


Volume 183
Published on September 2025Volume title: Proceedings of CONF-MLA 2025 Symposium: Applied Artificial Intelligence Research
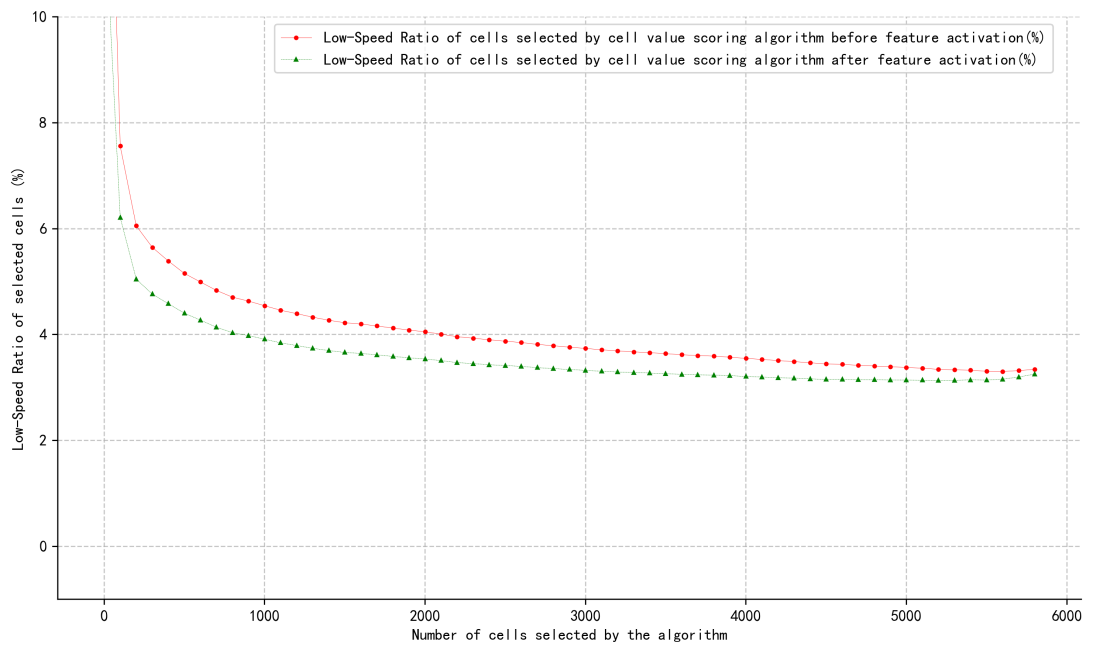
With the increasingly strict assessment of regional mobile operators’ wireless indicator by the wireless communication group, and the need for corresponding licenses and activation fees for the advanced feature algorithms provided by the vendor, regional mobile operators are in urgent need of optimizing a cost - controllable and scenario - based rapid deployment plan for the above - mentioned advanced feature algorithms due to cost control. This paper uses the methods of data analysis and comparative experiments to analyze and study the Key Performance Index (KPI) data of cells provided by regional mobile operators, and proposes an optimal algorithm for feature activation based on cell value scoring. This algorithm aims to solve the problem of how to select cells for deployment when mobile operators deploy specific feature algorithms. The algorithm can balance operating costs and network performance, and help mobile operators make optimal deployment decisions based on data. Based on the experimental KPI data, this algorithm can achieve an approximately optimal effect in terms of improving the Low-Speed network performance, and has a lower time complexity compared with the traditional combination algorithm.



Speech recognition technology, a pivotal element in human-computer interaction, has witnessed substantial advancements in recent years, propelled by the synergies of deep learning and big data. This paper provides a systematic review of the evolution of speech recognition algorithms, delineating the principal characteristics and application contexts of traditional speech recognition algorithms, such as Hidden Markov Models (HMM), deep learning-based algorithms, including Recurrent Neural Networks (RNN) and Convolutional Neural Networks (CNN), and end-to-end speech recognition algorithms. Furthermore, this study delves into the multifaceted applications of these algorithms in domains such as voice assistants (e.g., Siri and Alexa), machine translation, and meeting transcription, elucidating their transformative impact. The paper also synthesizes the prevailing speech recognition technologies and the challenges they confront, with a particular emphasis on the limitations of commonly used language recognition algorithms, such as susceptibility to noise, accent variability, and data dependency. Through this comprehensive analysis, the paper aims to illuminate the current state and future trajectories of speech recognition technology. This paper identifies and summarizes the shortcomings of commonly used language recognition algorithms.
