







1. Introduction
Artificial Intelligence (AI) possesses the immense potential to accelerate the development of technology and improve people’s lives at a rate that is unparalleled in industries such as transportation, medical images and scientific research [1-3]. It has quietly entered into people’s daily lives, and some examples of practical applications are chatbots that detect words from clients and respond accordingly and digital assistance that people use daily, like Siri and Alexa [4]. Moreover, self-parking uses AI to detect the spaces around the car, along with self-driving cars that use deep learning to learn from experience by driving on the road and learn to respond differently and adjust the driving style to different road conditions [4].
In the realm of AI, one particularly noteworthy modeling paradigm is known as Generative Adversarial Networks known as Generative Adversarial Network (GANs) model first introduced by Ian Goodfellow Today’s academics are becoming increasingly familiar with the foundations of the original GANs model; as a result, they are enhancing these fundamentals by creating numerous variants version of different GANs models, for example, SRGAN, DR-GAN, TP-GAN, VGAN, and etc. [5], and incorporating them into daily practical uses in accordance with their respective research interests. Machine vision and shape identification have been GANs model research priorities since 2016 [6]. Image processing uses the GANs model to clarify fuzzy images and build basic recognition [6]. Using the model to produce three-dimensional objects improves computer vision. Face detection using GAN models is being utilized to improve surveillance system face detection [6]. Additionally, a traffic control system that uses GANs to learn traffic patterns in multiple locations to accurately predict road conditions [6].
The concept of GANs model appears to have a great deal of strength and has had a significant impact in the academic world; it is hard to identify the limitations of the original GANs model by observing the loss plot while reimplementing the model and the loss plot also shows the problem of mode collapse which means the plot shows the discriminator loss curve exhibits periods of stability with relatively little change, but the generator loss curve frequently reaches plateaus or fluctuations without noticeably improving, demonstrating that the GANs model could have trouble accurately capturing all the phases of the data distribution [7]. Therefore, this article aims to investigate how the original GANs model may be improved to the point where the Generator Loss and the Discriminator Loss become more stable and converge closer towards the value.
This study reimplements GANs to test the Loss of GANs model. In the end, the result displays loss curves of their training progress. In order to visualize the results of the improved model, this study decided to keep the framework of the GANs model this paper reimplemented throughout the experimental process. The only changes that were made were to the loss function, the training procedure, or the method by which data was generated. In the end, this study would compare the loss curves of each adjustment made on the original GANs model to arrive at a conclusion regarding which adjustment is the one that should be utilized.
2. Method
2.1. Introduction of GAN and corresponding structure
General Adversarial Networks (GANs) are prevailing models recently that are based on the fundamental idea that it generates two networks—Generator (G) and Discriminator (D)—in the process of its operation. The generator of the fake data is denoted by the letter G, and after the fake data has been generated, it is sent to the recipient, denoted by the letter D [8]. The discriminator, denoted by the letter D, is a binary classifier that has the ability to differentiate between the real data found in the training set and the fake data that is supplied by the generator [8]. As the generator and discriminator compete in the GANs model, the model gradually learns through the process of producing data and differentiating between the real and fake data until the real and fake data become eerily similar and are impossible to distinguish [8]. The developed model for this study has a generator and a discriminator neural network, like Ian Goodfellow’s GANs model [4]. The discriminator checks data for authenticity while the generator generates it. The generator tries to fool the discriminator while training it to distinguish real from fake data. Competition refines both models, making the generator generate more realistic data that cannot be distinguished. The dataset that the model uses contains two different functions. The initial function’s primary task is to generate these data points, which involves drawing random numbers from a normal distribution with a mean of 0.5 and a standard deviation of 0.2. To introduce diversity and randomness into the training data produced by the established GANs model, a second function is employed. This function generates random noise and subsequently injects it into the GANs model’s generator to achieve this objective. After the generator and discriminator have been developed, the model is altered into a GANs model by including both of the networks in the model by sequential manners.
2.2. Implementation details
The GANs implementation for this study requires using the whole datasets for training for 400 epochs, with a batch size of 128, and this indicates that the number of data points used by the generator and discriminator in each training iteration is 128. In addition, the learning rates of both the discriminator and the generator that has the application of Adam optimizer have been adjusted down to 0.0002, which enables the model to be trained in a learning environment that is more evenly distributed and produces a more accurate result. After establishing the foundational framework of the basic GANs model, encompassing components like the binary cross-entropy Loss function involving a two-player minimax game, the generator, discriminator, and the training process, the methodology was employed with the aim of visualizing both the Generator Loss and the Discriminator Loss of the model on a single graph throughout the training process.
