







1. Introduction
Currently, the image generation based on deep learning has already been ripe. In 1989, Yann and his team developed the model named LeNet-5[1], which shows that convolutional neural network can be used to extract image features precisely. This research was the basis of the image generation based on deep learning. Since the concept of Generative Adversarial Networks (GAN) [2] was proposed, a large number of image generation methods based on deep learning have been proposed. Through concluding and improving previous achievements, the dataset, such as Microsoft Common Objects in Context (MS COCO) [3] and others, has already contained extensive and precise data, which is suitable for all kinds of image outpainting and super-resolution. Besides, in order to improve the accuracy which system deal with special types of images, researchers developed datasets that focus on a certain type of images, such as Flickr-Faces-HQ (FFHQ) [4]. With the cooperation of a new dataset, improved outpainting network and convolutional neural networks, image outpainting and image super-resolution based on deep learning have already been widely used in the field of face feature outpainting, aerial image super-resolution, image optimization and other specific scenes.
Usually, old image outpainting and resolution are based on huge datasets, their loss functions are designed to focus on overall quality of results. Therefore, there are limitations that cannot be ignored when these mehods are utilized to outpaint areas that contain a lot of details. As time goes, new outpainting methods utilize GAN [2]. Its more complex structure improves its ability to generate new data, which makes it can adapt more complicated iamge generation tasks better. According to GAN, researchers created new Generative Adversarial Network, such as Non-local Dense Skip Residual GAN (NDSRGAN) [5]. Through cooperating with new convolutional neural network, such as U-Net [6] and Super-Resolution Convolutional Neural Network (SRCNN) [7], GAN can reach expected goals better. This essay chooses several representative methods of image outpainting and image super-resolution, being designed in recent years, to analyze. In order to show differences between different image outpainting methods, this essay analyzes new image outpainting methods from 2 aspects.
1) Image outpainting network with different GAN as network architecture are widely used. The image outpainting methods, which are based on GAN and are introduced in this essay, all use various GAN to improve their functions. The image outpainting methods with one kind or various kinds of GAN as main architecture are similar. Therefore, in order to analyze advantages and disadvantages of different methods, this essay anaylzes the methods that use GAN as the main architecture together.
2) Image outpainting network based on multi-resolution mutual network is another effective way. Basically, image outpainting network based on multi-resolution mutual network is composed of encoder, decoder and deep multi-resolution mutual learning. Its principle and datasets of training are different from the image outpainting network with different GAN as network architecture. This essay analyzes the advantages of methods that are not based on GAN, compared with methods that have same principles. Besides, the essay analyzes the advantages and disadvantages of methods based on different principles. The essay can analyze two issues separately. Therefore, classifying and analyzing image outpainting methods with above-mentioned way is reasonable.
In order to analyze applicable fields of different image super-resolution methods, this essay analyzes several representative methods from 2 aspects:
1) Image super-resolution methods that are suitable for all fields is respected in civilian field. In order to ensure that network can deal with all kinds of images, representative super-resolution methods utilize various SR datasets generally to train. Although the 2 representative methods introduced by this essay are based on different principles. they are all trained by various SR datasets. Therefore, analyzing 2 representative ways together can conclude advantages and disadvantages of different methods that are suitable for all fields.
2) Image super-resolution methods that are suitable for special fields have been developed in recent years. When researchers design the image super-resolution methods that are suitable for special fields, they usually train the models with specific datasets. The specific dataset only contains low and high resolution images of one specific field. The advantage is that it cannot only reduce the training time, but can also improve accuracy of results. Analyzing image super-resolution methods that are suitable for all and special fields separately can reduce error. The reason is that the dataset that is suitable for specific fields may cause error when the input image is not proper. Therefore, classifying and analyzing image super-resolution methods with above-mentioned way is reasonable.
According to the above-mentioned review and issues, this essay is divided into 3 parts. The first part makes a brief review of principle and method of image generation based on deep learning. The following 2 parts analyzes the methods of image outpainting and image super-resolution and compare advantages and disadvantages of all methods comprehensively, according to the results.
2. Overview of Image Generation Technology
2.1. Image generation
The image generation based on deep learning is applied in many fields, but there is relevance between them. Since neural network was proposed in 1940s, deep learning has become possible. For the application of deep learning in image generation, artificial data is particularly worthy of attention. In the model of deep learning, recording data source, training program and comparing results are more crucial to be focused on. The reason is that most of deep learning models is commercial, the cost influenced by data source and training program and the commercial value influenced by output results is worthy of attention [8]. In many image generation methods, GAN is the representative model of deep learning, the core of GAN are generator and discriminator. During the process of training, through the confrontation of two parts, it reaches a Nash Equilibrium. In order to explain principle, the explanation method of GAN model can be classified into Supervised Learning, Unsupervised Learning and Embedding-based Learning. In the supervised learning, it checks generator through using labels or classifiers. The representative of supervised learning is GAN Dissection. Due to training classifier requires a large number of images, while an unsupervised model can identify controllable dimensions of generator that do not use labels and classifiers. Therefore, the time of data preparation is shorter. So many models use unsupervised methods to reduce time of preparation. Besides, Embedding-based Learning is most flexible for it allows users to guide image generation with text of any format. Therefore, it is also widely utilized.
