







1. Introduction
1.1. General introduction and motivation
With the continuous development of society, second language learning plays an indispensable role. At the same time, the research on mother tongue and second language acquisition is more and more extensive, and the influence of dialects in different backgrounds on second language learning has gradually become a concern. However, there are still some gaps in the specific dialect research. This paper focuses on the situation of learners whose mother tongue is Chinese but whose dialect does not contain coda/m/ (mainly in Sichuan, Chongqing and Yunnan) and those who contain coda/m/ (mainly in Guangdong and Fujian) in learning coda/m/ words in English as a second language through listening tests and aims to analyze which learners have advantage.
Although the literature has discussed multiple aspects of cross-language influence, there is a gap in the specific research on coda/m/and its impact on second language acquisition. This paper aims to fill this gap, gain a deeper understanding of the cross-linguistic phonetic transfer phenomena in language acquisition, and advance language teaching practices, making teaching methods more targeted, and also optimizing language learning materials and resources. Besides, it not only deepens our understanding of the manifestation and acquisition process of /m/ coda in different languages, but also provides new perspectives on exploring the mutual influence between different phonetic systems.
In this work, the subjects were divided into two groups---with-coda/m/ dialect speakers (mainly from Guangdong province) and without-coda/m/ dialect speakers (from Sichuan, Chongqing and Yunnan provinces) ---, completed listening tests on perception of coda/m/, and finally analyzed results.
1.2. Literature review
So far, there have been many studies on the impact of L1 on SLA, with many focusing on the transfer effects of dialect phonetics, especially negative ones [1-3]. As for Chinese dialects, Guan selected Shenyang local English learners as the research subjects to explore the acquisition of nine English fricatives by using speech acoustics software to extract the acoustic parameters, the center of gravity and dispersion. She found that Shenyang EFL learners’ acquisition of English fricatives is influenced by the negative transfer of Shenyang dialect fricatives [4]. However, our study will mainly focus on the possible positive transfer effect on L2 phonetic acquisition by focusing on the acquisition of coda[m] within two certain groups of people.
In fact, there were some comparative studies on different dialect’s transfer effect before. Zang asked L1 speakers of Tianjin Mandarin and Wenzhou Wu dialects, who have not been exposed to English before, to repeat the recording of English words. The result shows that Tianjin Mandarin speakers face greater difficulties pronouncing [e] and sequence of [k] and high front vowel, while Wenzhou Wu native speakers cannot differentiate [ʃ] and [s], or [n], and [ŋ] correctly. At the same time, they all have their own advantages in pronouncing certain sounds [5]. This study illustrates that dialects may have both negative and positive effects on the phonetic acquisition of a second language.
This study will focus on comparing the perception of coda/m/ within two specific groups of people.
1.3. Questions and alternative answers
The core question is whether the existing coda/m/ of their L1 has a positive transfer effect on the perception of the coda/m/ in L2. To this end, specific research questions were formulated to prove our hypothesis.
1.3.1. Broad question
There are both positive and negative L1 transfers in SLA. It's assumed that shared features will facilitate L2 acquisition, while distinguished features will have negative effects on learning.
1.3.2. Specific question
Will learners whose L1 has coda/m/ have an advantage over other learners in acquiring L2 words with coda/m/?
1.Learners of coda/m/ dialects have advantages over other learners
a. L1 positive transfer is restricted. Those with-coda/m/-dialect speakers have learning advantages against the others in existing sounds of their L1, but have no significant advantages in phonetic combinations that do not exist in L1.
b. They have a significant advantage in the acquisition of all kinds of coda/m/ words.
2.Without-coda/m/-speakers have an advantage in acquisition.
3.Acquisition advantage is not significant among two groups of people.
1.4. Method
1.4.1. General introduction
This study uses quantitative research methods and questionnaires to collect data, aiming to explore the influence of different dialect backgrounds (Cantonese, Min dialect, Hakka, Sichuan-Chongqing dialects and other southwest Mandarin) on the perception and acquisition of coda m. Through the collection and analysis of relevant data, this study is expected to fill the gap in the study of coda m in second language acquisition and provide targeted teaching suggestions for educators.
1.4.2. Participants
This study mainly takes 80 people aged 18-45 as the research object. The subjects were divided into two groups---with-coda/m/ dialect speakers (mainly from Guangdong province, see Figure 1, Figure 2 and Figure 3) and without-coda/m/ dialect speakers (from Sichuan, Chongqing and Yunnan provinces).
After the test, 68 samples (34 of both groups) are qualified to be analyzed since some of the dialects lack coda/m/ as shown below.

