







1. Introduction
Music, as an essential part of society, combines vocal and instrumental sounds to create beauty, and harmony and can evoke emotional expression [1]. In today's world, music is deeply intertwined with people's lives. With advanced technology, music apps make it easy for listeners to find songs they like. The music industry has also developed, especially online. Those music applications change people’s daily lives, and the media of music alters dramatically. Thus, traditional music forms are outdated and an inaccurate portrayal of the organizational structure of the global music economy in the mid-2000s [2].
One common application of music trend prediction is to help users discover genres and styles they prefer. As technology continues to advance, the digitization of music has significantly transformed how music is consumed, produced, and distributed. Digitization has led to more diverse cultural markets, and it has increased the accessibility to international music in the globalized market [3]. The music industry spans various regions such as East Asia, Europe, and the USA, each with unique cultural backgrounds and music preferences. Through the diverse styles and massive amounts of songs various music applications can provide now, people can find more songs with the lyrics or styles they like by checking the recommendations of those apps. The recommendation system is also driven by music trend prediction. Specifically, the usage of the collaborative-filtering (CF) model or content-based (CB) model is a mature technology to track the popularity of certain songs among the users in a platform considering music trend prediction [4]. Music recommendation not only enables music app users to quickly search for new songs they like for their entertainment but also provides opportunities for music companies so they can change their marketing strategies and release new songs to meet the popularity among massive users to earn more profit.
Modern music trend prediction relies heavily on model training. Trained models analyze databases to identify song styles that users prefer. Common algorithms used in model training include the nearest neighbor search (NNS), decision trees, and learning algorithms. These algorithms can track changes in music trends over time by mining data about genres and styles based on evaluation metrics. This process is called data mining (DM) [5]. After data collection, models can extract audio features like rhythm, melody, and harmony, as well as text features such as keywords and sentiment analysis. Using these features, data can be further cleaned since the raw data have so much unnecessary and irrelevant information. By utilizing such clean data after processing, models can predict user preferences based on the data set without some dirty data such as missing values, duplicating data, etc. Through prediction from such models, a general trend of music genres can be analyzed by researchers to benefit from it.
