


Volume 185
Published on September 2025Volume title: Proceedings of CONF-CDS 2025 Symposium: Application of Machine Learning in Engineering
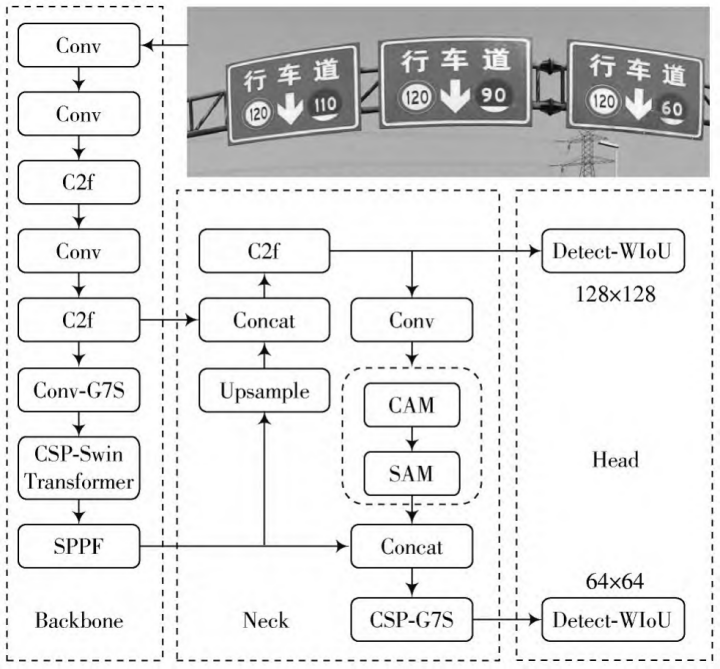
This paper aims to introduce deep learning approaches developed to overcome challenges in traffic sign recognition, which include YOLOv8-TS, STD-YOLOv5s, Semantic Scene Understanding & Structured Localization, and Cascade R-CNN with Multi-Scale Attention. The paper also delves into critical system architecture considerations, analyzing the roles of various sensors and computing platforms in enabling real-time and efficient TSR. Performance evaluation is discussed using essential metrics such as Precision, Recall, F1-score, and mean Average Precision (mAP), highlighting their importance in quantifying detection and classification accuracy. Optimization strategies are emphasized as crucial for practical deployment, relying heavily on continuous algorithmic advances (like novel network architectures and attention modules) and sophisticated hardware-software co-design to balance computational efficiency with recognition performance. Looking ahead, TSR research is poised to advance significantly in key directions, including multi-modal data fusion for enhanced environmental perception, extreme lightweighting and real-time optimization for edge deployment, achieving cross-regional and cross-language generality, developing robust adversarial defense and safety mechanisms, improving model interpretability, and fostering deeper integration with driving decision systems. These advancements are vital for enhancing the reliability and safety of autonomous vehicles operating in complex, real-world driving environments.



Convolutional Neural Networks (CNNs) have achieved remarkable success in image classification and other vision tasks in recent years. However, their large model size and computational complexity hinder their application in mobile terminals and embedded devices. To address this issue, this paper proposes a lightweight CNN design method that combines Mixup data augmentation and network pruning. The method aims to balance the trade-off between model compression and performance preservation, achieving the maximum model compression while maintaining as much of the original performance as possible. Using the FashionMNIST dataset as the experimental platform, a classification model based on a simplified LeNet structure is constructed. The model is evaluated under four different settings: the standard model, the Mixup-augmented model, the pruned sparse model, and the collaborative model integrating both Mixup augmentation and pruning. The experimental results show that Mixup enhances the model's generalization ability and robustness, pruning significantly reduces the number of parameters, and the combination of both achieves superior lightweight performance while preserving accuracy. This study demonstrates the effectiveness of Mixup and pruning techniques in collaborative optimization and proposes practical optimization strategies for deploying lightweight neural networks in resource-constrained environments.

Pólya’s Enumeration Theorem, or PET, is a sine qua non tool in combinatorial mathematics for solving counting problems that involve symmetry. This paper provides a comprehensive review of the theorem and its related theories. We begin by establishing the necessary group-theoretic foundations, followed by rigorous proofs of the "Orbit-Stabilizer Theorem" and "Burnside’s Lemma". The core of the paper is a detailed analysis of PET, including complete proofs for its unweighted and weighted forms, demonstrating how the cycle index allows for detailed pattern enumeration. The theorem’s broad utility is illustrated through classic applications in chemistry (isomer counting), graph theory (non-isomorphic graph counting), and music theory. Furthermore, we explore key modern generalizations of PET, including de Bruijn’s theorem on dual group actions, Rota’s lattice-theoretic formulation, and Fujita’s stereochemical method for complex molecular structures. The paper concludes by positioning the Theory of Combinatorial Species as a potential unifying framework for future research in enumeration theory.
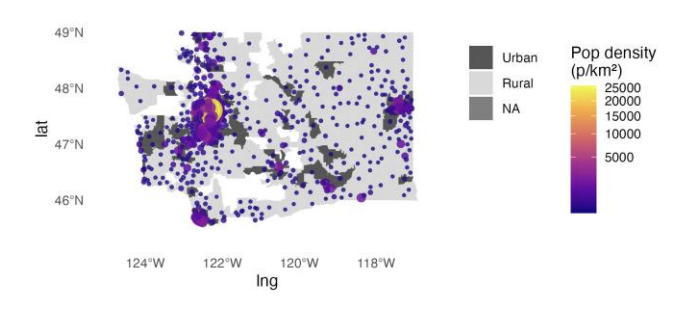
Electric vehicles (EVs) offer lower noise and zero tailpipe emissions compared to traditional internal combustion engine (ICE) vehicles. This study quantifies EV adoption across Washington State using ZIP-code–level data from 2020–2025. Multivariable linear regressions relate the monthly change in EV share to socioeconomic factors, urbanization, family structure, and the roll-out of public charging infrastructure. Results indicate that adoption growth is positively associated with higher per-capita income, higher educational attainment, greater urbanization, and larger average family size. Proximity to infrastructure matters: the number of newly built local stations (0–20 miles) is positively associated with adoption growth, whereas a higher number of newly built distant stations (≥30 miles) correlates negatively, consistent with rurality and limited access. By providing a comprehensive ZIP-code–level analysis, the study addresses aggregation bias common in county-level work and reveals localized patterns that broader geographies can obscure. The findings offer policy-relevant evidence for charger siting and for targeting incentives.