


Volume 202
Published on October 2025Volume title: Proceedings of CONF-MLA 2025 Symposium: Intelligent Systems and Automation: AI Models, IoT, and Robotic Algorithms
Deep learning has advanced image recognition, achieving strong results in medical imaging, autonomous driving, and security. Yet significant bottlenecks still limit deployment. This paper reviews three main challenges: weak robustness, high computational demands, and reliance on large labeled datasets. Recent studies identify the causes of these issues, including growing model complexity, distribution shifts between training and real data, and lack of security-aware design. To address these problems, various strategies have been developed in the past five years. For robustness, adversarial training, data augmentation, and domain adaptation have been widely applied. To enhance the efficiency of deep learning models, techniques including network pruning, parameter quantization, and lightweight architectures (e.g., MobileNet and EfficientNet) are widely adopted—often augmented by knowledge distillation and hardware-aware neural architecture search (NAS). To mitigate reliance on large-scale labeled datasets, approaches such as transfer learning, self-supervised learning frameworks (e.g., SimCLR and BYOL), and multimodal models (e.g., CLIP) have demonstrated promising performance. While progress is evident, trade-offs remain. Future work should focus on combining these strategies to achieve models that are simultaneously accurate, efficient, and robust for real-world applications.



World Models, such as Dreamer, rely on latent representations to learn environment dynamics and facilitate planning. However, standard VAE-based encoders often capture redundant background features, resulting in inefficient training and slower convergence. In particular, reconstructions from vanilla VAEs tend to overlook dynamic elements---such as the player and ghosts in game scenes---prioritizing overall pixel fidelity over task-critical components. We introduce a Dynamic Saliency-Guided Encoder that incorporates a learnable attention mask to prioritize task-relevant regions in visual inputs. This encoder integrates seamlessly into a Dreamer-style architecture with a Recurrent State-Space Model (RSSM) and is optimized end-to-end with actor-critic updates. Experiments on the Atari MsPacman environment demonstrate that our method yields clearer reconstructions of salient elements, including maze walls, pellets, and the player character. Quantitative results show a 28% improvement in PSNR for task-critical entities and a 15% increase in average episodic rewards compared to the baseline Dreamer-V3 [1], indicating enhanced latent representation efficiency and sample efficiency in model-based reinforcement learning (MBRL). This work highlights the value of attention-enhanced encoders for scalable and semantically focused representation learning in MBRL.
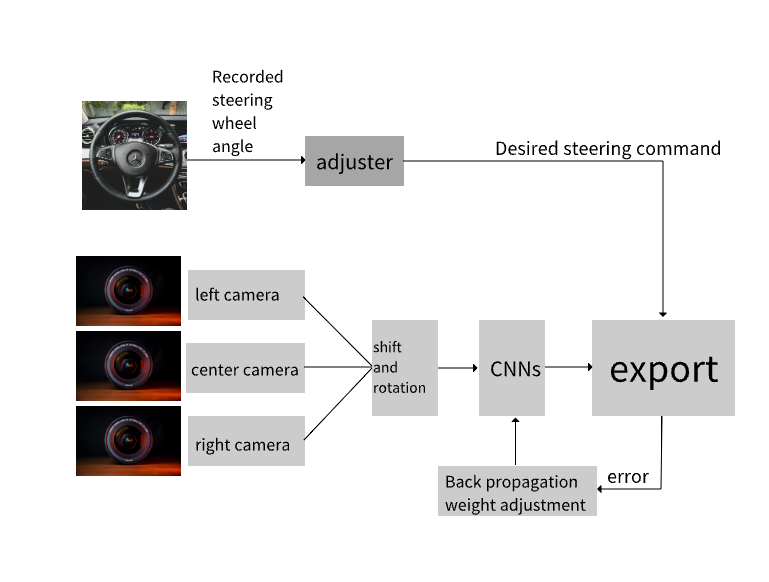
Many challenges such as environmental complexity, decision-making security, and algorithm generalization ability remain as the main problems faced by autonomous driving technology. Current research focuses on multimodal perception, end-to-end control systems, and reinforcement learning frameworks, but still has problems such as insufficient handling of long-tail scenarios, weak interpretability of black-box decisions, and high training costs. This paper's research can be deepened in three directions: integrating large language models (LLMs) with visual foundation models (VLMs) to enhance the scene understanding and few-shot generalization ability of end-to-end systems through semantic reasoning; developing hybrid learning frameworks that combine imitation learning and model-based reinforcement learning (such as the DIRL method) to reduce the demand for high-risk interactions; and building high-fidelity simulation environments to generate dynamic scenes using multimodal trajectory prompts and optimize the robustness of algorithms in extreme conditions. This paper can solve the black-box problem of autonomous driving through decision transparency enhanced by LLMs; lightweight models and hybrid training strategies can significantly reduce computational costs; the simulation supplementation of long-tail scenarios by world models will promote the implementation of safety standards and provide technical support for the commercialization of fully autonomous driving.
