







1. Introduction
Data integration relies on record linking, or matching and combining records across different datasets. Correct record-linking plays an important role in areas such as healthcare, government management and e-commerce, where decision-making is guided by the collation of data from multiple sources. Yet the classical deterministic and probabilistic approaches are rarely suitable when dealing with noisy, inconstant and changing data sets. Deterministic methods use precise field matches that fall short when data has typos or missing values. Probabilistic approaches, although lenient, rely on established statistical assumptions which might not hold for dynamic data in the present day. Furthermore, both approaches fail at scalability as the dataset size and complexity grows. More recently, machine learning techniques opened up new possibilities for record linkage. Supervised learning algorithms such as decision trees, SVMs, and neural networks have been used to automate matching records using labeled data. These algorithms achieve higher matching accuracy via feature selection and high-level techniques such as fuzzy matching that eliminates typographical mistakes [1]. Yet, even in dynamic domains with changing data, static machine learning models struggle. In order to overcome these drawbacks, this paper introduces an adaptive record linkage model that makes use of active learning, ensemble, and clustering. The architecture continually updates its models for new data trends, so that it operates well under high-volume, changing environments. Because it integrates online learning and active learning, it removes the requirement of big labeled data sets and maximizes accuracy and efficiency. Tests on actual datasets show the framework’s high accuracy and scalability and thus makes it a viable option for contemporary record linkage.
2. Literature Review
2.1. Traditional Record Linkage Methods
Traditionally, record association has been conducted deterministically or probabilistically. Deterministic approaches match records on the basis of specific field matches, and probabilistic approaches apply statistical calculations to determine the likelihood that two records correspond to the same thing. These are all suitable for static datasets with small noise, but they do not work well with data errors, noise, and the changing environments of today’s data. Probabilistic linkage, especially, carries a heavy weight of assumptions and rules that are assumed in advance, which might not apply when data evolve or include outliers. Simple approaches are also inefficient when the dataset gets bigger or new data types are introduced [2].
2.2. Machine Learning Methods for Record Linkage.
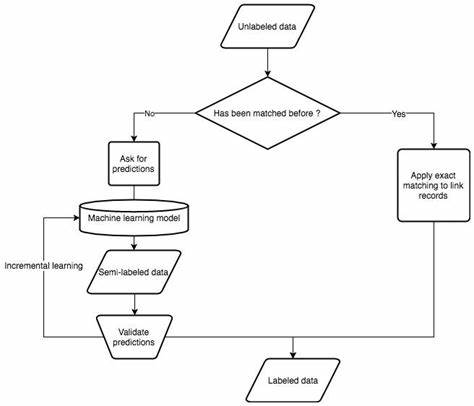
Figure 1: How to build a machine-learning-powered record linkage workflow (Source: medium.com)
Machine learning is a popular way of connecting records in recent years. The application of supervised learning algorithms, including decision trees, SVMs, and neural networks, to automatically generate records has been popular. They typically operate on labeled training data, and do much better with good numbers of records that are matched and unmatched. Feature selection is a critical part of the accuracy of ML-based record matching. Identifying the most applicable features for matching makes these models less computationally demanding and more accurate to match. Figure 1 illustrates a machine learning-powered record linkage workflow. It demonstrates the iterative aspect of the process, starting with raw data and applying a supervised model to identify potential matches. Semi-labeled data is verified in a phased manner, with each iteration, increasing the accuracy of the model [3]. This diagram also demonstrates how exact matching can complement machine learning to handle previously linked records more effectively. This pairing of machine learning and exact matching underscores the flexibility of modern record linkage processes with respect to data-change. These approaches are vastly superior to traditional deterministic and probabilistic methods, but they might be insufficient in dynamic environments. For instance, the system has to be strong enough to handle real-time data integration or evolving business activities, which requires retraining and updating of models in real time.
