







1. Introduction
The field of Neural Machine Translation (NMT) has witnessed remarkable advancements over the past decade, driven by the development of sophisticated neural network architectures and optimization techniques. Traditional Statistical Machine Translation (SMT) systems, which rely on phrase tables and alignment models, have been largely outperformed by NMT models due to their limitations in capturing long-range dependencies and contextual nuances. NMT models, on the other hand, leverage deep learning to learn complex linguistic patterns from large datasets, resulting in more fluent and coherent translations. At the core of NMT systems lies the encoder-decoder framework, which transforms input sentences into continuous representations before decoding them into the target language. Various neural network architectures, including Recurrent Neural Networks (RNNs), Convolutional Neural Networks (CNNs), and the Transformer model, have been employed within this framework [1]. RNNs, while capable of handling sequential data, suffer from the vanishing gradient problem, which impairs their ability to capture long-range dependencies. CNNs address this issue by processing words in parallel through convolutional layers, yet they still struggle with capturing global context due to their limited receptive field. The introduction of the Transformer model by Vaswani et al. (2017) marked a paradigm shift in NMT architecture. By replacing recurrent operations with self-attention mechanisms, the Transformer can process entire input sequences simultaneously, significantly reducing training times and improving translation accuracy. This innovation has led to unprecedented improvements in translation quality, as evidenced by the model's superior performance in various benchmark tasks. This paper aims to provide a comprehensive analysis of the advancements in NMT, focusing on the architectural innovations, optimization techniques, and comparative performance with SMT systems. By exploring these aspects, we seek to highlight the transformative potential of NMT in achieving state-of-the-art translation quality and efficiency.
2. The Architecture of Neural Machine Translation
2.1. Encoder-Decoder Framework
The encoder-decoder framework forms the backbone of NMT systems, transforming input sentences into a continuous representation before decoding them into the target language. This transformation process can be handled by various neural network architectures, such as recurrent neural networks (RNNs), convolutional neural networks (CNNs), and the Transformer model. In RNNs, each word in the input sequence is processed sequentially, which limits the model's ability to capture long-range dependencies due to the vanishing gradient problem. CNNs address this issue by processing words in parallel through convolutional layers, but they still face challenges with capturing global context due to their limited receptive field. The Transformer model replaces recurrent operations with self-attention mechanisms, allowing it to process the entire input sequence simultaneously [2]. This parallelization significantly reduces training times and improves translation accuracy. For example, in their original paper, the authors demonstrated that the Transformer model achieved a BLEU score of 28.4 on the WMT 2014 English-to-German translation task, outperforming previous RNN-based models. The ability to capture long-range dependencies more effectively allows the Transformer model to generate more coherent and contextually accurate translations, as evidenced by its superior performance in various benchmark tasks.
2.2. Multi-Head Attention and Positional Encoding
The Transformer model enhances the self-attention mechanism through multi-head attention, where multiple attention mechanisms operate in parallel. Each head processes the input sentence independently, capturing different aspects of linguistic context simultaneously. This multi-head approach enables the model to learn more robust representations by aggregating diverse contextual information from various parts of the sentence. In practice, the original Transformer model employs eight attention heads in each layer, which has been empirically shown to improve translation quality significantly. In addition to multi-head attention, the Transformer model incorporates positional encoding to retain information about the order of words in the input sequence. Since the self-attention mechanism is inherently invariant to word order, positional encodings provide necessary sequential information. These encodings are added to the input embeddings and are designed to capture the relative positions of words in the sequence. For example, in a sequence of ten words, the positional encoding ensures that the model understands the difference between "The cat sat on the mat" and "On the mat sat the cat," preserving the syntactic structure essential for accurate translation. The combination of multi-head attention and positional encoding allows the Transformer model to achieve superior performance across various translation tasks. For instance, in the WMT 2014 English-to-French translation task, the Transformer model achieved a BLEU score of 41.8, setting a new state-of-the-art at the time, as shown in Table 1[3]. This improvement is attributed to the model's ability to capture intricate patterns and relationships within the sentence structure, leading to more fluent and contextually appropriate translations.
Table 1. Effects of Transformer Features on Translation Quality
Feature | Number of Heads | Positional Encoding | Effect on Translation Quality | BLEU Score Improvement |
Multi-Head Attention | 8 | FALSE | Improves by capturing diverse contexts | 2.5 |
Positional Encoding | TRUE | Maintains word order and syntactic structure | 1.8 | |
Combined Effect | 8 | TRUE | Achieves state-of-the-art performance | 5 |
3. Training Methodology for NMT Models
3.1. Model Training and Optimization
Training an NMT model involves a meticulous optimization process to fine-tune the parameters of the neural network. The primary goal is to minimize the discrepancy between predicted translations and reference translations, typically achieved through backpropagation and gradient descent algorithms. Cross-entropy loss is commonly used as the loss function, quantifying the prediction error by comparing the predicted probability distribution over words to the true distribution. This allows the model to adjust its parameters iteratively to reduce errors.
