







1. Introduction
In today's digital era, personalized recommendation systems play a vital role in enhancing user satisfaction and engagement across a wide range of platforms and services.These systems offer customized content to users by analyzing their behavior, preferences, and historical data. For example, platforms like Netflix and [1]Amazon utilize personalized recommendation systems to suggest movies, TV shows, and products based on individual user data. This personalized approach not only facilitates content discovery but also increases user satisfaction and loyalty to the platform. To further enhance the effectiveness of personalized recommendation systems, prompt engineering technology can be integrated. Prompt engineering involves adjusting input prompts to guide model output, ensuring that recommendations are consistent and aligned with user preferences. By leveraging prompt engineering techniques, personalized recommendation systems can deliver more accurate and relevant recommendations, thereby improving overall user experience. By analyzing user data and offering tailored recommendations, these systems not only enhance user satisfaction and engagement but also promote long-term user loyalty and platform growth. Through the integration of prompt engineering technology, personalized recommendation systems can further optimize recommendations, ensuring a seamless and personalized user experience.
2. Related Work
2.1. Development and challenge of personalized recommendation system
With the development of computer technology, the recommendation technology adopted by the recommendation system is mainly based on the early user-item-based data matrix decomposition technology, and gradually develops in the direction of integrating with data mining, machine learning, artificial intelligence and other technologies, so as to deeply explore the potential preferences of users' behaviors and build a more accurate user preference model. Zhang and Jiao (2007) proposed a recommendation system based on association classification, aiming at personalized recommendation services in B2C e-commerce applications. Their research combines the concepts of relational classification and personalized recommendation to achieve targeted recommendations by analyzing users' historical purchasing behavior and product attributes. Therefore, the work of Zhang and Jiao (2007) emphasized the potential of association classification methods in e-commerce applications. [2]By combining association classification technology with recommendation system, they provide a new idea and solution for personalized recommendation. This research is of great significance to the development of personalized recommendation technology in the field of e-commerce, and provides beneficial reference and enlightenment for realizing more accurate and effective personalized recommendation.
2.2. User experience optimization
In large software organizations, the challenges and implications of user experience optimization extend beyond the lack of customer data sharing. The research of Fabijan et al. (2016) also reveals other aspects of the problem, such as:
1. Limitations of personalized recommendation: [3]Lack of customer data sharing may lead to performance degradation of personalized recommendation systems. 2. Reduced user engagement: If users feel that their data is not properly protected and used, they may have doubts about participating in the use of software products. 3. Trust and privacy issues: The lack of customer data sharing can raise concerns about the privacy and security of personal data.
Personalized recommendation system has shown vigorous development in the aspect of diversified recommendation algorithms. Among them, the [4]IBM.com personalized user experience work studied by Karat et al. (2003) explored the application of collaborative filtering, content-based recommendation and other algorithms in personalized recommendation. The research of Karat et al. highlights the importance of data in recommendation algorithms, laying a solid foundation for the development and performance improvement of personalized recommendation systems.
2.3. LLMOps-Driven Personalized Recommendation Systems
According to the study of Kulkarni et al. (2023), the application of LLMOps (Large Language Model Operations) in enterprises has attracted wide attention. LLMOps refers to the operation and strategy of managing, optimizing and extending LLM (Large Language Model), which is of great significance for the development of personalized recommendation system. With the progress of large-scale language model technology and the continuous evolution of LLMOps, people begin to realize the potential of LLMOps in personalized recommendation system. [5]Through the personalized recommendation system driven by LLMOps, the ability of large-scale language models can be better utilized to provide users with more personalized and accurate recommendations, thus improving the user experience and the competitiveness of the platform.
Despite the promising prospects of LLMOps, there remain several challenges and limitations to address. These include constraints related to model size and computational resources, as well as considerations regarding data privacy and security. Additionally, there is a need for ongoing algorithm and model optimization to fully realize the potential of LLMOps in personalized recommendation systems.Integrating prompt engineering technology into LLMOps-driven recommendation systems offers several advantages. Prompt engineering enables the customization of input prompts to guide model output, ensuring that recommendations are aligned with user preferences. By incorporating prompt engineering techniques, LLMOps-driven recommendation systems can further enhance recommendation accuracy and relevance, ultimately providing users with a more intelligent and personalized recommendation experience.
