







1. Introduction
In the realm of data science, deep learning has emerged as a transformative force, reshaping how we analyze and derive insights from vast and complex datasets. Unlike traditional machine learning techniques, which often require handcrafted features and struggle with high-dimensional data, deep learning models autonomously learn hierarchical representations of data, leading to remarkable performance improvements in a wide array of tasks. At the core of deep learning lies the neural network architecture, a computational framework inspired by the biological neural networks of the human brain. These architectures, such as Convolutional Neural Networks (CNNs), Recurrent Neural Networks (RNNs), and Transformers, have proven to be exceptionally adept at processing different types of data, ranging from images and text to sequential and time-series data. Convolutional Neural Networks, for instance, have revolutionized computer vision tasks by preserving spatial hierarchies in visual data, allowing them to excel in tasks like image classification, object detection, and image segmentation. Recurrent Neural Networks, on the other hand, are tailored for sequential data processing, making them ideal for tasks such as natural language processing, speech recognition, and time-series forecasting. Meanwhile, Transformers have introduced a paradigm shift in sequence modeling by leveraging self-attention mechanisms to capture long-range dependencies in data, leading to breakthroughs in tasks like machine translation, text generation, and language understanding. However, the success of deep learning models is not solely attributed to their architectural design. Optimization algorithms play a critical role in training these models effectively, ensuring that they converge to meaningful solutions while avoiding issues like overfitting. Techniques like Stochastic Gradient Descent (SGD), Adam, and RMSprop are commonly used to minimize the loss function during training, enabling the models to learn from large-scale datasets efficiently [1]. Moreover, regularization techniques such as dropout and L1/L2 regularization are employed to prevent overfitting and improve the generalization of deep learning models. These techniques add constraints to the optimization process, helping the models generalize well to unseen data and improving their robustness in real-world scenarios. In this paper, we delve into the theoretical foundations of deep learning, exploring the nuances of neural network architectures, optimization algorithms, and regularization techniques. We also examine practical applications of deep learning across various domains, highlighting its transformative impact on industries such as healthcare, finance, and retail. Additionally, we conduct a comparative analysis to evaluate the performance of deep learning models against traditional machine learning methods, providing insights into their efficacy and potential limitations. Through this comprehensive exploration, we aim to elucidate the significance of deep learning in data science and pave the way for further advancements in this rapidly evolving field.
2. Theoretical Foundations
2.1. Neural Network Architectures
Deep learning's success in data science largely depends on the architecture of the neural networks employed. In this section, we delve into various architectures such as Convolutional Neural Networks (CNNs), Recurrent Neural Networks (RNNs), and Transformer models, discussing their unique capabilities and limitations in processing different types of data. CNNs excel in analyzing visual imagery by preserving the spatial hierarchy, which makes them ideal for tasks like image classification and object detection. For instance, a CNN might utilize a series of convolutional layers to detect edges in early layers, shapes in middle layers, and specific objects in deeper layers, as demonstrated by their pivotal role in systems like autonomous vehicles and facial recognition technologies. Recurrent Neural Networks (RNNs) are favored for their ability to handle sequential data like time-series or natural language [2]. An RNN processes data sequentially, maintaining an internal state that captures information about previous elements in the sequence, which is crucial for applications such as speech recognition or language translation. For example, in language modeling, RNNs predict the probability of the next word in a sentence based on the previous words, which is fundamental for generating coherent text or performing effective machine translation. Transformers provide an advanced approach to managing sequence-based problems without the need for recurrent processing [3]. Unlike RNNs, Transformers use self-attention mechanisms to weigh the importance of different words in a sentence, regardless of their positional distance from each other. This architecture allows for more parallelization during training and leads to significant improvements in tasks such as natural language processing (NLP), where models like BERT and GPT have set new standards for understanding and generating human-like text.
2.2. Optimization Algorithms
Optimization algorithms are critical in training deep learning models effectively. This subsection focuses on algorithms like Stochastic Gradient Descent (SGD), Adam, and RMSprop, explaining their roles and mechanisms in minimizing the loss function during training. SGD, for example, updates the model parameters using a fixed-size step based on the gradient of the loss function, which helps in navigating the complex landscapes of high-dimensional parameter spaces typical of deep networks.