Figure 1: The distribution of the word“三”(three)'s coda in Cantonese [6]
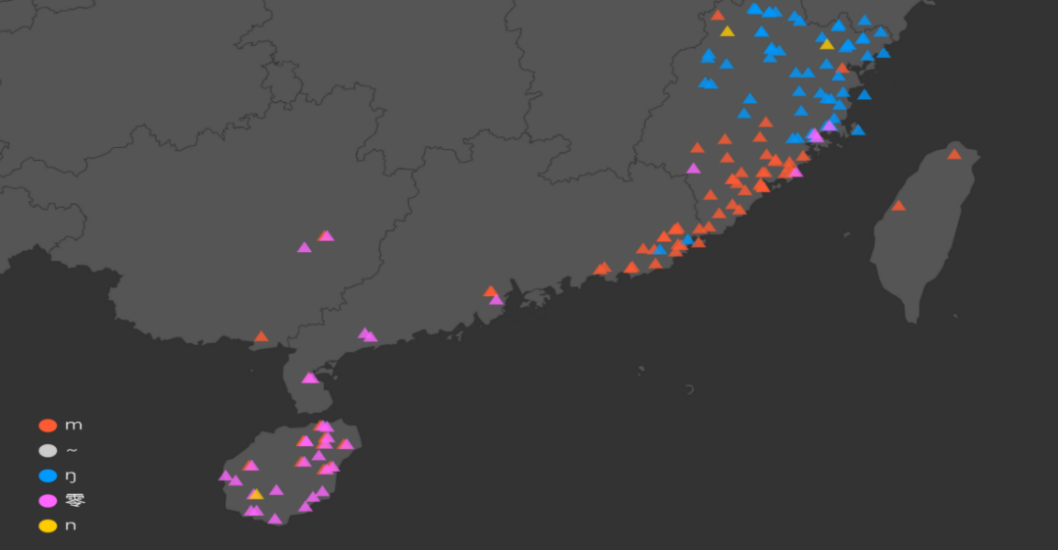
Figure 2: The distribution of the word“三” (three)’s coda in Min dialect [7]
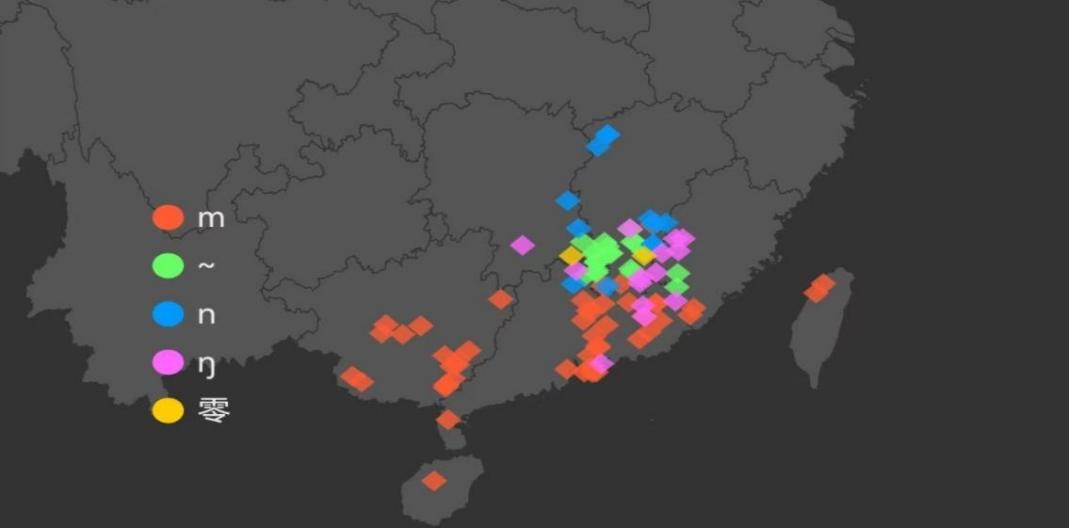
Figure 3: The distribution of the word“三” (three)’s coda in Hakka [8]
The sample included people of different ages and English proficiency (classified by The Common European Framework of Reference for Languages, also including scores for different examinations as reference, see Figure.4) to ensure that the sample is representative and broad.

Figure 4: English proficiency classification basis, including IELTS, TOEFL, CET-4, CET-6 and high school average scores
1.4.3. Data collection
The data collection is carried out through questionnaire on an online platform (Sojump), ensuring the convenience and anonymity of the data. The questionnaire design is based on the relevant literature and theoretical framework, and the final decision is made after the pre-test.
1.4.4. Questionnaire design
The questionnaire consisted of 30 listening questions according to the audio of artificial words produced by both an English native speaker and a software called text to speech. The usage of artificial words makes participants use their own perception and knowledge instead of habitual thinking. Among the questions, eight of them were words with coda m, four each of coda n, coda ŋ, coda b and coda p, and one each of coda s, coda f, coda d, coda t, coda g and coda k. In the eight questions of coda m, different vowel combinations am and im (widely found in Cantonese, Hakka, and Min dialect) and om and um (rarely found in Cantonese, Hakka, and Min dialect) are included. The design logic of the options is as follows: A: vowel 1 + coda 1; B: vowel 2 + coda 1; C: vowel 1+coda 2; D: vowel 2 + coda 2. Coda 1 and coda 2 are the voice opposition or similar nasal sound pairs (see Figure 5). The actual phonetic values of those vowels are: /e/ for “e”, /ɛ/ for “a” , /i/ for “i” , /ɔ/ for “o” and /u/ for “oo”.
