







1. Introduction
The exponential growth of social media platforms, including Twitter and Weibo, has generated massive volumes of user-generated text. This abundance of text has made sentiment analysis a critical tool for decoding public opinion on various topics, such as brands, policies, and societal trends. Traditional methods of sentiment analysis often face challenges when dealing with the informal language, sarcasm, and cultural nuances present in text from platforms like Twitter and Weibo. For instance, studies have revealed that economic factors dominate discussions related to AIGC on Weibo, with 78% of posts focusing on this topic, while Twitter discussions tend to center on technical ethics [1]. This contextual gap between different platforms and cultures necessitates the use of advanced computational approaches to extract actionable insights.
Recent advances in the field have highlighted Python’s dominance in sentiment analysis, primarily due to its powerful NLP libraries such as NLTK and spaCy, as well as its robust deep learning frameworks including TensorFlow and PyTorch. Key innovations in Python-based sentiment analysis include BERT-based ensembles, which have achieved 6-12% gains in F1-scores over legacy tools by combining contextual embeddings [2]. Another important innovation is hierarchical Transformers, which have outperformed state-of-the-art (SOTA) models in financial sentiment analysis by using RoBERTa with multi-head attention, achieving cosine similarity values ranging from 0.88 to 0.92 [3]. Additionally, dual-channel attention models that integrate RoBERTa-wwm-ext with BiLSTM have reached an accuracy of 93.44% on Chinese reviews [4].
This paper employs a combination of literature review and case analysis to examine Python-driven techniques for social media sentiment analysis. The focus areas of this examination include deep learning architectures such as BERT, BiLSTM, and attention mechanisms, cross-platform adaptation strategies like lexicon customization for Weibo versus Twitter, and the challenges associated with real-time deployment. The paper contributes to the field in several ways. In terms of theoretical innovation, it synthesizes the cultural and technical dimensions of sentiment expression. For practical applications, it provides implementable Python pipelines for domain-specific sentiment tracking in fields such as finance and healthcare. Additionally, it addresses ethical AI development by highlighting bias mitigation strategies in capital-driven sentiment analysis.
2. Fundamentals of sentiment analysis
2.1. Definition & scope expansion
Sentiment analysis (SA) is defined as the computational study of opinions, emotions, and subjectivity in text. Its applications span a wide range of fields, including brand monitoring, political campaigning, and public health. The core tasks of sentiment analysis include polarity classification, which can be binary (classifying text as positive or negative) or fine-grained (such as 5-star ratings), aspect-based analysis that involves extracting sentiment toward specific entities (for example, "battery life" in product reviews), and emotion detection that focuses on identifying emotions like joy, anger, and sadness [5].
2.2. Machine learning methods: deep dive
Feature engineering is a crucial aspect of machine learning-based sentiment analysis. Lexical features, such as TF-IDF weighted unigrams and bigrams, are commonly used [6]. Syntactic features, including part-of-speech (POS) tags and dependency parsing, also play an important role in capturing the structure of text [7]. Sentiment lexicons like SentiWordNet and NTUSD with polarity scores are another key component. An example of using a sentiment lexicon in Python is shown in the following code snippet, which demonstrates lexicon integration using the NLTK library [3]:
from nltk.sentiment import SentimentIntensityAnalyzer
sia = SentimentIntensityAnalyzer()
polarity = sia.polarity_scores("The camera quality is stunning!")['compound']
However, machine learning methods for sentiment analysis have certain limitations. They often fail to handle negations effectively, for instance, misclassifying the phrase "not good" as positive. Additionally, their accuracy plateaus at approximately 82% F1 on noisy social media text [4].
2.3. Deep learning: architectural innovations
Contextual embeddings are a significant advancement in deep learning-based sentiment analysis. Models like BERT and RoBERTa generate dynamic word vectors that can resolve polysemy, such as distinguishing between "bank" used as a financial institution and "bank" referring to a riverbank. Attention mechanisms, particularly multi-head attention, are capable of capturing dependencies between distant words in a text, which enhances the model’s ability to understand the context. A visual representation of a model architecture incorporating attention mechanisms is provided in Figure 1.