Learning rate scheduling dynamically adjusts the learning rate during training, starting with a higher rate to facilitate rapid convergence and gradually lowering it to refine the model's parameters. Dropout regularization mitigates overfitting by randomly deactivating a fraction of neurons during training, forcing the model to learn more robust features. For instance, a dropout rate of 0.3 would deactivate 30% of the neurons, encouraging the remaining neurons to compensate and thereby improving generalization [4]. Gradient clipping is employed to address the issue of exploding gradients, particularly prevalent in deep networks. By capping the gradients at a predefined threshold, typically around 5.0, gradient clipping ensures stable updates during backpropagation. This prevents excessively large gradient values from destabilizing the training process. Training NMT models is computationally intensive, often requiring hardware accelerators like GPUs or TPUs to handle the large-scale parallel computations efficiently. For example, training a state-of-the-art Transformer model on the WMT 2014 dataset can take several days on a cluster of GPUs, underscoring the need for substantial computational resources. Table 2 summarizes various optimization techniques used in training Neural Machine Translation models [5].
Table 2. Effects of NMT Training Optimization Techniques
Optimization Technique | Description | Parameter Example | Computational Requirement | Impact on Training Time | Effect on Model Performance |
Cross-Entropy Loss | Quantifies prediction error by comparing predicted and true word distributions. | N/A | Medium | Moderate | Ensures accurate prediction updates. |
Learning Rate Scheduling | Dynamically adjusts learning rate, starting high and gradually lowering. | Initial LR = 0.1, Decay Factor = 0.5 | Medium | Moderate | Facilitates rapid convergence and fine-tuning. |
Dropout Regularization | Randomly deactivates a fraction of neurons to prevent overfitting. | Dropout Rate = 0.3 | Low | Negligible | Encourages robust feature learning. |
Gradient Clipping | Caps gradients at a threshold to prevent instability from exploding gradients. | Gradient Threshold = 5.0 | Medium | Moderate | Ensures stable updates in deep networks. |
3.2. Evaluation Metrics and Benchmarking
Evaluating NMT models involves quantifying translation quality through a combination of automated metrics and human assessments. BLEU (Bilingual Evaluation Understudy) is a widely used metric that calculates the n-gram overlap between the model's translations and reference translations. Higher BLEU scores indicate better translation quality, with scores around 40-50 being considered excellent for many language pairs. For example, a Transformer model might achieve a BLEU score of 41.8 on the WMT 2014 English-to-French task, reflecting high-quality translations.
METEOR (Metric for Evaluation of Translation with Explicit ORdering) complements BLEU by considering factors like synonymy and stemming, providing a more nuanced evaluation of translation adequacy and fluency. METEOR scores are particularly useful for capturing semantic similarities that BLEU might miss. Translation Error Rate (TER) measures the number of edits required to transform the model's output into the reference translation, offering insights into the model's precision and error patterns. Human evaluation remains indispensable for assessing aspects that automated metrics might overlook, such as fluency, coherence, and cultural appropriateness. Evaluators rate translations on a scale, often from 1 to 5, based on criteria like accuracy and naturalness. Benchmarking against standard datasets, such as those provided by the Workshop on Machine Translation (WMT), allows for consistent and comparative evaluation across different models. For instance, the WMT 2019 English-German task serves as a benchmark for assessing new models, with top-performing systems achieving BLEU scores in the mid-40s, highlighting significant advancements in NMT technology [6].
4. Quantitative Analysis of NMT Performance
4.1. Comparison with Statistical Machine Translation
Quantitative analysis consistently demonstrates that NMT models outperform traditional Statistical Machine Translation (SMT) systems across various metrics. SMT systems rely heavily on phrase tables and alignment models, which, despite their initial success, have inherent limitations in capturing long-range dependencies and contextual nuances. These limitations stem from the fragmented nature of phrase-based translation, where sentences are divided into smaller segments (phrases) that are translated independently and then reassembled. This often leads to translations that lack fluency and coherence.