Stochastic Gradient Descent (SGD) is a foundational optimization technique in neural network training. Unlike traditional gradient descent, which computes the gradient of the cost function using the entire dataset to update model parameters, SGD updates parameters incrementally for each training example or small batch. This incremental approach helps in reducing the computational burden, making it feasible to train on large datasets. Mathematically, the parameter update rule in SGD is given by:
\( {θ_{new}}={θ_{old}}-η∙{∇_{θ}}J(θ; {x^{(i)}}, {y^{(i)}}) \) (1)
where θ represents the parameters of the model, 𝜂η is the learning rate, and \( {∇_{θ}}J(θ; {x^{(i)}}, {y^{(i)}}) \) is the gradient of the cost function 𝐽 with respect to the parameters for the i-th data point ( \( {x^{(i)}}, {y^{(i)}} \) ). This method benefits from faster iterations and a natural regularization effect due to the noise introduced by the random selection of data points, which helps prevent overfitting [4].
Adam, which stands for Adaptive Moment Estimation, combines the benefits of two other extensions of SGD—Root Mean Square Propagation (RMSprop) and Momentum. Adam calculates an exponential moving average of the gradient and the squared gradient, and the parameters beta1 and beta2 control the decay rates of these moving averages. This adjustment helps in handling sparse gradients on noisy problems, which is particularly useful in applications such as training large neural networks for computer vision.
2.3. Regularization Techniques
To prevent overfitting and enhance the generalization of deep learning models, regularization techniques are employed. This part covers methods such as dropout, L1 and L2 regularization, and early stopping. Dropout, specifically, involves randomly setting a fraction of input units to zero at each update during training time, which helps in preventing neurons from co-adapting too much. L1 and L2 regularization add a penalty on the magnitude of coefficients. L1 regularization can yield sparse models where some coefficients can become exactly zero [5]. This is useful in feature selection. L2 regularization, on the other hand, tends to spread error among all the terms and is known to be less sensitive to outliers, thereby promoting model reliability. Early stopping, a form of regularization used to avoid overfitting when training a learner with an iterative method, such as gradient descent, involves ending model training as soon as the validation performance begins to deteriorate, despite continued improvement in training performance.
3. Practical Applications
3.1. Healthcare
Deep learning has emerged as a transformative force in healthcare, offering innovative solutions to complex challenges in disease diagnosis and genetic research. One of the most notable applications is in diagnostic imaging, where convolutional neural networks (CNNs) have demonstrated remarkable performance in detecting and classifying various medical conditions, including cancerous lesions in mammography. These CNN models leverage their ability to extract meaningful features from images, enabling accurate and timely diagnoses that rival those made by trained radiologists. In addition to diagnostic imaging, deep learning plays a crucial role in genomics, where it aids in predicting gene activation patterns and understanding disease mechanisms [6]. By analyzing vast genomic datasets, deep learning techniques can identify subtle genetic variations associated with diseases, paving the way for personalized medicine approaches tailored to individual patients. Moreover, the speed and accuracy of deep learning models in analyzing genomic data surpass traditional methods, enabling researchers to make significant strides in unraveling the complexities of genetic diseases. The integration of deep learning into healthcare practices not only improves diagnostic accuracy but also enhances patient outcomes by facilitating early disease detection and personalized treatment strategies. However, challenges such as data privacy concerns, model interpretability, and regulatory compliance remain areas of ongoing research and development. Addressing these challenges is crucial to ensuring the safe and effective deployment of deep learning technologies in healthcare settings, ultimately leading to improved patient care and outcome.