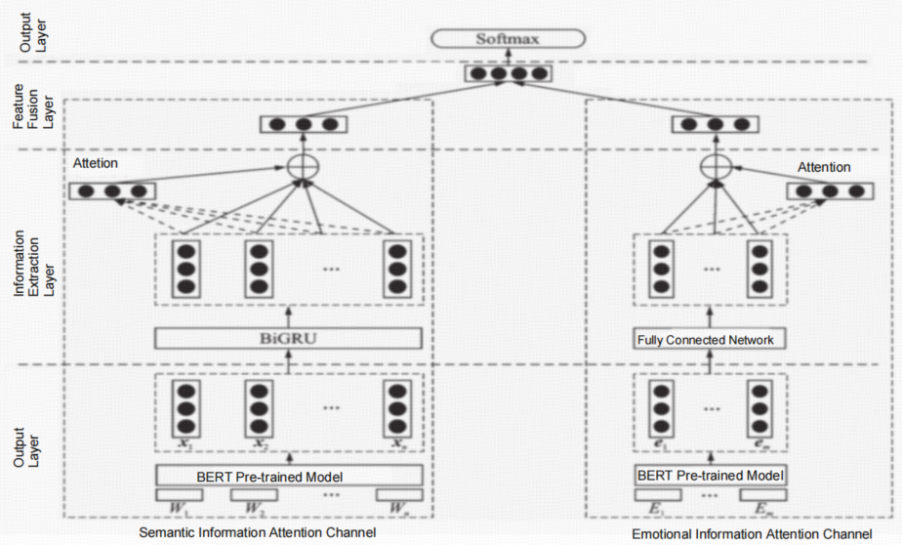
Hybrid models that combine different deep learning architectures have also shown promising results. The BERT-BiLSTM-Attention model combines BERT's context awareness with BiLSTM's sequence modeling capabilities. This hybrid approach has led to improved performance, with an accuracy of 93.44% compared to 86.7% for the SVM model [4].
3. Python in social media SA: extended case studies
3.1. Weibo analysis: technical enhancement
For Weibo sentiment analysis, the data source typically includes 15K posts from ChnSentiCorp along with live API streams. Advanced preprocessing steps are essential to handle the unique characteristics of Weibo text. Emoji translation is one such step, where emojis are mapped to the word "happy" using Unicode tables. Slang normalization is also important, for example, converting the slang term "yyds" (which means "eternal god" in Chinese internet slang) to its standard meaning.
The RoBERTa-wwm-ext model is often used for Weibo sentiment analysis. This model is pretrained on Chinese Wikipedia and a Weibo corpus and undergoes domain adaptation by being fine-tuned with finance and healthcare lexicons [9]. The performance of this model, along with comparisons to other models like SVM and BERT, is presented in Table 1.
|
Metric |
SVM |
BERT |
RoBERTa-BiLSTM-MHA |
|
Accuracy |
86.7% |
91.2% |
93.44% |
|
F1-Score |
0.82 |
0.89 |
0.93 |
3.2. Twitter analysis: scalability solutions
Real-time processing is a key requirement for Twitter sentiment analysis, and Python provides effective tools for this purpose. A Kafka pipeline is commonly used for streaming tweets, as demonstrated in the following code snippet [10]:
from kafka import KafkaConsumer
consumer = KafkaConsumer('tweets', bootstrap_servers='localhost:9092')
for msg in consumer:
sentiment = model.predict(msg.value.decode('utf-8'))
Hashtag semantics also play a vital role in Twitter sentiment analysis. For example, the hashtag "CancelCulture" is often associated with a negative sentiment cluster. The integration of BERT with emoji embeddings has shown improved performance, achieving an F1-score of 0.88 compared to 0.78 for text-only analysis [3]. The posting trends on Weibo and Twitter, which impact the data available for sentiment analysis, are illustrated in Figure 2.
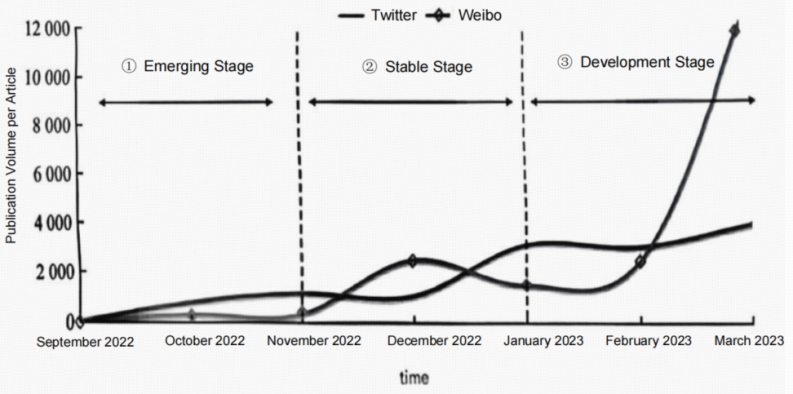
4. Challenges & trends: expanded framework
One of the major challenges in sentiment analysis is the lack of explainability in many advanced models. Specifically, attention weights in deep learning models often lack human-interpretable semantics. To address this challenge, several solution trends have emerged. Integrated Gradients, developed by Sundararajan et al., is a method that quantifies the contribution of each feature to the model’s prediction. Another approach is Local Interpretable Model-Agnostic Explanations (LIME), created by Ribeiro et al., which provides local explanations for individual predictions, making the model’s decisions more understandable.