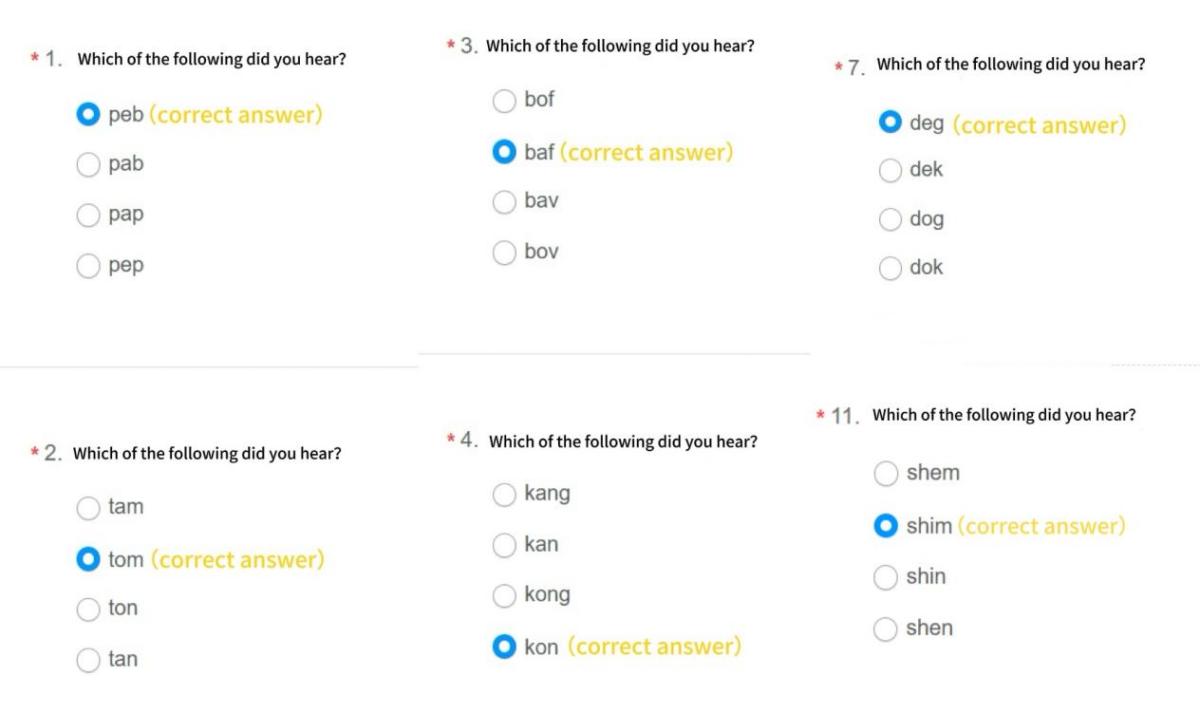
Figure 5: Partial question samples
1.4.5. Data analysis
Data analysis was carried out using Excel statistical software. First, the collected data is cleaned and sorted out, and invalid questionnaires are eliminated. Then, descriptive statistical analysis was conducted to understand the basic characteristics and distribution of samples, explore the relationship between dialect background and coda m perception, and test the rationality of the hypothesis. Finally, the analysis results are explained and discussed, and corresponding conclusions and suggestions are put forward.
2. Results and analysis
2.1. General performance
2.1.1. Performance on coda/m/
To measure the general performance of the two groups, there are two kinds of accuracy calculated. The first one is 100% accuracy, meaning that the participant chooses exactly the correct answer. The other is coda m accuracy, meaning that the participant may choose the wrong answer with a wrong nucleus, but the option which he or she chooses still end with coda m. As shown in Figure 6, the 100% accuracy of group 1 (Cantonese, Hakka and Min dialect group) is higher than group 2 (Chongqing, Sichuan and Yunnan dialect group).
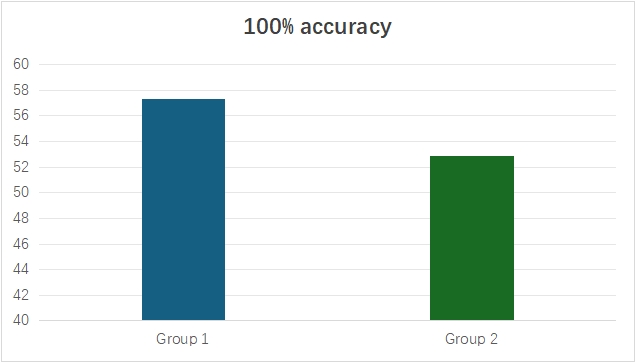
Figure 6: 100% accuracy of 2 groups
As for the coda m accuracy, group 2 did better than group 1 (see Figure 7). Group 2 is more affected by the nucleus, and this will be discussed separately.