However, despite the promising application of LLMOps in personalized recommendation [6]systems, there are still some challenges and limitations. These include model size and computational resource constraints, data privacy and security considerations, and the need for algorithm and model optimization. In the future, with the continuous progress of technology and the maturity of LLMOps, it is believed that LLMops-driven personalized recommendation systems will become an important development direction in the field of personalized recommendation, and bring users a more intelligent and personalized recommendation experience.
1)LLMOps implementation steps
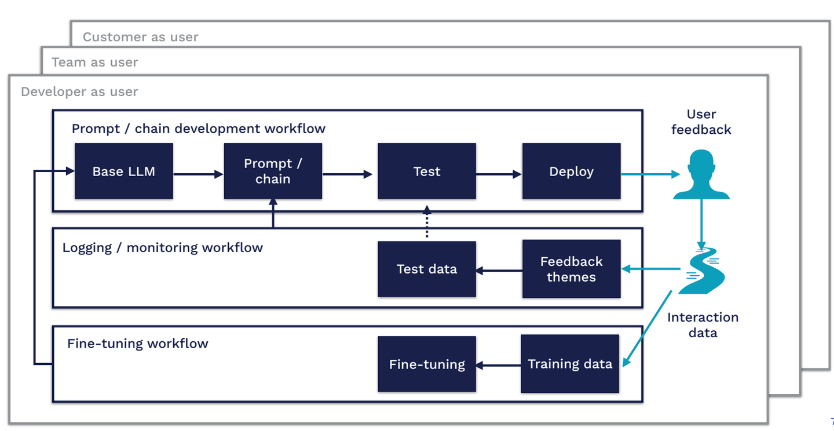
Figure 1. Step-by-step process of LLMops
One of the issues that LLM mentioned in its production survey was model accuracy and hallucinations.
This means that getting output from the LLM API in the format you want can take some iteration, and, if LLMS don't have the specific knowledge they need, they can hallucinate. To address these issues, you can adapt the base model to downstream tasks by:
2) Prompt Engineering: is a technique of adjusting the input to make the output conform to your expectations. You can use different techniques to improve your Prompt. One way is to provide some examples of the expected output format. This is similar to zero-sample or small-sample learning Settings. Tools such as LangChain or HoneyHive have emerged to help you manage and version prompt templates.
3) Fine-tuning pre-trained models is a known technique in [7]ML. It can help improve the performance of the model on specific tasks. Although this increases the training effort, it reduces the inference cost. The cost of the LLM API depends on the input and output sequence length. Therefore, reducing the number of tokens you enter reduces API costs because you no longer have to provide an example in the prompt.
4) External Data: The underlying model often lacks contextual information (e.g., access to some specific document or email) and can quickly become obsolete (e.g., GPT-4 was trained on data until September 2021). Because LLMS can hallucinate if they don't have enough information, we need to be able to give them access to relevant external data. There are already tools available, such as LlamaIndex (GPT Index), LangChain, or DUST, that can act as a central interface to connect (" link ") LLMS to other agents and external data.
5) Embeddings: Another approach is to extract information from the LLM API in the form of embeddings (for example, movie summaries or product descriptions) and build applications on top of them (for example, search, compare, or recommend). If np.array is not enough to store your long-term memory embedding, you can use vector databases such as Pinecone, Weaviate, or Milvus.
3. Methodology
3.1. Prompt engineering technology
Prompt engineering refers to adjusting the input prompts to guide the model to produce the desired output when using the AI model. Prompt engineering can help the model better understand the user's intentions, reduce misunderstandings and error outputs, and thus improve the system's performance and user experience. A variety of Prompt engineering techniques can be used for different tasks and scenarios. [8]A common technique in natural language processing tasks is to use sample output to guide the model to generate a specific type of text. For example, in a language translation task, a pair of sentences can be provided as input prompts to guide the model to produce the corresponding translation result. In image generation tasks, Prompt engineering techniques can direct the model to generate images of a particular style, content, or composition by adjusting the input visual description or adding specific markup. In conclusion, the choice of the appropriate Prompt engineering technology depends on the specific task requirements and the characteristics of the model, through proper Prompt design, you can improve the performance and scope of the model, and achieve a more intelligent and personalized output. There are two applications of prompt engineering technology in personalized recommendation system:
1. In the field of personalized recommendation, Prompt engineering technology can improve the accuracy and user experience of the recommendation system. For example, consider an e-commerce platform that wants to recommend personalized items to users. [9]With Prompt engineering, you can design A series of input prompts that are specific to user preferences, such as "Based on your recent purchase of X, we recommend you browse Y" or "Your favorite category is Z, and we recommend related product A." By analyzing a user's purchase history, browsing behavior, and preferences, as well as actual data related to those behaviors, you can generate personalized Prompt and guide the recommendation system to produce recommendations that are more accurate and aligned with the user's interests. In this way, users will get a more personalized recommendation experience, increasing user satisfaction and loyalty to the platform.