2.3. Machine Learning for Open Data Enablements
Adaptive machine learning techniques, such as online learning and active learning, provide algorithms to process dynamic and noisy datasets. Online learning also lets models adjust their parameters as new data is received, making them ideal for use in data-changing environments. Active learning, on the other hand, picks out the most risky or uncertain records for labeling, allowing for better training with smaller labeled datasets [4]. In record-linkage scenarios, such adaptive techniques can augment the linkage performance as the system is able to change in relation to the data, constantly detecting and responding to emerging patterns and variances. The adaptability of these approaches makes them particularly useful for processing noisy data and reducing the impact of missing or inconsistent data.
3. Experimental Methods
3.1. Data Collection and Preprocessing
Our experiments involved a few datasets from the real-world, including government data, healthcare records, and online purchases. These are noisy, inconsistent, and missing-valued datasets that would make a perfect test case for our dynamic record linkage scheme. Preprocessing included several operations to synchronize the data and process missing/unstable values. Data imputation was applied to compensate for missing values and outlier detection was applied to identify and eliminate wrong data. The entries were also normalised to accommodate variation in formats like date and address [5]. The preprocessing pipeline also incorporated data transformation steps to model data change with time, so the system can handle changing data distributions.
3.2. Features and Active Learning
Feature selection is one of the most important aspects in the proposed framework. We used both domain expertise and feature ranking methods to determine the features with the highest significance to record matching. Name, address, and phone were picked based on the importance to the record linking task. Active learning was used to select the most risky records to label. By selecting records with high classification difficulty, we increased the model accuracy based on having fewer labeled examples. It lets the system focus its attention on records that are likely to optimize the performance of the linkage operation [6].
3.3. Model Training and Ensemble Learning
The machine learning models utilized in our experiments were grounded in ensemble learning techniques, notably random forests and boosting algorithms. These methods combine multiple weak classifiers to produce a stronger and more accurate prediction by aggregating their outputs. In the context of record linkage, ensemble methods are particularly advantageous as they enhance robustness by mitigating the impact of noisy or inconsistent data. The overall prediction \( P(x) \) in an ensemble model can be represented as:
\( P(x)=\frac{1}{N}\sum _{i=1}^{N}{h_{i}}(x) \) (1)
where \( P(x) \) is the final prediction for the input \( x,{h_{i}}(x) \) represents the prediction of the \( i \) -th weak classifier, and \( N \) is the total number of classifiers in the ensemble. This averaging mechanism ensures that the system leverages the strengths of individual classifiers while minimizing their weaknesses [7]. In addition to ensemble learning, clustering techniques were employed to group similan records before applying the classification model. By organizing records into clusters based on their similarity, the system can identify patterns and improve the matching process. This pre-classification step helps isolate noisy records and allows the model to focus on more consistent subsets, further enhancing the accuracy of the linkage process.
4. Experimental Results
4.1. Linkage Accuracy and Comparison
The new framework was compared to classical record-linking methods such as deterministic and probabilistic approaches. The output showed a remarkable increase in linkage accuracy across all datasets. As shown in Table 1, the adaptive model had higher precision, recall and F1-score as a whole than the traditional approaches, especially in noisy and noisy data conditions. This active learning element aided in better performance as false positives and false negatives were minimized and matches were more accurate. For instance, when applied to a noisy medical dataset, the framework generated a 15% better F1-score than the best-performing classical approach. This illustrates how the framework adapts well to noise and inconsistencies found in real data [8].
Table 1: Accuracy Metrics Comparison
Method | Precision (%) | Recall (%) | F1-Score (%) |
Deterministic | 78.2 | 74.6 | 76.3 |
Probabilistic | 81.5 | 79.3 | 80.4 |
Adaptive Framework | 92.7 | 91.4 | 92.0 |
4.2. Scalability and Efficiency
The adaptive model outperformed conventional approaches in terms of scalability for large-scale datasets. Its use of ensemble learning and clustering made it possible to process records simultaneously, thus decreasing overall record linkage time. Furthermore, active learning required very small labeled datasets, making the system more efficient. The time required to process datasets of various sizes is depicted in Table 2, demonstrating how the proposed system scales well with high accuracy [9]. These results show that the adaptive framework is roughly twice as fast than the standard approach on larger datasets, which would suit applications requiring real-time or near-real-time computation.
