







1. Introduction
The prediction of stock prices plays a crucial role in providing investors and financial institutions with a clearer understanding of potential market movements and investment opportunities. Accurate predictions can help these entities make informed decisions, manage risks, and optimize their portfolios. Eugene Fama developed the Efficient Market Hypothesis, which holds that financial markets efficiently absorb all available information into stock prices, making it difficult to continuously outperform the market using predictive tactics [1]. Similarly, Burton Malkiel's Random Walk Theory contends that stock values follow a random and unpredictable path, implying that they cannot be easily forecasted [2]. However, there are some opponents proposing that the persistent biases exist, which means the Efficient Market Hypothesis would not always be valid. People will hardly achieve the alpha returns if the Efficient Market Hypothesis holds true. In real life, some stocks are outperforming others, which suggests that investors are able to seek some strategies as a result of greater yields [3]. There are numerous factors that influence stock prices, including market news and events, company financial performance, and investor sentiments [4]. The interplay of these elements makes analyzing stock price trends a significant challenge for investors. As a result, investors and financial analysts continuously seek different methods and approaches to uncover insights that might offer a competitive edge in the market. This quest for predictive models and techniques underscores the complexity and uncertainty inherent in financial markets, as well as the ongoing efforts to better understand and navigate them [5].
Machine learning has emerged as an effective tool capable of detecting patterns and extracting valuable information from datasets. Recent advancements in tree-based models, particularly gradient boosting, have demonstrated superior performance and are widely used by data scientists in competitive scenarios. Enhancing ML, the modern trend of deep learning introduces deep nonlinear topologies, making it exceptionally effective in analyzing financial time series. Recurrent neural networks, a step beyond simple artificial neural networks, excel in financial predictions by retaining memory of recent events, which is crucial for accurate forecasting. Long short-term memory networks address RNN limitations with specialized gates, effectively handling both single data points and sequences for improved predictive performance in economic contexts. Kelotra and Pandey, for example, used a deep convolutional LSTM model to analyze stock market movements and trained it using a Rider-based monarch butterfly optimization technique, resulting in low mean squared error values [6].
This study will look into the use of AI models, specifically the LSTM, Transformer, and XGBoost architectures, in predicting stock values. The study aims to assess the effectiveness of these models in projecting stock prices by comparing their predictive ability to benchmark financial datasets.
2. Descriptions of AI Techniques
Since the 1990s, Computational Finance has made remarkable progress with the integration of computational methods into financial analysis. The emphasis has shifted progressively toward using artificial intelligence to improve stock market investment techniques. AI significantly improves the investment process by eliminating emotional biases and irrational decision-making, uncovering complex patterns that may be overlooked by human analysts, and enabling real-time data processing. These advancements streamline financial decision-making and provide more accurate, timely insights, thereby revolutionizing investment management and analysis [7].
Stock market prediction approaches are often divided into two categories: prediction-based techniques and clustering-based techniques. In contrast, clustering-based methods include filtering, fuzzy logic, k-means clustering, and optimization algorithms [4]. The prediction process typically involves several steps, starting with the preprocessing of stock data to eliminate noise and irrelevant features. This is achieved through attribute relevance analysis, which refines the data by focusing on key variables that impact stock trends. The cleaned and relevant data is then used to identify significant features for predicting future stock movements. This information is categorized into prediction details and current status, which are subsequently processed by a decision-making system to evaluate potential profit or loss. Based on these assessments, alerts are generated: profits might prompt recommendations for increasing sales, while losses trigger further analysis and necessary adjustments to the investment strategy.
By adding advanced AI and machine learning techniques into financial analysis, investors can obtain a better grasp of market dynamics, increase prediction accuracy, and make more informed decisions. This trend highlights the growing importance of computational approaches in modern finance, as well as their ability to drive investment practice innovation and efficiency.
3. AI Models
This study will explore the application of three distinct models for predicting stock prices: Long Short-Term Memory, Transformer, and Extreme Gradient Boosting. Each model offers unique strengths and methodologies for handling financial data.