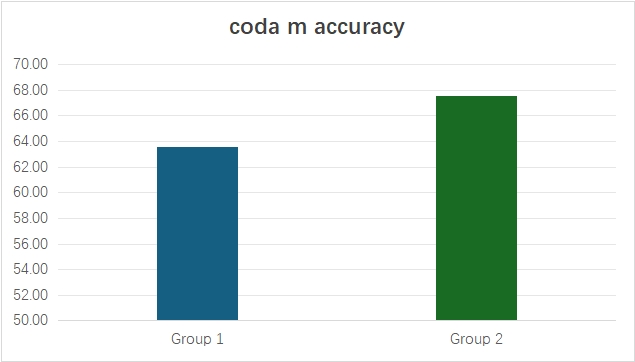
Figure 7: Coda m accuracy of two groups
2.1.2. Performance on coda/ŋ/
The questions ending in coda/m/ and whose interference options are coda/ ŋ / words were extracted from the question bank, and then the IF function in WPS was used to assign values to the questions and calculate the scores. Finally, the correction rates of each group were calculated, and the following results were obtained as Figure 8 shows:
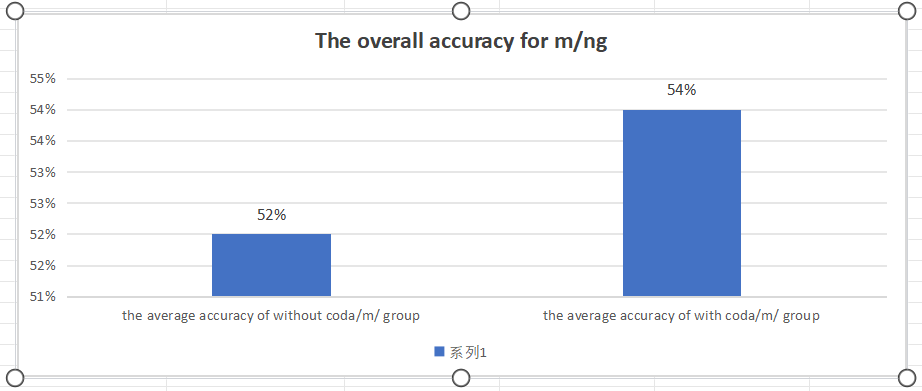
Figure 8: The overall accuracy of m/ŋ
It is observed that the correct rate of the coda/m/ group was slightly higher than that of the group without coda/m/, however, there is no significant difference between the two groups, which shows that the identification ability of coda/m/ and coda/ŋ/ in the coda/m/ group was stronger than that in the group without coda/m/.There are some differences in the pronunciation characteristics of daily dialects in Yunnan region, which to some extent caused the differences in the ability of the two groups to distinguish coda. In Sichuan, Chongqing and Yunnan regions, coda /m/ does not exist, and the pronunciation of /ŋ/ is not commonly omitted, which causes the confusion between coda/m/ and coda/ŋ/. However, the retention of /m/ and /ŋ/and the clarity of pronunciation in Guangdong are better than those in Sichuan, Chongqing and Yunnan regions, making the accuracy of coda/m/ group higher than that of the other group.
2.2. The linear relation between English proficiency and performance
In our data, there are 16 participants with English proficiency below B1 (B1-), 21 participants with English proficiency B1, 25 participants with English proficiency B2 and 6 participants with English proficiency C1 and C2 (C1+C2).
It is initially assumed that the perception of coda m has a positive linear relation with English proficiency. However, the results turn out to be completely opposite (see Figure 9).
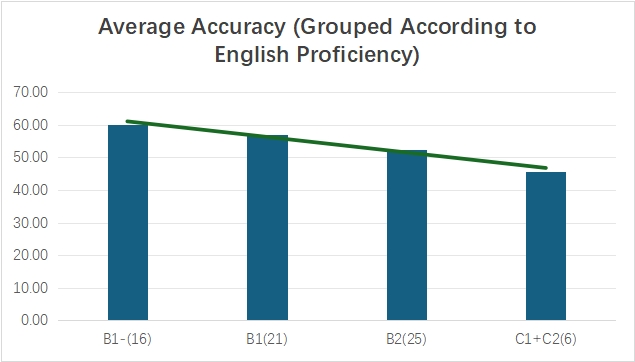
Figure 9: The average accuracy of different English proficiency groups
This uncommon finding may relate to the inconsistency between tests scores like IELTS and the actual English ability. Generally speaking, the improvement of English level means that the individual has a stronger ability in vocabulary understanding and grammar use. However, this is not always associated with better sound perception. Even though some people scored up to and including 7.0, they may still need assistance with the language and find sheltered instruction beneficial to achieve better academic results [9]. Besides, learners with higher English proficiency may over-rely on written materials, as reading is shown to have greatest correlation to the overall grades [10]. Thus, their ability of processing purely phonetic information is relatively weak, which may affect their perception of coda m in this research.