This review paper aims to collect and compare key model training methods in the chosen journals, analyzing their effectiveness in data mining, the use of their models, and the accuracy of their music trend prediction in order to evaluate the methods they use and compare and contrast those mainstream models used by those researchers.
2. The Procedure of Music Trend Prediction
The process of music trend prediction is complicated. Many procedures need to be done to make an accurate prediction of the music trend. The complete flowchart of music trend prediction is shown in Figure 1.
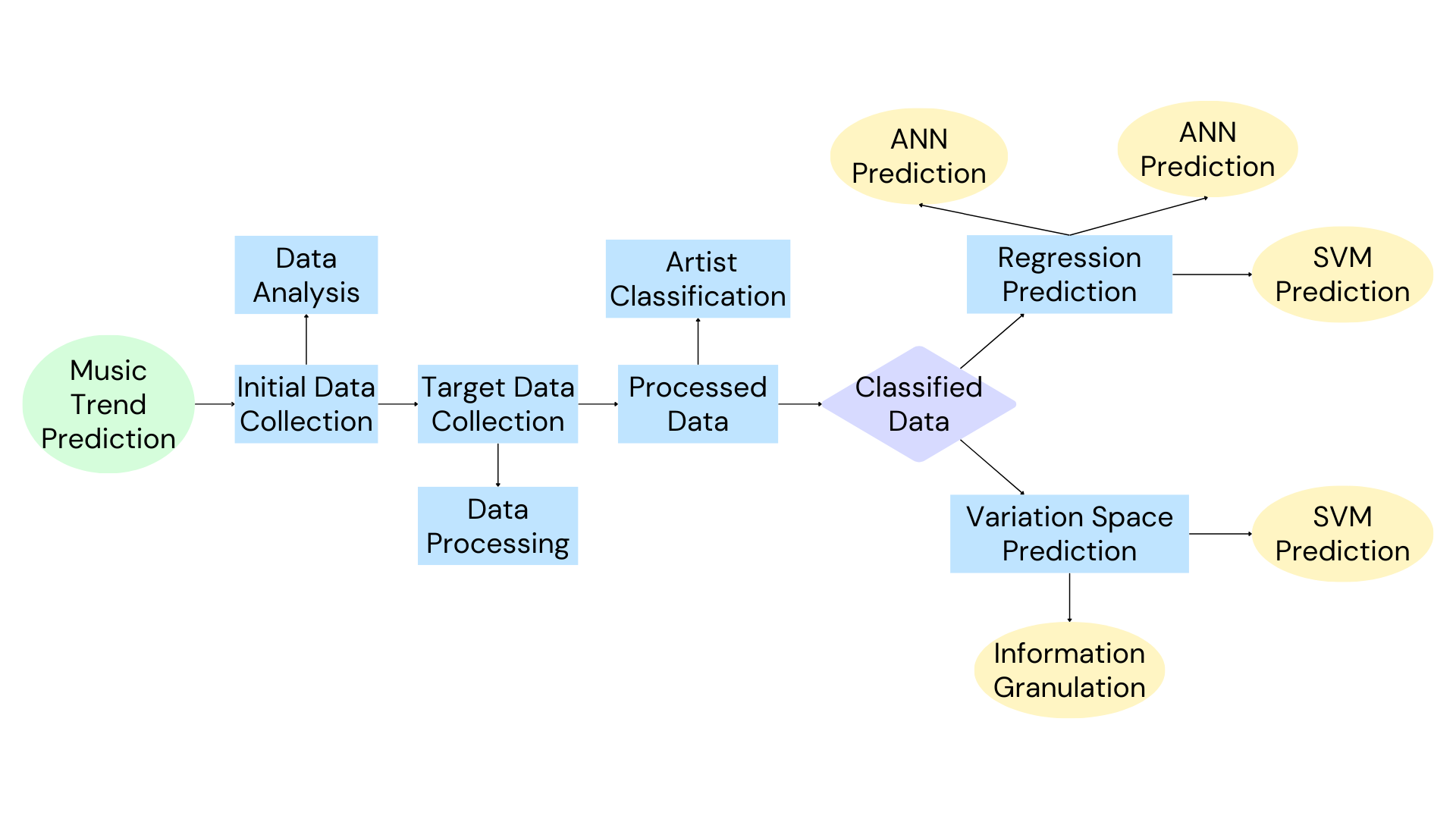
Figure 1: Flowchart of the music trend prediction.
2.1. Initial Data Collection
Data collection is the first step among all. Before predicting the trend, a massive amount of data must be collected from different platforms so that the database for the models is large enough for them to predict. For many of the predictions, data on the music are commonly collected from famous music apps such as Spotify, Apple Music, etc. Through the data from those music apps, the prediction can have enough data for models to predict the trend.
2.2. Target Data Collection
After collecting data from the music apps, are lot of data exists in the database for the prediction right now. However, many of them are useless or irrelevant to the topics that need to be investigated, including filling in missing values, filtering out duplicates or invalid entries, standardizing formats, cross-checking information, and adding more details. As a result, data mining is necessary to find valid, potentially useful, and easily understandable correlations and patterns in existing data. There are four types of data mining in the field of prediction: Classification Analysis, Regression Analysis, Time series analysis, and Prediction Analysis [6]. When predicting the music trend, regression analysis and prediction analysis are usually used, and both of them require data cleaning so that further analysis can be done.
For data cleaning, there are typically five steps: Remove duplicate or irrelevant observations, Fix structural errors, Filter unwanted outliers, Handle missing data, and Validate and QA [6]. All of these require a large amount of work and precise filtration so that useful information can be retained and irrelevant data can be cleaned out.
2.3. Processing Data
After cleaning the data, normalization, and standardization are needed to reduce attributes and eliminate data redundancy, making the data more understandable. Common forms of standardization include StandardScaler, Scale, RobustScaler, QuantileTransform, PowerTransform, MinMaxS caler, and MaxAbsS caler [7]. After normalization, music data can be standardized into a unified version for easier analysis.