3.2. Finance
In the finance sector, deep learning has revolutionized various aspects of financial analytics, including risk assessment, algorithmic trading, and fraud detection. One of the primary applications is in credit risk prediction, where deep learning models analyze vast amounts of financial data to assess the creditworthiness of individuals and businesses. By considering numerous variables such as transaction history, user behavior, and macroeconomic factors, these models can provide more accurate risk assessments compared to traditional methods like logistic regression. Furthermore, deep learning plays a crucial role in algorithmic trading, where it enables high-frequency trading strategies that leverage historical data, sentiment analysis, and market data to predict stock movements. Deep neural networks excel in identifying complex patterns in financial data, allowing traders to make informed decisions and adapt to market dynamics in real-time [7]. Additionally, deep learning models are instrumental in fraud detection, where they help identify fraudulent activities that evade traditional detection systems. By analyzing transaction patterns and user behavior, deep learning models can detect anomalies indicative of fraud and flag suspicious activities for further investigation. While the adoption of deep learning in finance offers significant benefits in terms of accuracy and efficiency, challenges such as model interpretability, regulatory compliance, and cybersecurity remain areas of concern. Addressing these challenges is essential to ensuring the robustness and reliability of deep learning applications in the finance sector, ultimately safeguarding the integrity of financial markets and protecting investors' interests.
3.3. Retail
Deep learning technologies have transformed the retail industry, revolutionizing customer experience, and operational efficiency. One of the key applications is in personalized recommendation systems, where deep learning models analyze vast amounts of customer data, including past purchases, browsing history, and search queries, to predict products that customers are likely to be interested in. By leveraging advanced machine learning algorithms, these recommendation systems can deliver personalized shopping experiences that enhance customer satisfaction and increase sales. Moreover, deep learning models play a critical role in inventory management, where they forecast product demand based on sales data, seasonal trends, and economic indicators. By accurately predicting demand, retailers can optimize their inventory levels to prevent overstock and understock situations, thereby reducing carrying costs and maximizing sales opportunities [8]. Additionally, deep learning assists in optimizing pricing strategies by analyzing competitors' pricing, market demand, and consumer behavior. By dynamically adjusting prices in real-time, retailers can maximize profit margins while ensuring competitiveness in the market. While the adoption of deep learning in retail offers significant benefits in terms of customer engagement and operational efficiency, challenges such as data privacy concerns, ethical considerations, and regulatory compliance remain areas of concern. Addressing these challenges is essential to ensuring the responsible and ethical deployment of deep learning technologies in the retail sector, ultimately fostering trust and loyalty among customers while driving business growth [9].
4. Comparative Analysis
4.1. Performance Metrics
In evaluating the effectiveness of deep learning versus traditional predictive analytics models, key performance metrics such as accuracy, precision, recall, and F1-score are employed. A detailed quantitative analysis of these metrics reveals that deep learning models often outperform their traditional counterparts, particularly in tasks involving large and complex datasets. For instance, a comparative study using CNNs for image recognition tasks reported an accuracy improvement from 80% with traditional machine learning models (such as SVM and random forests) to over 95% with CNNs, as shown in Table 1. Precision and recall metrics also show significant improvements, which is critical in applications like medical diagnostics where false negatives or false positives can have serious implications. The F1-score, which is the harmonic mean of precision and recall, is particularly useful for evaluating models on imbalanced datasets, common in real-world scenarios. Deep learning models tend to achieve higher F1-scores compared to traditional models, demonstrating their superior ability to balance recall and precision [10].
Table 1. Comparative Performance Metrics of Traditional ML vs. Deep Learning Models in Image Recognition
Model Type | Accuracy | Precision | Recall | F1-Score |
Traditional ML (SVM, RF) | 80% | 78% | 75% | 76.5% |
Deep Learning (CNN) | 95% | 92% | 90% | 91% |
4.2. Computational Efficiency
While deep learning models offer significant advantages in terms of performance, they also come with higher computational demands. These models require substantial processing power and memory, particularly when training large networks on vast datasets. However, the advent of GPU computing has dramatically improved the computational efficiency of training deep learning models. GPUs offer parallel processing capabilities that are well-suited to the matrix and vector operations fundamental to neural network training. For example, training a deep neural network on a standard CPU might take weeks, but can be reduced to days or even hours with GPU acceleration. Furthermore, techniques such as distributed computing allow deep learning tasks to be scaled by training models across multiple GPUs simultaneously, effectively managing large computational loads [11]. Despite these advances, the energy consumption and hardware costs associated with deep learning models are considerable, which might not be justifiable for all applications, particularly those with limited budget or computing resources. Figure 1 illustrates the training times for deep learning models using different technologies.
