







1. Introduction
Financial risk management plays an important role in the financial industry. It’s essential for ensuring stability and profitability [1]. Financial risk refers to uncertainties in financial decisions, which is a core concept that impacts both individuals and institutions [2,3]. In the modern era, big data poses significant challenges to the entire financial field, highlighting the limitations of traditional risk management methods.
Traditional approaches, which often rely on statistical techniques like linear regression, are hard to identify nonlinear relationships and deal with complex patterns [4]. Moreover, they are too traditional to address new challenges, such as emerging fraud patterns in operational risk [5]. This gap between traditional capabilities and modern demands seeks newer solutions.
Machine learning (ML) is a product of the digital age, including a lot of effective and accurate predictive models and algorithms. Techniques such as logistic regression for credit scoring and random forests for fraud detection have demonstrated significant improvements over traditional models. However, those models remain at a simple stage because only one algorithm is used in each model. Those simple models often face challenges, from overfitting to difficulties in handling imbalanced data.
To address these issues, this study proposes a machine learning framework. This paper will focus on credit risk and operational risk. First, for credit risk, an integrated model combining XGBoost and LSTM networks will be developed to more accurately predict customers’ credit risk. Second, for operational risk, a two-layer detection system that employs Isolation Forest for rapid filtering and the Prophet model for in-depth analysis will be introduced to achieve effective fraud detection.
This study is essential for two main reasons. First, it introduces new ideas to the field by testing a mixed-method approach, which addresses the limitations of using only one algorithm, offering a helpful way to combine different machine learning strengths. Second, it provides banks and companies with practical tools that are easy to use. These tools enhance the accuracy of risk prediction and can offer more effective risk management solutions. The following parts of the paper will explain earlier research, the methods used, test results, and what the findings mean.
2. Literature review
There are many types of financial risks. The most common are credit risk and operational risk. This study will focus on the management of credit risk and market risk. Credit risk refers to the risk that a client will not be able to perform the agreed business on the agreed date [6]. When an institution signs a project with a client, the assessment of this risk will become an important reference. Operational risk refers to the risk of losses due to various reasons in the company's operations, common reasons include fraud [6]. This risk reflects the stability of each company and is a significant indicator. Traditional financial risk management relies heavily on statistical techniques and expert opinions. For credit risk management, people often used credit scoring in the past. Common techniques include logistic regression model and discriminant analysis [4]. While these traditional methods laid the groundwork for risk management, their reliance on linear assumptions and static historical data makes them inadequate in today's dynamic financial environment [7]. For instance, logistic regression models, despite their interpretability, often fail to capture complex non-linear relationships between risk factors. Operational risk is often difficult to predict because it has many uncertain factors, such as natural disasters. In the past, the prediction of operational risk was based on expert experience or existing rules [5]. This method relies too much on expert experience. These approaches were adopted because they were interpretable, mathematically straightforward, and aligned with the available computational resources of their time. For credit assessment, techniques like logistic regression provided clear coefficient estimates that indicated how each factor affected risk, while discriminant analysis offered a statistical framework for classifying customers into risk categories. Similarly, operational risk management relied on expert judgment. However, both of these previous risk management methods have limitations. First, simple statistical techniques and weak expert opinions cannot deal with complex data. In the modern era, the categories and total number of data are increasing, and single statistics and expert opinions cannot fully analyze these new data [8]. Second, these methods only focus on static data, such as numbers and existing rules, but ignore dynamically updated data, such as changes in market conditions. Outdated data will lead to errors in the final analysis results. Finally, relying on expert experience for prediction is very unscientific, which will damage the objectivity of the results and make the results easily erroneous.
The emergence of machine learning has greatly solved these problems. First, machine learning has a strong ability to handle data, which enables them to deal with large and complex data and learn from it [9]. Furthermore, they are good at prediction. After learning the data, the machine learning model will automatically generate a mechanism and then use this mechanism to make predictions. This meets the needs of dynamic assessment of financial risks and makes good use of the characteristics of the big data era [10]. Finally, machine learning has a strong visualization ability. This allows many risk managers who do not understand algorithms to directly manage risks based on clear graphs, greatly improving the efficiency of risk management [11].
