, has played a key role in creating federated learning, a framework that permits multiple entities to collaboratively train models without sharing raw data [4]. This strategy has become more popular, especially in fields where protecting data privacy is crucial important fields, like finance and healthcare. Parallel machine learning has seen widespread adoption in environments requiring high computational efficiency, such as the training of deep neural networks. Techniques like model parallelism and data parallelism have become standard practices in large-scale machine learning projects, reducing the time and resources needed to train complex models [5]. These developments underscore the increasing relevance of both distributed and parallel machine learning in handling the demands of modern data-driven applications.
The motivation behind this study is to provide a comprehensive comparison between distributed and parallel machine learning, focusing on their efficiency and effectiveness in processing large-scale data. By exploring the strengths and limitations of each approach, this paper aims to offer insights into their respective suitability for various applications. This essay follows the following format. In Section 2, a list of well-liked machine learning models for distributed and parallel approaches is provided. After Section 3 examines the ideas and jargon of distributed machine learning, Section 4 discusses parallel machine learning. Case studies and visual aids are used in Section 5 to compare and contrast the two approaches. The paper's conclusion, a summary of the findings and their implications, and the limitations and possible uses of these approaches are finally covered in Section 6. Section 7 also covers these topics.
2. ML models
Machine learning models form the backbone of distributed and parallel machine learning systems. They are categorized based on their functionality and the specific tasks they address. This section provides an overview of common machine learning models, highlighting their applications and key features. Supervised learning models are trained on labeled data, where the model learns to map inputs to the correct outputs. Common examples include:
• Linear Regression: This model predicts a continuous output variable based on one or more input features. It assumes a linear relationship between inputs and outputs, making it simple yet effective for many problems.
• Support Vector Machines (SVMs): SVMs are used for classification tasks, working by finding the optimal hyperplane that maximizes the margin between different classes. They are particularly effective in high-dimensional spaces and are used for tasks such as text classification and image recognition.
Unsupervised learning models identify patterns and structures in data without pre-existing labels. Notable examples include:
• K-Means Clustering: K-Means partitions data into k clusters by minimizing intra-cluster variance. It is useful for tasks such as customer segmentation and anomaly detection [6].
• Principal Component Analysis (PCA): PCA reduces dimensionality by transforming data into orthogonal components that capture the most variance. It is commonly used for data preprocessing and visualization [7].
Neural networks, especially deep learning models, have become essential for handling large-scale and complex data. Key models include:
• Convolutional Neural Networks (CNNs): CNNs are designed for processing grid-like data such as images, using convolutional layers to learn hierarchical features. They are highly effective for image classification and object detection [8].
• Recurrent Neural Networks (RNNs): RNNs are used for sequential data by maintaining a memory of previous inputs. They are widely applied in natural language processing and time-series prediction [9].
Reinforcement learning models learn to make decisions through interactions with an environment. Key examples include:
Q-Learning: This value-based algorithm learns the value of actions in states to maximize cumulative rewards. It is used in various applications such as robotics and game playing [10].
Deep Q-Networks (DQNs): DQNs extend Q-Learning by using deep neural networks to approximate Q-values, enabling the handling of complex tasks such as playing Atari games [10].
3. Descriptions of distributed ML
To handle large-scale data processing, a framework known as distributed machine learning (DML) distributes computational tasks among multiple machines, or nodes. This kind of approach is necessary to properly manage the massive volumes of data generated in today's digital world. Due to its ability to leverage parallelism for scalability and speed up model training, DML is a powerful tool for a wide range of applications. Distributed machine learning involves the partitioning of data and computational tasks across a network of machines to handle large-scale datasets that cannot be processed on a single machine. The core idea is to break down the computation into smaller tasks that can be executed in parallel, thereby speeding up the learning process and reducing the time required for training complex models [2].
Subsets of data are dispersed among various nodes in a distributed machine learning system. Processing a portion of the data, each node adds to the overall learning task. The synchronization of models and the aggregation of results are made easier by the ability to connect these nodes via a communication network. The distributed nature of the system allows for the handling of larger datasets and more complex models than what would be feasible on a single machine [10].
A number of fundamental ideas, such as synchronization, model parallelism, and data parallelism, support distributed machine learning:
• Data Parallelism: This refers to the distribution of data among several nodes, each of which stores a portion of the data and carries out computations on its own. The global model is then updated by averaging the output from these nodes. This approach is effective for large datasets, as it allows the system to process data in parallel and speed up training [8].
• Model Parallelism: The division of the model among several nodes is known as model parallelism. Computations are carried out in parallel, with each node handling a portion of the model. Large models that are too big to fit in a single machine's memory can benefit from this technique. Model parallelism requires efficient communication between nodes to ensure that the model parameters are updated correctly [9].