As the experiment continues, each of the parameters and loss functions discussed so far will have their value tuned to carry out a series of controlled manipulations aimed at determining how the GANs model’s generator loss and discriminator loss may be improved. This experiment will involve three distinct sets of comparisons: the first set will compare the original model with the same model that has been parameterized; the second set will compare all models that share the same loss function but have varying parameter values; and the third set will compare the model with a modified loss function against the model that exhibits superior performance from the second set. This study will solely use the Wasserstein Earth Mover’s distance, which, informally, may be seen as the least amount of energy required to move and change a pile of dirt in the form of one probability distribution into the form of another distribution [9]. It provides a more reliable technique to compare the distributions of the generated data with those of the actual data. In place of the traditional binary cross-entropy loss function in this comparison experiment.
3. Results and discussion
3.1. The performance of the GANs model with different epochs
The two losses that were exhibited by the original GANs model reimplemented for this study during a training cycle of 400 epochs are depicted in Figure 1. However, due to the short training cycle, the training is stopped prior to the Loss beginning to stabilize. This, in return, prevents further observation of the relationship between the two losses and prevents an accurate judgment as to whether or not the GANs model is operating efficiently. In this experiment, the training cycle was extended to 1000 epochs and remaining parameters and the same model framework as shown in Figure 2 in an effort to reduce the amount of error that was produced as a result of the short training period. Figure 2 reveals that the discriminator loss begins to stabilize after nearly 500 epochs, while the generator loss exhibits a continuing tendency to fluctuate even after this epoch count has been surpassed. The shape from Figure 2 shows the fundamental flaw in GANs model, which is known as mode collapse.
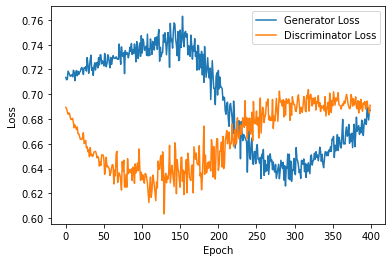
Figure 1. Original GANs model plot with 400 epochs only.
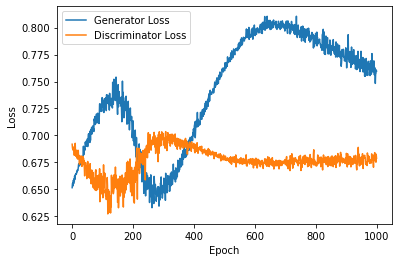
Figure 2. Original Gans model plot with 1000 epochs.
3.2. Comparison between all the models that has the same loss function but different value of parameters
It was chosen to tweak the other parameters while leaving the loss function alone because it was discovered that simply increasing the experimental step size was still insufficient to determine whether the original GAN model was being trained effectively. In order to better visualize the entire training process, the training step size was first increased to 5000, and then the batch size was increased from 128 to 512 to make the model training more converged stable, and let the learning rate be 0.0001 in Figure 3, 0.0002 in Figure 4 and 0.0003 in Figure 4 respectively. According to academic research, increasing batch size results in much fewer parameter updates while still achieving approximately the same model performance on the test set with the same number of training epochs by not decreasing the learning rate [10]. This statement is partially true, however, as the same batch size and training step size are kept in all three configurations 3, 4, and 5 mentioned above, and it is more apparent that the training is more effective for the lower learning rate. The training begins to stabilize in Figure 3, which has the lowest learning rate, at roughly 1300 epochs; moreover, from 2000 to 5000 epochs later, the up and down ranges are smaller and have less fluctuation than they are in Figure 4 and Figure 5. While the tuning of the parameter improves the model to some extent, it is still possible to see both generator and discriminator loss start to float upwards after stabilizing at around 0.7, and there is no improvement whatsoever. At this point, improving the loss function from the original framework may be necessary. Figure 3 stands out to be the best model out of the three figures.
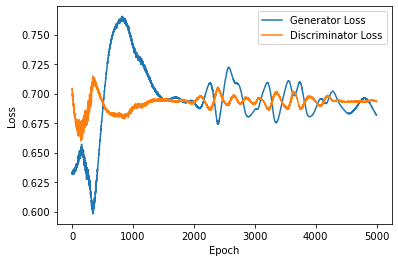
Figure 3. Learning rate=0.0001, batch=512, epochs=5000.