3.1. LSTM Models
LSTM is an advanced RNN architecture designed for time series prediction. It excels in handling both classification and regression tasks due to its ability to preserve information over time. The LSTM architecture includes an input layer, hidden layers, a cell state, and an output layer. The cell state is crucial for maintaining long-term dependencies, while the network features input, output, and forget gates that regulate the flow of information. The forget gate determines whether to retain or discard previous state information, allowing LSTMs to overcome the limitations of standard RNNs and effectively analyze time-series patterns. In this study, an LSTM model is utilized to predict stock prices for the S&P 500 index. Fig. 1 shows the schematic diagram of the proposed research framework [8]. The data preparation phase involves several steps: splitting the dataset into training and test sets, normalizing the features, and reshaping the data to meet the model's input requirements. The LSTM architecture is constructed by defining input sequences, adding LSTM layers, and incorporating a final dense layer for output prediction.
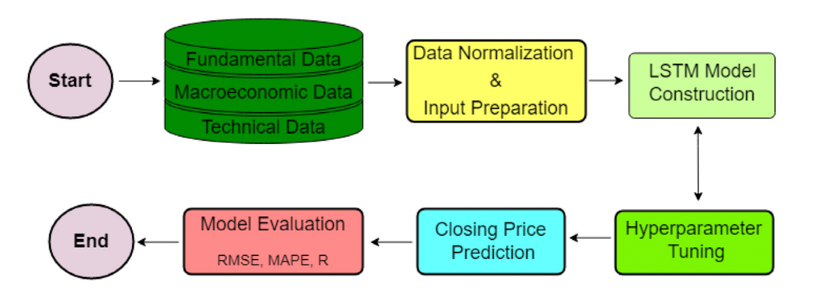
Figure 1: The LSTM architecture [8].
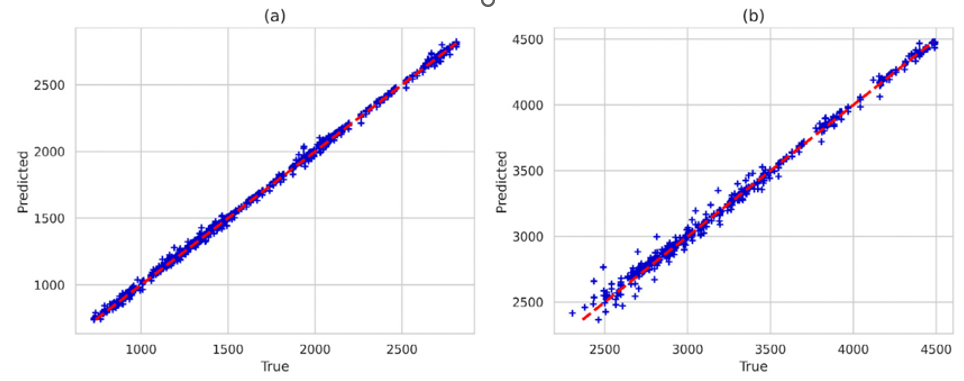
Figure 2: Scatter plot of actual and predicted price on (a) training data and (b) test data [8].
The dataset spans a 15-year period (2006-2020) and includes fundamental trading data, macroeconomic variables, and technical indicators. Fundamental data, such as open and close prices, is sourced from Yahoo Finance. Fig. 2 presents a scatter plot comparing actual closing prices with predicted prices generated by the best single-layer LSTM model for both the training and test datasets. The graphic shows the model's ability to capture the link between input features and the target variable. In the scatter plot, the predicted values are plotted against the true values. A high degree of alignment indicates the model's accuracy. For the training dataset, the predicted values closely match the actual closing prices, demonstrating the model's capability to learn from historical data. This close alignment suggests effective pattern recognition in the training data. Similarly, the test dataset demonstrates a significant connection between predicted and actual values, with only minor deviations. This indicates that the model generalizes well to unseen data, making it reliable for future stock price predictions. Overall, the proximity of predicted values to true values in both datasets reflects the robustness and precision of the LSTM model [8, 9].