Multilingual sentiment analysis faces significant challenges, particularly with low-resource languages. Languages such as Uyghur and Tibetan lack sufficient annotated corpora, which hinders the development of accurate sentiment analysis models. A promising trend to address this issue is zero-shot cross-lingual transfer.
Data annotation is a time-consuming and resource-intensive task in sentiment analysis. Active learning has emerged as a valuable approach to mitigate this challenge. It involves selecting informative samples for manual labeling, which helps reduce the overall labeling cost by 60% [7].
5. Conclusion
This paper synthesizes Python's pivotal role in sentiment analysis for social media texts. It demonstrates that deep learning architectures, such as RoBERTa-BiLSTM-MHA, achieve superior accuracy, with a recorded accuracy of 93.44%, by dynamically capturing contextual semantics and accounting for cross-platform sentiment disparities. Key conclusions drawn from this review include the importance of cultural nuances in sentiment analysis. Weibo discussions prioritize economic sentiment, with 78% of posts focusing on this area, while Twitter emphasizes technical ethics. This divergence requires the use of culture-specific lexicons to ensure accurate sentiment analysis .
Hybrid models that integrate attention mechanisms with transformer-based models like BERT and RoBERTa have been shown to excel in sentiment analysis. These models improve F1-scores by 6–12% compared to traditional machine learning classifiers. Furthermore, Python's NLP ecosystem, including libraries such as NLTK, spaCy, and Hugging Face, enables the scalable deployment of sentiment analysis models for applications like brand monitoring and policy feedback.
Despite the significant advancements presented in this review, there are several limitations that need to be addressed. Data annotation costs remain a major issue, as manual labeling of social media texts is still resource-intensive. An improvement to this challenge is the adoption of semi-supervised learning with tools like Snorkel. Computational overhead is another limitation, as models like RoBERTa-BiLSTM-MHA demand high GPU resources. Model distillation, using approaches such as DistilBERT, offers a way to optimize these models and reduce their computational requirements. Additionally, cross-lingual gaps persist, with non-English sentiment analysis lacking benchmark datasets. The development of multilingual transformers, such as mBERT, for low-resource languages is a potential improvement to this problem.
Future research directions in Python-based social media sentiment analysis include the integration of Explainable AI (XAI) techniques like SHAP and LIME to interpret attention weights in deep learning models. Multimodal fusion, which combines text with emojis and images for holistic sentiment inference, is another promising area. The development of ethical frameworks to address bias amplification in capital-driven sentiment analysis is also crucial. Furthermore, the deployment of lightweight models such as MobileBERT for real-time mobile applications through edge computing presents an interesting avenue for future research.
References
[1]. Zhang, E. K., Zhang, H. Z., Yao, J. C., & Wang, S. R. (2024). The dynamic evolution and dissemination structure of AIGC topics: A comparative analysis based on Weibo and Twitter. Journal of Xi'an Jiaotong University (Social Sciences), 44(3).
[2]. Batra, H., Punn, N. S., Sonbhadra, S. K., & Agarwal, S. (2021, August). Bert-based sentiment analysis: A software engineering perspective. In International Conference on Database and Expert Systems Applications (pp. 138-148). Cham: Springer International Publishing.
[3]. Pontes, E. L., & Benjannet, M. (2021, December). Contextual sentence analysis for the sentiment prediction on financial data. In 2021 IEEE International Conference on Big Data (Big Data) (pp. 4570-4577). IEEE.
[4]. Wang, L. L. (2019). Research and application of Chinese text sentiment classification based on deep learning (Doctoral dissertation, Xuzhou: China University of Mining and Technology).