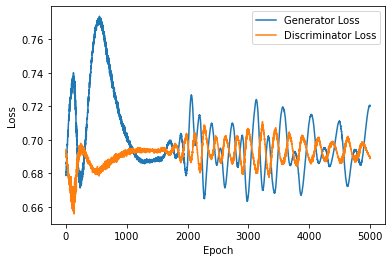
Figure 4. Learning Rate=0.0002, batch=512, epochs=5000.
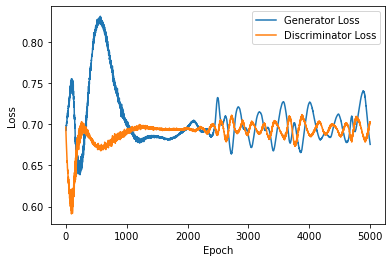
Figure 5. Learning Rate=0.0003, batch=512, epochs=5000.
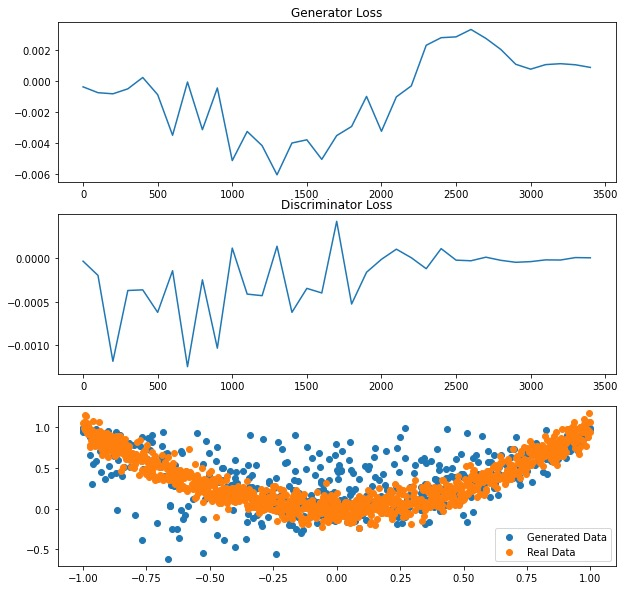
Figure 6. GANs model plot with main Loss function changed.
3.3. Compares the model best out of 3.2, and model that has the loss function changed
As previously mentioned, merely altering the parameters of the original model does not result in a significant enhancement of the original GANs model’s performance. Consequently, in this experiment, the primary modification involved changing the original binary cross-entropy loss to the Wasserstein Loss, also recognized as the Earth Mover’s Distance, in an effort to improve the model’s performance. It is better suited for GANs since it can quantify the disparity between two probability distributions [9]. Moreover, it motivates the generator to generate data that closely resembles the distribution of actual data, further promoting training stability. Furthermore, the best-shaped loss map was discovered to have a learning rate of 0.0003 for the discriminator and 0.0007 for the generator after spending hours experimenting with various learning rates between 0.0001 and 0.001. Surprisingly, both the generator loss and the discriminator loss have been improving over time and are inching closer and closer to the point where the loss will be equal to zero, beginning around 2500 and 2000 epochs, respectively, which is a significant step forward compared to Figure 3, which finally brought both Losses closer to 0.7 as shown in Figure 6.
4. Conclusion
This study advocates for finding ways to make the performance of the initial traditional GANs model, introduced by Ian Goodfellow, more efficient and allow both generator loss and discriminator loss to stabilize and converge to a loss of 0 during the training process. Methods of tuning the model parameters and the main loss function have been used and proved to be effective in improving the performance of the origin GANs model in this study. Finally, it is discovered that the model that performed the best overall was the one that changed the original binary cross-entropy function to the Wasserstein Loss Function and tuned the learning rates of the discriminator and generator to 0.0003 and 0.0007, respectively from the original values of 0.0002. Although this study has only employed a single technique to replace the loss function with the Wasserstein Loss, there are several ways to alter the loss function to enhance model performance, therefore there may still be ways to significantly enhance the model’s performance. To determine the optimum strategy for performance improvement, this study will concentrate on applying more diverse loss functions and experimenting with other parameters in the future.