With the rapid development of the automotive industry and the growing influence of social media, public opinion on automotive safety tests has become a key factor affecting consumer trust and the reputation of corporations. In 2025, the collision experiment between Li Auto i8 and CHENGLONG truck caused controversy on Weibo, which authenticity of the test results and the safety performance of the vehicles were questioned by public. However, traditional public opinion analysis methods struggle to accurately capture both thematic focuses and emotional tendencies in large-scale unstructured comment data. Against this backdrop, this study focused on analyzing public opinion regarding the controversial collision experiment between Li Auto i8 and CHENGLONG truck, which happened in 2025. This research used a fusion method of LDA, BERT and data augmentation. It explored public opinion themes and the effectiveness of the model in automotive public opinion text analysis, which provided insights for car companies' responses. Data was selected from 599 Weibo comments, after cleaning, tokenizing, stopword filtering and augmenting, data reached 2803 samples. The LDA-BERT (Latent Dirichlet's Assignment - Bidirectional Encoder Representation) fusion model extracted four core topics, which achieved 98.93% sentiment classification accuracy. Findings showed the model effectively managed automotive public opinion. It helped car companies find the direction of public questioning. Limitations included insufficient negative emotion extraction in LDA and errors in recognizing niche slang. In the future, more research can be done on optimizing the subject title filtering logic. Although the research had limitations, it can still contribute methodologically and practically to automotive public opinion analysis.
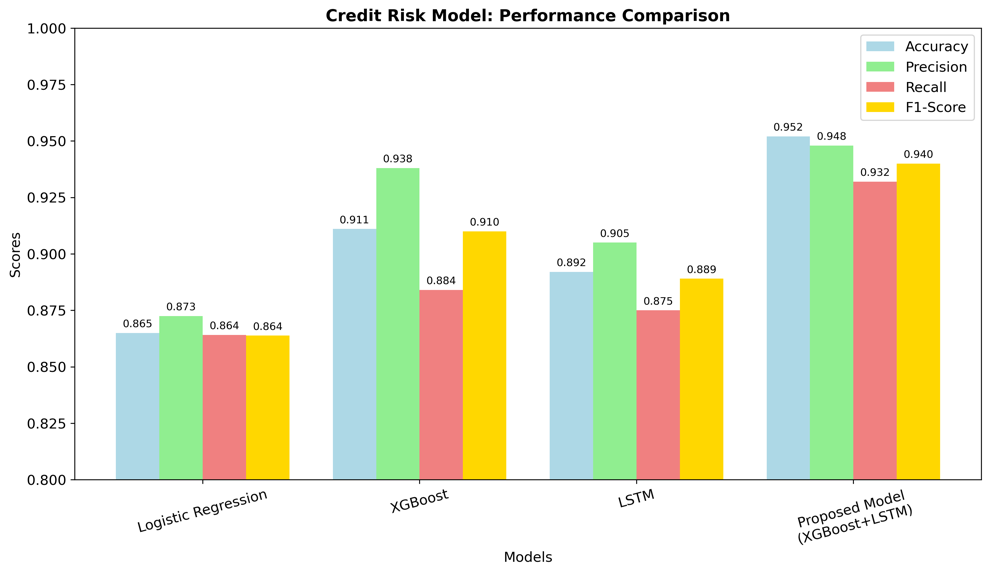
Effective financial risk management is critically important in the financial field, as it safeguards institutional stability and ensures sustainable economic growth. However, traditional methods, such as the linear regression model, have some limitations when addressing complex and modern risk prediction, which is challenging to apply in the big data age. With a focus on credit risk and operational risk, this study aims to address problems by applying machine learning techniques. For credit risk management, a precise model will be proposed, which integrates Extreme Gradient Boosting (XGBoost) for basic judgment and Long Short-Term Memory (LSTM) for analyzing suspected behavioral data. For operational risk, a two-layer detection model is introduced, employing Isolation Forest for rapid filtering and Prophet time series model for in-depth analysis. Final results indicate that proposed approaches have better performance than previous models in terms of accuracy and efficiency. This research presents a scalable and interpretable solution for risk management, although it also has some potential drawbacks, such as missing data.