For credit risk management, many teams use advanced machine learning models such as neural networks to improve the accuracy of credit scoring [12]. Many tree models and gradient boosting machines have also become common models for credit risk management due to their strong learning capabilities. In operational risk management, fraud detection has become a hot topic for the use of machine learning. The essence of fraud detection is to find anomalies and identify abnormal fraudulent behavior. Isolation forest is an algorithm designed specifically for anomaly detection, which can efficiently separate anomalies in data. At the same time, many clustering algorithms, such as K-means, are also often used to find abnormal groups. The application of machine learning has undoubtedly brought significant improvements in accuracy, creating new ways for risk management [13].
However, the application of machine learning in risk management also has many limitations. These new limitations are mainly reflected in two aspects. The first aspect is the gap between static and dynamic. Many models only use a single algorithm, which has caused many problems [14]. For example, people only use algorithms such as XGBoost that is good at handling static data or LSTM that is good at dealing with dynamic data, which makes it impossible to achieve both static and dynamic analysis. The second aspect is the contradiction between efficiency and accuracy. Many models combine multiple algorithms, which indeed improves accuracy but significantly reduces the efficiency of the entire model. Many algorithms require a precise review of each customer's long-term data, which slows the entire model.
These limitations collectively identify a clear research gap in the current literature. While machine learning has demonstrated superior performance in financial risk management, most existing approaches focus either on static data analysis or dynamic pattern recognition, but rarely on both. Furthermore, few solutions effectively address the competing demands of accuracy and efficiency in real-world financial applications. There remains a critical need for integrated frameworks that can leverage the strengths of multiple machine learning algorithms while mitigating their individual weaknesses. Therefore, reasonable hybrid models are urgently needed. This research aims to address these gaps by proposing a novel hybrid model that combines XGBoost for static analysis with LSTM for dynamic behavioral sequencing in credit risk. For operational risk management, a two-layer model that consists of Isolation Forest and Prophet will be introduced to achieve a more robust and adaptive solution.
3. Methods
This paper introduces two complicated models to address credit risk and operational risk, respectively. The first model combines XGBoost with the LSTM network algorithm to implement a double-check mechanism. This effectively combines XGBoost's static analysis capabilities and LSTM's dynamic analysis capabilities, significantly improving model accuracy. The second model is a two-layer model. The first layer uses an Isolation Forest algorithm for rapid screening, while the second layer uses a prophet model for detailed judgment.
3.1. Data preprocessing
Because financial data is mostly private, the available data is very limited. During data preprocessing, this study used the mean to fill missing data and standardized the data. When processing categorical features, such as jobs, this study used the average annual salary for each job as a numerical representation. Financial risk datasets are highly imbalanced [12]. For example, the number of good customers is always much bigger than the number of high-risk or fraud cases. To balance the data, this study used XGBoost's built-in functions for adjustment. For the other three models, this study applied the SMOTE technique to avoid severe overfitting. This technique inserts a small number of samples which are automatically generated.
