







1. Introduction
1.1. Background and significance
1.1.1. Development and application fields of drone technology
Drones have rapidly evolved from niche gadgets to mainstream tools in the last decade as the manufacturing costs have decreased. Alongside the lower costs, many drone-related technologies have also improved, such as sensors. To adapt to the many different environments in which drones are being used today, flight controllers must be well-tested and exhibit desirable control even under extreme conditions,as shown in Figure 1 and Figure 2.

|
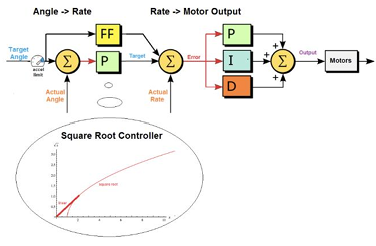
|
Drones typically consist of an inner loop for stability and control, and an outer loop for high-level tasks, such as navigation. Many algorithms are used to achieve these abilities, such as computer vision-based obstacle avoidance, and AI models for path planning and controls. The inner loop is implemented predominantly with PID. Despite the great performance of PID in stable environments, a different algorithm is definitely needed to navigate a harsher and more unpredictable environment [2].
1.1.2. Key role of attitude control
A drone’s attitude—its roll, pitch and yaw—is the single variable that separates controlled flight from an uncontrolled tumble: being inherently unstable, the airframe must be re-levelled dozens of times per second to stay upright, and any gust or ground-reflected turbulence only tightens that deadline. The same angles also constitute the machine’s only steering mechanism: every translation order is executed by tilting the airframe just enough to vector part of the thrust, so forward flight demands a few degrees of nose-down pitch while hovering in a crosswind requires an opposite roll into the breeze. Because the human stick commands are therefore fulfilled only to the extent that those micro-tilts are accurate and timely, a well-tuned attitude loop is what ultimately gives the pilot the impression of an obedient, “easy-flying” aircraft that will sit motionless in the sky until the next intentional nudge [3].
1.1.3. Potential of reinforcement learning in attitude control
Reinforcement learning (RL) treats control as a sequential decision-making problem, where an agent (the drone’s controller) learns a policy by interacting with the environment and receiving feedback in the form of rewards. Unlike traditional model-based approaches, RL is model-free: it does not require an explicit dynamics model. Instead, the system learns an optimal control policy through trial-and-error, optimizing behavior to maximize cumulative rewards. Modern deep RL algorithms use neural networks to handle high-dimensional state inputs and continuous action outputs, making them well-suited for complex drone dynamics [4].
1.2. Purpose and problem
1.2.1. Limitations of traditional controllers
Traditional controllers—cascaded PID, LQR or linear MPC—depend on a fixed, low-order model and on an IMU whose drift-prone, noisy outputs must be continuously filtered; they treat the drone as a time-invariant plant and tune gains for a narrow hover envelope. Once mass shifts, rotors age, wind becomes gusty, or the airframe enters aggressive maneuvers, the same gains over- or under-react, excite un-modeled flexible modes, and saturate motors, so performance drops and manual re-tuning is required—an inherent limitation that motivates learning-based, adaptive alternatives [5].
1.2.2. Applicability of PPO in drone attitude control
PPO (Proximal Policy Optimization) is a learning-based controller. Instead of hand-tuning gains or relying on a fixed model, PPO learns a policy—a mapping from the drone’s state (angles, rates, etc.) to motor commands—by practice (usually in simulation first). During training, it tries many actions, sees what works, and improves step by step. PPO adds a simple safety idea to training: only allow small, careful policy updates each round, which keeps learning stable [6].
It's particularly suitable for drone attitude control for the following reasons:
1. The drone’s true behavior changes with battery voltage, prop damage, wind, and payload. PPO doesn’t need a perfect model; it learns how to react from experience, including tricky cases (e.g., wind, ground effect), so it can handle nonlinear and changing dynamics naturally.
2. Instead of tuning KP, KI, KD (the values for a PID controller) by hand, you design a reward that encodes what you care about (small angle error, low rates, smoothness, low power). PPO then tunes itself to balance those goals. That makes it easier to target multiple objectives at once.
3. When you train in simulation with varied conditions (different masses, winds, sensor noise), PPO learns a single policy that works across them. This “practice on many scenarios” often yields robust behavior without per-scenario gain tables.
4. PPO can take in many signals at once (attitude, rates, motor temps, vibration metrics). Classical loops typically use a few signals and assume the rest is constant/insignificant. PPO can learn to weigh these inputs to make better choices.
1.2.3. Points of innovation
First, I adopted Reinforcement Learning algorithm (PPO) in drone attitude control to achieve better stability than traditional PID and LQR controllers, without spending too much extra computation budget.
Second, rather than report error only, I measured actuator command distribution and second-moment statistics to show that PPO achieves improved stability without unreasonable actuation spikes (smooth overall action instead of sudden twitches that minimizes error).
2. PPO algorithm
2.1. Core principals and mathematical derivation of PPO
TRPO derives a theory-backed update rule that contains each policy step using a KL-divergence-based trust region, yielding conservative updates with monotonic improvement guarantees. In practice, however, directly penalizing the KL term can be overly stringent and lead to very small steps unless the penalty weight is carefully tuned. Moreover, a single penalty coefficient that works across tasks, or even across phases of training on the same task, can be hard to pick [7].
A useful way to describe the KL-penalized step is:
where
With PPO, one widely used variant (PPO Clip) replaces the explicit KL penalty with a clipped probability-ratio objective. Let
if
PPO clipped is generally preferred as it's much easier to implement while still maintaining trust region like behavior. The original study also found PPO clipped to be more stable and generally better-performing than PPO penalty (another variant that relies on an adaptive KL penalty, but due to relevance, I will not go too deep into how it works) across multiple benchmarks [8].
2.2. Construction and optimization of objective function
Within PPO, the objective function is commonly a clipped function, to control the steps of policy updates.
where,
Update the policy parameters $theta$ by performing gradient ascent to maximize the clipped objective. At each update, compute the policy loss
Objective Function Construction and Optimization process for Value Function Update
The goal of updating the value function is to make its predictions as close as possible to the ground truth values. This is typically achieved by minimizing the mean squared error between the predicted value and the actual target. Specifically, the optimization objective for the value function is:
where
3. Application and design of PPO in drone attitude control
3.1. Experimental environment
In this project, I have chosen the CQ230 Open Source Drone Development Kit as our platform. This kit combines a Raspberry Pi 4B with a Pixhawk 2.4.8 flight controller (FC) to form a compact quadrotor. The Pixhawk FC runs the open source ArduPilot firmware, while the Raspberry Pi hosts development tools. Together, these features make the CQ230 kite ideal for my project [9].
3.1.1. Overall setup
The drone design comprises two main aspects: the structural design and the electrical design. The CQ230 kit provides all necessary hardware components, allowing us to focus primarily on algorithm implementation and system integration.
3.1.2. Structural design
The CQ230 drone kit uses a custom designed anti-collision frame as its structural backbone,as shown in Figure 3.