2.3. Performance on certain vowel-coda sets
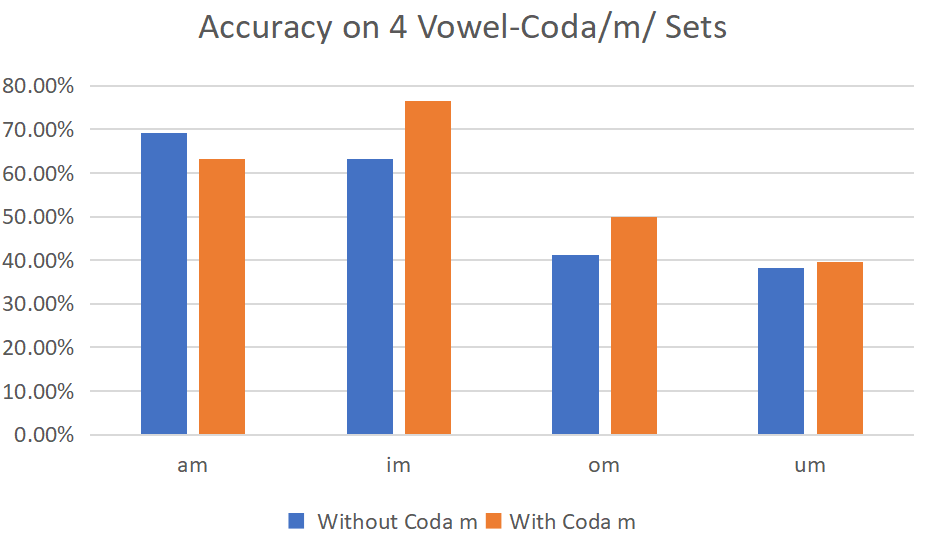
Figure 10: The accuracy of two groups on 4 vowel-coda/m/ sets
Table 1: The accuracy of 4 vowel-coda/m/ sets (%)
Coda set | Without Coda m | With Coda m |
am | 69.12 | 63.23 |
im | 63.24 | 76.37 |
om | 41.18 | 50 |
um | 38.24 | 39.71 |
When it comes to the accuracy on these 4 coda sets (am, im, om, um), without-coda/m/ group and with-coda/m/ group have no significant difference on am, om and um. With-coda/m/ group did a better job in perceiving /im/ (see Figure 10 and Table 1).
2.3.1. Performance on “am”
In terms of coda set “am”, two questions are designed for testing them (question 6 for “sam” and question 27 for “tam”). The result shows that without-coda/m/ group generally had a better performance (69.12% vs 63%). 18 people chose “sam” (13 of Without-coda/m/ group) and 29 of them picked “tam” (30 of Without-coda/m/ group). It is supposed that the result has something to do with the actual pronunciation in the recording of “sam”. The authentic phonetic value is/ɛn/ and it’s more natural for Southwest Mandarin speakers as they tend to pronounce /ɛn/ instead of/an/ when it comes to “Front vowel + coda/n/” in words like “三”(three, /san/ in Mandarin). On the other hand, the actual nucleus /ɛ/ making with-coda/m/ group more difficult to connect it with coda/m/ and chose “san” since they only have /am/ in their dialects. The familiarity of the vowel/ɛ/ saves with-coda/m/ group more energy to focus on the perception of coda/m/. Therefore, the vowel before the coda really makes a difference here.
2.3.2. Performance on “im”
When perceiving /im/, with-coda/m/ group had a significant advantage over the other group thanks to its existence in their L1. In Cantonese, Hakka and Min dialects, coda set /im/ universally exist in many commonly used words. For example, the word for “salt” is /im/ in Cantonese and “forest”(林) is pronounced like /lim/ in Hakka and Min dialects. From the comparison here, it’s clearly seen that the positive phonetic transfer from L1 to L2 in with-coda/m/ group. For without-coda/m/ group, who comes from Sichuan, Chongqing and Yunnan provinces, they tend to confuse /im/ with /em/, especially in question 21 (“shim”) where 34 of them correctly perceived coda/m/ while 21 of them chose “shim” and 13 people picked the wrong answer “shem”. This is because of the impact of their pronouncing habits. Our findings on i/e confusion are similar to Wang’s, where he illustrated the confusion of /i/ and /e/ by Sichuan English Learners in a text reading task.[11] By looking at the phonetic system of many Sichuan, Chongqing and Yunnan dialects, it is obvious that the phonetic set /ɛn/ are quite common in their dialects and sometimes they even omit /i/ when pronouncing /iɛn/. In general, their mouth are flatter and tongue’s position are quite close to the lower one /ɛ/ when pronouncing vowel /i/, making them easier to pick “shem” (like /ʃɛm/ for them) or “lem” (/lɛm/) in these questions.