Dimensionality reduction represents a dataset with fewer features while preserving its meaningful properties. High-dimensional data take up significant space and increase computation time, making dimensionality reduction necessary. This allows data to be stored more efficiently. Methods for dimensionality reduction include Principal Component Analysis (PCA), Linear Discriminant Analysis (LDA), and T-distributed Stochastic Neighbor Embedding [8]. LDA, often used in music trend prediction, is a linear dimension reduction method like PCA, but it retains classification labels. These methods reduce the dimensionality of music data, allowing models to store and analyze data more efficiently with less computational cost.
2.4. Classified Data
Finally, the processed data can be classified into different categories to make predictions. There are two main types of prediction methods to predict music trends: regression prediction and variation space prediction. Regression prediction is the most common statistical machine learning algorithm to find the linear relationships between one or more predictors, and it has two types: simple regression and multiple regression [9]. Based on the concepts of linear regression, artificial Neural Networks (ANN) and Support Vector Machines (SVM) methods are developed to further predict a more accurate result of the music trend.
Besides linear regression, the variable space prediction method is also used by many researchers. To deal with problems of uncertain analysis, information granulation, a type of variable space prediction method, provides an effective solution for uncertain analysis by extracting the maximum and minimum-related information from raw time series [10]. In addition, SVM prediction can also solve such problems of uncertainty by avoiding it and converting the problem to form that a linear regression prediction model can deal with.
3. Methodology of Music Trend Prediction
Training models is the core process of music trend prediction since human beings cannot handle such a large amount of data stored in the database. Therefore, choosing an appropriate model for the prediction becomes the most important thing.
To train a model, machine learning techniques are required. Machine learning refers to a branch of computer science that focuses on using data and algorithms to enable AI to imitate the way that humans learn, gradually improving its accuracy [10]. Through AI and machine learning algorithms, trained models can help researchers address the data stored in a database so that a common trend can be predicted.
Until now, many researchers have found methods to train mature models for trend prediction. They mainly used the methods of machine learning and deep learning to establish the models and find the music trend by utilizing them.
3.1. Machine Learning Models
Wu, a researcher among them, used a method called big data algorithm [11]. Wu calculated the time series symbol aggregation by utilizing the starting and the end distance in the process of prediction. The method deals with problems of the fact that the consistency of symbols cannot be measured in each sequence segment and inaccurate prediction caused by the sudden increase of the amount of music data, which in turn, increases the effect of the distance amount. The method has an advantage over other music trend prediction models using time series since the F value calculated by using this model is 5064 which is superior. The result shows that the average song-playing amount is better than the original song-playing amount.
Qin applied the Deepwalk and Cosine Similarity Method and created a mathematical model to evaluate the influence of the musicians [12]. On the other hand, a music similarity model is utilized in the paper, which is based on the PCA, and Euclidean distance. The model successfully summarizes the music similarity based on genres.According to the theory mentioned in the paper, the trend of music genre and music similarity can help predict the music trend, which means the music similarity and the mathematical model can successfully predict the music trend.
Agarwal proposed a machine-learning model to analyze the potential popularity of a song so that certain marketing strategies can be determined [13]. The model combines genre-based prediction and clustering methods by using machine learning algorithms. Specifically, the methodology contains feature extraction from the songs, using clustering of datasets, applying those datasets to the model of genre-based and cluster-based approaches trained by themselves, and using the Extra Tree regressor to further improve accuracy so that their model can achieve a satisfactory outcome to predict the song popularity up to date. The composers can use the model to revise their songs to meet the needs of the market based on the results of the trend prediction.
3.2. Deep Learning Models
Dhanushya focuses on how digital streaming platforms affect artistic collaborations within the Spotify environment. This approach contains the features of Eigen centrality measures, artist popularity, and genre information, and it utilizes the SEAL framework to achieve this [14]. Besides, Graph Neural Networks (GNNs) such as Graph Convolution Network (GCN), Graph Attention Networks (GAT), Graph Isomorphism Network (GIN), and GraphSage are used so that a precise predictive model can be established. In addition, the research explores the concept of ensemble modeling to increase the precision of the link prediction model. Finally, the research achieves an accuracy of 0.795 and 0.957 based on whether the ensemble approach contains a SEAL framework or not.