3.2. Transformer Models
The Transformer model has two basic components: the encoder and the decoder. The encoder applies dot-product attention to the input sequence, successfully capturing complicated linkages and dependencies while conserving the sequence's length. It creates contextually rich representations by balancing the value of various aspects of the incoming data. The decoder then constructs the output sequence by applying dot-product attention to both the encoded input and the current output sequence, beginning with a placeholder. This configuration allows the decoder to construct a forecast sequence of the appropriate length directly, based on encoded information and the context of previously produced pieces [10]. Fig. 3 depicts the Transfomer's architecture [11]. The Transformer model uses positional encoding to properly manage non-sequential historical data. This technique gives vital context on each token's relative location in reference to the current timestamp, allowing the self-attention mechanism to appropriately assess the relevance of various tokens. Each location is encoded with a unique real number to ensure that no two positions are the same, preserving the sequence's order. The Transformer's attention mechanism computes attention weights by taking the dot product of vectors, determining how each token affects others. When the input is represented by one-dimensional vectors, such as stock closing prices, the model uses a linear layer to expand it to a higher-dimensional space. This expansion converts the decoder output to a more informative one-dimensional sequence.
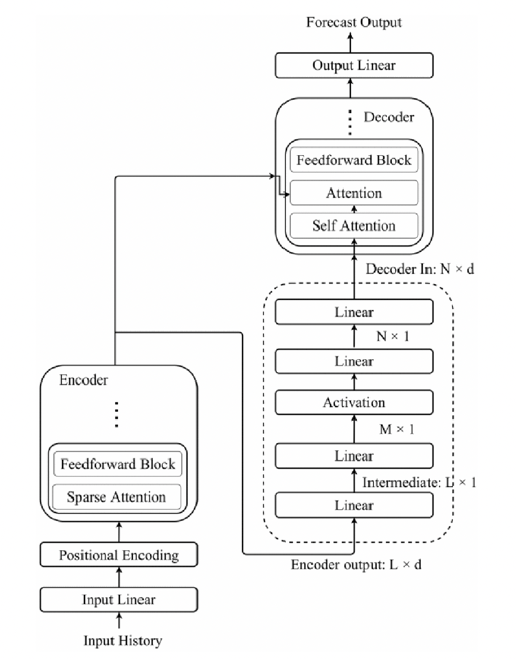
Figure 3: The Transformer architecture [11].
The encoder is made up of multiple-head self-attention mechanisms and a feedforward neural network, which allows it to process and modify input data thoroughly. Meanwhile, the decoder consists of multiple layers, each of which performs self-attention on the decoder's output as well as attention between the decoder's output and the encoder's processed sequence. This tiered method ensures that the decoder can make accurate predictions based on the encoder's enhanced information. This study investigated the use of a Transformer-based model for predicting the next day's closing price. It employed three benchmark datasets: Yahoo Finance, Facebook Finance, and JPMorgan Finance, spanning from January 1, 2017, to September 17, 2023. These datasets, which were devoid of identical or missing values, were divided into training and test sets. Fig. 4 illustrates the preciseness of the Transformer predictions in relation to the actual pricing for Facebook and JP Morgan [11].
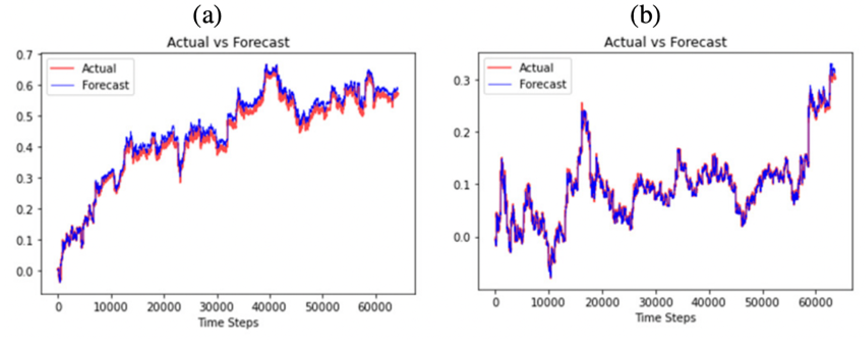
Figure 4: Transformer forecasting on (a) Facebook and (b) JP Morgan [11].