2.2. Image outpainting
The image outpainting based deep learning means the technology, which uses deep learning as base to repair missing and vague parts of damaged images. The following article section introduces several representative methods.
2.2.1. The image outpainting network that use different kinds of GAN as main network structure. Through the confrontation of generator and discriminator, GAN can improve the quality of output results constantly. For images that has large areas of missing content, the image outpainting network that use different kinds of GAN as main network structure can deal with them very well.
(1) perceptual image outpainting assisted by low-level feature fusion
Due to most of deep learning model cannot extract valid details of image effectively, Li et al. design a network based on Perceptual Image Outpainting Assisted by Low-Level Feature Fusion [9], and use multi-patch discriminator to improve image texture.
The model designed by Li et al. uses normal GAN. Figure 1 shows the main structure of the network. The generator has two architectures, which are used to reconstruct inpainting image and generate inpainting image respectively. Through fusing texture information of low-level feature map in the decoder, the texture of image is strengthened. In the encoder, where aggregated features reusability is combined with semantic information of deep feature map, is connected with encoder through inference module. Output feature is separated to two different inference modules respectively to sample potential feature.
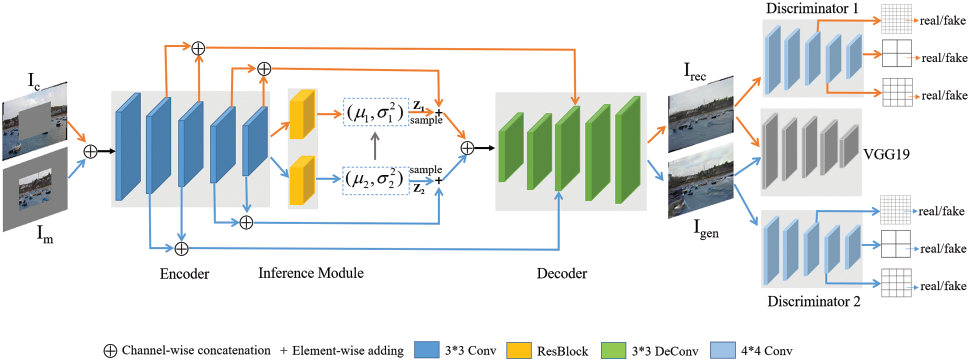
Figure 1. The main structure of the network [9]
The multi-patch discriminator used in this method can discriminate generation image from feature of different levels. In the last 3 layers, it can discriminate whether the generation image is real or fake. When data distribution is got by generator, the generator can improve the visual effect of image. The generation results have better image structure and the texture is enhanced.
(2) image outpainting network composed of two mutual independent GAN
When using old method to repair irregular damage, there is always error on the border. The reason is that most of the relevance between text messages of old methods and the damage area is invalid. In order to solve the problems, Chen et al. designed an image outpainting method composed of two mutual independent GAN [10]. The network can acquire structure that is similar to original image text message through convolutional neural network.
As it is shown in Figure 2, the whole model is composed of a repair network and an optimization network. The two networks use different loss functions.
The module of image outpainting that is based on partial convolutional network focuses on irregular damage area of image. It mainly includes partial convolutional layer, batch normalization layer and RELU layer. The optimization network is based on GAN architecture. It is set to maintain the reasonable part of image. The generator in the network extracts the image feature in two steps. Firstly, the front convolutional layer extracts image features preliminarily. The scale of the core is 9, the number of trajectories is 32, the stride is 1. Secondly, through using 16 convolutioanl residual blocks, it learns multi-scale deep features of image. Through applying more complicated network architecture, the repaired network has better visual effect and is more realistic.
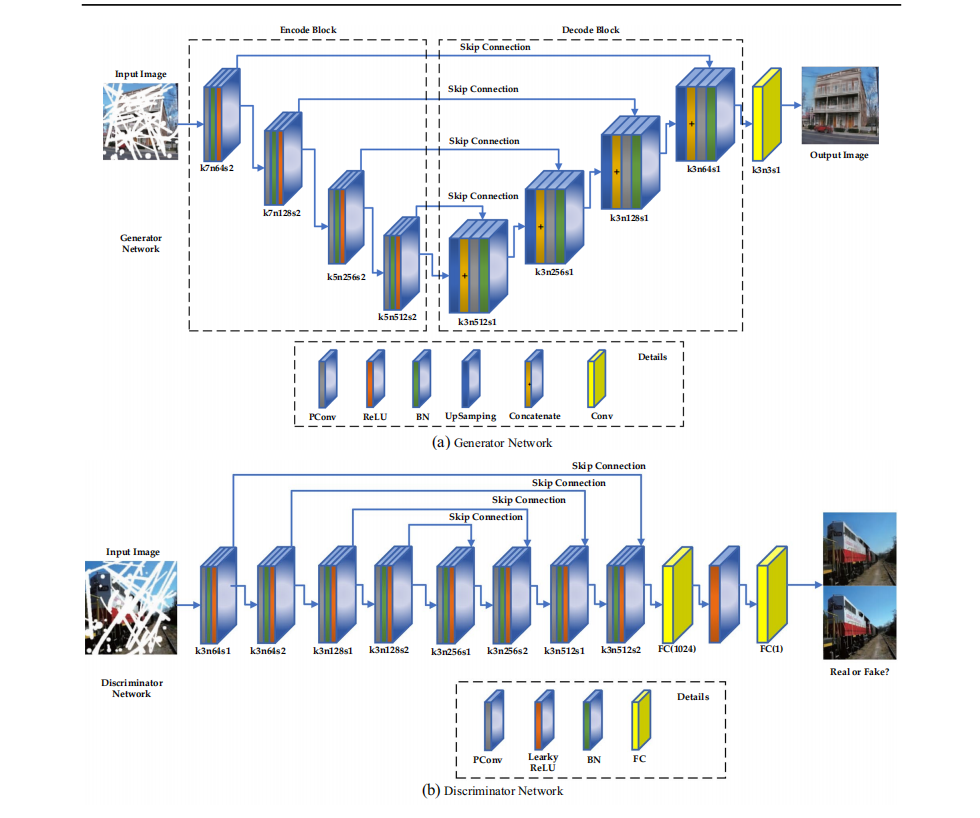
Figure 2. The generator and discriminator network in optimization network [10]
2.2.2. The new image outpainting method based on multi-resolution mutual network. Compared with normal GAN, multi-resolution mutual network is more stable. A lot of new images outpainting models use multi-resolution mutual network to improve stability.
