







1. Introduction
1.1. Attacks on recommender systems
The central idea of a Content-based recommender system is to compare the information of different products to the users’ profiles. This is a very neat and specific process that leads to a relatively accurate result. Content-based recommender system recommends product to users that are very similar to what the users had previously consumed. Unlike Content-based recommender system, collaborative filtering works be analyzing the historical behavior of a certain user. If two users share similar preference on list of items they like, then most likely they will have similar interest and need for goods. Thus, in a collaborative filtering case, the connection and relationship between users and items is very important.
There are two kinds of collaborative filtering, User-based collaborative filtering, and Item-based collaborative filtering. The idea of User-based collaborative filtering is that it cross- checks for users who have interest in similar products and shares a relatively close item list. In this case, the system identifies two users with similar preference, and recommends the item on one user’s list that is not on the other user’s list to the other user. For example, we have user \( {u_{1}} \) and user \( {u_{2}} \) , if \( {u_{1}} \) have item \( {i_{1}} \) , \( {i_{2}} \) , \( {i_{3}} \) , \( {i_{4}} \) , on his list, and \( {u_{2}} \) have item \( {i_{1}} \) , \( {i_{2}} \) , , \( {i_{3}} \) , \( {i_{5}} \) , on his list, the system can identify \( {u_{1}} \) and \( {u_{2}} \) as user with similar preference since that both like \( {i_{1}} \) , \( {i_{2}} \) , Most likely, the system will recommend \( {i_{4}} \) , to \( {u_{2}} \) , and \( {i_{5}} \) to \( {u_{1}} \) . Item-based filtering considers more on the items selected by the users rather than users’ selections. Consider user \( {u_{1}} \) , \( {u_{2}} \) , and \( {u_{3}} \) purchased the item set \( \lbrace {i_{1}}, {i_{2}}, {i_{3}}\rbrace \) , \( \lbrace {i_{1}}, {i_{2}}, {i_{4}}\rbrace \) , \( \lbrace {i_{1}}, {i_{2}}, {i_{5}}\rbrace \) respectively. Then if a fourth user, \( {u_{4}} \) tend to purchase item \( {i_{1}} \) , then \( {i_{2}} \) will be recommended to the user since \( {i_{1}} \) and \( {i_{2}} \) are often purchased together, \( {i_{2}} \) might be a complement for \( {i_{1}} \) .
1.2. Attacks
Attacks on both Content-based filtering and collaborative filtering depends not only on the filtering method itself, but also on the complication of the recommender system. However, it is true that some methods of attack might work better for a certain form of filtering method. Hence, choosing the right attack method can be more efficient when organizing an attack to the recommender system. This paper will introduce some of the commonly seen attacking methods in brief.
1.2.1. Random Attack. Random attack, as the name indicates, it assigns filler items according to a probability distribution that is distributed around the global average of all ratings for all items. They are drawn from the same probability distribution, and chosen randomly from the database, not dependent on the target item. The rating of the target item is either set to the maximum possible rating value \( {R_{max}} \) or the minimum possible rating value \( {R_{min}} \) , which depends on whether it is a push attack or a nuke attack.
1.2.2. Average Attack. Average attack has high similarity to the random attack in terms of how the filler items are been selected, but they are different in how the filler items are assigned. When assigning the filler items, this attack usually assigns ones that are specified or approximate average for the specific item. Hence, a greater amount of knowledge is needed to average attack, it is not process efficient.
1.2.3. Bandwagon Attack. Bandwagon attack leverages a relatively small quantity of items, which are very popular in terms of the number of ratings they receive. The ratings can be both positive and negative, as long as the rated item has a large number of ratings, which depends on whether it is a bandwagon attack or a reverse bandwagon attack. The ratings for those positive popular items are set to maximum possible rating \( {R_{max}} \) , while other filler items are rated randomly. The target item can be set to either \( {R_{max}} \) or \( {R_{min}} \) depending on the nature of the attack.