3.2. Credit risk management model
First, for credit risk, the main purpose is to accurately determine whether customers are reliable. XGBoost is a collection of multiple decision trees. In XGBoost, different decision trees assess whether a user is a high-credit risk individual from different perspectives. XGBoost is highly practical because it performs well with numerical data, which is common in real life. Institutions can input customer data into the XGBoost model, then assign weights to key dimensions. Finally, XGBoost considers these factors and generates a high-risk assessment. In future engineering, this model considers annual income, number of overdue payments, and occupation. After extensive observation of industry data, this study finally weighted annual income, historical number of overdue payments, and occupational stability at 30%, 25%, and 20%, respectively. In addition to these three classic indicators, other features are also very important, such as debt-to-income ratio and historical credit history. These futures can help institutions to score customers’ credit. To improve assessment accuracy, institutions can weigh different aspects based on the special needs of their projects. In this study, to improve model performance, Hyperparameter Tuning was used to adjust several key XGBoost parameters. After tuning, the learning rate (eta) was set to 0.1 to ensure stable convergence. To control model complexity and prevent overfitting, the maximum tree depth (max_depth) was limited to 6. Row sampling (subsample=6) and column sampling (colsample_bytree=0.8) were also used to introduce randomness and enhance ensemble diversity. For this classification task, the objective function is set to binary:logistic. The optimal number of trees is 150(n_estimators=150). In XGBoost, this study employs a 0.3 validation split, which means 30% of the training data is used for training and 70% for testing. However, XGBoost focuses on analyzing static data, whereas financial risk is dynamic. This study adds an LSTM algorithm for dynamic risk management. The LSTM examines a user's historical behavior sequence and provides a final assessment result. In the forget gate, the LSTM records user black behaviours that can be erased. In the input gate, the LSTM selects and records users' high-risk behavior. Finally, based on the combined analysis of the forget and input gates, the LSTM generates the final assessment result in the output gate. In this study, the LSTM input is a series of monthly transaction records from the user over the past two years. These sequences include data on overdue payments, monthly transaction amounts, and transaction counts. Institutions can consider incorporating factors such as user activity and duration of activity into the LSTM input to improve fraud detection sensitivity. The sequence model used in this study consists of two layers: the first is a 128-unit LSTM layer that returns the complete output sequence. This is followed by a 64-unit LSTM layer for further feature extraction. Finally, the sequence outputs are summarized using a global average pooling layer. This combined information is then fed into a final output layer with one neuron and a sigmoid activation function to produce a probability score.The model is trained using the Adam optimizer with a default learning rate of 0.001. Considering the binary classification task, this study uses binary cross entropy as the loss function. The model is trained for 50 epochs with a batch size of 32. To prevent overfitting, this study uses a validation split of 0.2, with 20% of the training data and 80% of the test data. To further enhance the model's generalization and prevent overfitting, a dropout layer with a dropout rate of 0.5 is added after the LSTM layer. The combined model makes credit risk management more scientific.
3.3. Operational risk management model
For operational risk management, this risk is to detect suspected fraud. This study uses the Isolation Forest detection model, which is also a collection of decision trees. However, its focus is not on assessment but on identification. Each decision tree makes multiple decisions, breaking the customer base into single individual. Within the Isolation Forest, each decision tree adopts a different classification dimension. Finally, the Isolation Forest counts the number of times each customer is broken down into single individual. Then it will output people with an anomaly score. To better determine the score threshold, this study uses the ROC curve to find the optimal threshold. The machine iterates through each score, sets it as the threshold, and calculates the accuracy for that score. Finally, the score with highest accuracy value is selected as the threshold. Customers with scores bigger than this threshold are considered fraudulent. However, as fraudulent techniques evolve, fraudsters use long-term strategies, making it hard to identify them. Therefore, this study uses the Prophet time series model for a secondary screening. After Isolation Forest's rapid screening, it passes the target customers to the Prophet model for further analysis. The prophet model analyzes each customer's personal history, capturing three factors: trend, seasonality, and holiday. Based on these factors, the prophet model generates a forecast graph. If a customer's behaviors are very different from the forecasted data, the Prophet model suspects this person. In this study, the prophet model takes as input a monthly series of daily transaction amounts from a user. With these three factors, the Prophet model generates a future transaction trend for the user. If the user's transaction behaviors are greatly different from the generated trend, the Prophet model determines that the user is engaging in fraudulent activities. Combining the Isolation Forest and Prophet time series models, the Isolation Forest quickly screens for suspect customers, while the Prophet model examines individuals in person. This balances shortcomings of both algorithms. As a result, this model achieves both efficiency and accuracy.
4. Discussion
This study demonstrates that the proposed complicated models enhance the accuracy and robustness of financial risk management compared to traditional single-model approaches. In the figure 1 and 2, the research data indicates that proposed complicated models perform better than single models and previous solutions. The integration of XGBoost with LSTM effectively addresses the limitations of static analysis, and the combination of Isolation Forest and Prophet model improves the efficiency and accuracy. The success of the credit risk model is the result of combining both static features and dynamic behavioral patterns. In 2016, Chen et al. demonstrated that XGBoost played a significant positive role in credit risk classification [15]. However, XGBoost ignores the dynamic characteristics of financial risk, which is very important in finance. Therefore, this study chooses to add LSTM algorithm for dynamic analysis. The successful integration of LSTM and XGBoost enables the model to be both dynamic and static, thereby improving its accuracy.