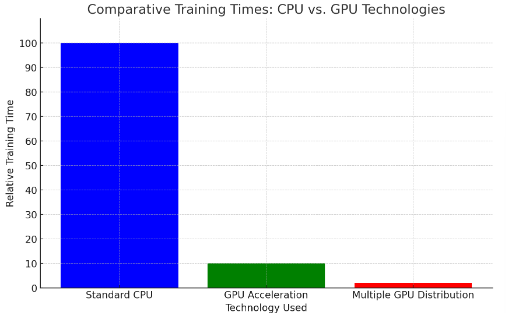 Figure 1. Comparative Training Times: CPU vs. GPU Technologies
Figure 1. Comparative Training Times: CPU vs. GPU Technologies
4.3. Limitations and Challenges
Despite their robust performance, deep learning models face several limitations and challenges that can affect their practical deployment. One of the primary concerns is the dependency on large amounts of training data. Deep learning models are inherently data-hungry; they require vast datasets to perform well, which can be a significant hurdle in fields where data is scarce or expensive to acquire. Moreover, the issue of interpretability remains a major challenge. Unlike traditional models where decision processes might be more transparent (e.g., decision trees), deep learning models often operate as "black boxes," where the decision-making process is not easily understood. This lack of transparency can be problematic in industries requiring rigorous validation and explanation of model decisions, such as healthcare and finance. Additionally, deep learning models are vulnerable to adversarial attacks—small, intentionally designed perturbations to input data can deceive models into making incorrect decisions. This vulnerability poses security risks, particularly in sensitive applications like autonomous driving and cybersecurity. These challenges necessitate ongoing research and development to find solutions that can mitigate these limitations, ensuring that deep learning models are both powerful and practical tools across various applications.
5. Conclusion
In conclusion, deep learning has cemented its position as a cornerstone of data science, offering unprecedented capabilities to tackle the complexities of modern datasets and address intricate problems across diverse domains. Throughout this paper, we have delved into the theoretical underpinnings of deep learning, exploring the intricacies of neural network architectures, optimization algorithms, and regularization techniques. The practical applications of deep learning in healthcare, finance, and retail underscore its transformative impact on industries worldwide. From enhancing diagnostic accuracy in medical imaging to revolutionizing risk assessment in financial markets, deep learning has reshaped traditional practices and paved the way for innovative solutions that improve outcomes and drive efficiency. However, deep learning is not without its challenges. Data dependency and interpretability issues remain significant hurdles that must be addressed to ensure the robustness and reliability of deep learning models. Efforts to overcome these challenges through ongoing research and development are essential to unlocking the full potential of deep learning across various domains. Looking ahead, the future of deep learning is promising, with continued advancements poised to revolutionize data science and propel innovation to new heights.
Contribution
Yingxuan Chai and Liangning Jin: Conceptualization, Methodology, Data curation, Writing- Original draft preparation, Visualization, Investigation.
References
[1]. Taye, Mohammad Mustafa. "Understanding of machine learning with deep learning: architectures, workflow, applications and future directions." Computers 12.5 (2023): 91.
[2]. Sharifani, Koosha, and Mahyar Amini. "Machine learning and deep learning: A review of methods and applications." World Information Technology and Engineering Journal 10.07 (2023): 3897-3904.
[3]. Mehrish, Ambuj, et al. "A review of deep learning techniques for speech processing." Information Fusion (2023): 101869.
[4]. Soori, Mohsen, Behrooz Arezoo, and Roza Dastres. "Artificial intelligence, machine learning and deep learning in advanced robotics, a review." Cognitive Robotics (2023).
[5]. Aslani, S., and J. Jacob. "Utilisation of deep learning for COVID-19 diagnosis." Clinical Radiology 78.2 (2023): 150-157.
[6]. Ahmed, Shams Forruque, et al. "Deep learning modelling techniques: current progress, applications, advantages, and challenges." Artificial Intelligence Review 56.11 (2023): 13521-13617.