• Synchronization: Synchronization is crucial for ensuring consistency across distributed nodes. Techniques such as synchronous and asynchronous updates are employed to coordinate the learning process. In synchronous updates, all nodes synchronize and update the model parameters together, ensuring consistency but potentially introducing delays. In asynchronous updates, nodes update the model parameters independently, which can speed up training but may lead to inconsistencies [2].
Distributed machine learning has been applied across various domains, including large-scale image and text processing, recommendation systems, and natural language processing. For instance, federated learning, a subset of distributed machine learning, has been employed to train models across decentralized devices while preserving data privacy [11]. Despite its advantages, distributed machine learning presents several challenges. These include managing the communication overhead between nodes, handling failures and inconsistencies, and ensuring efficient utilization of resources. Addressing these challenges requires advanced algorithms and system designs to optimize performance and scalability [12].
4. Descriptions of parallel ML
Parallel machine learning (ML) is a type of deep ML frame, the main idea is to separate a big mission in to several small mission then simultaneously calculates them. Parallel machine learning mostly use a Python environment, it contains different python package such as NumPy, Panda, and Scikit-Learn. The definition of Distributed parallel machine learning (ML), it’s based on using one CPU to run the missions breaks from a large mission. Which is mean using multiply CPUs to run a parallel ML can also implement the distributed ML. There are several principles that parallel machine learning is using, there are Data Parallelism, Model Parallelism, Hybrid Parallelism, Synchronization Techniques, and Communication Overheads. Data parallelism which is mean to separate the dataset into more small pieces and then distribute these data across multiple processors. For each processor they will train their own part and then combines the results. A typical structure is shown in Fig. 1 [11].
When a model is too large to fit into the memory of a single processor, one divides the model itself to make sure it will fit in to each processor, in this way each processor will handle a different part of the model, so the datasets must go passed between the processors. Using the both data and model parallelism and combine their benefits. Using data parallelism in each partition of the model and the model is used across partition, this needs a really careful management of both data and model synchronization. It’s integrated from different processors such as Parameter Server, it’s a central server that will update the model parameters while when the processors upload the gradients. One needs to minimize the time spent on communication between processors to ensure efficient parallel processing. For example, Gradient Compression: reduces the amount of data sent between processors by compressing gradients. The Parallel ML has ability to handle a large dataset and improve the computational, the major applications of parallel ML is distributed deep learning. Makes the multiply multiple GPUs or machines work together to train complex models. This approach allows for faster convergence and better performance on tasks like image and speech recognition [11]. However, challenges remain, such as communication overhead and synchronization issues, which can hinder scalability and efficiency [12].
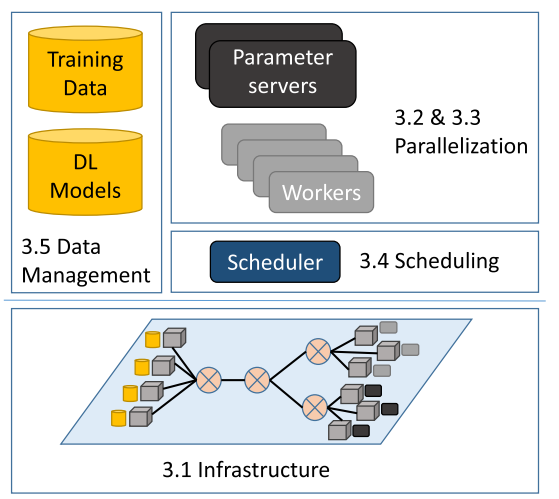
Figure 1. Typical structure for parallel ML [11].
5. Comparison distributed ML & parallel ML
Distributed ML and parallel ML are two different method that will satisfy the growing demand for efficient model training. Distributed ML leverages multiple machines to handle large datasets, allowing for improved scalability but often facing communication overhead, which can slow down training [2]. In contrast, parallel ML utilizes multiple processors within a single machine, minimizing communication delays and enhancing speed, particularly for real-time applications [13]. For instance, in scenarios involving massive datasets, distributed ML excels by managing data that exceeds single-machine memory limits, whereas parallel ML is more effective for smaller datasets requiring immediate updates [14]. Over all by knowing these differences between distributed ML and parallel ML, one can be able to use them more efficiently. Parallel ML works on a single machine and use multiple CPUs to speed up the computations, so when Parallel ML is dealing with a smaller dataset, it is usually faster than distributed ML. This is because parallel ML doesn’t need a lot of communication between the machines. Distributed ML works on multiple machines that are teamed up across a network, this means distributed ML can handle a large dataset since it connects to multiple machines [15].