1.2.4. Popular Attack. Similar to the bandwagon attack, a popular attack also uses popular items to create filler items. Popular attack itself can both consider positive and negative ratings. When the average of the filler item in the rating matrix is less than the global rating average, then the rating of the item will be set to minimum possible rating \( {R_{min}} \) However, if the filler item in the rating matrix is greater than the global rating average of all times, then the rating of the item will be set to \( {R_{min}}+1 \) . The target item will always set to maximum possible rating \( {R_{max}} \) in the fake user’s profile.
1.2.5. Love/Hate Attack. Unlike other attacks that consider both push and nuke attack, love/hate attack is only designed to be a nuke attack. The advantage of this form of attack is that it only requires a very little mount of knowledge to raise this attack. Since this is a nuke attack, the probability of the nuked item is set to minimum possible rating \( {R_{min}} \) , while other items are all set to maximum possible rating \( {R_{max}} \) .
1.2.6. Probe Attack. The probe attack takes more real ratings of an item directly from a user-based recommendation system and use those values during an attack. Something different from all other attacks is that the attacker has to create a seed profile before the attack. Predictions are made by generating items that had appeared by user-neighbors of the seed profile. Again, the rating of the target item can be set to both \( {R_{max}} \) or \( {R_{min}} \) depending on the nature of the attack been raised.
1.2.7. Segment Attack. Segment attack is also known as the favorite item attack, this form of attack works better for an item- based collaborative filtering system. Segment attacks usually change the peer items by using the fake profiles they had generated. It is called segment attack because it can identify the segment of the given item and choose the item that is most correlated to the given item. The selected item is then set to \( {R_{max}} \) . Note that the rating of the filler items is set to minimum possible value \( {R_{min}} \) . Because of the nature of the attack, segment attack is only restricted to a specific group of users.
2. Sentiment Analysis
2.1. Introduction
In the information age, people can speak freely on the Internet and evaluate the goods they buy and the places they visit. These reviews also provide judgment value to new users, and can provide businesses with ways to improve their services.
Sentiment analysis used to be done by a large labor force reading and manually evaluating texts. This approach is costly and prone to human error. To automate the process, the company sought advanced analytical methods to solve the problem.
2.2. Analytical method
The process of sentiment analysis can be understood in this way.
Extract the text from the comments to get sentences and phrases. Then we categorize these sentences and phrases into emotional categories, and we get sentences and phrases with emotion. Then extract their aspects labels, and finally get the final result by aggregating and summarizing [1].
There are three commonly used methods of sentiment analysis: Sentiment Lexicons, Machine learning in natural language processing, Deep learning.
2.2.1. Sentiment Lexicons. When it comes to sentiment analysis, a good sentiment lexicon can make our work more effective with less effort. Sentiment Lexicons generally include: emotion words and degree words. Users use emotional words to express their attitudes, such as: like, hate, etc.; And users use degree words to express strength, such as: very, average and so on.
Here are some of the more popular and mature sources of open sentiment lexicons: GI (The General Inquirer), LIWC (Linguistic Inquiry and Word Count), SentiWordNet etc.
2.2.2. Machine learning in natural language processing. During the training, both text and emotional labels are fed into machine-learning algorithms to create models that can predict new text. It is also to reduce the loss value as much as possible, so that the model can predict the results more accurately.
The process is roughly as follows: first, feature X is input into the prediction function (model) and the corresponding prediction label is calculated; Secondly, the difference is calculated by loss function, namely loss value. The smaller the loss value, the better the model effect and the more accurate the prediction. Then the parameter is updated by the loss value. Finally, the process is repeated until the loss drops to an ideal level.
It is worth mentioning that supervised machine learning requires labeling of data, so any subjectivity and bias in the data will be reflected in the model.
Custom models give you better control over the output than pre-trained models and are suitable for specific applications.