In previous ways of operational risk management, two-stage models often outperform one-stage models [16]. This study also adopts a two-stage model. Considering that the first layer needs fast screening, the isolation forest algorithm is selected. On this basis, this model uses the prophet time series model in the second layer to conduct detailed individual screening. By integrating these two classic algorithms, this two-layer model has both efficiency and accuracy.
However, these two models also have certain limitations. Firstly, model performance is constrained by the availability and quality of data. Like many studies in this field, the challenges, such as the ethical use of customer data, are unavoidable and may affect the LSTM's ability to capture long-term information [17]. Secondly, for operational risk models, concept drift and resource consumption are two major problems. The model proposed in this study can only learn existing fraud methods and then make judgments. When concept drift occurs, meaning the fraud method changes, the model cannot detect it initially. This may lead to inaccurate detection results, allowing fraudsters to escape. Thirdly, the increased complexity of models comes at a cost. The LSTM and Prophet components are computationally more intensive and less inherently interpretable than a simple decision tree, which could be difficult to explain in real working environments. Lastly, the sensitivity of machine learning models is not very high, and they are easily affected by rare events and make wrong judgments [18].
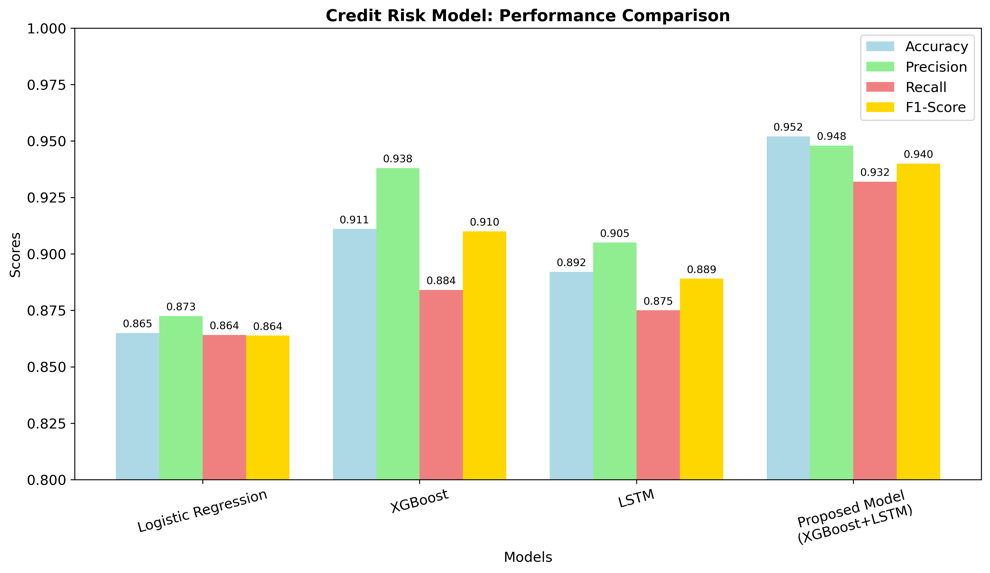
(Data from: https://www.kaggle.com/datasets/laotse/credit-risk-dataset)
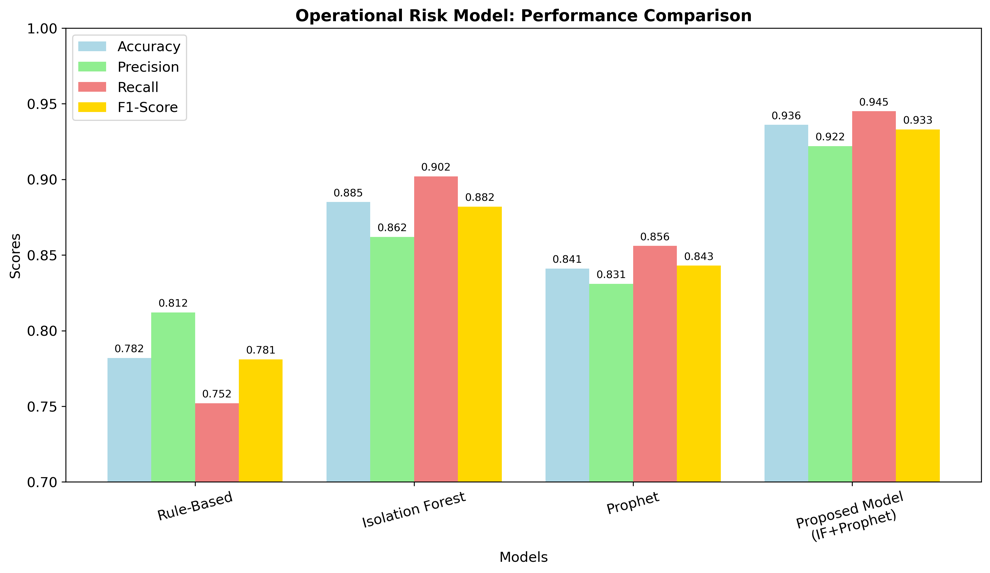
(Data from: https://www.kaggle.com/datasets/laotse/credit-risk-dataset)
Future research directions could focus on several areas. To address concept drift, an online learning mechanism could be integrated to update the model with new data periodically. To enhance interpretability, techniques such as SHAP or LIME can be employed to explain the predictions of the LSTM and Prophet models, making the 'black box' more transparent to risk. Furthermore, institutions can try to sign agreements with some trusted long-term customers and legally use their behavioral records as experimental data so that LSTM can capture long-term behavior. Despite these limitations, proposed models offer financial institutions a scalable and effective way to manage financial risk in the era of big data. By achieving a superior balance between accuracy and operational efficiency, this approach has the potential to reduce economic losses and foster a more secure financial environment. The methodologies explored could also be adapted to other domains, such as insurance or healthcare.
5. Conclusion