2.3.3. Performance on “om” and “um”
There is no significant difference in perception of /om/ and /um/ and they have a relatively low accuracy on questions related to /om/ and /um/. It is because these two coda sets are absent in all of our target dialects.
In conclusion, the impact of vowels on coda/m/ perception is salient. It seems with-coda/m/ group rely more on the matching between vowel and coda, making us interested in their performance on other codas like /n/ and /ŋ/.
2.4. Further analysis on vowel’s impact: e/i and o/a +coda /n/ and /ŋ/
After research analysis and calculation of the relevant percentage, as Figure 11 shows, there is no significant difference of the accuracy of coda /n/ and coda /ŋ/ when the vowel is /e/ or /i/.
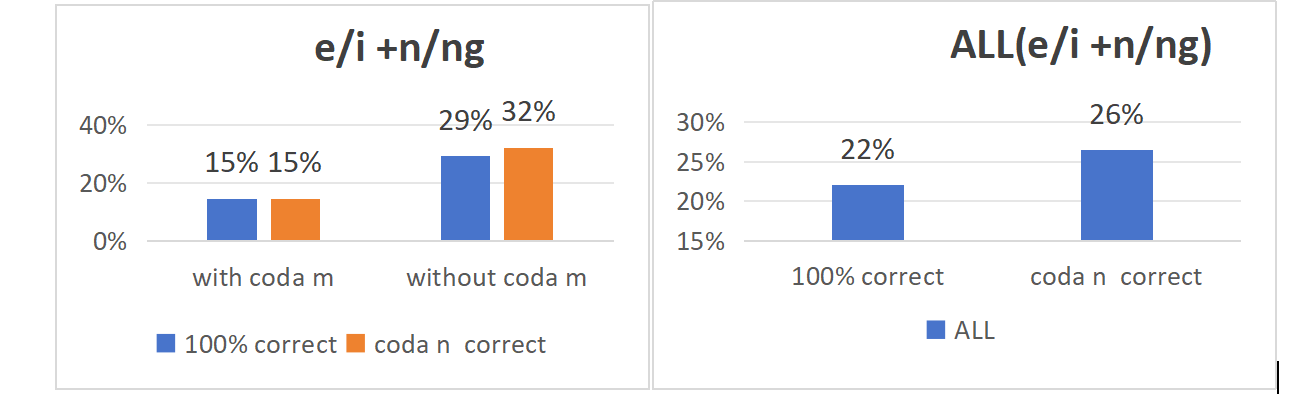
Figure 11: The overall and separate accuracy of e/i+ n/ŋ of two groups
However, as Figure 12 shows, the vowels /ɔ/ and /ɛ/ have a greater impact on the accuracy of coda /n/ and /ŋ/.
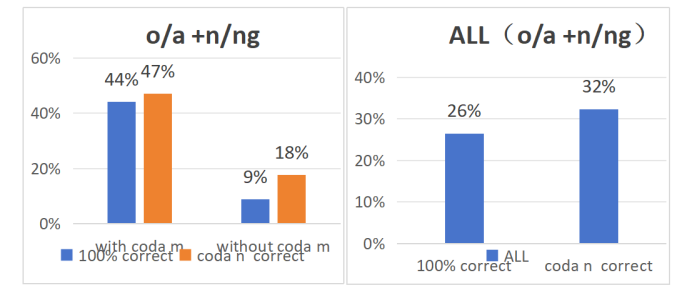
Figure 12: The overall and separate accuracy of ɔ/ɛ+ n/ŋ of two groups
This may be explained that compared to /i/ and /e/, /ɔ/ and /ɛ/ are further back, and compared to /m/, /n/ and /ŋ/ are also further back, so their combination sounds more harmonious. This leads to the combination of /in/, /en/, /iŋ/ and /eŋ/ sound more distinct, thus making it easier to distinguish the nucleus and the coda, while the combination of /ɔn/, /ɛn/, /ɔŋ/ and /ɛŋ/ are opposite, so it is more difficult to distinguish the nucleus and the coda in this case. Still, the perception of the coda has a lot to do with the vowel nucleus.
2.5. Findings
In this part, the following findings are obtained after analysis of data. First, the acquisition advantage of coda/m/ is not significant among the two groups of people. Second, though it seems there is no correlation between English proficiency and coda/m/ perception, the ambiguity of English proficiency evaluation makes it difficult to draw the final conclusion. Third, both positive transfer and negative transfer within two groups of people: positive transfer effects of with-coda/m/ groups are restricted to certain vowel-coda/m/ sets like “im”; negative transfer effects are more prevalent like Southwest Mandarin group’s i/e confusion and difficulties in recognizing absent phonetic sets “om” and “um”. Last but not least, it is shown that the vowel in front of the coda makes a substantial difference in coda type perception, for instance, with-coda/m/ groups like to link coda/m/ with certain vowels that matches the existing vowel-coda/m/ circumstances in their dialects.