6. Limitations and prospects
Numerous obstacles are currently facing machine learning. Large labeled datasets, for example, are necessary for many machine learning techniques, and obtaining and labeling these datasets can be difficult and time-consuming. Because of legal restrictions and privacy concerns, obtaining such data can be particularly challenging in industries like healthcare and finance. Overfitting is another major problem; models trained on sparse data frequently find it difficult to generalize to new cases, producing inaccurate outcomes.
However, advancements such as AutoML offer promising solutions to these challenges. AutoML can significantly reduce the model development process, making it easier for individuals, even those without extensive technical backgrounds, to create effective models. By automating essential tasks such as data preprocessing, feature selection, and hyperparameter tuning, AutoML streamlines the entire machine learning pipeline. This not only saves valuable time but also democratizes access to machine learning, allowing a broader range of users to leverage these powerful tools. Moreover, AutoML can assist in mitigating overfitting by facilitating techniques like cross-validation and regularization, helping ensure models are robust and generalizable. This capability is especially beneficial in domains where data scarcity is a concern, as it allows practitioners to make the most out of the available data. Ultimately, while challenges persist in machine learning, innovations like AutoML hold the potential to enhance efficiency and accessibility, paving the way for more innovative applications across various fields. By empowering a wider audience to engage with machine learning, one can expect to see a surge in creative solutions and advancements that address real-world problems, further driving the evolution of this dynamic field.
7. Conclusion
In conclusion, the distributed ML and parallel ML comparison has shown their benefit on training a large dataset, and the challenges they will face in the future. The distributed ML are more advantage on handling vast datasets across multiple machines specifically in the environments that is highly required privacy. In other side parallel ML use multiple CPUs in a single machine, this make the parallel ML a really nice choice to run a samller dataset. Well knowing these differce between distributed ML and parallel ML will lead the researcher get to finish the research tasks much easier and faster. As this field could be continued development in the future, distributed ML and parallel ML will be facing a data availability challenge. Getting the label dataset for machine learning could be the biggest challenge from distributed ML and parallel ML. Well anyways distributed ML and parallel ML could be transformation during the field development, they need to be adaptable to meet the needs of the field.
References
[1]. Jordan M I and Mitchell T M 2015 Machine learning: Trends perspectives and prospects Science vol 349(6245) pp 255-260
[2]. Li T, Sahu A K, Talwalkar A and Smith V 2020 Federated learning: Challenges methods and future directions IEEE Signal Processing Magazine vol 37(3) pp 50-60
[3]. Dean J and Ghemawat S 2020 MapReduce: Simplified data processing on large clusters Communications of the ACM vol 63(1) pp 107-113
[4]. Kairouz P, McMahan H B, Avent B, Bellet A, Bennis M, Bhagoji A N and Yang H 2021 Advances and open problems in federated learning Foundations and Trends in Machine Learning vol 14(1) pp 1-210
[5]. You Y, Zhang Z, Hsieh C J, Demmel J and Keutzer K 2020 Imagenet training in minutes Proceedings of the 47th International Conference on Parallel Processing pp 1-10
[6]. Jin Y, Liu X, Yang W and Jiang B 2021 An improved K-means clustering algorithm for high-dimensional data analysis Journal of Computational and Graphical Statistics vol 30(2) pp 325-338
[7]. Wu J, Xu Z and Zeng L 2022 Principal component analysis for dimensionality reduction in large-scale data IEEE Transactions on Knowledge and Data Engineering vol 34(4) pp 1301-1312
[8]. Kairouz P, McMahan H B, Avent B, Bellet A, Bennis M, Bhagoji A N and Yang H 2021 Advances and open problems in federated learning Foundations and Trends in Machine Learning vol 14(1) pp 1-210
[9]. Xu Y, Li Y and Yang L 2020 A survey on distributed machine learning IEEE Access vol 8 pp 86078-86091
[10]. Zhang X, Liu J and Li J 2021 Scalable and efficient distributed deep learning: Challenges and strategies ACM Computing Surveys vol 54(3) pp 1-35
[11]. Gao Y, Wang X and Zhou J 2021 Efficient Distributed Deep Learning with GPU Clusters Journal of Machine Learning Research vol 22 pp 1-25
[12]. Zhang L, Li H and Sun Y 2022 Challenges in Scaling Parallel Machine Learning: 12 Communication Overhead and Synchronization IEEE Transactions on Neural Networks and Learning Systems vol 33(4) pp 1552-1565
[13]. Li J, Huang Y and Zhang X 2021 Communication Costs in Distributed Machine Learning: Trade-offs and Strategies ACM Transactions on Intelligent Systems and Technology vol 12(2) pp 1-20
[14]. Kim S, Park T and Choi J 2022 Comparative Analysis of Distributed and Parallel Algorithms in Deep Learning Journal of Artificial Intelligence Research vol 75 pp 385-410
[15]. Patel R, Singh A and Kumar P 2023 Scaling Up Machine Learning: Distributed vs Parallel Frameworks IEEE Transactions on Neural Networks and Learning Systems vol 34(1) pp 23-38
Cite this article
Peng,C. (2024). Comparison of Distributed and Parallel Machine Learning: Efficiency and Effectiveness in Large-Scale Data Processing. Applied and Computational Engineering,96,175-180.