(1) Mutual learning for multi-resolution image
As time goes, a lot of new images outpainting method do not use GAN as main structure. Zheng et al. designed multi-resolution mutual network (MRM-Net) [11]. Figure 3 shows the main architecture of the network. It is composed of parallel encoder, multi-resolution mutual feature learning (MRMFL) and decoder. In order to discover the correlation of multiple resolutions and exchanging information, a multi-resolution information interaction (MRII) is designed in the model. Besides, in order to use interactive features to improve content, an adaptive content enhancement (ACE) is designed in the model. These two parts and memory preservation mechanism (MPM) make up MRMFL. As the area of damage enlarges, the repair performance of old methods is reduced. Compared with old methods, the reduce speed of performance of this new method is slower.
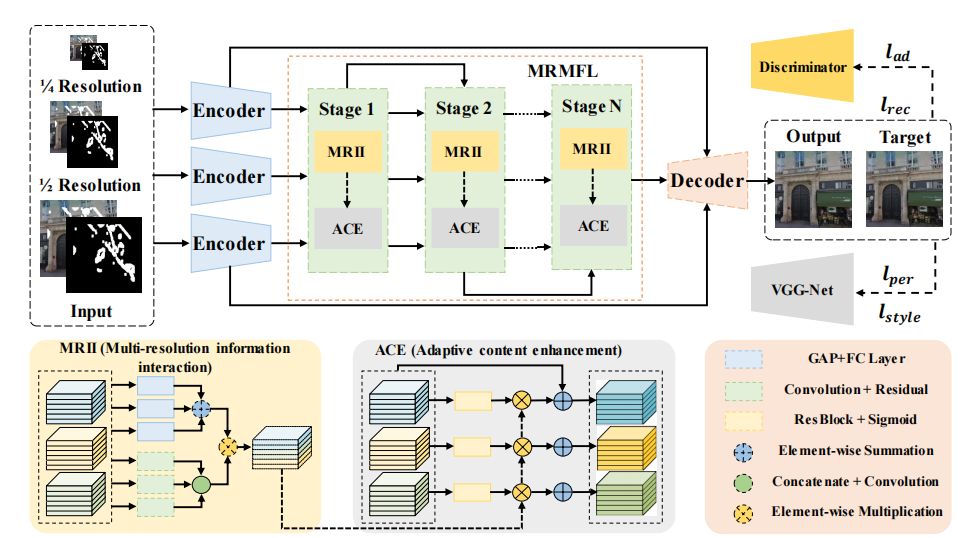
Figure 3. The main architecture of multi-resolution mutual network [11]
2.3. The image super-resolution
The image super-resolution based on deep learning means the technology, which uses deep learning as base to improve resolution of image. The following article section introduces several representative methods.
2.3.1. Image super-resolution methods that are suitable for all fields. Currently, image super-resolution methods that are suitable for all fields is mainly based on GAN or convolutional group. It is widely used in civilian field.
(1) the application of enhanced convolutional group in super-resolution field
In order to improve the performance of super-resolution, most of old super-resolution method use complicated convolutional network architecture. But its cost is too high, and the improvement of effect is not obvious. Therefore, Tian et al. designed an enhanced super-resolution convolutional group [12].
Through fusing deep and wide channel features, the model can extract more exact information from single image super-resolution (SISR). Due to model cannot maintain robustness when it uses single feature fusion, so it uses multilevel feature fusion. The point is that it uses low-resolution image as input directly. The network is composed of 4 parts, the combination of convolutional layer and RELU, GEB, upsampling mechanism and a single convolutional layer. The model chooses public mean squared error (MSE) as the loss function. In SISR, six enhanced convolutional groups are set to improve operational efficiency. The datasets of this model are a lot of known SR datasets. For SISR efficiency and performance, running speed and visual effect, this method is better than old method. But it has to be noted that the complexity of this network is still high. Besides, the model requires a lot of datasets for it to train. Therefore, the cost is still high.