Naive Bayes is one of the commonly used methods. In Naive Bayes, we calculate the emotional value of each word. Then the emotional value of the sentence will be calculated by the frequency of the word and the positive and negative values of the word, and the sentence will be judged to be positive, negative or neutral.
2.3. Deep Learning
Deep learning allows data to be processed in more complex ways. Long-short term memory model (LSTM) is a recursive neural network for processing temporal data.
Recursive neural network (RNN) is a class of artificial neural networks in which the connections between nodes form a directed graph along a time series. This allows it to exhibit time-dynamic behavior. The primary function of RNN is to process sequential information based on internal memory captured by a directed loop. Humans don't always start their thinking with a blank brain. As you read this article, you are inferring the true meaning of the current word based on the understanding you already have of the words you have seen before. We don't throw everything away and think with a blank mind. Our thoughts have permanence.
Traditional neural networks can't do this, which seems like a huge drawback. The cyclic neural network (RNN) solves this problem.
Sentiment analysis was carried out by using the comment statement section of Sports and Outdoors in Amazon data set.
2.4. Problem statement
Sentiment analysis was carried out by using the comment statement section of Sports and Outdoors in Amazon Review Data (2018).
2.5. Dataset
Amazon's public Sports and Outdoors data set, which includes tags such as user name, review, and the time when the review was posted. Each comment is a user's real evaluation and emotional level of the sports and outdoors platform. This is a large amount of data, and in this paper, we will use 2,000 of these comments for sentiment analysis.
2.6. Implementation
The data set contains attributes such as reviewTime, reviewerName, and reviewText, so we need to split the data set and only keep the reviewText part (figure 1).

Figure 1. Partial reviews in Sports and Outdoors in Amazon Review Data (2018)
We will use TextBlob to implement sentiment analysis. Split the sentence into a set of words, go through all the words in all the corpus, delete the stops. Calculate the score of the sentence according to the sentiment lexicon (figure 2).

Figure 2. Some reviews and their scores in Sports and Outdoors in Amazon Review Data (2018)
Finally, through calculation, we can see that the average evaluation score is 0.3915, and the evaluation of this sports and outdoors application is average. It could also be that the review sample was not large enough.
2.7. Challenges in Sentiment Analysis
The development of sentiment analysis is very rapid, but it also has some limitations. Some abbreviations, Internet language, can make judgment difficult. Some ironic lines, such as in Perfumes: In the Guide, "If you are reading this because it is your darling fragrance, please wear it at home exclusively, and tape the windows shut. " Sentences like this can make sentiment analysis difficult. Another challenge for natural language processing is that some comments need to infer whether the emotion expressed is positive, negative, or neutral based on the context [1].
Cultural differences can also make sentiment analysis difficult. For example, what is an expression of kindness in one culture is an expression of rude in another.
3. Evaluating Recommender System
To improve both the economic benefits and the accuracy of the recommendation system, evaluation is required. Via three methods—User Research, Online Evaluation, and Offline Evaluation with Historical Data Sets—recommendation system evaluation seeks to learn how to efficiently recommend products to users.
3.1. User Studies
To comprehend how users and recommender systems interact, we can conduct user studies. Users offer input throughout this process. For instance, people frequently place a high value on a recommendation system’s findings being innovative. If a user enjoys burgers, the recommender system ought to suggest pizza instead of only burgers or other products that are comparable to burgers. The experience of the user is frequently greatly impacted by novelty. We allow two people who are similar to each other to share their preferences in the recommender system. For instance, if one person enjoys watching movies and playing eSports, and the other person enjoys watching movies. Yet we already know that when it comes to choosing things, these two people have remarkably similar preferences. After then, we can suggest eSports to the other person. The recommender system’s diversity, which should recommend comparable products with various characteristics, is increasingly crucial. For instance, if we wish to suggest history books to users, we must provide several histories authored by various authors. As a more realistic evaluation tool, user studies frequently include multiple user biases, such as the impact of various experiences on people’s judgment.