3.3. XGBoost Models
Extreme Gradient Boosting (XGBoost) has emerged as a leading machine learning technique due to its exceptional performance across a variety of data sets. Introduced in 2014 by Tianqi Chen, XGBoost is renowned for its effectiveness in tasks such as stock market prediction. This technique enhances the performance of weak classifiers (WC) by iteratively transforming them into stronger classifiers (SC). The process of boosting involves leveraging gradient descent to refine and improve the predictive power of ensemble models composed of Classification and Regression Trees (CART). The essence of XGBoost lies in its ability to continuously build upon existing models, correcting errors and minimizing loss with each iteration. In this approach, each decision tree acts like a judge, with multiple trees working together to vote on the most likely outcome. This ensemble method significantly boosts predictive accuracy compared to a single decision tree, which typically starts from a root node and branches out into various outcomes based on feature tests.
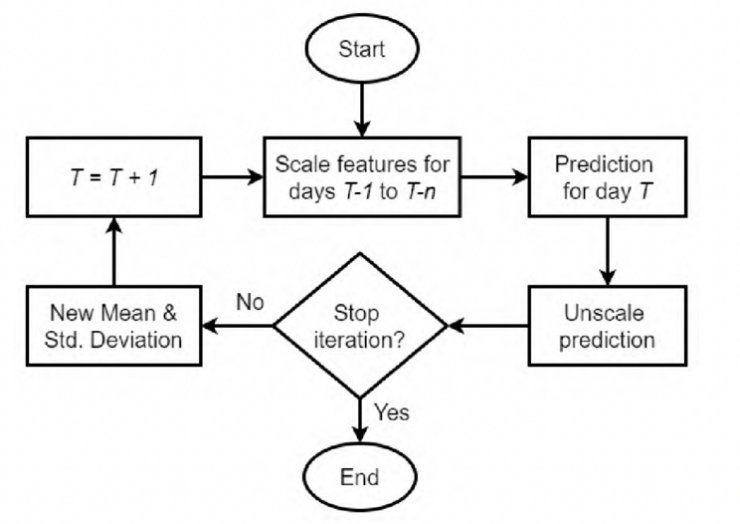
Figure 5: XGBoost’s architecture [12].
XGBoost's architecture as shown in Fig. 5 integrates gradient boosting with several key enhancements to maximize computational efficiency and performance. These include advanced regularization techniques, efficient handling of sparse data, and support for parallel processing. This combination of features enables XGBoost to push the boundaries of traditional boosting algorithms, making it a preferred choice for a wide range of applications. The ability to leverage computational resources effectively while continuously refining predictions underscores XGBoost's status as a powerful and sought-after algorithm in the field of machine learning [12].
4. Limitations
The application of machine learning models, particularly Transformer and Long Short-Term Memory networks, in predicting financial markets has seen significant growth due to their advanced capabilities in analyzing complex data patterns. These models offer sophisticated approaches to studying financial time series and making forecasts that could enhance investment strategies. However, despite their considerable benefits, these models face several limitations that present challenges within the financial domain.
The Transformer model is highly valued for its ability to capture and process long-term dependencies and relationships within sequential data. Its self-attention mechanism allows it to efficiently evaluate and interpret complex sequences by considering the importance of different elements within the data. This makes Transformer particularly adept at handling large and intricate datasets where long-range relationships are crucial. Nevertheless, its effectiveness depends on the availability of substantial training data, which can be a major challenge in the financial sector, where high-quality datasets are often limited. Additionally, the sophisticated architecture of Transformer results in lower interpretability compared to more straightforward models. In financial contexts, where transparency is essential for validating and trusting model predictions, this lack of clarity can pose significant problems for decision-making and regulatory compliance.
LSTM networks address some of the challenges associated with traditional recurrent neural networks (RNNs) by incorporating mechanisms designed to manage and retain information over long sequences. This makes LSTM particularly effective for sequential data such as time series, where maintaining historical context is critical for accurate forecasting. LSTM models have demonstrated their effectiveness in various financial forecasting tasks, including predicting stock prices and analyzing market trends. Despite their strengths, LSTM networks encounter limitations, particularly when dealing with long-term dependencies and datasets characterized by irregular or sparse time series data. Financial datasets frequently exhibit gaps, uneven intervals, and missing values, which can complicate the training process and impact model performance. Although LSTM is better suited for sequential data compared to traditional RNNs, it still faces difficulties in capturing very long-term dependencies, which can constrain its effectiveness in certain financial forecasting scenarios [11]. XGBoost is well-known for its ability to increase predicted accuracy by iteratively strengthening weak classifiers. However, the technique necessitates precise hyperparameter adjustment and can become computationally intensive when dealing with huge datasets. Furthermore, while XGBoost excels in many situations, it may not always capture complex temporal patterns as effectively as deep learning models such as LSTM and Transformer.