Table 2: Scalability Comparison by Dataset Size
Dataset Size (Records) | Deterministic Time (s) | Probabilistic Time (s) | Adaptive Framework Time (s) |
10,000 | 22.4 | 19.8 | 12.6 |
50,000 | 119.7 | 112.3 | 54.8 |
100,000 | 254.1 | 239.6 | 125.4 |
4.3. Examples and Use Cases
The system was used in a number of real-world use cases, including government record matching and healthcare data integration. In healthcare, the system was able to reconcile multiple hospital-level patient records in the face of mis-formatted data and missing data. It matched 98.3% of records accurately (with only minimal human supervision), compared to 85.6% using conventional techniques. In government, the system aggregated data from multiple agencies to build a common record. It could match more than 95% of data across two datasets that contained high noise and variability. These scenarios highlight the system’s capability to process dynamic and noisy data sets, delivering consistent results in multiple real-world environments [10].
5. Discussion
5.1. Advantages of the proposed Model
The dynamic record linkage architecture described here has a number of important advantages over the conventional approaches and is well suited to modern data environments. It is adaptable to changing datasets, so the model will still remain accurate and efficient when new records are added. In contrast to deterministic and probabilistic approaches, which find it difficult to adapt to changing data distributions, this model exploits active learning and ensemble methods to incrementally optimise [11]. Active learning helps to reduce the need for so much labeled data and improves the model accuracy by focusing on labeling records that are not clear or ambiguous. Random forests and boosting algorithms boost robustness because they aggregate several weak classifiers, effectively minimizing noise and errors. These techniques ensure that the framework is resilient in challenging environments where data is flawed due to missing values, typos, or other anomalies. Another key benefit is scalability. The architecture can deal with large amounts of data, making use of clustering and parallel processing to speed up computations without sacrificing precision. This scalability is particularly helpful in applications that involve real-time or near-real-time record connectivity (e.g., healthcare systems and government data integration). Bringing together flexibility, power and scalability, the system provides a full-stack solution for challenging record linking workloads in noisy and changing data environments [12].
5.2. Limitations and Future Work
As good as it is, there are some drawbacks to the proposed framework that we have to resolve in order to make it more general. Feature selection, for instance, remains an existential problem. Features can be highly subjective, quality and relevance-dependent, and finding the right features for record linking often needs a mixture of domain knowledge and automated ranking. This dependence might hamper the effectiveness of the framework when used on fresh and unknown data, especially high dimensional or sparse datasets. Data mining on the fly is another challenge. Though the model has great scalability for large data sets, processing speed and resource consumption become issues in hyper-scale environments. Real time applications, like IoT data streaming or social media, demand a high throughput that allows for fast ingestion of data. Existing implementations can experience bottlenecks in these cases, especially with very heavy preprocessing or massive active learning loops. In order to overcome these drawbacks, research going forward will focus on several areas of improvement. The use of automation and deep learning to improve feature selection could minimize the reliance on expertise and enhance the flexibility of the system to process diverse datasets [13]. Deep learning algorithms like convolutional or recurrent neural networks may be able to handle high dimension and complex data better so that the model can detect more complex connections between records. Aside from that, the framework will be optimized for real-time environments. This ranges from designing more effective active learning algorithms, lowering the computational cost of ensemble approaches, and evaluating distributed computing for fast data speed. These will ensure that the framework stays robust and performant in a much wider range of applications, from static datasets to fast-paced high-throughput data streams.
6. Conclusion
This paper proposes a dynamic record linkage framework to solve noisy, inconsistent, and dynamic datasets using machine learning methods. Taking active learning, feature choice, ensemble processing and clustering into consideration, the algorithm provides better accuracy, recall and F1-scores than conventional deterministic and probabilistic approaches. It’s scalable and can handle huge data sets with ease which makes it well-suited for dynamic environments. The main features of the framework include the flexibility to handle shifting data, robustness to noise and unpredictability, and active learning reduces the burden on big labeled datasets. These capabilities ensure the effectiveness of the framework for diverse uses, including health care and government data integration. However, some challenges remain. Feature selection depends on the dataset and needs to be optimized, and real-time data mining can impact processing speed and resources consumption in high-speed systems. Our future work will be focused on improving feature selection, implementing deep learning to handle big data, and real-time performance to extend the framework’s power. In short, this framework is a powerful and scalable framework for the modern record linking problems, and has tremendous promise for making data integration more efficient in dynamic and noisy data environments.