2. Prompt engineering can also play an important role in user experience. Taking intelligent voice assistant as an example, Prompt engineering can improve the response accuracy and user interaction experience of voice assistant. By designing input prompts with clear semantics, such as "Please tell me what you want to do" or "[10]What help do you need," the voice assistant can be guided to better understand the user's intentions and provide accurate responses. By analyzing user interaction data and actual conversation records with the voice assistant, the design of input prompts can be optimized and a more intelligent and personalized interactive experience can be provided. In this way, users will be more willing to use voice assistants and feel satisfied with their interactive experience, improving user recognition and frequency of use of products.
3.2. Introduction to the application of LLMOps in personalized recommendation system
LLMOps, or Large Language Model Operations, refers to the operation and strategy of managing, optimizing, and extending Large Language Models (LLMs) within personalized recommendation systems. LLMOps serves as the backbone of personalized recommendation systems, driving their effectiveness and ensuring their ability to meet user demands and expectations in today's dynamic digital landscape. The working principle of LLMOps revolves around managing, optimizing, and extending Large Language Models to enhance the performance of personalized recommendation systems. By employing advanced techniques such as model fine-tuning, resource allocation, and optimization of computational processes, LLMOps ensures that LLMs operate efficiently and effectively within recommendation systems. The impact of LLMOps on recommended system performance is profound, as it leads to improved recommendation accuracy, reduced latency in generating recommendations, and enhanced user satisfaction and engagement[11]. Ultimately, LLMOps empowers personalized recommendation systems to deliver more accurate, relevant, and timely recommendations, thereby optimizing the overall user experience and driving business success.
3.3. Comparative analysis of LLMOps and MLOps
1) Data pipeline
LLMOps emphasizes trust in data sources and interpretability of data, and tends to capture less but higher quality data. In the case of e-commerce, LLMOps may choose to use only sales data from reliable suppliers and ensure that this data is accurate and complete. Its data management process includes rigorous screening and evaluation of data sources, possibly vendor reputation investigations and verification to ensure the credibility of the data. Subsequently, the data is cleaned and preprocessed to eliminate any outliers and missing values and ensure data quality. [12]Finally, through data annotation and classification, such as classifying sales data according to product category, sales region, etc., in order to better apply to the training and testing of recommendation systems or predictive models. In contrast, MLOps focuses more on the diversity and quantity of data and on improving data quality through data engineering and data science approaches. In e-commerce, MLOps may collect data from different channels, including sales data, user behavior data, marketing data, etc., and build sophisticated data warehouses and data lakes to store and integrate this data. Then, data mining and machine learning technologies are used to conduct in-depth analysis and feature engineering of the data, such as extracting user preference characteristics through user behavior data, so as to achieve personalized recommendation. Finally, model training and tuning techniques are used to improve the effect and performance of the model.
2) Model experiment process
LLMOps emphasizes the normativity and reproducibility of experiments, requiring detailed recording and interpretation of model experiments, including experimental steps, data sets, model parameters, etc. Experimental design and execution are required, as well as analysis and interpretation of experimental results.[13] In addition, interpretability analysis of the model is also required to better understand the operating mechanism of the model. The design of model experiments under LLMOps focuses on specification and reproducibility. MLOps pays more attention to the iteration speed and experimental efficiency of the model, shorens the experimental period and improves the experimental efficiency through automatic and intelligent methods. Automated machine learning and automated experimentation platforms are needed to quickly build and train models. The model needs to be evaluated and tuned to improve its performance and accuracy. Finally, the model needs to be deployed and applied to realize the practical application value of the model. The model experiment design under [14]
3) Model evaluation
LLMOps prefers to use interpretable evaluation metrics such as accuracy, recall, etc., in order to better understand the performance of the model. MLOps focuses more on the use of complex and more representative metrics such as OC-ROC, F1 scores, etc., to assess model performance more comprehensively. In conclusion, LLMOps and MLOps have some differences in the model experiment process and evaluation process, but both are committed to improving the performance and interpretability of the model to achieve better business results and user experience.