[5]. Xue, T. (2021). A Python-based attention model for social sentiment analysis. Intelligent Computer and Applications.
[6]. Chaudhari, M. (2021). Sentimental emotion analysis using Python and machine learning. International Journal of Trend in Scientific Research and Development (IJTSRD), 5(4). Available online: www.ijtsrd.com. e-ISSN: 2456-6470.
[7]. Li, D. Y., Wang, Y. G., & Zhai, Q. Q. (2024). A deep learning-based method for sentiment analysis of online comments. Modeling and Simulation, 13, 5372.
[8]. Xie, R. Z., & Li, Y. (2020). A text sentiment classification model based on BERT and dual-channel attention. Journal of Data Acquisition & Processing, 35(4).
[9]. Joseph, T. (2024). Natural language processing (NLP) for sentiment analysis in social media. International Journal of Computing and Engineering, 6(2), 35-48.
[10]. Darshan, R., & Girish, A. (2023). Twitter sentiment analysis in Python. Journal of Emerging Technologies and Innovative Research (JETIR), 10(4).
Cite this article
Chen,Z. (2025). Python in Sentiment Analysis: A Review with a Focus on Social Media Text. Applied and Computational Engineering,191,46-51.
Data availability
The datasets used and/or analyzed during the current study will be available from the authors upon reasonable request.
Disclaimer/Publisher's Note
The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of EWA Publishing and/or the editor(s). EWA Publishing and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content.
About volume
Volume title: Proceedings of CONF-MLA 2025 Symposium: Intelligent Systems and Automation: AI Models, IoT, and Robotic Algorithms
© 2024 by the author(s). Licensee EWA Publishing, Oxford, UK. This article is an open access article distributed under the terms and
conditions of the Creative Commons Attribution (CC BY) license. Authors who
publish this series agree to the following terms:
1. Authors retain copyright and grant the series right of first publication with the work simultaneously licensed under a Creative Commons
Attribution License that allows others to share the work with an acknowledgment of the work's authorship and initial publication in this
series.
2. Authors are able to enter into separate, additional contractual arrangements for the non-exclusive distribution of the series's published
version of the work (e.g., post it to an institutional repository or publish it in a book), with an acknowledgment of its initial
publication in this series.
3. Authors are permitted and encouraged to post their work online (e.g., in institutional repositories or on their website) prior to and
during the submission process, as it can lead to productive exchanges, as well as earlier and greater citation of published work (See
Open access policy for details).
References
[1]. Zhang, E. K., Zhang, H. Z., Yao, J. C., & Wang, S. R. (2024). The dynamic evolution and dissemination structure of AIGC topics: A comparative analysis based on Weibo and Twitter. Journal of Xi'an Jiaotong University (Social Sciences), 44(3).
[2]. Batra, H., Punn, N. S., Sonbhadra, S. K., & Agarwal, S. (2021, August). Bert-based sentiment analysis: A software engineering perspective. In International Conference on Database and Expert Systems Applications (pp. 138-148). Cham: Springer International Publishing.
[3]. Pontes, E. L., & Benjannet, M. (2021, December). Contextual sentence analysis for the sentiment prediction on financial data. In 2021 IEEE International Conference on Big Data (Big Data) (pp. 4570-4577). IEEE.
[4]. Wang, L. L. (2019). Research and application of Chinese text sentiment classification based on deep learning (Doctoral dissertation, Xuzhou: China University of Mining and Technology).
[5]. Xue, T. (2021). A Python-based attention model for social sentiment analysis. Intelligent Computer and Applications.
[6]. Chaudhari, M. (2021). Sentimental emotion analysis using Python and machine learning. International Journal of Trend in Scientific Research and Development (IJTSRD), 5(4). Available online: www.ijtsrd.com. e-ISSN: 2456-6470.
[7]. Li, D. Y., Wang, Y. G., & Zhai, Q. Q. (2024). A deep learning-based method for sentiment analysis of online comments. Modeling and Simulation, 13, 5372.
[8]. Xie, R. Z., & Li, Y. (2020). A text sentiment classification model based on BERT and dual-channel attention. Journal of Data Acquisition & Processing, 35(4).
[9]. Joseph, T. (2024). Natural language processing (NLP) for sentiment analysis in social media. International Journal of Computing and Engineering, 6(2), 35-48.
[10]. Darshan, R., & Girish, A. (2023). Twitter sentiment analysis in Python. Journal of Emerging Technologies and Innovative Research (JETIR), 10(4).