3.2. Online Evaluation
The system’s stability and robustness are given greater attention during the online evaluation than user studies. In general, we categorize the users into groups. We give various groups the opportunity to use various suggestion methods before obtaining their comments. We can compare the advantages they provide to the economy more directly. Another crucial factor is the recommender system’s scalability, which includes Training time, Prediction time, and Memory requirements.
3.3. Offline Evaluation with Historical Data Sets
Offline Evaluation with Historical Data Sets is closer to the analysis of big data than the first two approaches. We can intercept a small matrix in a large matrix of historical data.
\( {A_{whole}}=(\begin{matrix}\begin{matrix}{a_{11}} & {a_{12}} \\ \end{matrix} & \begin{matrix}{a_{13}} & {a_{14}} \\ \end{matrix} & \begin{matrix}{a_{15}} & {a_{16}} & {a_{17}} \\ \end{matrix} \\ \begin{matrix}\begin{matrix}{a_{21}} & {a_{22}} \\ \end{matrix} \\ \begin{matrix}{a_{31}} & {a_{32}} \\ \end{matrix} \\ \begin{matrix}{a_{41}} & {a_{42}} \\ \end{matrix} \\ \end{matrix} & \begin{matrix}\begin{matrix}{a_{23}} & {a_{24}} \\ \end{matrix} \\ \begin{matrix}{a_{33}} & {a_{34}} \\ \end{matrix} \\ \begin{matrix}{a_{43}} & {a_{44}} \\ \end{matrix} \\ \end{matrix} & \begin{matrix}\begin{matrix}{a_{25}} & {a_{26}} & {a_{27}} \\ \end{matrix} \\ \begin{matrix}{a_{35}} & {a_{36}} & {a_{37}} \\ \end{matrix} \\ \begin{matrix}{a_{45}} & {a_{46}} & {a_{47}} \\ \end{matrix} \\ \end{matrix} \\ \begin{matrix}\begin{matrix}{a_{51}} & {a_{52}} \\ \end{matrix} \\ \begin{matrix}{a_{61}} & {a_{62}} \\ \end{matrix} \\ \begin{matrix}{a_{71}} & {a_{72}} \\ \end{matrix} \\ \end{matrix} & \begin{matrix}\begin{matrix}{a_{53}} & {a_{54}} \\ \end{matrix} \\ \begin{matrix}{a_{63}} & {a_{64}} \\ \end{matrix} \\ \begin{matrix}{a_{73}} & {a_{74}} \\ \end{matrix} \\ \end{matrix} & \begin{matrix}\begin{matrix}{a_{55}} & {a_{56}} & {a_{57}} \\ \end{matrix} \\ \begin{matrix}{a_{65}} & {a_{66}} & {a_{67}} \\ \end{matrix} \\ \begin{matrix}{a_{75}} & {a_{76}} & {a_{77}} \\ \end{matrix} \\ \end{matrix} \\ \end{matrix}) \) \( {A_{test}}=(\begin{matrix}{a_{11}} & {a_{12}} & {a_{13}} \\ {a_{21}} & {a_{22}} & {a_{23}} \\ {a_{31}} & {a_{32}} & {a_{33}} \\ \end{matrix}) \) (1)
We can Use the dataset (Atest) to find the Prediction Accuracy in order to know the accuracy of a recommender system. We have three main approaches including MAE, MSE and RMSE.
• MAE (Mean Absolute Error)
\( MAE=\frac{1}{|Q|}\sum _{(u,i)∈Q}|{r_{ui}}-{\hat{r}_{ui}}| \) (2)
One of disadvantage of the MAE is that it does not take consideration for the direction of error [2-3]. The direction of error is important in the realistic evaluation process.
• MSE (Mean Square Error)
Using the MSE to evaluate the error can enlarge the penalty, which make the error prediction be too large to predict in correct way [2].
 RMSE (Root Mean Square Error)
RMSE (Root Mean Square Error)
Overall, RMSE is the best way to measure the prediction accuracy of recommender system [2].