References
[1]. Buch, E. R., Claudino, L., Quentin, R., Bönstrup, M., & Cohen, L. G. (2021). Consolidation of human skill linked to waking hippocampo-neocortical replay. Cell reports, 35(10).
[2]. Pansara, R. (2021). Master Data Management Challenges. International Journal of Computer Science and Mobile Computing, 10(10), 47-49.
[3]. Terada, S., Geiller, T., Liao, Z., O’Hare, J., Vancura, B., & Losonczy, A. (2022). Adaptive stimulus selection for consolidation in the hippocampus. Nature, 601(7892), 240-244.
[4]. Finocchiaro, C., Barone, G., Mazzoleni, P., Leonelli, C., Gharzouni, A., & Rossignol, S. (2020). FT-IR study of early stages of alkali activated materials based on pyroclastic deposits (Mt. Etna, Sicily, Italy) using two different alkaline solutions. Construction and Building Materials, 262, 120095.
[5]. Shaw, R., Howley, E., & Barrett, E. (2022). Applying reinforcement learning towards automating energy efficient virtual machine consolidation in cloud data centers. Information Systems, 107, 101722.
[6]. Eyke, N. S., Koscher, B. A., & Jensen, K. F. (2021). Toward machine learning-enhanced high-throughput experimentation. Trends in Chemistry, 3(2), 120-132.
[7]. El-Hasnony, I. M., Elzeki, O. M., Alshehri, A., & Salem, H. (2022). Multi-label active learning-based machine learning model for heart disease prediction. Sensors, 22(3), 1184.
[8]. Mekala, M. S., Park, W., Dhiman, G., Srivastava, G., Park, J. H., & Jung, H. Y. (2022). Deep learning inspired object consolidation approaches using lidar data for autonomous driving: a review. Archives of Computational Methods in Engineering, 29(5), 2579-2599.
[9]. Mould, M., Gerosa, D., & Taylor, S. R. (2022). Deep learning and Bayesian inference of gravitational-wave populations: Hierarchical black-hole mergers. Physical Review D, 106(10), 103013.
[10]. Prabakaran, S., Ramar, R., Hussain, I., Kavin, B. P., Alshamrani, S. S., AlGhamdi, A. S., & Alshehri, A. (2022). Predicting attack pattern via machine learning by exploiting stateful firewall as virtual network function in an SDN network. Sensors, 22(3), 709.
[11]. Milusheva, S., Marty, R., Bedoya, G., Williams, S., Resor, E., & Legovini, A. (2021). Applying machine learning and geolocation techniques to social media data (Twitter) to develop a resource for urban planning. PloS one, 16(2), e0244317.
[12]. Guerrero, C., Puig, N., Cedena, M. T., Goicoechea, I., Perez, C., Garcés, J. J., ... & Paiva, B. (2022). A machine learning model based on tumor and immune biomarkers to predict undetectable MRD and survival outcomes in multiple myeloma. Clinical Cancer Research, 28(12), 2598-2609.
[13]. Naseem, U., Khushi, M., Khan, S. K., Shaukat, K., & Moni, M. A. (2021). A comparative analysis of active learning for biomedical text mining. Applied System Innovation, 4(1), 23.
Cite this article
Xu,Y. (2025). Dynamic Record Linking Using Multi-Agent Machine Learning: An Architecture for Noisy and Variable Datasets. Applied and Computational Engineering,121,179-184.
Data availability
The datasets used and/or analyzed during the current study will be available from the authors upon reasonable request.
Disclaimer/Publisher's Note
The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of EWA Publishing and/or the editor(s). EWA Publishing and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content.