Deepfake technology, empowered by breakthroughs in deep learning-based image synthesis, is profoundly reshaping identity verification systems, finding extensive application in security, finance, and social media with enhanced convenience. However, its capacity to generate hyper-realistic facial forgeries presents a dual impact: while driving innovation, it simultaneously introduces unprecedented security threats, including privacy violations, identity spoofing, and data poisoning attacks. This paper systematically reviews and assesses current research progress on the security risks and defense strategies associated with Deepfake technology. Through synthesis of existing literature, this paper constructs a multidimensional analytical framework examining three core dimensions: first, the core technological principles underpinning Deepfakes and their evolution; second, the diverse spectrum of security risks arising from their misuse and their underlying mechanisms; and third, the effectiveness and inherent limitations of prevailing defense mechanisms, encompassing detection techniques and legal regulations. This study concludes that although Deepfakes advance facial recognition, mitigating their inherent security threats necessitates a multidimensional synergistic approach. This approach must integrate continuous technological advancements, robust legal oversight, and strengthened public awareness initiatives. Future efforts must prioritize establishing cross-disciplinary collaborative governance mechanisms to achieve a dynamic equilibrium between technological innovation and security assurance.
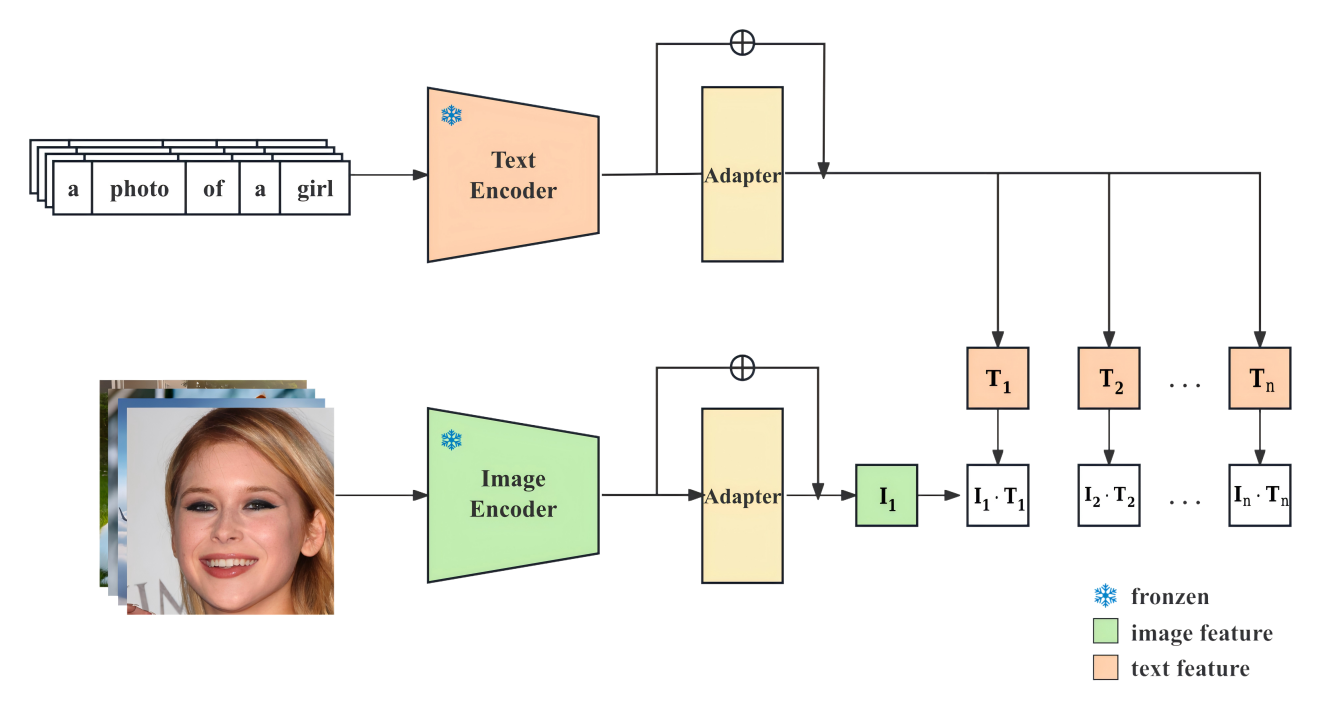
In recent years, with the rapid development of cross-modal learning, pretrained models such as CLIP have demonstrated powerful zero-shot capabilities in image-text alignment tasks, making them central to multimodal research. However, a key challenge remains: how to effectively transfer these capabilities while preserving the strengths of CLIP. To address this, we propose a parameter-efficient multi-task fine-tuning framework—Multi-Task CLIP-Adapter. By inserting lightweight Adapter modules after the frozen CLIP encoder, our method enables unified adaptation across multiple tasks, including classification, image-text retrieval, and regression. Experimental results show that our approach achieves an 8%–12% performance improvement with less than 0.2% additional parameters, while maintaining the original model’s zero-shot capability. Compared to the original CLIP and conventional transfer strategies, the Multi-Task CLIP-Adapter offers significant advantages in parameter efficiency and task generalization, paving a new path for scalable applications of large multimodal models.