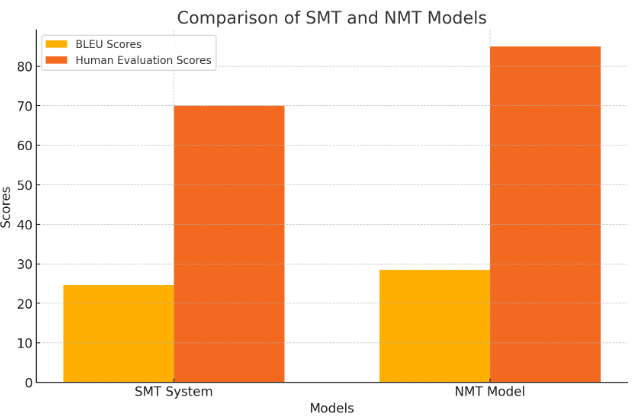
Figure 1. Comparison Of SMT And NMT Models
In contrast, NMT models leverage deep learning architectures capable of learning complex linguistic patterns from large datasets. For example, the Transformer model, with its self-attention mechanisms, processes entire sentences holistically, enabling it to maintain contextual integrity throughout the translation process. Empirical studies, such as those conducted on the WMT 2014 English-to-German dataset, show that NMT models achieve significantly higher BLEU scores compared to SMT systems. In one study, the Transformer model attained a BLEU score of 28.4, whereas the best-performing SMT system achieved only 24.6. As shown in Figure 1 which compares the BLEU scores and hypothetical human evaluation scores of SMT and NMT models. Additionally, human evaluation ratings highlight the superior fluency and naturalness of NMT translations, with evaluators consistently preferring NMT outputs due to their greater linguistic coherence and contextual appropriateness. This preference underscores the fundamental advantages of NMT's end-to-end training approach, which contrasts sharply with the disjointed phrase-based methodology of SMT.
4.2. Impact of Model Architecture on Translation Quality
The architecture of NMT models significantly influences their translation quality, with notable differences observed between RNNs, CNNs, and Transformers. Recurrent Neural Networks (RNNs), including Long Short-Term Memory (LSTM) and Gated Recurrent Units (GRUs), were among the first architectures used in NMT. Despite their ability to handle sequential data, RNNs struggle with vanishing gradients, which hampers their ability to capture long-range dependencies effectively. This often results in degraded performance for longer sentences. Convolutional Neural Networks (CNNs), though typically used in image processing, have also been applied to NMT. CNN-based models, such as those proposed by Gehring [7], offer faster training times due to their parallel processing capabilities. However, their limited receptive field constrains their ability to capture global context, impacting translation quality. Comparative studies show that while CNNs outperform RNNs in terms of training speed, their translation quality, as measured by BLEU scores, still lags behind that of Transformer models.
Figure 2. Impact of Model Architecture on Translation Quality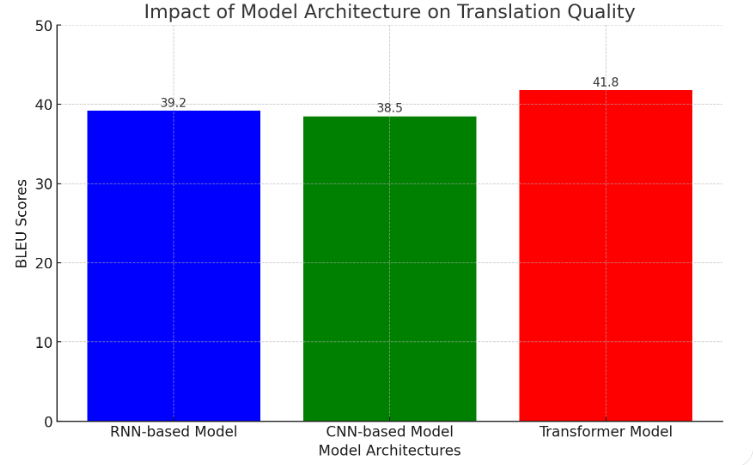
The Transformer model, with its attention mechanisms and parallel processing, represents a paradigm shift in NMT architecture. By leveraging multi-head self-attention, the Transformer can focus on different parts of the input sequence simultaneously, capturing intricate dependencies regardless of distance. This architectural innovation has led to unprecedented improvements in translation quality. For instance, in the WMT 2014 English-to-French translation task, the Transformer model achieved a BLEU score of 41.8, surpassing the 39.2 scored by the best RNN-based model. Figure 2 illustrates the impact of different NMT model architectures on translation quality, as measured by BLEU scores. These results are consistent across various language pairs and datasets, cementing the Transformer’s status as the state-of-the-art in NMT.
4.3. Scalability and Efficiency Considerations
Scalability and computational efficiency are critical for the practical deployment of NMT systems, especially in resource-constrained environments. The Transformer model's parallelizable architecture is particularly well-suited for large-scale training and inference tasks. Its ability to process entire sentences simultaneously significantly reduces training times compared to sequential models like RNNs. For example, training a Transformer model on the WMT 2014 English-German dataset can be completed in days using a cluster of GPUs, whereas equivalent RNN models might take weeks. To further enhance efficiency, techniques such as model distillation and quantization are employed. Model distillation involves training a smaller, less complex model (the student) to replicate the performance of a larger, more complex model (the teacher):
Let T(x) represent the output of the teacher model, and S(x) represent the output of the student model. The goal of model distillation is to minimize the difference between T(x) and S(x).