Cai predicts the trend of different music genres as the music develops [15]. The research paper is based on the dataset of Integrative Collective Music (ICM) and the influence_data dataset investigating the relationship between those factors that affect the trend of music genres and the followers, and it successfully creates a network graph structure to showcase the music influence and utilizes PageRank algorithm to quantify the influence, which is the impact factor. To solve the impact factor, the Long Short-term Memory (LSTM) neural network to predict music development based on music genres.
4. Limitations and Future Perspectives
4.1. Limitations
In the above paper, several proposed models from researchers in different countries are listed, indicating the development of model training in the field of music trend prediction in machine learning. However, there are still some limitations exist in those methods.
4.1.1. Lack of Research Data access/Data Quality
Those journals aiming to predict music trends in different ways have a common limitation which is the lack of research data access. The research has a relatively reliable data set and complete procedures to analyze those data. However, the data are all limited to a very small scale. The data set in Wu’s research is based on Alibaba Cloud Music, which is a reliable source for investigating features of pop music and collecting users’ data on playing music. However, the data set is still limited on a small scale, which means the research is lack of data access. This is because Alibaba Cloud Music is a platform established mainly in China which could have strong bias toward certain groups of people or certain regions. In addition, the limitation of this platform means that the music trend cannot be generalized. Such bias in specific platforms and limitation of data set hinder the generalization of the prediction of the music trend to be accurate.
4.1.2. Temporal Dynamics and Static Trends
Besides the problem of data quality and lack of access to diverse data sets of songs, the research of those journals also has a common problem which is the fact that the predictions can only have temporal dynamics, and all predict static trends of music popularity and user patterns. Specifically, that research cannot handle the change of music trends in the future, they can only predict them concerning current features of music and user information. For instance, Agarwal focuses on features like loudness, energy, danceability, etc. which all should be dynamic in real life but are assumed to be static in the data set provided in the research paper. This means the prediction of the genre-based and cluster-based model trained by the machine learning approach is limited to the data collected at the time when the researchers gathered them. However, the music trend might change dynamically through many factors including time, social and cultural influences, marketing and industrial strategies of different companies and countries, etc. Therefore, the static data from the Kaggle data set cannot accurately predict the music trend around the globe in the future either.
4.2. Future Perspectives
The limitations mentioned above also hinder the research to make accurate predictions. As a result, some attempts can be made in the future to improve the field of music prediction.
4.2.1. Public Data Set
A common problem of this research is the data quality. Data collected from different platforms might cause a bias towards certain cultural groups or countries. The popularity of songs would also be very different under different social and cultural backgrounds, marketing strategies, etc. Thus, a public data set becomes necessary to unify the large variety of data from those different music platforms. Even though the data cleaning process may become more complicated and dirty data such as missing values, duplicating data, etc. might become hard to identify, a public data set for global music data is still necessary for the prediction of the music trend so that it can be more accurate by analyzing data with less bias and fewer inclinations towards certain groups. Through such a public data set collected data from all mainstream music platforms with as many users as possible, research of music trend prediction can be more precise and the prediction can be used to make marketing strategies or for composers to revise their songs.
4.2.2. Support of Music Industry
Music trend prediction has many useful applications, and the essential one is to support the music industry to some extent. By analyzing user information and music popularity in general, many companies in the music industry can take advantage of it. They can modify their marketing strategy and revise their investment or release songs to make more profit. In addition, music platforms can personalize the styles so that a specific user is fond of them. Such a recommending system is very useful for both the operator of the app and the users. The operator can attract more users to use the music app to make more profits. On the other hand, the users can also find lots of new music they like to enjoy. The whole procedure could boost the whole music industry and enhance the advancement of technologies and creations in the field of live music.