The models proposed in this paper make contributions both theoretically and practically. From the theoretical perspective, this study proposes hybrid modeling and demonstrates its effectiveness in dealing with both static and dynamic financial data. This fills a critical gap in existing approaches and helps give a more complete picture of risk than using just one type of model. From the practical perspective, through more accurate risk assessment and faster fraud detection, this research provides financial institutions with more effective tools to reduce financial losses. The proposed model offers a balanced solution to the long-standing trade-off between accuracy and efficiency. Despite these positive results, this research also has several limitations. First, the proposed model still relies on the quality and quantity of historical data. If the historical data is old, has missing information, or is biased, the model's predictions will be less reliable. This is a common problem when working with real-world data. Second, the credit management model suffers from the black box problem. The results generated by the LSTM algorithm cannot be well explained to customers, thus lacking great interpretability. Based on these limitations, future research is suggested to focus on several directions. First, exploring online learning techniques to make the model better adapt to concept drift in rapidly changing financial markets. Second, introducing explainable artificial intelligence (XAI) techniques, such as SHAP or LIME, will enhance the model's transparency and interpretability, thereby addressing the black box problem to a certain extent. Finally, the model should be tested on much larger and more varied datasets from different parts of finance, like insurance or investment banking. This will further verify its robustness and generalization ability.
References
[1]. Chakraborty, G. (2020). Evolving profiles of financial risk management in the era of digitization: The tomorrow that began in the past. Journal of Public Affairs, 20(2), e2034.
[2]. Horcher, K. A. (2011). Essentials of financial risk management. John Wiley & Sons. Retrieved from https: //books.google.com/books?hl=en& lr=& id=X__zoNzVh-QC& oi=fnd& pg=PT8& dq=Essentials+of+Financial+Risk+Management& ots=6uQ0cQkI-D& sig=LdAnZuV_1BUwonbsjt8Gv4hPmsE.
[3]. Hopkin, P. (2018). Fundamentals of risk management: understanding, evaluating and implementing effective risk management. Kogan Page Publishers.
[4]. Pang, S., Hou, X., & Xia, L. (2021). Borrowers’ credit quality scoring model and applications, with default discriminant analysis based on the extreme learning machine. Technological Forecasting and Social Change, 165, 120462.
[5]. Aloqab, A., Alobaidi, F., & Raweh, B. (2018). Operational risk management in financial institutions: An overview. Business and economic research, 8(2), 11-32.