2.6. Shortage and future study
2.6.1. Shortage
Some challenges and constraints exposed in the experiment, such as the quality of the recording equipment is not high enough due to time and equipment limited, resulting in some echo in the audio and unnecessary experimental errors; In addition, online experiment makes it difficult to control the subjects to take the test seriously, resulting in a part of data waste; What’s more, the experimental sample size and designed questions are relatively small, especially when it comes to the different vowel’s impact on coda/m/ perception. Thus, the higher quality of recording and increase of questions on different vowel-coda/m/ sets should be ensured in future study.
2.6.2. Future study
Given the results and analysis, the future study should focus on these following aspects: first, more vowel-coda/m/ combination sets should be studied as vowels in front of codas really play an important role in the perception of codas; second, since the English proficiency among people in China is higher and higher, it’s important to minimize the impact of English when exploring the transfer effect from L1 to L2. Therefore, it’s ideal to recruit monolingual speakers of certain dialects to complete the test. However, it’s quite challenging to ensure that those participants are familiar with those phonetic symbols; third, given the difficulty for monolingual speakers to response on those phonetic symbols, production test would be a good option as participants would be asked to repeat words with coda/m/ they had just heard and analyze the recording. The last but not least, the dialect proficiency should be taken into account in the future study since nowadays Mandarin is predominant over most of the dialects and young generation’s dialect proficiency has dropped rapidly in recent years, making many distinguished features like coda/m/ fade away from people’s daily talk. Thus, it’s quite important to encourage younger generations to restart speaking their original dialects since some phonemes in their dialects may be beneficial for them when acquiring similar sounds in L2. At the same time, school foreign language teachers should have some basic phonetic knowledge both on their dialects and L2 so to help students take advantage of their dialects and avoid pronunciation mistakes when speaking English. On the other hand, studying certain shared sounds in L2 may also benefit young people’s dialect authenticity though the counteraction may be very light. Therefore, more studies of transfer effect L1 dialects to L2, especially language other than English, should be conducted in the future.
3. Conclusion
In this study, online questionnaire was used to compare the perception of coda/m/ between 34 with-coda/m/ dialect speakers and 34 without-coda/m/ dialect speakers. The results show that with-coda/m/ dialect speakers have no significant advantage on L2 coda/m/ perception over their counterparts. However, with-coda/m/ had a better performance on certain vowel-coda/m/ sets that exist in their L1, which justifies the restrict positive transfer from L1 to L2. What’s more, it shows that the vowel in front of coda/m/ really makes a difference on coda perception for both groups of people as they are more used to certain vowel-coda sets over other strange ones. The study provides some ideas and efficient materials for second language teaching and lays a certain foundation for related second language acquisition concepts. The focus on phonetic transfer from L1 to L2, especially from the perspective of Chinese dialects, empowers the exploration of new teaching methods implementing the positive phonetic transfer in different regions. In the future, more studies on L1 phonetic transfer should be done to benefit more teachers and students.
Acknowledgement
Our thesis could not have been accomplished without the support and encouragement of many people.
First and foremost, we express our heartfelt gratitude to our professor, Andrew Nevins. Throughout the completion of the thesis, he has been guiding us patiently and encouraging us constantly, enabling us to successfully finish this thesis. It is precisely because of his continuous encouragement that we have been able to constantly break through ourselves, make progress, and have the courage to boldly express our viewpoints. Besides, his earnest academic spirit and humble, open personality have inspired our passion for academic research. Moreover, before the preparation of the thesis, he established a knowledge network system for us, laying a solid foundation for our subsequent writing. During the process of our thesis completion, he offered us many professional and valuable suggestions, allowing us to correct some inaccurate parts and overcome many difficulties. Under his guidance, we not only broadened our horizons but also laid a solid foundation for our future development, which will always be a precious asset for our subsequent academic research and career.
In addition, we are also very grateful to the authors whose books and articles have greatly inspired us, as well as provided us with inspiration for this paper.
At this point, we have mixed feelings. People are growing in progress, and in the continuous progress of growth. We hope that on the way to the future, we still have endless love, such as bright stars, such as wind freedom!
All the authors contributed equally to this work and should be considered as co-first author.
References
[1]. Flege, J. E. (1995). Second-language speech learning: Theory, findings, and problems. In W. Strange (Ed.), Speech Perception and Linguistic Experience: Issues in Cross-Language Research (pp. 233-277). York Press.
[2]. Johnson, K. (1997). Phonetic constraints on second language acquisition. Cambridge University Press.
[3]. Best, C. T., & Tyler, M. J. (2007). Non-native phoneme perception: findings, theory, and implications. In B. Goldstein (Ed.), The Oxford handbook of psycholinguistics (pp. 400-428). Oxford University Press.