Despite from predicting the error, we also need to consider the efficiency of recommendation system. Most of the time, the users only pay attention to the top n items in the recommender system list. In this case, we can use precision, recall, and F-Measure to know the effectiveness of the recommender system [2].
\( Precision=\frac{{N_{rs}}}{{N_{s}}} \) or \( Precision@n=\frac{{N_{rs@}}n}{n} \) (5)
\( Recall=\frac{{N_{rs}}}{{N_{r}}} \) (6)
\( F-Measure=\frac{2×Precision×Recall}{Precision+Recall} \) (7)
\( {N_{rs}} \) : the number of items in the recommendation list the users prefer
\( {N_{s}} \) : the total number of items in the recommendation list
\( n \) : the first n recommended items
\( {N_{r}} \) : the number of items the user prefer
We use the formula to calculate the top items.
We can evaluate the accuracy by the Receiver Operating Characteristic Curve in the evaluation process (figure 3).
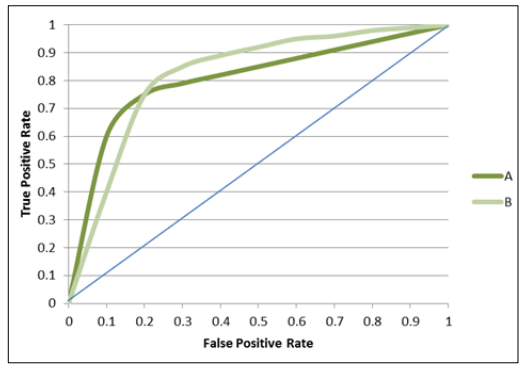
Figure 3. ROC curve [2]
We can assume that the whole area is 1, we need to know how many percentages the AUC occupies:
·AUC = 1 (Perfect recommendation prediction
·0.5 < AUC < 1 (There is a somewhat relationship)
·AUC = 0.5 (Randomly, no worth)
·AUC < 0.5 (Randomly or predict in a negative direction)
3.4. Long Tail Problem
As shown in figure 4, there are many items in the long tail that are not considered as low ratings or negative comments, but the item in the long tail is a low frequency of appearing in the user’s eyes.
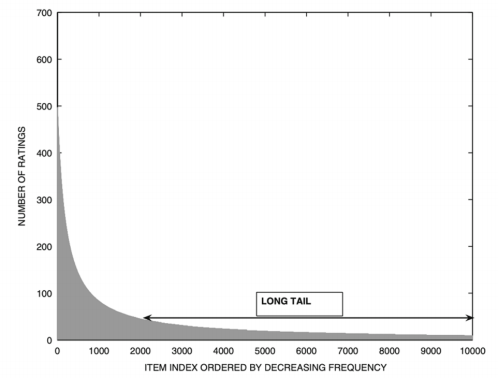
Figure 4. Ratings of items in the long tail
Increasing the randomness of the recommender system is necessary. Fixing the long tail effect helps many big companies gain many benefits, and people like the unique and special things. Meanwhile, the items in long tail provide more opportunities for exploring and discover [4-5].
4. Hybrid Recommender System
4.1. Introduction
In the field of recommender systems, existing algorithms often face limitations due to the strengths and weaknesses of their data sources. This can result in less effective recommendations for users. However, hybrid recommender systems offer a solution by exploring the possibilities of combining different methods to make inferences more powerful.
It is important to recognize that data sources used by existing algorithms often have limitations. For instance, some sources may provide more accurate data but be limited in scope, while others may have broader coverage but less accuracy. These limitations can impact the effectiveness of recommendations made by these algorithms, making it challenging to provide the best solution for users.
4.2. Method
In the context of ensemble recommender systems, the weighted approach involves the combination of scores from several individual components into a single unified score. This is achieved by computing the weighted aggregates of the scores from each individual component. The methodology for weighting the components may involve heuristic techniques or formal statistical models, depending on the specific application and data characteristics.