(2) super-resolution algorithm and improved SRGAN network
SRGAN is the super-resolution network that is based on GAN and use perceptual loss as loss function. Even though the output image generated by it has high perceptual quality, but there are some artifacts. Therefore, Liu et al. improve SRGAN [13]. Firstly, they introduce the attention channel mechanism. Secondly, in order to maintain stable, the batch normalization (BN) layer is deleted. Eventually, they replace original loss function with L1 loss function. Compared with original loss function, L1 loss function has less impact on error term for it is simpler. As it is shown in Figure 4, improved SRGAN is still composed of generated network and discriminant network. The attention channel mechanism CA used in this model is based on RCAB and CBAM. It includes two modules. The first one is composed of an average pooling layer, two convolution layers, and an activation function. The second one is composed of a maximum pooling layer, a convolution layer and another convolution layer. The model is same as the model of Tian et al. [12] mentioned above. It uses a lot of known SR datasets to train. This model has the same performance of the origianl SRGAN. Meanwhile, it can reduce artifacts to acceptable degree.
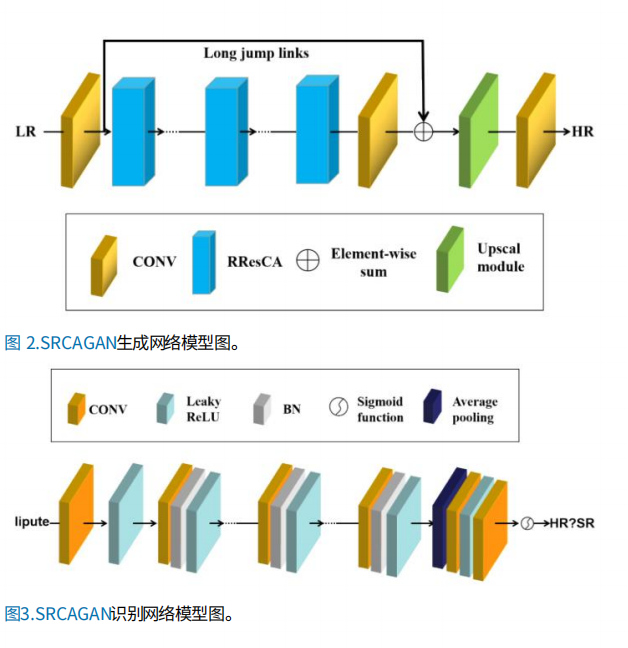
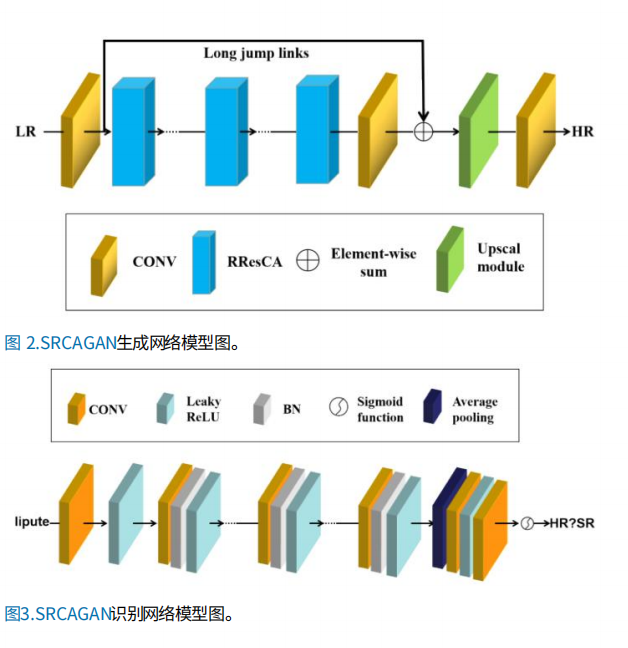
Figure 4. The generated network and discriminant network architecture [13]
2.3.2. Image super-resolution methods that are suitable for special fields. It is hard for old super-resolution method to improve resolution of professional images substantially. Therefore, lots of researchers design image super-resolution methods that are suitable for special fields.
(1) Real Aerial Imagery Super-Resolution Reconstruction
During the flight, most of images shot by camera have low resolution for the camera can be influenced by airflow and other factors easily. In order to solve this problem, Guo et al. designed a super-resolution method which deals with aerial image especially [5]. Figure 5 shows the architecture of generated network and discriminant network. This model uses NDSRGAN, which gas dense connections in residual dense block. Compared with the model based on normal GAN, this is the main difference. Its last layer of discriminator outputs a discriminator matrix. While the last layer of old method is usually full connection. The generative network architecture of this new model is different from old ones. Firstly, using convolutional neural network to extract original features in LR images. Secondly, input original features to dense connection in the residual dense block (DCRDB). DCRDB includes dense block and convolutional layer, using dense network to connect each other. Therefore, it ensures every output feature maps can be reused at multiple levels. The discriminant network has 5 layers in total. The first layer is convolutional layer and LRELU. The second, third and fourth layers are composed of convolutional layer, BN layer and LRELU. The fifth layer is a convolutional layer. The loss function of this model can be used to calculate pixel loss, perceptual loss and adversarial loss respectively.