5. Conclusion
The music industry has become much more advanced than before. To make better plans and strategies for both composers and music companies operating music apps, music trend prediction is necessary to track the popularity of songs among the public. To make it successful, there is a common procedure including initial data collection, target data collection, processing data, and classifying data so that different methods can be applied. After gathering data, models need to be trained to help predict the trend of the music. Many researchers are trying to make such models. The journals listed in this review paper are examples of them. They used different methods including big data algorithms, making mathematical models, feature extraction from the songs, utilizing SEAL framework and GNNs, and using influence data set and ICM. By applying these models, they got different outcomes of the music's popularity. However, the predictions made by those researchers have some common drawbacks. First, the data are collected from different music platforms, and some of them may have a bias towards certain groups or regions since they are not popular enough to attract users from around the world. Thus, a common public data set of music might be established in the future to limit the bias of data and increase data access and quality. Another drawback is the characteristic of static prediction. The data used for prediction is not dynamic so influences such as social changes or technological advances cannot be counted into the model prediction. Still, current prediction of music trends can help support the music industry which is an impressive application of machine learning.
References
[1]. Warrenburg, L. A. (2019). Comparing Musical and Psychological Emotion theories. Psychomusicology: Music, Mind, and Brain. https://doi.org/10.1037/pmu0000247
[2]. WILLIAMSON, J., & CLOONAN, M. (2007). Rethinking the Music Industry. Popular Music, 26(02), 305.
[3]. Bello, P., & Garcia, D. (2021). Cultural Divergence in Popular music: the Increasing Diversity of Music Consumption on Spotify across Countries. Humanities and Social Sciences Communications, 8(1).
[4]. Deldjoo, Y., Schedl, M., & Knees, P. (2024). Content-driven Music recommendation: Evolution, State of the art, and Challenges. Computer Science Review, 51, 100618.
[5]. Xu, Y., Wang, M., Chen, H., & Hu, F. (2022). Prediction Model of Music Popular Trend Based on NNS and DM Technology. ProQuest.
[6]. Brownlee, J. (2020). Data Preparation for Machine Learning. Machine Learning Mastery.
[7]. Raju, V. N. G., Lakshmi, K. P., Jain, V. M., Kalidindi, A., & Padma, V. (2020, August 1). Study the Influence of Normalization/Transformation Process on the Accuracy of Supervised Classification. IEEE Xplore.
[8]. Reddy, G. T., Reddy, M. P. K., Lakshmanna, K., Kaluri, R., Rajput, D. S., Srivastava, G., & Baker, T. (2020). Analysis of Dimensionality Reduction Techniques on Big Data. IEEE Access, 8(5), 54776–54788.
[9]. Maulud, D., & Abdulazeez, A. M. (2020). A Review on Linear Regression Comprehensive in Machine Learning. Journal of Applied Science and Technology Trends, 1(4), 140–147.
[10]. Li, Y., Tong, Z., Tong, S., & Westerdahl, D. (2022). A data-driven Interval Forecasting Model for Building Energy Prediction Using attention-based LSTM and Fuzzy Information Granulation. Sustainable Cities and Society, 76, 103481.
[11]. Wu, D., & Zhao, J. (2023). Construction of Music Popular Trend Prediction Model Based on Big Data Algorithm. 40, 346–350.
[12]. Qin, C., Yang, H., Liu, W., Ding, S., & Geng, Y. (2021). Music Genre Trend Prediction Based on Spatial-Temporal Music Influence and Euclidean Similarity. 2022 37th Youth Academic Annual Conference of Chinese Association of Automation (YAC), 2, 406–411.
[13]. Agarwal, S., Goyal, J., Thapa, S., Deshpande, A., Aryan, N., & Kumari, D. (2023). Live Music popularity prediction using genre and clustering based classification system: A machine learning approach. 8, 67–71.
[14]. Dhanushya M, Gowri Nandana P K, Gutta Lavanya, & Arya, A. (2023). Anticipating Collaborative Trends in Spotify Music using Variants of Graph Neural Networks.
[15]. Cai, H., Luo, Y., Pu, T., & He, G. (2021). Research on the Influence Factors and Genre Development Trends of Music Based on PageRank and LSTM Model. 2021 4th International Conference on Advanced Electronic Materials, Computers and Software Engineering (AEMCSE), 498–501.
Cite this article
He,J. (2025). Live Music Industry and Common Music Trend Prediction in Machine Learning Algorithms. Applied and Computational Engineering,121,51-57.
Data availability
The datasets used and/or analyzed during the current study will be available from the authors upon reasonable request.
Disclaimer/Publisher's Note
The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of EWA Publishing and/or the editor(s). EWA Publishing and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content.