[6]. RISK, F. (2010). ELEMENTS OF FINANCIAL RISK MANAGEMENT. Retrieved from https: //www.academia.edu/34311333/Elements_of_Financial_Risk_Management.
[7]. Bello, O. A. (2023). Machine learning algorithms for credit risk assessment: an economic and financial analysis. International Journal of Management, 10(1), 109-133. Retrieved from https: //eajournals.org/ijmt/wp-content/uploads/sites/69/2024/06/Machine-Learning-Algorithms.pdf.
[8]. Mashrur, A., Luo, W., Zaidi, N. A., & Robles-Kelly, A. (2020). Machine learning for financial risk management: a survey. Ieee Access, 8, 203203-203223
[9]. Addy, W. A., Ajayi-Nifise, A. O., Bello, B. G., Tula, S. T., Odeyemi, O., & Falaiye, T. (2024). Machine learning in financial markets: A critical review of algorithmic trading and risk management. International Journal of Science and Research Archive, 11(1), 1853-1862.
[10]. SULTAN, M. (2025). Machine Learning Models for Financial Risk Assessment. Retrieved from https: //www.researchgate.net/publication/390661682_Machine_Learning_Models_for_Financial_Risk_Assessment.
[11]. Guan, C., Suryanto, H., Mahidadia, A., Bain, M., & Compton, P. (2023). Responsible credit risk assessment with machine learning and knowledge acquisition. Human-Centric Intelligent Systems, 3(3), 232-243.
[12]. Bhatore, S., Mohan, L., & Reddy, Y. R. (2020). Machine learning techniques for credit risk evaluation: a systematic literature review. Journal of Banking and Financial Technology, 4(1), 111-138.
[13]. Aziz, S., & Dowling, M. (2019). Machine learning and AI for risk management. Disrupting finance, 33-50.
[14]. Bussmann, N., Giudici, P., Marinelli, D., & Papenbrock, J. (2021). Explainable machine learning in credit risk management. Computational Economics, 57(1), 203-216.
[15]. Chen, T., & Guestrin, C. (2016, August). Xgboost: A scalable tree boosting system. In Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining (pp. 785-794).
[16]. Araz, O. M., Choi, T. M., Olson, D. L., & Salman, F. S. (2020). Data analytics for operational risk management. Decis. Sci., 51(6), 1316-1319.
[17]. Eceiza, J., Kristensen, I., Krivin, D., Samandari, H., & White, O. (2020). The future of operational-risk management in financial services. Preuzeto, 17, 2022. Retrieved from https: //www.mckinsey.com/~/media/McKinsey/Business%20Functions/Risk/Our%20Insights/The%20future%20of%20operational%20risk%20management%20in%20financial%20services/The-future-of-operational-risk-management-in-financial-services-vF.pdf.
[18]. Bracke, P., Datta, A., Jung, C., & Sen, S. (2019). Machine learning explainability in finance: an application to default risk analysis.
Cite this article
Liu,X. (2025). Financial Risk Control and Management Based on Machine Learning. Applied and Computational Engineering,202,31-38.
Data availability
The datasets used and/or analyzed during the current study will be available from the authors upon reasonable request.
Disclaimer/Publisher's Note
The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of EWA Publishing and/or the editor(s). EWA Publishing and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content.
About volume
Volume title: Proceedings of CONF-MLA 2025 Symposium: Intelligent Systems and Automation: AI Models, IoT, and Robotic Algorithms
© 2024 by the author(s). Licensee EWA Publishing, Oxford, UK. This article is an open access article distributed under the terms and
conditions of the Creative Commons Attribution (CC BY) license. Authors who
publish this series agree to the following terms:
1. Authors retain copyright and grant the series right of first publication with the work simultaneously licensed under a Creative Commons
Attribution License that allows others to share the work with an acknowledgment of the work's authorship and initial publication in this
series.
2. Authors are able to enter into separate, additional contractual arrangements for the non-exclusive distribution of the series's published
version of the work (e.g., post it to an institutional repository or publish it in a book), with an acknowledgment of its initial
publication in this series.