The weighted aggregation can be performed using various techniques, such as weighted average, weighted sum, or weighted product. The choice of aggregation method depends on the specific application and the nature of the data.
The weights assigned to each individual system can be determined using various techniques, including heuristic methods or formal statistical models. For instance, the weights can be assigned based on the performance of each individual system on a validation dataset, or they can be determined using optimization techniques that maximize the accuracy of the weighted ensemble method.
The resulting recommendations from the weighted ensemble method are expected to be more accurate and effective than those generated by any individual recommender system alone, as the ensemble method leverages the strengths of multiple systems and compensates for their weaknesses. In addition, the weighted ensemble method can adapt to changes in the data or user preferences over time, by updating the weights of the individual systems accordingly.
4.3. Problem
The outbreak of COVID-19 has had a devastating impact on individuals and communities worldwide. In addition to the physical health implications, the pandemic has caused a wide range of problems such as depression, anxiety, and reduced access to healthcare. As a result, there is an urgent need to design an effective model to recommend the best treatment for COVID-19. This essay aims to explore the potential needs of application users on COVID-19 related problems and design personalized solutions based on the backgrounds of users.
The first step in designing an effective model is to understand the potential needs of application users on COVID-19 related problems. Users might search for information on COVID-19 related issues such as symptoms, prevention, and treatment options. They might also search for information related to their psychological well being, such as mental health support or self-help techniques to manage anxiety and depression. Understanding user needs and search behaviors is essential to build a useful model that can offer personalized solutions.
The second step is to analyze the effective advice and treatment options for people who need help with COVID-19-related problems. This analysis should consider both medical and non- medical interventions, including psychological support and access to healthcare. Additionally, the model should account for the diverse backgrounds of users, such as age, gender, ethnicity, and socio-economic status, as these factors can impact the effectiveness of different interventions.
The third step is to build a hybrid model that can analyze user search behaviors and offer personalized solutions based on their backgrounds. This model should leverage machine learning and natural language processing techniques to identify user needs and offer relevant and timely solutions. For instance, if a user searches for COVID-19-related symptoms and reports feelings of anxiety, the model might suggest mindfulness techniques or online counseling resources that cater to their needs.
In conclusion, the design of an effective model to recommend the best treatment for COVID-19 should consider the diverse needs of users and account for their backgrounds. By leveraging machine learning and natural language processing techniques, such a model can offer personalized solutions and help individuals navigate the challenges brought by the pandemic. Furthermore, evaluating user acceptance of recommended treatments is critical to ensure that the model addresses the real needs of users.
4.4. Dataset
Data preprocessing is an essential step in data analysis, which involves various techniques to transform raw data into a format that is suitable for further analysis. In this context, several techniques are typically applied to preprocess the data.
Data selection involves importing all files and attributes that are relevant to the analysis. This step typically involves parsing the data and selecting the relevant attributes, which are separated by commas and double colons.
Data cleansing is another critical step in data preprocessing, which aims to identify and correct errors or inconsistencies in the data. This step involves identifying missing values and replacing them with appropriate values to ensure that the data is complete and accurate. In the specific case mentioned, the missing values are replaced with zero values, which are subsequently replaced by the rating predicted values.
Finally, data splitting is an essential step in data preprocessing, which involves dividing the dataset into two parts: a training dataset and a testing dataset. The training dataset is used to develop the model, while the testing dataset is used to evaluate the performance of the model. In the specific case mentioned, the dataset is split into 80% training data and 20% testing data, with three random splits.
5. Conclusion
Among all methods of attacks introduced above, popular attack is regarded as most efficient when there is full source of knowledge. But if there is only limited source of knowledge, then probe attack can be more efficient when attacking the same recommender system. Again, the efficiency of the attack depends on the recommender system’s algorithm, conclusions can only be given relatively without actual algorithm given for a certain recommender system.