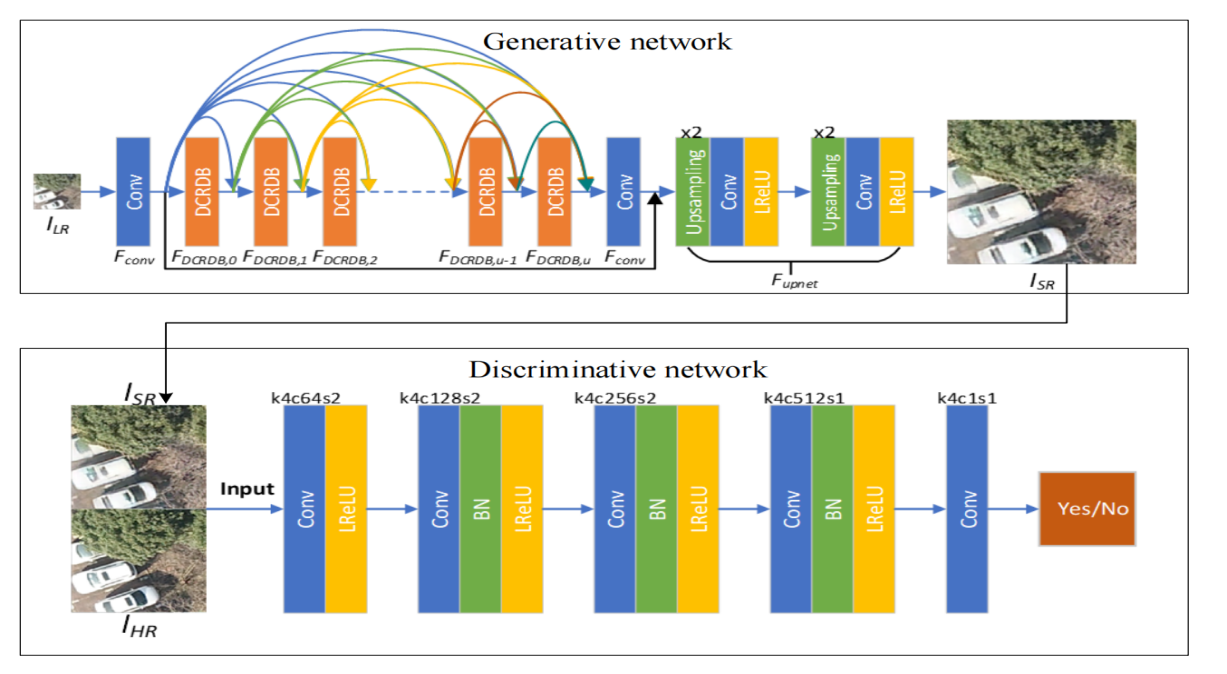
Figure 5. The generated network and discriminant network architecture [13]
Most of old datasets are LR images acquired through bicubic interpolation of HR images. While in order to improve its performance for aerial image, the dataset of this model contains real shot LR images and HR images. After being trained with this specific dataset, the image generated by this model has more abundant texture details and is more similar to real high-resolution image. But on the other hand, due to the limitation of dataset, this model is lack of reconstruction generalization ability when it deals with images shot by various images.
(3) underwater image super-resolution GAN
Most of underwater images shot by underwater cameras have low resolution for the camera can be influenced by water quality and flow rate easily. Therefore, Jiang et al. design a super-resolution method which deals with underwater image specially [14]. This method is based on simultaneous restoration and super-resolution GAN. The process is divided into 2 periods. The first period is restoring, the second period is super-resolution. Compared with old super-resolution method, this method can perform restoration and super-resolution at the same time. The restoration network is composed of encoder and decoder. The two components constitute multi-level degradation restoration generator (MLDRG) to deal with color degradation. In order to improve the ability of color restoration, the restoration network uses channel attention blocks (CAB) to improve attention on shallow feature colors. Before decoder, a self-attention block is set to remove noise. The restoration discriminator includes 4 convolutional blocks. Each one contains 3x3 convolutional layer with stride 1 and 3x3 convolutional layer with stride 2. Each convolutional layer has one SN layer and one leaky RELU function yo make network training more stable.
The super-resolution network architecture is composed of a high frequency learning module (HFLM) and an upsampling module (UM). Through the cooperation of 2 parts, the model can ensure processing efficiency. In the high frequency learning module (HFLM), the network will transport low frequency information to upsampling module (UM) and then learn high frequency information. UM uses a pix-shuffle layer to sample. The super-resolution discriminator is relativistic discriminator that is similar to the one in last period.
The dataset for training contains specific underwater images that are shot by specific camera. They researchers use a two-stage training strategy. Firstly, they use restoration discriminator to supervise the training of generator. This step is the pre-training of GAN in restoration stage. Secondly, using super-resolution discriminator to supervise the training results of whole SRSRGAN model, training SRSRGAN to end-to-end GAN-based model. Compared with old model, this new model can generate more texture details to prevent artifacts. Besides, the overall performance of this new model is better for it can benefit from two stages.