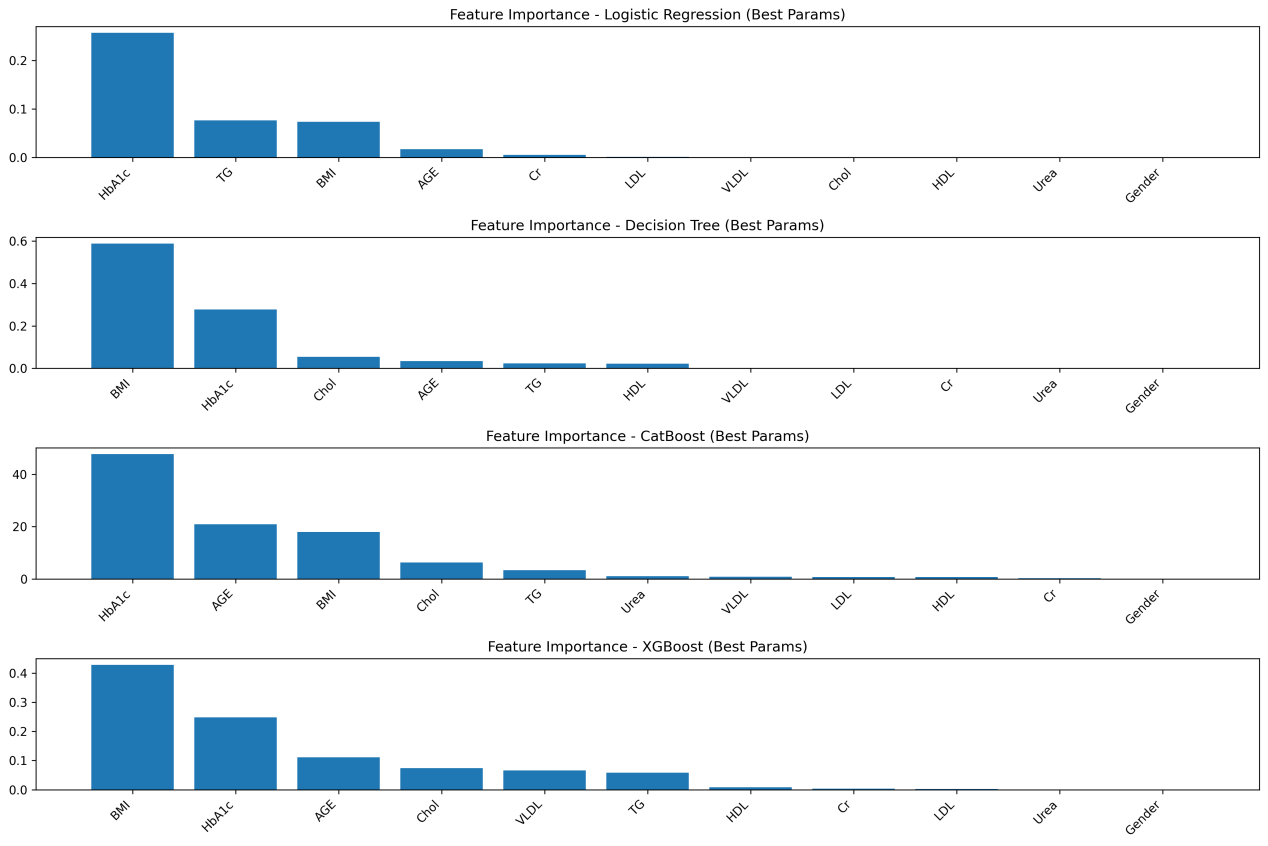
This study investigates key predictors of diabetes risk across non-diabetes, prediabetes, and diabetes categories, while developing an optimal prediction model using multiple machine learning algorithms. Biomedical indicators such as HbA1c, urea, and creatinine, along with demographic factors like age and gender, were analyzed to evaluate their predictive value. Among the five algorithms tested, ensemble learning methods (CatBoost and XGBoost) outperformed traditional models, with CatBoost achieving the highest accuracy and demonstrating superior robustness. Feature importance analysis identified HbA1c as the most influential predictor, followed by age and BMI, aligning with established medical knowledge, whereas gender contributed minimally. The findings highlight the potential of advanced machine learning models, particularly CatBoost, in delivering highly accurate and stable diabetes risk prediction. This research provides strong technical support for early screening, targeted intervention, and practical risk assessment in diabetes management.