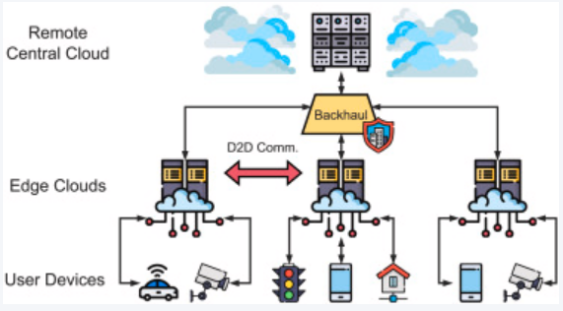
The widespread adoption of smart cameras in areas such as security monitoring, intelligent transportation, and industrial quality inspection is fueled by the growing number of Internet of Things (IoT) devices and continuous progress in artificial intelligence (AI) algorithms. However, traditional video surveillance systems rely on cloud computing and face challenges like limited bandwidth, high latency, and privacy risks. Edge computing, a distributed architecture that brings computation and storage closer to the data source, offers an effective way to improve smart camera video processing and recognition. Therefore, the paper investigates smart camera video processing and recognition systems based on edge computing reviewing key technologies and implementation methods via recent research and typical applications. In addition, it examines the progress and features of edge platform architecture, video analysis and object detection algorithms, resource scheduling and energy management, model compression, and data security and privacy protection. The results show that edge-intelligent video systems are effective in reducing network load, lowering response latency, and improving the security of local data processing. However, they still face technical challenges in heterogeneous resource management, real-time scheduling, and multi-task collaboration. As such, this paper further reviews the main existing issues and offers a practical outlook on system optimization and future applications.
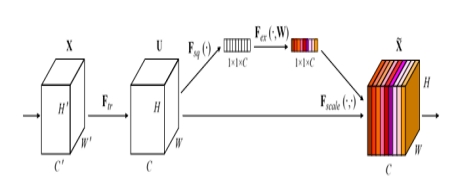
With the continuous breakthroughs in deep learning technology, face recognition methods based on deep learning have become a prominent research focus in the field of computer vision. In particular, within service robots and embedded intelligent systems, face recognition plays a critical role in identity verification, interactive control, and behavioral understanding, and its performance directly affects the intelligence level of such systems. However, traditional face recognition models based on deep convolutional neural networks (CNNs) are often computationally intensive and contain a large number of parameters, making them unsuitable for deployment on robotic platforms that require real-time processing, low power consumption, and lightweight models. To address these challenges, this paper proposes a lightweight face recognition method based on deep learning, which combines the MobileNetV3 architecture with the Convolutional Block Attention Module (CBAM) to construct an efficient recognition model suitable for robotic vision systems. MobileNetV3, as the backbone network, provides excellent computational efficiency and structural compression capabilities, effectively reducing the size and latency of the model, while the CBAM module introduces channel and spatial attention mechanisms to guide the network to focus on key facial regions during deep feature extraction, thereby enhancing the discriminative power and robustness of recognition. Extensive experiments are conducted on the publicly available Labeled Faces in the Wild (LFW) dataset, where the model is trained using the cross-entropy loss function and optimized with the Adam optimizer, evaluating its performance under realistic scenarios such as complex backgrounds, pose variations, and occlusions. Experimental results show that the proposed model achieves higher recognition accuracy than several existing lightweight networks while maintaining a compact structure, demonstrating better adaptability and generalization. This method effectively balances accuracy and real-time performance, offering a feasible and efficient solution for robot-oriented face recognition systems. The study confirms the effectiveness of integrating deep learning and attention mechanisms into lightweight architectures and provides new ideas and practical paths for achieving high-performance face recognition on edge computing devices, with strong application potential.