4) Algorithm selection and application
LLMOps prefers to choose algorithms that have clear physical meaning and interpretability, such as decision trees, linear regression, etc., in order to better understand how the model operates. In addition, the stability and reliability of the algorithm need to be considered. The application process includes: algorithm selection and adjustment, model training and verification, model application and optimization[15-17]. MLOps pays more attention to the innovation and experimental effect of algorithms, and actively explores and applies new algorithms, such as neural networks and deep learning, to improve model performance. In addition, factors such as the advanced nature and efficiency of the algorithm need to be considered. The application process includes: algorithm research and selection, model design and training, model evaluation and application, etc.
5) Model deployment and monitoring
LLMOps emphasizes the stability and reliability of the model. In the process of model deployment and monitoring, it is necessary to formulate corresponding emergency plans, monitor the operation of the model in real time, and discover and solve problems in time. At the same time, LLMOps focuses on the interpretability and maintainability of the model, which helps to better understand the operation and performance of the model. MLOps focuses more on model efficiency and iteration speed, with intelligent methods to automate deployment and monitoring, reducing manual intervention. MLOps usually adopts real-time monitoring and alarm mechanism to discover and solve problems in time to ensure efficient and stable operation of the model. In addition, MLOps also focuses on the scalability and scalability of the model to adapt to different scenarios and requirements.
Through the above process, LLMOps and MLOps have different focuses on algorithm selection and application, model deployment and monitoring, but both aim to improve the performance, stability, and maintainability of models to meet business needs and improve user experience.
3.4. LLMOps application value
LLMOps is a method to deal with the future application of ultra-large scale machine learning technology to Ops operation and maintenance management, which can help enterprises more intuitively realize the automatic deployment and management of machine learning models through human natural language, and improve efficiency and reliability. Its application value is: 1) Automated machine learning model deployment: LLM's MLOps can reduce human intervention and improve model deployment efficiency and reliability by automating the deployment of machine learning models. 2) Model monitoring and management: LLM's MLOps can monitor and manage the running state of machine learning models, timely discover and solve problems in the model, and ensure the normal operation of the model. 3) Resource utilization optimization: LLMOps can monitor and analyze the resource utilization of IT systems through machine learning algorithms, optimize the resource allocation of the system, improve resource utilization, and reduce costs. 4) Automatic capacity expansion and contraction: LLMOps can automatically expand and shrink the capacity to cope with system load changes, allocate IT system resources based on actual requirements, and improve system performance and reliability. 5) Fault diagnosis and self-healing capability: LLMOps can diagnose and self-heal IT systems through machine learning algorithms, discover and solve faults in time, improve system reliability, and reduce downtime and maintenance costs. 6) Cost prediction and control: LLMOps can predict and control the operation and maintenance costs of IT systems through machine learning algorithms, helping enterprises better grasp the operation and maintenance costs, and optimizing the operation and maintenance strategies of future IT ultra-large scale algorithm model systems.
4. Conclusion and prospect
In conclusion, the advent of LLMOps heralds a new era in managing the lifecycle of LLM-driven applications, presenting both opportunities and challenges for enterprises. [18]The complexity of engineering technology involved demands specialized teams for development and maintenance, while ensuring data security remains paramount to safeguard against breaches and misuse. The integration of LLMOps into personalized recommendation systems underscores its potential in optimizing user experience. By leveraging LLMOps, enterprises can enhance the efficiency and reliability of large-scale machine learning models, driving personalized recommendations that align closely with user preferences. Looking ahead, LLMOps is poised to witness widespread adoption as AI technology continues to evolve. LLMOps will evolve to deliver more efficient, trustworthy, and secure machine learning services, ushering in a new era of personalized recommendation systems that elevate user experience to new heights.
References
[1]. Zhao, H., Si, L., Li, X., & Zhang, Q. (2017). Recommending Complementary Products in E-Commerce Push Notifications with a Mixture Model Approach. Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval.
[2]. Fang, C., Li, X., Fan, Z., Xu, J., Nag, K., Korpeoglu, E., Kumar, S., & Achan, K. (2024). LLM-Ensemble: Optimal Large Language Model Ensemble Method for E-commerce Product Attribute Value Extraction.