3. Analysis of experimental results
In order to show the advantages of new image generation method, this eaasy cites sime representative data. According to data, this essay analyzes the performance of old and new methods using PSNR and SSIM as an indicator. Besides, this essay shows the excellent performance through the figure.
The image outpainting model designed by Li et al. is noted as PICnet-SP-LM. Table 1 shows the results obtained from initial training on Places 2 dataset of PICnet-SP-LM.
Table 1. Quantitative results of different methods with 128 × 64 valid pixels’ input on the Places2 dataset [9]
Method | IS | FID | PSNR | SSIM | RMSE |
PICnet | 4.05 | 13.94 | 16.38 | 0.6407 | 57.71 |
PICnet-S | 4.11 | 12.78 | 16.38 | 0.6442 | 57.89 |
PICnet-SP | 4.09 | 11.78 | 16.42 | 0.6438 | 57.49 |
PICnet-SP-LM | 4.13 | 9.99 | 16.78 | 0.6452 | 55.13 |
According to the analysis, the Inception Score (IS) of results generated by PICnet-SP-LM is highest. Therefore, the authenticity of its results is highest. Besides, the results generated by PICnet-SP-LM has the lowest Fréchet Inception Distance (FID) and lowest Peak Signal-to-Noise Ratio (PSNR). It proves that PICnet-SP-LM can make results be highly similar to original image and maintain high visual quality of results.
Table 2. PSNR results of different methods on Paris Street View dataset[11]
Datasets | Paris Street View | ||||||
Metric | Mask | PIC | PC | FE | RN | GCM | MRM |
PSNR | 0-10% | 30.46 | 35.62 | 33.95 | 35.11 | 36.12 | 36.55 |
10-20% | 25.72 | 29.99 | 28.82 | 30.63 | 31.02 | 31.38 | |
20-30% | 22.90 | 26.79 | 25.79 | 27.98 | 28.26 | 28.49 | |
30-40% | 21.02 | 24.72 | 23.59 | 25.90 | 26.39 | 26.42 | |
40-50% | 19.66 | 22.78 | 21.60 | 24.00 | 24.60 | 24.72 | |
50-60% | 18.71 | 20.43 | 18.90 | 21.25 | 22.34 | 22.16 | |
Table 3. SSIM results of different methods on Paris Street View dataset[11]
Datasets | Paris Street View | ||||||
Metric | Mask | PIC | PC | FE | RN | GCM | MRM |
SSIM | 0-10% | 0.961 | 0.955 | 0.970 | 0.969 | 0.975 | 0.977 |
10-20% | 0.906 | 0.886 | 0.922 | 0.928 | 0.934 | 0.938 | |
20-30% | 0.836 | 0.802 | 0.858 | 0.881 | 0.888 | 0.893 | |
30-40% | 0.768 | 0.718 | 0.789 | 0.824 | 0.834 | 0.840 | |
40-50% | 0.677 | 0.621 | 0.708 | 0.755 | 0.771 | 0.777 | |
50-60% | 0.551 | 0.510 | 0.589 | 0.648 | 0.684 | 0.686 | |
The image oupainting method designed by Zheng et al. is noted as MRM. According to Table 2 and Table 3, on Paris Street View dataset, the Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index (SSIM) of result generated by MRM are higher than others. It proves that result generated by MRM is most similar to original image. Besides, as the damage area increases, the reduce speed of performance of MRM is slower than any old methods.
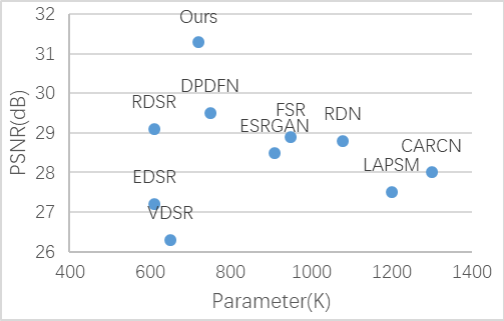
Figure 6. Comparison of parameters of different methods [13]
Figure 6 shows the comparison of parameters of super-resolution model designed by Liu et al. and other models. The model designed by Liu et al. is noted as Ours. On set 5 dataset, the high-resolution image generated by Ours has the highest Peak Signal-to-Noise Ratio (PSNR). Compared with model has second highest PSNR, the parameter of Ours is lower, which means the complexity of Ours is lower. It proves that Ours model has the highest performance, which means its operation speed is fastest, and its requirement of hardware is lower.

Figure 7. Visual effects of reconstructed images by different methods and their corresponding
LPIPS values [5]
Figure 7 shows visual effects of images generated by different super-resolution methods. The model designed by Jiang et al. is noted as Ours. From the perspective of visual effect, the texture of images generated by Ours is more clear and contains more details. For example, the parking lines of images of last line are more clear and more real than others. From the perspective of LPIPS, LPIPS of Ours is lower. It proves that the low-resolution image processed by Ours is more similar to original high-resolution image.