Data availability
The datasets used and/or analyzed during the current study will be available from the authors upon reasonable request.
Disclaimer/Publisher's Note
The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of EWA Publishing and/or the editor(s). EWA Publishing and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content.
About volume
Volume title: Proceedings of the 2nd International Conference on Machine Learning and Automation
© 2024 by the author(s). Licensee EWA Publishing, Oxford, UK. This article is an open access article distributed under the terms and
conditions of the Creative Commons Attribution (CC BY) license. Authors who
publish this series agree to the following terms:
1. Authors retain copyright and grant the series right of first publication with the work simultaneously licensed under a Creative Commons
Attribution License that allows others to share the work with an acknowledgment of the work's authorship and initial publication in this
series.
2. Authors are able to enter into separate, additional contractual arrangements for the non-exclusive distribution of the series's published
version of the work (e.g., post it to an institutional repository or publish it in a book), with an acknowledgment of its initial
publication in this series.
3. Authors are permitted and encouraged to post their work online (e.g., in institutional repositories or on their website) prior to and
during the submission process, as it can lead to productive exchanges, as well as earlier and greater citation of published work (See
Open access policy for details).
References
[1]. Jordan M I and Mitchell T M 2015 Machine learning: Trends perspectives and prospects Science vol 349(6245) pp 255-260
[2]. Li T, Sahu A K, Talwalkar A and Smith V 2020 Federated learning: Challenges methods and future directions IEEE Signal Processing Magazine vol 37(3) pp 50-60
[3]. Dean J and Ghemawat S 2020 MapReduce: Simplified data processing on large clusters Communications of the ACM vol 63(1) pp 107-113
[4]. Kairouz P, McMahan H B, Avent B, Bellet A, Bennis M, Bhagoji A N and Yang H 2021 Advances and open problems in federated learning Foundations and Trends in Machine Learning vol 14(1) pp 1-210
[5]. You Y, Zhang Z, Hsieh C J, Demmel J and Keutzer K 2020 Imagenet training in minutes Proceedings of the 47th International Conference on Parallel Processing pp 1-10
[6]. Jin Y, Liu X, Yang W and Jiang B 2021 An improved K-means clustering algorithm for high-dimensional data analysis Journal of Computational and Graphical Statistics vol 30(2) pp 325-338
[7]. Wu J, Xu Z and Zeng L 2022 Principal component analysis for dimensionality reduction in large-scale data IEEE Transactions on Knowledge and Data Engineering vol 34(4) pp 1301-1312
[8]. Kairouz P, McMahan H B, Avent B, Bellet A, Bennis M, Bhagoji A N and Yang H 2021 Advances and open problems in federated learning Foundations and Trends in Machine Learning vol 14(1) pp 1-210
[9]. Xu Y, Li Y and Yang L 2020 A survey on distributed machine learning IEEE Access vol 8 pp 86078-86091
[10]. Zhang X, Liu J and Li J 2021 Scalable and efficient distributed deep learning: Challenges and strategies ACM Computing Surveys vol 54(3) pp 1-35
[11]. Gao Y, Wang X and Zhou J 2021 Efficient Distributed Deep Learning with GPU Clusters Journal of Machine Learning Research vol 22 pp 1-25
[12]. Zhang L, Li H and Sun Y 2022 Challenges in Scaling Parallel Machine Learning: 12 Communication Overhead and Synchronization IEEE Transactions on Neural Networks and Learning Systems vol 33(4) pp 1552-1565
[13]. Li J, Huang Y and Zhang X 2021 Communication Costs in Distributed Machine Learning: Trade-offs and Strategies ACM Transactions on Intelligent Systems and Technology vol 12(2) pp 1-20
[14]. Kim S, Park T and Choi J 2022 Comparative Analysis of Distributed and Parallel Algorithms in Deep Learning Journal of Artificial Intelligence Research vol 75 pp 385-410
[15]. Patel R, Singh A and Kumar P 2023 Scaling Up Machine Learning: Distributed vs Parallel Frameworks IEEE Transactions on Neural Networks and Learning Systems vol 34(1) pp 23-38