The limitations connected with these machine learning models highlight the importance of continual research and innovation to improve their robustness and usefulness in financial forecasting. Future developments should focus on creating new procedures and improving existing techniques to better meet the unique aspects of financial data. Improving model interpretability, for example, using approaches like explainable AI (XAI), could increase transparency and trust in model predictions. Furthermore, investigating hybrid models that combine the capabilities of various methodologies or including external market aspects may result in more accurate and comprehensive forecasting solutions. Future research should also focus on improving the resilience of these models and investigating novel ways to forecast accuracy. Integrating new data sources, such as macroeconomic indicators, geopolitical events, and different data types, may provide a more complete picture of market dynamics and improve forecasting performance. Researchers could look into ways to better handle missing numbers and outliers, as well as tactics for managing the unstructured character of financial data. By tackling these limits and exploring new approaches, the area of financial forecasting can progress, resulting in more reliable and effective AI-driven tactics for navigating the complex and changing terrain of financial markets.
5. Conclusion
In conclusion, this study demonstrates the effectiveness of advanced AI models (i.e., LSTM, Transformer, and XGBoost) in predicting stock prices. LSTM networks excel in capturing temporal dependencies and managing sequential data, proving valuable for financial forecasting. The Transformer model's ability to handle non-sequential data and enhance forecasting precision highlights its potential in overcoming limitations of traditional models. XGBoost's iterative boosting process further improves predictive accuracy, showcasing its robustness in handling diverse datasets. Despite their strengths, these models face limitations, such as the need for substantial training data and challenges in handling irregular time series data. Future research should focus on improving model interpretability, integrating additional data sources, and developing hybrid approaches to enhance forecasting accuracy. By addressing these challenges and exploring innovative methodologies, the field of financial forecasting can advance, leading to more effective AI-driven strategies for navigating the complexities of financial markets.
References
[1]. East, R. and Wright, M. (2024) Potential Predictors of Psychologically Based Stock Price Movements. Journal of Risk and Financial Management, 17(8), 312–312.
[2]. Durusu-Ciftci, D., Ispir, M.S. and Kok, D. (2019) Do stock markets follow a random walk? New evidence for an old question. International Review of Economics and Finance, 64, 165–175.
[3]. Lin, X. (2023) The Limitations of the Efficient Market Hypothesis. Highlights in Business, Economics and Management, 20, 37-41.
[4]. Gandhmal, D.P. and Kumar, K. (2019) Systematic analysis and review of stock market prediction techniques. Computer Science Review, 34(100190), 100190.
[5]. Shahi, T.B., Shrestha, A., Neupane, A. and Guo, W. (2020) Stock Price Forecasting with Deep Learning: A Comparative Study. Mathematics, 8(9), 1441.
[6]. Nabipour, M., Nayyeri, P., Jabani, H., Mosavi, A., Salwana, E. and Chen S.S. (2020) Deep Learning for Stock Market Prediction. Entropy, 22(8), 840.
[7]. Ferreira, F.G.D.C., Gandomi, A.H. and Cardoso, R.T.N. (2021) Artificial Intelligence Applied to Stock Market Trading: A Review. IEEE Access, 9(2169-3536), 30898–30917
[8]. Bhandari, H.N., Rimal, B., Pokhrel, N.R., Rimal, R., Dahal, K.R. and Khatri, R.K.C. (2022) Predicting stock market index using LSTM. Machine Learning with Applications, 9(100320), 100320.
[9]. Bathla, G. (2020) Stock Price prediction using LSTM and SVR. IEEE Xplore, 50313, 9315800.
[10]. Wang, C., Chen, Y., Zhang, S. and Zhang, Q. (2022) Stock market index prediction using deep Transformer model. Expert Systems with Applications, 208, 118128.
[11]. Tariq, S.M. (2023) Evaluation of Stock Closing Prices using Transformer Learning. Engineering, Technology and Applied Science Research/Engineering, Technology and Applied Science Research, 13(5), 11635–11642.