[3]. Kulkarni, Akshay, et al. "LLMs for Enterprise and LLMOps." Applied Generative AI for Beginners: Practical Knowledge on Diffusion Models, ChatGPT, and Other LLMs. Berkeley, CA: Apress, 2023. 117-154.
[4]. Arawjo, I., Swoopes, C., Vaithilingam, P., Wattenberg, M., & Glassman, E. (2023). ChainForge: A Visual Toolkit for Prompt Engineering and LLM Hypothesis Testing. arXiv preprint arXiv:2309.09128.
[5]. D. Hershey and D. Oppenheimer (2023).. Development tools for language models - Predicting the future
[6]. Wan, Weixiang, et al. "Progress in artificial intelligence applications based on the combination of self-driven sensors and deep learning." arXiv preprint arXiv:2402.09442 (2024).
[7]. Wang, Yong, et al. "Construction and application of artificial intelligence crowdsourcing map based on multi-track GPS data." arXiv preprint arXiv:2402.15796 (2024).
[8]. Zheng, Jiajian, et al. "The Random Forest Model for Analyzing and Forecasting the US Stock Market in the Context of Smart Finance." arXiv preprint arXiv:2402.17194 (2024).
[9]. Yang, Le, et al. "AI-Driven Anonymization: Protecting Personal Data Privacy While Leveraging Machine Learning." arXiv preprint arXiv:2402.17191 (2024).
[10]. Cheng, Qishuo, et al. "Optimizing Portfolio Management and Risk Assessment in Digital Assets Using Deep Learning for Predictive Analysis." arXiv preprint arXiv:2402.15994 (2024).
[11]. Zhu, Mengran, et al. "Utilizing GANs for Fraud Detection: Model Training with Synthetic Transaction Data." arXiv preprint arXiv:2402.09830 (2024).
[12]. Wu, Jiang, et al. "Data Pipeline Training: Integrating AutoML to Optimize the Data Flow of Machine Learning Models." arXiv preprint arXiv:2402.12916 (2024).
[13]. Yu, Hanyi, et al. "Machine Learning-Based Vehicle Intention Trajectory Recognition and Prediction for Autonomous Driving." arXiv preprint arXiv:2402.16036 (2024).
[14]. Huo, Shuning, et al. "Deep Learning Approaches for Improving Question Answering Systems in Hepatocellular Carcinoma Research." arXiv preprint arXiv:2402.16038 (2024).
[15]. K. Tan and W. Li, "Imaging and Parameter Estimating for Fast Moving Targets in Airborne SAR," in IEEE Transactions on Computational Imaging, vol. 3, no. 1, pp. 126-140, March 2017, doi: 10.1109/TCI.2016.2634421.
[16]. K. Tan and W. Li, "A novel moving parameter estimation approach offast moving targets based on phase extraction," 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 2015, pp. 2075-2079, doi: 10.1109/ICIP.2015.7351166.
[17]. K. Xu, X. Wang, Z. Hu and Z. Zhang, "3D Face Recognition Based on Twin Neural Network Combining Deep Map and Texture," 2019 IEEE 19th International Conference on Communication Technology (ICCT), Xi'an, China, 2019, pp. 1665-1668, doi: 10.1109/ICCT46805.2019.8947113.
[18]. Shi, Peng, Yulin Cui, Kangming Xu, Mingmei Zhang, and Lianhong Ding. 2019. "Data Consistency Theory and Case Study for Scientific Big Data" Information 10, no. 4: 137. https://doi.org/10.3390/info10040137.
Cite this article
Shi,C.;Liang,P.;Wu,Y.;Zhan,T.;Jin,Z. (2024). Maximizing user experience with LLMOps-driven personalized recommendation systems. Applied and Computational Engineering,64,100-106.
Data availability
The datasets used and/or analyzed during the current study will be available from the authors upon reasonable request.
Disclaimer/Publisher's Note
The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of EWA Publishing and/or the editor(s). EWA Publishing and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content.
About volume
Volume title: Proceedings of the 6th International Conference on Computing and Data Science
© 2024 by the author(s). Licensee EWA Publishing, Oxford, UK. This article is an open access article distributed under the terms and
conditions of the Creative Commons Attribution (CC BY) license. Authors who
publish this series agree to the following terms:
1. Authors retain copyright and grant the series right of first publication with the work simultaneously licensed under a Creative Commons
Attribution License that allows others to share the work with an acknowledgment of the work's authorship and initial publication in this
series.