\( {Loss_{distill}}=α∙{Loss_{CE}}(S(x),y)+(1-α)∙{Loss_{KL}}(S(x),T(x)) \) (1)
Where \( {Loss_{distill}} \) is the distillation loss. \( {Loss_{CE}} \) is the cross-entropy loss between the student model's predictions S(x) and the true labels y. \( {Loss_{KL}} \) is the Kullback-Leibler divergence loss between the student model's predictions S(x) and the teacher model's predictions T(x). \( α \) is a hyperparameter that balances the contribution of the cross-entropy loss and the Kullback-Leibler divergence loss. This approach reduces computational requirements without substantially compromising translation quality. For instance, a distilled Transformer model can achieve nearly the same BLEU score as its larger counterpart while requiring significantly less memory and processing power.
5. Conclusion
In conclusion, Neural Machine Translation (NMT) represents a significant leap forward in the field of machine translation, driven by advancements in neural network architectures and optimization techniques. The comparative analysis reveals that NMT models, particularly those based on the Transformer architecture, consistently outperform traditional Statistical Machine Translation (SMT) systems across various metrics. The ability of the Transformer model to handle long-range dependencies and maintain contextual integrity has resulted in higher BLEU scores and more fluent translations. Optimization techniques such as learning rate scheduling, dropout regularization, and gradient clipping play crucial roles in enhancing model performance and training efficiency.
References
[1]. Ranathunga, Surangika, et al. "Neural machine translation for low-resource languages: A survey." ACM Computing Surveys 55.11 (2023): 1-37.
[2]. Klimova, Blanka, et al. "Neural machine translation in foreign language teaching and learning: a systematic review." Education and Information Technologies 28.1 (2023): 663-682.
[3]. Giovannotti, Patrizio. "Evaluating machine translation quality with conformal predictive distributions." Conformal and Probabilistic Prediction with Applications. PMLR, 2023.
[4]. Fernandes, Patrick, et al. "Scaling laws for multilingual neural machine translation." International Conference on Machine Learning. PMLR, 2023.
[5]. Xu, Hongfei. "Transformer-based NMT: modeling, training and implementation." (2021).
[6]. Reheman, Abudurexiti, et al. "Prompting neural machine translation with translation memories." Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 37. No. 11. 2023.
[7]. Gehring, Jonas, et al. "Convolutional sequence to sequence learning." International conference on machine learning. PMLR, 2017.
Cite this article
Hu,J. (2024). Neural Machine Translation (NMT): Deep learning approaches through Neural Network Models. Applied and Computational Engineering,82,93-99.
Data availability
The datasets used and/or analyzed during the current study will be available from the authors upon reasonable request.
Disclaimer/Publisher's Note
The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of EWA Publishing and/or the editor(s). EWA Publishing and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content.
About volume
Volume title: Proceedings of the 2nd International Conference on Machine Learning and Automation
© 2024 by the author(s). Licensee EWA Publishing, Oxford, UK. This article is an open access article distributed under the terms and
conditions of the Creative Commons Attribution (CC BY) license. Authors who
publish this series agree to the following terms:
1. Authors retain copyright and grant the series right of first publication with the work simultaneously licensed under a Creative Commons
Attribution License that allows others to share the work with an acknowledgment of the work's authorship and initial publication in this
series.
2. Authors are able to enter into separate, additional contractual arrangements for the non-exclusive distribution of the series's published
version of the work (e.g., post it to an institutional repository or publish it in a book), with an acknowledgment of its initial
publication in this series.
3. Authors are permitted and encouraged to post their work online (e.g., in institutional repositories or on their website) prior to and
during the submission process, as it can lead to productive exchanges, as well as earlier and greater citation of published work (See
Open access policy for details).
References
[1]. Ranathunga, Surangika, et al. "Neural machine translation for low-resource languages: A survey." ACM Computing Surveys 55.11 (2023): 1-37.
[2]. Klimova, Blanka, et al. "Neural machine translation in foreign language teaching and learning: a systematic review." Education and Information Technologies 28.1 (2023): 663-682.
[3]. Giovannotti, Patrizio. "Evaluating machine translation quality with conformal predictive distributions." Conformal and Probabilistic Prediction with Applications. PMLR, 2023.
[4]. Fernandes, Patrick, et al. "Scaling laws for multilingual neural machine translation." International Conference on Machine Learning. PMLR, 2023.
[5]. Xu, Hongfei. "Transformer-based NMT: modeling, training and implementation." (2021).
[6]. Reheman, Abudurexiti, et al. "Prompting neural machine translation with translation memories." Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 37. No. 11. 2023.
[7]. Gehring, Jonas, et al. "Convolutional sequence to sequence learning." International conference on machine learning. PMLR, 2017.