This project implements the D* Lite algorithm for dynamic pathfinding in a simulated urban street environment featuring realistic autonomous vehicle constraints. The AV, modeled as a 2×3 grid-aligned car, navigates forward through a narrow 10×100 grid with both static and probabilistically generated dynamic obstacles, such as pedestrians crossing at designated intervals. The simulation integrates a forward safety buffer of three grid cells, equivalent to the vehicle’s length to ensure safety, which allows the AV to anticipate and react to potential threats before they intersect its path. The system computes planning and safety masks at each timestep, which enable real-time halting and re-routing behavior in response to environmental changes. While the safety radius improves collision avoidance, D* Lite remains a geometric planner without predictive capabilities. Rare collisions can still occur due to dynamic obstacle motion between sensing and actuation. Results of this research demonstrate that the algorithm supports low-latency decision-making and efficient re-planning under uncertainty. The project validates the algorithm’s practical utility for simulating AV navigation in simplified yet dynamic scenarios.
As an important technology required for intelligent devices such as autonomous driving and autonomous robots that can actively obtain environmental information, synchronous positioning and map construction technology has developed in response to practical demands and technological progress, and has given rise to a variety of algorithms with different efficiencies and consumption levels. However, the existing research related to SLAM is more focused on improving the performance of simultaneous localization and mapping algorithms in complex environments, while there are relatively few specialized optimizations for devices with lower computing or sensing capabilities. This paper mainly studies the existing solutions for reducing the requirements of synchronous positioning and map construction technology for the computing power or perception ability of devices, sorts out the relevant academic papers since 2009, and analyzes these papers through the review method. And from this, several optimization schemes for reducing the consumption of synchronous positioning and map construction algorithms have been sorted out, such as adding additional sensors like inertial measurement units, reducing the consumption of the search process through more efficient heuristic algorithms, lowering the data processing volume through dimensionality reduction, and reducing the recognition difficulty through strong features.
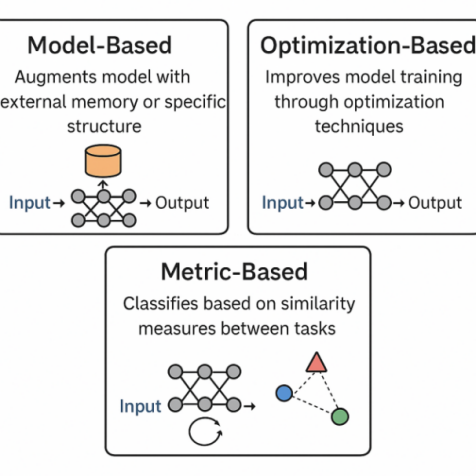
With the development of data-driven technologies, Few-Shot Learning (FSL) and environmental adaptability have become important research directions in machine learning. Traditional methods are highly dependent on large amounts of annotated data, which makes it difficult to cope with the data scarcity problem in the real world. This paper explores the integration of meta-learning and multi-armed bandit (MAB) algorithms in few-shot learning, aiming to investigate how their synergy improves model adaptability and decision-making efficiency in novel tasks. Through a review of existing literature, it analyzes the strengths of meta-learning in cross-task representation learning and the dynamic adaptability of MAB algorithms in uncertain environments. Their integration, supported by deep learning and attention mechanisms, is investigated in applications such as federated learning and remote sensing image analysis. The results demonstrate that meta-learning improves generalization by extracting cross-task knowledge, while MAB facilitates rapid task adaptation through effective exploration and exploitation strategies. Together, they form a unified framework that achieves state-of-the-art performance in few-shot learning across various domains.
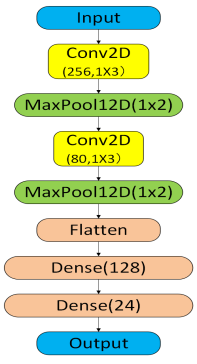
Convolutional neural networks (CNNs) have become the mainstream approach for AMR tasks. However, model selection still faces a trade-off among "performance", "complexity" and "adaptability". Current literature primarily focuses on model innovation itself while lacking systematic comparative analysis of different types of CNN models under the same data conditions. This study investigates the performance differences between two deep neural networks—DenseNet and CNN2—across signal-to-noise ratio (SNR) conditions ranging from 0 dB to 20 dB, based on the standard dataset (RadioML 2018.01A) and evaluates the performance by combining dimensions such as accuracy rate, convergence curve, confusion matrix, etc. The experimental results demonstrate that DenseNet achieves superior recognition accuracy under resource-constrained conditions, particularly at medium-to-high SNR levels. At 20 dB SNR, DenseNet attains an accuracy of 82.1%, outperforming CNN2 by 3.6 percentage points. However, at low SNR, especially at 0 dB, CNN2 demonstrated stronger robustness and generalization ability, but DenseNet was difficult to converge. These findings establish both empirical benchmarks and a theoretical framework for optimizing AMR network architecture selection across diverse communication environments.