References
[1]. Chan Y K Chen Y F Pham T Chang W and Hsieh M Y 2018 Artificial intelligence in medical applications. Journal of healthcare engineering
[2]. Qiu Y Wang J Jin Z Chen H Zhang M and Guo L 2022 Pose-guided matching based on deep learning for assessing quality of action on rehabilitation training Biomedical Signal Processing and Control 72 103323
[3]. Wang F Y 2017 Artificial intelligence and intelligent transportation: Driving into the 3rd axial age with ITS IEEE Intelligent transportation systems magazine 9(4) pp 6-9
[4]. Nadikattu R R 2016 The emerging role of artificial intelligence in modern society International Journal of Creative Research Thoughts
[5]. Gui J Sun Z Wen Y Tao D and Ye J 2021 A review on generative adversarial networks: Algorithms theory and applications IEEE transactions on knowledge and data engineering 35(4) 3313-3332
[6]. Aggarwal A Mittal M and Battineni G 2021 Generative adversarial network: An overview of theory and applications International Journal of Information Management Data Insights 1(1) 100004
[7]. Srivastava A Valkov L Russell C Gutmann M U and Sutton C 2017 Veegan: Reducing mode collapse in gans using implicit.
[8]. Goodfellow I et al 2014 Generative Adversarial Nets Advances in Neural Information Processing Systems 27 (NIPS)
[9]. Weng L 2019 From gan to wgan arXiv preprint arXiv:1904 08994
[10]. Smith S L Kindermans P J Ying C and Le Q V 2017 Don’t decay the learning rate increase the batch size arXiv preprint arXiv:1711 00489
Cite this article
Zhang,H. (2024). The investigation of performance improvement based on original GANs model. Applied and Computational Engineering,54,1-6.
Data availability
The datasets used and/or analyzed during the current study will be available from the authors upon reasonable request.
Disclaimer/Publisher's Note
The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of EWA Publishing and/or the editor(s). EWA Publishing and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content.
About volume
Volume title: Proceedings of the 4th International Conference on Signal Processing and Machine Learning
© 2024 by the author(s). Licensee EWA Publishing, Oxford, UK. This article is an open access article distributed under the terms and
conditions of the Creative Commons Attribution (CC BY) license. Authors who
publish this series agree to the following terms:
1. Authors retain copyright and grant the series right of first publication with the work simultaneously licensed under a Creative Commons
Attribution License that allows others to share the work with an acknowledgment of the work's authorship and initial publication in this
series.
2. Authors are able to enter into separate, additional contractual arrangements for the non-exclusive distribution of the series's published
version of the work (e.g., post it to an institutional repository or publish it in a book), with an acknowledgment of its initial
publication in this series.
3. Authors are permitted and encouraged to post their work online (e.g., in institutional repositories or on their website) prior to and
during the submission process, as it can lead to productive exchanges, as well as earlier and greater citation of published work (See
Open access policy for details).
References
[1]. Chan Y K Chen Y F Pham T Chang W and Hsieh M Y 2018 Artificial intelligence in medical applications. Journal of healthcare engineering
[2]. Qiu Y Wang J Jin Z Chen H Zhang M and Guo L 2022 Pose-guided matching based on deep learning for assessing quality of action on rehabilitation training Biomedical Signal Processing and Control 72 103323
[3]. Wang F Y 2017 Artificial intelligence and intelligent transportation: Driving into the 3rd axial age with ITS IEEE Intelligent transportation systems magazine 9(4) pp 6-9
[4]. Nadikattu R R 2016 The emerging role of artificial intelligence in modern society International Journal of Creative Research Thoughts
[5]. Gui J Sun Z Wen Y Tao D and Ye J 2021 A review on generative adversarial networks: Algorithms theory and applications IEEE transactions on knowledge and data engineering 35(4) 3313-3332
[6]. Aggarwal A Mittal M and Battineni G 2021 Generative adversarial network: An overview of theory and applications International Journal of Information Management Data Insights 1(1) 100004
[7]. Srivastava A Valkov L Russell C Gutmann M U and Sutton C 2017 Veegan: Reducing mode collapse in gans using implicit.
[8]. Goodfellow I et al 2014 Generative Adversarial Nets Advances in Neural Information Processing Systems 27 (NIPS)
[9]. Weng L 2019 From gan to wgan arXiv preprint arXiv:1904 08994
[10]. Smith S L Kindermans P J Ying C and Le Q V 2017 Don’t decay the learning rate increase the batch size arXiv preprint arXiv:1711 00489