4. Discussion
Although the representative models mentioned in this essay is more advanced, compared with origianl methods, there are still some unresolved problems. From the perspective of image outpainting method, the cost of two kinds of methods mentioned in this essay is high. On the other hand, the dataset for training is too complex. Besides, it takes too long time to construct network. The performances of two image outpainting methods which have different focus are all poor when the damage area of input image is too large. From the perspective of image super-resolution, the image super-resolution methods that are comprehensively suitable for all fields has higher precision. Therefore, it can deal with most of kinds of images, but its results cannot reach the degree that is extremely similar to original high-resoution image. From the perspective of the image super-resolution methods that are suitable for special fields, its performance is poor when it deals with images that are not in its intended field. According to the previous descriptions and analysis, it can be concluded that image outpainting method based on GAN may train on more dataset and its basic structure may be reset. The image outpainting method based on other theory may be combined with GAN to improve performance. The image super-resolution methods that are suitable for all fields can train on more datasets to improve precision continuously. According to the analysis, most of researchers tend to choose most accurate datasets to reduce cost. The image super-resolution methods that are suitable for special fields will continue to develop. There are supposed to be more image super-resolution methods that are suitable for special fields in the future. In order to reduce cost, the image super-resolution methods that are suitable for all fields can only train on dataset which mainly contains images about daily life. The reason is that most of researchers choose the image super-resolution methods that are suitable for special fields when they perform image of specific scientific field super-resolution. Although this essay performs systematic analysis, it still has limitations. This essay only analyzes the advantages and disadvantages of some representative models and do not do a review on other models. Besides, these representative models also have limitations.
5. Conclusion
Through discussing representative methods and finding out resources, this essay compares these methods with old methods. According to the analysis of results, the essay evaluates the advantages of image outpainting methods based on different theories from different aspects, such as image texture, visual effect and PSNR. From the perspective of image super-resolution, the essay evaluates the images processed by image super-resolution methods that are suitable for all fields. The focuses of two representative methods are analyzed. From the perspective of the image super-resolution methods that are suitable for special fields, this essay analyzes 2 methods respectively and introduce datasets. The essay evaluates the performance of new methods through comparing the results with original high-resolution image. Eventually, according to the information obtained and the pros and cons obtained through analyzing, the essay makes comprehensive analysis on development trend and application prospects of two image generation fields. Due to the growing maturity of basic theory and large market demand, it is expected that the image outpainting and image super-resolution based on deep learning will develop rapidly in the following 10 years.
References
[1]. Yann, L., Léon, B., Yoshua, B., and Patrick, H. (1998). Gradient-based learning applied to document recognition. Proc. IEEE 86, 11, 2278-2324.
[2]. Ian, G., Jean, P.-A., Mehdi, M., Bing, X., David, W.-F., Sherjil, O., Aaron, C., and Yoshua, B. (2020). Generative adversarial networks. Commun. ACM 63, 11, 139–144.
[3]. Tsung-Yi, L., Michael, M., Serge, B., James, H., Pietro, P., Deva, R., Piotr, D. (2014). Microsoft COCO: Common Objects in Context. In Proceedings of the 13th European Conference on Computer Vision (ECCV), 740-755.
[4]. Tero, K., Samuli, L., and Timo, A. (2019). A Style-Based Generator Architecture for Generative Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 4401-4410.
[5]. Guo, M., Zhang, Z., Liu, H., and Huang, Y. (2022). NDSRGAN: A Novel Dense Generative Adversarial Network for Real Aerial Imagery Super-Resolution Reconstruction. Remote Sensing, 14, 7, 1574.
[6]. Ronneberger, O., Fischer, P., and Brox, T. (2015). U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI), 234–241.
[7]. Dong, C., Loy, C. C., He, K., and Tang, X. (2016). Image Super-Resolution Using Deep Convolutional Networks. IEEE Transactions on Pattern Analysis and Machine Intelligence 38, 2, 295–307.
[8]. Holzinger, A., Goebel, R., Fong, R., Moon, T., Müller, K.-R., and Samek, W. (2022). xxAI - Beyond Explainable Artificial Intelligence. In xxAI - Beyond Explainable AI: International Workshop, Held in Conjunction with ICML 2020, July 18, 2020, Vienna, Austria, Revised and Extended Papers, A. Holzinger, R. Goebel, R. Fong, T. Moon, K.-R. Müller, and W. Samek (Eds.). Springer International Publishing, Cham, 3–10.
[9]. Li, X., Ren, Y., Ren, H., Shi, C., Zhang, X., Wang, L., Mumtaz, I., and Wu, X. (2022). Perceptual Image Outpainting Assisted by Low-Level Feature Fusion and Multi-Patch Discriminator. CMC-Computers, Materials & Continua 71, 3, 5021–5037.
[10]. Chen, Y., Xia, R., Zou, K., and Yang, K. (2023). RNON: Image Inpainting via Repair Network and Optimization Network. International Journal of Machine Learning and Cybernetics 14, 9, 2945–2961.
[11]. Zheng, H., Zhang, Z., Zhang, H. J. (2022). Deep Multi-Resolution Mutual Learning for Image Inpainting. In Proceedings of the 30th ACM International Conference on Multimedia (MM '22). Association for Computing Machinery, New York, NY, USA, 6359–6367.
[12]. Tian, C., Yuan, Y., Zhang, S., Lin, C.-W., Zuo, W., and Zhang, D. (2022). Image super-resolution with an enhanced group convolutional neural network. Neural Networks 153, 373–385.