2. Authors are able to enter into separate, additional contractual arrangements for the non-exclusive distribution of the series's published
version of the work (e.g., post it to an institutional repository or publish it in a book), with an acknowledgment of its initial
publication in this series.
3. Authors are permitted and encouraged to post their work online (e.g., in institutional repositories or on their website) prior to and
during the submission process, as it can lead to productive exchanges, as well as earlier and greater citation of published work (See
Open access policy for details).
References
[1]. Zhao, H., Si, L., Li, X., & Zhang, Q. (2017). Recommending Complementary Products in E-Commerce Push Notifications with a Mixture Model Approach. Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval.
[2]. Fang, C., Li, X., Fan, Z., Xu, J., Nag, K., Korpeoglu, E., Kumar, S., & Achan, K. (2024). LLM-Ensemble: Optimal Large Language Model Ensemble Method for E-commerce Product Attribute Value Extraction.
[3]. Kulkarni, Akshay, et al. "LLMs for Enterprise and LLMOps." Applied Generative AI for Beginners: Practical Knowledge on Diffusion Models, ChatGPT, and Other LLMs. Berkeley, CA: Apress, 2023. 117-154.
[4]. Arawjo, I., Swoopes, C., Vaithilingam, P., Wattenberg, M., & Glassman, E. (2023). ChainForge: A Visual Toolkit for Prompt Engineering and LLM Hypothesis Testing. arXiv preprint arXiv:2309.09128.
[5]. D. Hershey and D. Oppenheimer (2023).. Development tools for language models - Predicting the future
[6]. Wan, Weixiang, et al. "Progress in artificial intelligence applications based on the combination of self-driven sensors and deep learning." arXiv preprint arXiv:2402.09442 (2024).
[7]. Wang, Yong, et al. "Construction and application of artificial intelligence crowdsourcing map based on multi-track GPS data." arXiv preprint arXiv:2402.15796 (2024).
[8]. Zheng, Jiajian, et al. "The Random Forest Model for Analyzing and Forecasting the US Stock Market in the Context of Smart Finance." arXiv preprint arXiv:2402.17194 (2024).
[9]. Yang, Le, et al. "AI-Driven Anonymization: Protecting Personal Data Privacy While Leveraging Machine Learning." arXiv preprint arXiv:2402.17191 (2024).
[10]. Cheng, Qishuo, et al. "Optimizing Portfolio Management and Risk Assessment in Digital Assets Using Deep Learning for Predictive Analysis." arXiv preprint arXiv:2402.15994 (2024).
[11]. Zhu, Mengran, et al. "Utilizing GANs for Fraud Detection: Model Training with Synthetic Transaction Data." arXiv preprint arXiv:2402.09830 (2024).
[12]. Wu, Jiang, et al. "Data Pipeline Training: Integrating AutoML to Optimize the Data Flow of Machine Learning Models." arXiv preprint arXiv:2402.12916 (2024).
[13]. Yu, Hanyi, et al. "Machine Learning-Based Vehicle Intention Trajectory Recognition and Prediction for Autonomous Driving." arXiv preprint arXiv:2402.16036 (2024).
[14]. Huo, Shuning, et al. "Deep Learning Approaches for Improving Question Answering Systems in Hepatocellular Carcinoma Research." arXiv preprint arXiv:2402.16038 (2024).
[15]. K. Tan and W. Li, "Imaging and Parameter Estimating for Fast Moving Targets in Airborne SAR," in IEEE Transactions on Computational Imaging, vol. 3, no. 1, pp. 126-140, March 2017, doi: 10.1109/TCI.2016.2634421.
[16]. K. Tan and W. Li, "A novel moving parameter estimation approach offast moving targets based on phase extraction," 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 2015, pp. 2075-2079, doi: 10.1109/ICIP.2015.7351166.
[17]. K. Xu, X. Wang, Z. Hu and Z. Zhang, "3D Face Recognition Based on Twin Neural Network Combining Deep Map and Texture," 2019 IEEE 19th International Conference on Communication Technology (ICCT), Xi'an, China, 2019, pp. 1665-1668, doi: 10.1109/ICCT46805.2019.8947113.
[18]. Shi, Peng, Yulin Cui, Kangming Xu, Mingmei Zhang, and Lianhong Ding. 2019. "Data Consistency Theory and Case Study for Scientific Big Data" Information 10, no. 4: 137. https://doi.org/10.3390/info10040137.