In the contemporary field of diagnostic and clinical medical practice, the reliance on big data is steadily deepening. However, it is confronted with challenges such as the exponential growth of data volume and the diversification of data types, which impose new requirements for the efficiency of data processing. Against this backdrop, decision trees play an indispensable and pivotal role in precision medicine and disease diagnosis. Therefore, this study aims to systematically sort out the core application directions and underlying principles of decision trees in the medical field through literature review and case analysis methods, while identifying their existing limitations and future development trends. The research findings indicate that decision trees have been widely applied in fields such as stomatology, cardiovascular diseases, and chronic diseases, achieving remarkably positive outcomes. Their value extends beyond disease diagnosis; they also exert a beneficial and positive impact on optimizing treatment regimens and rationalizing the structure of medical treatment costs. The study further highlights the current problems and future development directions.
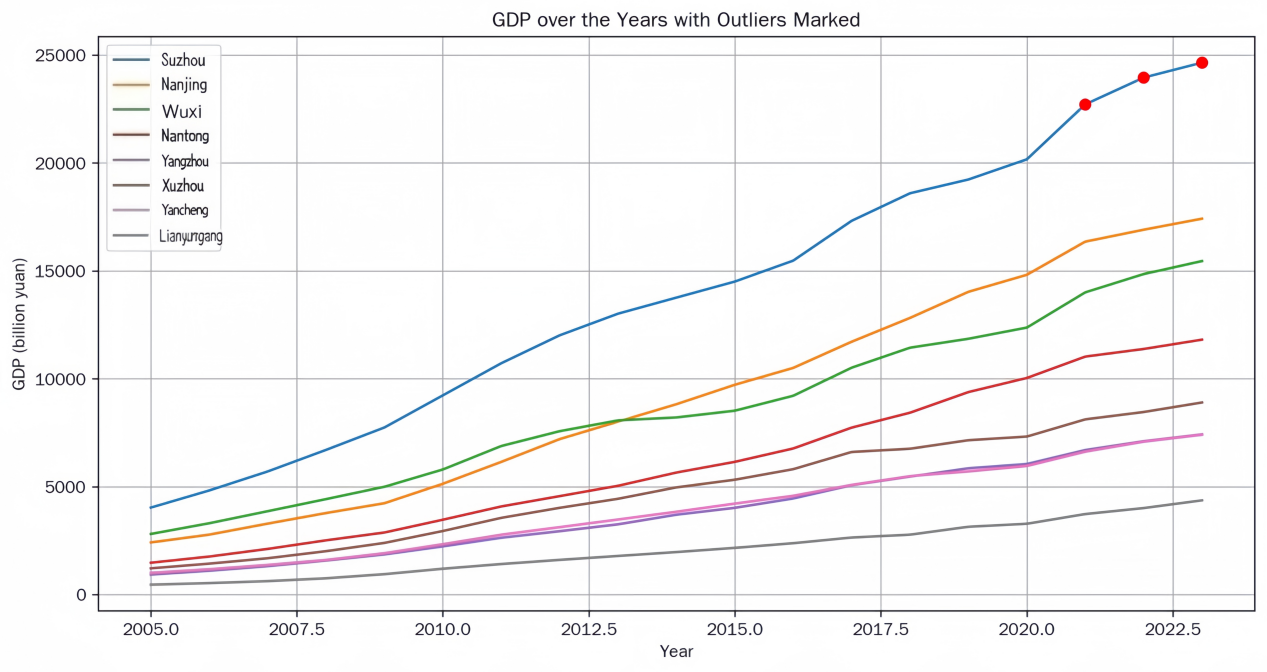
Gross domestic product (GDP) is the sum of the market value of final goods and services produced by all permanent units in a country over a specific period. It is a core indicator for measuring economic scale. Regional GDP forecasting is also an important and indispensable task. Jiangsu Province is one of the major economic powerhouse in China, accurate regional GDP forecasting is crucial for guiding government policy-making, optimizing resource allocation, and addressing inter-city economic disparities. This study focuses on 8 representative prefecture-level cities in Jiangsu (covering Southern, Central, and Northern Jiangsu) and utilizes panel data from 2005 to 2023, including municipal GDP figures and 16 key economic indicators (e.g., fixed asset investment, local fiscal revenue, and total patent applications). Two models—multiple linear regression (MLR) and random forest (RF)—are constructed to forecast GDP. The essay finds that the multivariate linear regression model outperforms the random forest model in predicting GDP, achieving a closer approximation to the true value, provides data support for the government.