3. Authors are permitted and encouraged to post their work online (e.g., in institutional repositories or on their website) prior to and
during the submission process, as it can lead to productive exchanges, as well as earlier and greater citation of published work (See
Open access policy for details).
References
[1]. Chakraborty, G. (2020). Evolving profiles of financial risk management in the era of digitization: The tomorrow that began in the past. Journal of Public Affairs, 20(2), e2034.
[2]. Horcher, K. A. (2011). Essentials of financial risk management. John Wiley & Sons. Retrieved from https: //books.google.com/books?hl=en& lr=& id=X__zoNzVh-QC& oi=fnd& pg=PT8& dq=Essentials+of+Financial+Risk+Management& ots=6uQ0cQkI-D& sig=LdAnZuV_1BUwonbsjt8Gv4hPmsE.
[3]. Hopkin, P. (2018). Fundamentals of risk management: understanding, evaluating and implementing effective risk management. Kogan Page Publishers.
[4]. Pang, S., Hou, X., & Xia, L. (2021). Borrowers’ credit quality scoring model and applications, with default discriminant analysis based on the extreme learning machine. Technological Forecasting and Social Change, 165, 120462.
[5]. Aloqab, A., Alobaidi, F., & Raweh, B. (2018). Operational risk management in financial institutions: An overview. Business and economic research, 8(2), 11-32.
[6]. RISK, F. (2010). ELEMENTS OF FINANCIAL RISK MANAGEMENT. Retrieved from https: //www.academia.edu/34311333/Elements_of_Financial_Risk_Management.
[7]. Bello, O. A. (2023). Machine learning algorithms for credit risk assessment: an economic and financial analysis. International Journal of Management, 10(1), 109-133. Retrieved from https: //eajournals.org/ijmt/wp-content/uploads/sites/69/2024/06/Machine-Learning-Algorithms.pdf.
[8]. Mashrur, A., Luo, W., Zaidi, N. A., & Robles-Kelly, A. (2020). Machine learning for financial risk management: a survey. Ieee Access, 8, 203203-203223
[9]. Addy, W. A., Ajayi-Nifise, A. O., Bello, B. G., Tula, S. T., Odeyemi, O., & Falaiye, T. (2024). Machine learning in financial markets: A critical review of algorithmic trading and risk management. International Journal of Science and Research Archive, 11(1), 1853-1862.
[10]. SULTAN, M. (2025). Machine Learning Models for Financial Risk Assessment. Retrieved from https: //www.researchgate.net/publication/390661682_Machine_Learning_Models_for_Financial_Risk_Assessment.
[11]. Guan, C., Suryanto, H., Mahidadia, A., Bain, M., & Compton, P. (2023). Responsible credit risk assessment with machine learning and knowledge acquisition. Human-Centric Intelligent Systems, 3(3), 232-243.
[12]. Bhatore, S., Mohan, L., & Reddy, Y. R. (2020). Machine learning techniques for credit risk evaluation: a systematic literature review. Journal of Banking and Financial Technology, 4(1), 111-138.
[13]. Aziz, S., & Dowling, M. (2019). Machine learning and AI for risk management. Disrupting finance, 33-50.
[14]. Bussmann, N., Giudici, P., Marinelli, D., & Papenbrock, J. (2021). Explainable machine learning in credit risk management. Computational Economics, 57(1), 203-216.
[15]. Chen, T., & Guestrin, C. (2016, August). Xgboost: A scalable tree boosting system. In Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining (pp. 785-794).
[16]. Araz, O. M., Choi, T. M., Olson, D. L., & Salman, F. S. (2020). Data analytics for operational risk management. Decis. Sci., 51(6), 1316-1319.
[17]. Eceiza, J., Kristensen, I., Krivin, D., Samandari, H., & White, O. (2020). The future of operational-risk management in financial services. Preuzeto, 17, 2022. Retrieved from https: //www.mckinsey.com/~/media/McKinsey/Business%20Functions/Risk/Our%20Insights/The%20future%20of%20operational%20risk%20management%20in%20financial%20services/The-future-of-operational-risk-management-in-financial-services-vF.pdf.
[18]. Bracke, P., Datta, A., Jung, C., & Sen, S. (2019). Machine learning explainability in finance: an application to default risk analysis.