[13]. Liu, B. and Chen, J. (2021). A Super Resolution Algorithm Based on Attention Mechanism and SRGAN Network. IEEE Access 9, 139138–139145.
[14]. Wang, H., Zhong, G., Sun, J., Chen, Y., Zhao, Y., Li, S., and Wang, D. (2023). Simultaneous restoration and super-resolution GAN for underwater image enhancement. Frontiers in Marine Science 10, Article 1162295.
Cite this article
Li,J. (2024). Representative Image Outpainting and Image Super-Resolution Methods Based on Deep Learning. Applied and Computational Engineering,80,18-28.
Data availability
The datasets used and/or analyzed during the current study will be available from the authors upon reasonable request.
Disclaimer/Publisher's Note
The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of EWA Publishing and/or the editor(s). EWA Publishing and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content.
About volume
Volume title: Proceedings of CONF-MLA Workshop: Mastering the Art of GANs: Unleashing Creativity with Generative Adversarial Networks
© 2024 by the author(s). Licensee EWA Publishing, Oxford, UK. This article is an open access article distributed under the terms and
conditions of the Creative Commons Attribution (CC BY) license. Authors who
publish this series agree to the following terms:
1. Authors retain copyright and grant the series right of first publication with the work simultaneously licensed under a Creative Commons
Attribution License that allows others to share the work with an acknowledgment of the work's authorship and initial publication in this
series.
2. Authors are able to enter into separate, additional contractual arrangements for the non-exclusive distribution of the series's published
version of the work (e.g., post it to an institutional repository or publish it in a book), with an acknowledgment of its initial
publication in this series.
3. Authors are permitted and encouraged to post their work online (e.g., in institutional repositories or on their website) prior to and
during the submission process, as it can lead to productive exchanges, as well as earlier and greater citation of published work (See
Open access policy for details).
References
[1]. Yann, L., Léon, B., Yoshua, B., and Patrick, H. (1998). Gradient-based learning applied to document recognition. Proc. IEEE 86, 11, 2278-2324.
[2]. Ian, G., Jean, P.-A., Mehdi, M., Bing, X., David, W.-F., Sherjil, O., Aaron, C., and Yoshua, B. (2020). Generative adversarial networks. Commun. ACM 63, 11, 139–144.
[3]. Tsung-Yi, L., Michael, M., Serge, B., James, H., Pietro, P., Deva, R., Piotr, D. (2014). Microsoft COCO: Common Objects in Context. In Proceedings of the 13th European Conference on Computer Vision (ECCV), 740-755.
[4]. Tero, K., Samuli, L., and Timo, A. (2019). A Style-Based Generator Architecture for Generative Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 4401-4410.
[5]. Guo, M., Zhang, Z., Liu, H., and Huang, Y. (2022). NDSRGAN: A Novel Dense Generative Adversarial Network for Real Aerial Imagery Super-Resolution Reconstruction. Remote Sensing, 14, 7, 1574.
[6]. Ronneberger, O., Fischer, P., and Brox, T. (2015). U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI), 234–241.
[7]. Dong, C., Loy, C. C., He, K., and Tang, X. (2016). Image Super-Resolution Using Deep Convolutional Networks. IEEE Transactions on Pattern Analysis and Machine Intelligence 38, 2, 295–307.
[8]. Holzinger, A., Goebel, R., Fong, R., Moon, T., Müller, K.-R., and Samek, W. (2022). xxAI - Beyond Explainable Artificial Intelligence. In xxAI - Beyond Explainable AI: International Workshop, Held in Conjunction with ICML 2020, July 18, 2020, Vienna, Austria, Revised and Extended Papers, A. Holzinger, R. Goebel, R. Fong, T. Moon, K.-R. Müller, and W. Samek (Eds.). Springer International Publishing, Cham, 3–10.
[9]. Li, X., Ren, Y., Ren, H., Shi, C., Zhang, X., Wang, L., Mumtaz, I., and Wu, X. (2022). Perceptual Image Outpainting Assisted by Low-Level Feature Fusion and Multi-Patch Discriminator. CMC-Computers, Materials & Continua 71, 3, 5021–5037.
[10]. Chen, Y., Xia, R., Zou, K., and Yang, K. (2023). RNON: Image Inpainting via Repair Network and Optimization Network. International Journal of Machine Learning and Cybernetics 14, 9, 2945–2961.
[11]. Zheng, H., Zhang, Z., Zhang, H. J. (2022). Deep Multi-Resolution Mutual Learning for Image Inpainting. In Proceedings of the 30th ACM International Conference on Multimedia (MM '22). Association for Computing Machinery, New York, NY, USA, 6359–6367.
[12]. Tian, C., Yuan, Y., Zhang, S., Lin, C.-W., Zuo, W., and Zhang, D. (2022). Image super-resolution with an enhanced group convolutional neural network. Neural Networks 153, 373–385.
[13]. Liu, B. and Chen, J. (2021). A Super Resolution Algorithm Based on Attention Mechanism and SRGAN Network. IEEE Access 9, 139138–139145.
[14]. Wang, H., Zhong, G., Sun, J., Chen, Y., Zhao, Y., Li, S., and Wang, D. (2023). Simultaneous restoration and super-resolution GAN for underwater image enhancement. Frontiers in Marine Science 10, Article 1162295.