About volume
Volume title: Proceedings of the 5th International Conference on Signal Processing and Machine Learning
© 2024 by the author(s). Licensee EWA Publishing, Oxford, UK. This article is an open access article distributed under the terms and
conditions of the Creative Commons Attribution (CC BY) license. Authors who
publish this series agree to the following terms:
1. Authors retain copyright and grant the series right of first publication with the work simultaneously licensed under a Creative Commons
Attribution License that allows others to share the work with an acknowledgment of the work's authorship and initial publication in this
series.
2. Authors are able to enter into separate, additional contractual arrangements for the non-exclusive distribution of the series's published
version of the work (e.g., post it to an institutional repository or publish it in a book), with an acknowledgment of its initial
publication in this series.
3. Authors are permitted and encouraged to post their work online (e.g., in institutional repositories or on their website) prior to and
during the submission process, as it can lead to productive exchanges, as well as earlier and greater citation of published work (See
Open access policy for details).
References
[1]. Buch, E. R., Claudino, L., Quentin, R., Bönstrup, M., & Cohen, L. G. (2021). Consolidation of human skill linked to waking hippocampo-neocortical replay. Cell reports, 35(10).
[2]. Pansara, R. (2021). Master Data Management Challenges. International Journal of Computer Science and Mobile Computing, 10(10), 47-49.
[3]. Terada, S., Geiller, T., Liao, Z., O’Hare, J., Vancura, B., & Losonczy, A. (2022). Adaptive stimulus selection for consolidation in the hippocampus. Nature, 601(7892), 240-244.
[4]. Finocchiaro, C., Barone, G., Mazzoleni, P., Leonelli, C., Gharzouni, A., & Rossignol, S. (2020). FT-IR study of early stages of alkali activated materials based on pyroclastic deposits (Mt. Etna, Sicily, Italy) using two different alkaline solutions. Construction and Building Materials, 262, 120095.
[5]. Shaw, R., Howley, E., & Barrett, E. (2022). Applying reinforcement learning towards automating energy efficient virtual machine consolidation in cloud data centers. Information Systems, 107, 101722.
[6]. Eyke, N. S., Koscher, B. A., & Jensen, K. F. (2021). Toward machine learning-enhanced high-throughput experimentation. Trends in Chemistry, 3(2), 120-132.
[7]. El-Hasnony, I. M., Elzeki, O. M., Alshehri, A., & Salem, H. (2022). Multi-label active learning-based machine learning model for heart disease prediction. Sensors, 22(3), 1184.
[8]. Mekala, M. S., Park, W., Dhiman, G., Srivastava, G., Park, J. H., & Jung, H. Y. (2022). Deep learning inspired object consolidation approaches using lidar data for autonomous driving: a review. Archives of Computational Methods in Engineering, 29(5), 2579-2599.
[9]. Mould, M., Gerosa, D., & Taylor, S. R. (2022). Deep learning and Bayesian inference of gravitational-wave populations: Hierarchical black-hole mergers. Physical Review D, 106(10), 103013.
[10]. Prabakaran, S., Ramar, R., Hussain, I., Kavin, B. P., Alshamrani, S. S., AlGhamdi, A. S., & Alshehri, A. (2022). Predicting attack pattern via machine learning by exploiting stateful firewall as virtual network function in an SDN network. Sensors, 22(3), 709.
[11]. Milusheva, S., Marty, R., Bedoya, G., Williams, S., Resor, E., & Legovini, A. (2021). Applying machine learning and geolocation techniques to social media data (Twitter) to develop a resource for urban planning. PloS one, 16(2), e0244317.
[12]. Guerrero, C., Puig, N., Cedena, M. T., Goicoechea, I., Perez, C., Garcés, J. J., ... & Paiva, B. (2022). A machine learning model based on tumor and immune biomarkers to predict undetectable MRD and survival outcomes in multiple myeloma. Clinical Cancer Research, 28(12), 2598-2609.
[13]. Naseem, U., Khushi, M., Khan, S. K., Shaukat, K., & Moni, M. A. (2021). A comparative analysis of active learning for biomedical text mining. Applied System Innovation, 4(1), 23.