[7]. Mungoli, Neelesh. "Adaptive Feature Fusion: Enhancing Generalization in Deep Learning Models." arXiv preprint arXiv:2304.03290 (2023).
[8]. Pfeiffer, Jonas, et al. "Modular deep learning." arXiv preprint arXiv:2302.11529 (2023).
[9]. Mohammad-Rahimi, Hossein, et al. "Deep learning: a primer for dentists and dental researchers." Journal of Dentistry 130 (2023): 104430.
[10]. Iyortsuun, Ngumimi Karen, et al. "A review of machine learning and deep learning approaches on mental health diagnosis." Healthcare. Vol. 11. No. 3. MDPI, 2023.
[11]. Rai, Nitin, et al. "Applications of deep learning in precision weed management: A review." Computers and Electronics in Agriculture 206 (2023): 107698.
Cite this article
Chai,Y.;Jin,L. (2024). Deep learning in data science: Theoretical foundations, practical applications, and comparative analysis. Applied and Computational Engineering,69,1-6.
Data availability
The datasets used and/or analyzed during the current study will be available from the authors upon reasonable request.
Disclaimer/Publisher's Note
The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of EWA Publishing and/or the editor(s). EWA Publishing and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content.
About volume
Volume title: Proceedings of the 6th International Conference on Computing and Data Science
© 2024 by the author(s). Licensee EWA Publishing, Oxford, UK. This article is an open access article distributed under the terms and
conditions of the Creative Commons Attribution (CC BY) license. Authors who
publish this series agree to the following terms:
1. Authors retain copyright and grant the series right of first publication with the work simultaneously licensed under a Creative Commons
Attribution License that allows others to share the work with an acknowledgment of the work's authorship and initial publication in this
series.
2. Authors are able to enter into separate, additional contractual arrangements for the non-exclusive distribution of the series's published
version of the work (e.g., post it to an institutional repository or publish it in a book), with an acknowledgment of its initial
publication in this series.
3. Authors are permitted and encouraged to post their work online (e.g., in institutional repositories or on their website) prior to and
during the submission process, as it can lead to productive exchanges, as well as earlier and greater citation of published work (See
Open access policy for details).
References
[1]. Taye, Mohammad Mustafa. "Understanding of machine learning with deep learning: architectures, workflow, applications and future directions." Computers 12.5 (2023): 91.
[2]. Sharifani, Koosha, and Mahyar Amini. "Machine learning and deep learning: A review of methods and applications." World Information Technology and Engineering Journal 10.07 (2023): 3897-3904.
[3]. Mehrish, Ambuj, et al. "A review of deep learning techniques for speech processing." Information Fusion (2023): 101869.
[4]. Soori, Mohsen, Behrooz Arezoo, and Roza Dastres. "Artificial intelligence, machine learning and deep learning in advanced robotics, a review." Cognitive Robotics (2023).
[5]. Aslani, S., and J. Jacob. "Utilisation of deep learning for COVID-19 diagnosis." Clinical Radiology 78.2 (2023): 150-157.
[6]. Ahmed, Shams Forruque, et al. "Deep learning modelling techniques: current progress, applications, advantages, and challenges." Artificial Intelligence Review 56.11 (2023): 13521-13617.
[7]. Mungoli, Neelesh. "Adaptive Feature Fusion: Enhancing Generalization in Deep Learning Models." arXiv preprint arXiv:2304.03290 (2023).
[8]. Pfeiffer, Jonas, et al. "Modular deep learning." arXiv preprint arXiv:2302.11529 (2023).
[9]. Mohammad-Rahimi, Hossein, et al. "Deep learning: a primer for dentists and dental researchers." Journal of Dentistry 130 (2023): 104430.
[10]. Iyortsuun, Ngumimi Karen, et al. "A review of machine learning and deep learning approaches on mental health diagnosis." Healthcare. Vol. 11. No. 3. MDPI, 2023.
[11]. Rai, Nitin, et al. "Applications of deep learning in precision weed management: A review." Computers and Electronics in Agriculture 206 (2023): 107698.