[12]. Gumelar, A.B., Setyorini, H., Adi, D.P., Nilowardono, S., Latipah, Widodo, A., Wibowo, A.T., Sulistyono, M.T. and Christine, E. (2020) Boosting the Accuracy of Stock Market Prediction using XGBoost and Long Short-Term Memory. IEEE Xplore, 50169, 9234256.
Cite this article
Lyu,J. (2024). Analysis of the Principle and Implementations for Predicting Stock Prices Using AI Models. Advances in Economics, Management and Political Sciences,134,199-205.
Data availability
The datasets used and/or analyzed during the current study will be available from the authors upon reasonable request.
Disclaimer/Publisher's Note
The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of EWA Publishing and/or the editor(s). EWA Publishing and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content.
About volume
Volume title: Proceedings of the 3rd International Conference on Financial Technology and Business Analysis
© 2024 by the author(s). Licensee EWA Publishing, Oxford, UK. This article is an open access article distributed under the terms and
conditions of the Creative Commons Attribution (CC BY) license. Authors who
publish this series agree to the following terms:
1. Authors retain copyright and grant the series right of first publication with the work simultaneously licensed under a Creative Commons
Attribution License that allows others to share the work with an acknowledgment of the work's authorship and initial publication in this
series.
2. Authors are able to enter into separate, additional contractual arrangements for the non-exclusive distribution of the series's published
version of the work (e.g., post it to an institutional repository or publish it in a book), with an acknowledgment of its initial
publication in this series.
3. Authors are permitted and encouraged to post their work online (e.g., in institutional repositories or on their website) prior to and
during the submission process, as it can lead to productive exchanges, as well as earlier and greater citation of published work (See
Open access policy for details).
References
[1]. East, R. and Wright, M. (2024) Potential Predictors of Psychologically Based Stock Price Movements. Journal of Risk and Financial Management, 17(8), 312–312.
[2]. Durusu-Ciftci, D., Ispir, M.S. and Kok, D. (2019) Do stock markets follow a random walk? New evidence for an old question. International Review of Economics and Finance, 64, 165–175.
[3]. Lin, X. (2023) The Limitations of the Efficient Market Hypothesis. Highlights in Business, Economics and Management, 20, 37-41.
[4]. Gandhmal, D.P. and Kumar, K. (2019) Systematic analysis and review of stock market prediction techniques. Computer Science Review, 34(100190), 100190.
[5]. Shahi, T.B., Shrestha, A., Neupane, A. and Guo, W. (2020) Stock Price Forecasting with Deep Learning: A Comparative Study. Mathematics, 8(9), 1441.
[6]. Nabipour, M., Nayyeri, P., Jabani, H., Mosavi, A., Salwana, E. and Chen S.S. (2020) Deep Learning for Stock Market Prediction. Entropy, 22(8), 840.
[7]. Ferreira, F.G.D.C., Gandomi, A.H. and Cardoso, R.T.N. (2021) Artificial Intelligence Applied to Stock Market Trading: A Review. IEEE Access, 9(2169-3536), 30898–30917
[8]. Bhandari, H.N., Rimal, B., Pokhrel, N.R., Rimal, R., Dahal, K.R. and Khatri, R.K.C. (2022) Predicting stock market index using LSTM. Machine Learning with Applications, 9(100320), 100320.
[9]. Bathla, G. (2020) Stock Price prediction using LSTM and SVR. IEEE Xplore, 50313, 9315800.
[10]. Wang, C., Chen, Y., Zhang, S. and Zhang, Q. (2022) Stock market index prediction using deep Transformer model. Expert Systems with Applications, 208, 118128.
[11]. Tariq, S.M. (2023) Evaluation of Stock Closing Prices using Transformer Learning. Engineering, Technology and Applied Science Research/Engineering, Technology and Applied Science Research, 13(5), 11635–11642.
[12]. Gumelar, A.B., Setyorini, H., Adi, D.P., Nilowardono, S., Latipah, Widodo, A., Wibowo, A.T., Sulistyono, M.T. and Christine, E. (2020) Boosting the Accuracy of Stock Market Prediction using XGBoost and Long Short-Term Memory. IEEE Xplore, 50169, 9234256.