[4]. Guan Y. (2023). An experimental study on the influence of Shenyang Dialect fricative on English fricative acquisition. Liaoning Normal University, MA thesis. Doi: 10.27212 /, dc nki. Glnsu. 2023.000893.
[5]. Zang, Y. (2024). How Dialects of Chinese Language Influence L1-Speakers’ Phonological and Phonetic Acquisition of English. Communications in Humanities Research, 34, 17-22.
[6]. The distribution of coda m in Cantonese, [online image]. http://www.kaom.net/
[7]. The distribution of coda m in Min dialect, [online image]. http://www.kaom.net/
[8]. The distribution of coda m in Hakka, [online image]. http://www.kaom.net/
[9]. Oliver, R., Vanderford, S., & Grote, E. (2012). Evidence of English language proficiency and academic achievement of non-English-speaking background students. Higher Education Research & Development, 31(4), 541–555. https://doi.org/10.1080/07294360.2011.653958
[10]. Neumann, H., Padden, N., & McDonough, K. (2018). Beyond English language proficiency scores: understanding the academic performance of international undergraduate students during the first year of study. Higher Education Research & Development, 38(2), 324–338. https://doi.org/10.1080/07294360.2018.1522621
[11]. Wang H. et. al. (2014). A study on the negative transfer of Sichuan Dialect to English pronunciation for English majors. Journal of Chengdu Normal University, 2014, 30(05): 48-53+70.
Cite this article
Cheng,D.;Xu,M.;Huang,W. (2025). Comparative Study on Coda/m/ Transfer Effect Between With-coda/m/ Dialect Speakers and Without-coda/m/ Dialect Speakers. Communications in Humanities Research,68,34-44.
Data availability
The datasets used and/or analyzed during the current study will be available from the authors upon reasonable request.
Disclaimer/Publisher's Note
The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of EWA Publishing and/or the editor(s). EWA Publishing and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content.
About volume
Volume title: Proceedings of 3rd International Conference on Interdisciplinary Humanities and Communication Studies
© 2024 by the author(s). Licensee EWA Publishing, Oxford, UK. This article is an open access article distributed under the terms and
conditions of the Creative Commons Attribution (CC BY) license. Authors who
publish this series agree to the following terms:
1. Authors retain copyright and grant the series right of first publication with the work simultaneously licensed under a Creative Commons
Attribution License that allows others to share the work with an acknowledgment of the work's authorship and initial publication in this
series.
2. Authors are able to enter into separate, additional contractual arrangements for the non-exclusive distribution of the series's published
version of the work (e.g., post it to an institutional repository or publish it in a book), with an acknowledgment of its initial
publication in this series.
3. Authors are permitted and encouraged to post their work online (e.g., in institutional repositories or on their website) prior to and
during the submission process, as it can lead to productive exchanges, as well as earlier and greater citation of published work (See
Open access policy for details).
References
[1]. Flege, J. E. (1995). Second-language speech learning: Theory, findings, and problems. In W. Strange (Ed.), Speech Perception and Linguistic Experience: Issues in Cross-Language Research (pp. 233-277). York Press.
[2]. Johnson, K. (1997). Phonetic constraints on second language acquisition. Cambridge University Press.
[3]. Best, C. T., & Tyler, M. J. (2007). Non-native phoneme perception: findings, theory, and implications. In B. Goldstein (Ed.), The Oxford handbook of psycholinguistics (pp. 400-428). Oxford University Press.
[4]. Guan Y. (2023). An experimental study on the influence of Shenyang Dialect fricative on English fricative acquisition. Liaoning Normal University, MA thesis. Doi: 10.27212 /, dc nki. Glnsu. 2023.000893.
[5]. Zang, Y. (2024). How Dialects of Chinese Language Influence L1-Speakers’ Phonological and Phonetic Acquisition of English. Communications in Humanities Research, 34, 17-22.
[6]. The distribution of coda m in Cantonese, [online image]. http://www.kaom.net/
[7]. The distribution of coda m in Min dialect, [online image]. http://www.kaom.net/
[8]. The distribution of coda m in Hakka, [online image]. http://www.kaom.net/
[9]. Oliver, R., Vanderford, S., & Grote, E. (2012). Evidence of English language proficiency and academic achievement of non-English-speaking background students. Higher Education Research & Development, 31(4), 541–555. https://doi.org/10.1080/07294360.2011.653958
[10]. Neumann, H., Padden, N., & McDonough, K. (2018). Beyond English language proficiency scores: understanding the academic performance of international undergraduate students during the first year of study. Higher Education Research & Development, 38(2), 324–338. https://doi.org/10.1080/07294360.2018.1522621
[11]. Wang H. et. al. (2014). A study on the negative transfer of Sichuan Dialect to English pronunciation for English majors. Journal of Chengdu Normal University, 2014, 30(05): 48-53+70.