In this paper, we conduct sentiment analysis on some comments in Sports and Outdoors in Amazon Review Data, so that we can find some problems and give some suggestions to businesses. When used properly, sentiment analysis can provide great value to any organization. The technology of sentiment analysis is becoming more and more mature, and it is also continuously improving to improve accuracy. The evaluating system is considerably important for the updating recommender system, and also it can bring more benefit for companies and users.
Hybrid recommender systems can overcome the limitations of individual algorithms by combining different methods to make inferences more powerful. The use of weighted ensemble methods can result in more accurate and effective recommendations by leveraging the strengths of multiple systems and compensating for their weaknesses. Applying these techniques to design an effective model to recommend the best treatment for COVID-19 requires understanding user needs and search behaviors, analyzing effective advice and treatment options, and building a hybrid model that can offer personalized solutions based on user backgrounds. Data preprocessing is also crucial in preparing the dataset for further analysis, including data selection, data cleansing, and data splitting. The design of an effective model can offer personalized solutions to help individuals navigate the challenges brought by the pandemic, and evaluating user acceptance of recommended treatments is critical to ensure that the model addresses the real needs of users.
References
[1]. Katrekar, A., & Analytics, B. D.. An Introduction to Sentiment Analysis.
[2]. Chen, M., & Liu, P. (2017). Performance evaluation of recommender systems. International Journal of Performability Engineering, 13(8), 1246.
[3]. Chojnacki, S., & Kłopotek, Mieczysław. (2010). Random graphs for performance evaluation of recommender systems. Control & Cybernetics.
[4]. Celma, O. (2010). Music recommendation and discovery: The long tail, long fail, and long play in the digital music space. Springer Science & Business Media.
[5]. Herrada, B. C., & Oscar. (2008). Music recommendation and discovery in the long tail. Ceedings of International Congress on Electron Microscopy Methods Enzymol, 11(1), 7-8.
Cite this article
Xu,Y.;Mi,J.;Li,S. (2024). The analysis of recommender systems: Attacks, sentiment analysis, evaluation and hybrid methods. Applied and Computational Engineering,30,163-172.
Data availability
The datasets used and/or analyzed during the current study will be available from the authors upon reasonable request.
Disclaimer/Publisher's Note
The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of EWA Publishing and/or the editor(s). EWA Publishing and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content.
About volume
Volume title: Proceedings of the 2023 International Conference on Machine Learning and Automation
© 2024 by the author(s). Licensee EWA Publishing, Oxford, UK. This article is an open access article distributed under the terms and
conditions of the Creative Commons Attribution (CC BY) license. Authors who
publish this series agree to the following terms:
1. Authors retain copyright and grant the series right of first publication with the work simultaneously licensed under a Creative Commons
Attribution License that allows others to share the work with an acknowledgment of the work's authorship and initial publication in this
series.
2. Authors are able to enter into separate, additional contractual arrangements for the non-exclusive distribution of the series's published
version of the work (e.g., post it to an institutional repository or publish it in a book), with an acknowledgment of its initial
publication in this series.
3. Authors are permitted and encouraged to post their work online (e.g., in institutional repositories or on their website) prior to and
during the submission process, as it can lead to productive exchanges, as well as earlier and greater citation of published work (See
Open access policy for details).
References
[1]. Katrekar, A., & Analytics, B. D.. An Introduction to Sentiment Analysis.
[2]. Chen, M., & Liu, P. (2017). Performance evaluation of recommender systems. International Journal of Performability Engineering, 13(8), 1246.
[3]. Chojnacki, S., & Kłopotek, Mieczysław. (2010). Random graphs for performance evaluation of recommender systems. Control & Cybernetics.
[4]. Celma, O. (2010). Music recommendation and discovery: The long tail, long fail, and long play in the digital music space. Springer Science & Business Media.
[5]. Herrada, B. C., & Oscar. (2008). Music recommendation and discovery in the long tail. Ceedings of International Congress on Electron Microscopy Methods Enzymol, 11(1), 7-8.