About volume
Volume title: Proceedings of the 5th International Conference on Signal Processing and Machine Learning
© 2024 by the author(s). Licensee EWA Publishing, Oxford, UK. This article is an open access article distributed under the terms and
conditions of the Creative Commons Attribution (CC BY) license. Authors who
publish this series agree to the following terms:
1. Authors retain copyright and grant the series right of first publication with the work simultaneously licensed under a Creative Commons
Attribution License that allows others to share the work with an acknowledgment of the work's authorship and initial publication in this
series.
2. Authors are able to enter into separate, additional contractual arrangements for the non-exclusive distribution of the series's published
version of the work (e.g., post it to an institutional repository or publish it in a book), with an acknowledgment of its initial
publication in this series.
3. Authors are permitted and encouraged to post their work online (e.g., in institutional repositories or on their website) prior to and
during the submission process, as it can lead to productive exchanges, as well as earlier and greater citation of published work (See
Open access policy for details).
References
[1]. Warrenburg, L. A. (2019). Comparing Musical and Psychological Emotion theories. Psychomusicology: Music, Mind, and Brain. https://doi.org/10.1037/pmu0000247
[2]. WILLIAMSON, J., & CLOONAN, M. (2007). Rethinking the Music Industry. Popular Music, 26(02), 305.
[3]. Bello, P., & Garcia, D. (2021). Cultural Divergence in Popular music: the Increasing Diversity of Music Consumption on Spotify across Countries. Humanities and Social Sciences Communications, 8(1).
[4]. Deldjoo, Y., Schedl, M., & Knees, P. (2024). Content-driven Music recommendation: Evolution, State of the art, and Challenges. Computer Science Review, 51, 100618.
[5]. Xu, Y., Wang, M., Chen, H., & Hu, F. (2022). Prediction Model of Music Popular Trend Based on NNS and DM Technology. ProQuest.
[6]. Brownlee, J. (2020). Data Preparation for Machine Learning. Machine Learning Mastery.
[7]. Raju, V. N. G., Lakshmi, K. P., Jain, V. M., Kalidindi, A., & Padma, V. (2020, August 1). Study the Influence of Normalization/Transformation Process on the Accuracy of Supervised Classification. IEEE Xplore.
[8]. Reddy, G. T., Reddy, M. P. K., Lakshmanna, K., Kaluri, R., Rajput, D. S., Srivastava, G., & Baker, T. (2020). Analysis of Dimensionality Reduction Techniques on Big Data. IEEE Access, 8(5), 54776–54788.
[9]. Maulud, D., & Abdulazeez, A. M. (2020). A Review on Linear Regression Comprehensive in Machine Learning. Journal of Applied Science and Technology Trends, 1(4), 140–147.
[10]. Li, Y., Tong, Z., Tong, S., & Westerdahl, D. (2022). A data-driven Interval Forecasting Model for Building Energy Prediction Using attention-based LSTM and Fuzzy Information Granulation. Sustainable Cities and Society, 76, 103481.
[11]. Wu, D., & Zhao, J. (2023). Construction of Music Popular Trend Prediction Model Based on Big Data Algorithm. 40, 346–350.
[12]. Qin, C., Yang, H., Liu, W., Ding, S., & Geng, Y. (2021). Music Genre Trend Prediction Based on Spatial-Temporal Music Influence and Euclidean Similarity. 2022 37th Youth Academic Annual Conference of Chinese Association of Automation (YAC), 2, 406–411.
[13]. Agarwal, S., Goyal, J., Thapa, S., Deshpande, A., Aryan, N., & Kumari, D. (2023). Live Music popularity prediction using genre and clustering based classification system: A machine learning approach. 8, 67–71.
[14]. Dhanushya M, Gowri Nandana P K, Gutta Lavanya, & Arya, A. (2023). Anticipating Collaborative Trends in Spotify Music using Variants of Graph Neural Networks.
[15]. Cai, H., Luo, Y., Pu, T., & He, G. (2021). Research on the Influence Factors and Genre Development Trends of Music Based on PageRank and LSTM Model. 2021 4th International Conference on Advanced Electronic Materials, Computers and Software Engineering (AEMCSE), 498–501.