The frame has a 230 mm diagonal motor spacing in a symmetric quadcopter layout. The overall dimensions are approximately 350 by 360 by 300 mm, and the fully assembled weight is around 612 grams. This compact, lightweight design enables operation in confined, indoor spaces. In summary, the CQ230’s structural design balances miniaturization and robustness, providing a reliable hardware foundation for our experiments.
3.1.3. Hardware
All hardware used in the project is listed in Table 1.
|
Name |
Image |
Description |
|
Pixhawk 2.4.8 Flight Controller |
 |
Acts as the drone’s brain. It features a 32-bit STM32F427 processor, an onboard BMP561 barometer, and multiple I/O ports. |
|
Raspberry Pi 5B |
 |
Serves as the companion computer, running Ubuntu with pre-installed libraries. It handles high-level tasks such as computer vision, path planning, and network communication. |
|
Brushless Motors (2205) |
 |
Four 2205-series brushless motors paired with 5045 propellers deliver thrust and maneuverability. |
|
Electronic Speed Controllers (30 A ESC) |
 |
Each motor is controlled by a 20 A ESC, which receives PWM signals from the Pixhawk and precisely regulates motor RPM. |
|
Battery (4S, 16.8V 2300 mAh) |
 |
A single 4S battery provides enough power to sustain 7 minutes of flight. |
|
Power Module (Ledi Mini Pix) |
 |
Distributes battery power to the FC and provides voltage/current telemetry back to the FC for low-voltage warnings and failsafe logic. |
|
Optical Flow Sensor (MF-01) |
 |
Combines a downward-facing optical flow camera with a laser/ultrasonic rangefinder to provide position and height feedback. |
|
GPS Module (Ublox M8N) |
 |
Provides outdoor GNSS positioning with 2-3 m horizontal accuracy. |
|
RC Transmitter/Receiver (FlySky FS-i6) |
 |
A 6-channel 2.4 GHz transmitter and receiver allow manual control during testing and a range up to 700 meters. |
|
Buzzer (BB Alarm Buzzer) |
 |
Signals various flight events through audible alerts. |
3.1.4. Software environment and simulation setup
Operating system: On the drone, a Raspberry Pi 5B is used, with Ubuntu 24 installed, combined with Pixhawk to realize the control of the drone.Ground station uses: Windows + Anaconda + PyCharm/VScode.Programming language and toolchain: Python is used for the development of the PPO algorithm, and reinforcement learning libraries such as Stable-Baselines3 are used to accelerate implementation.Simulation platform: A UAV dynamics simulation environment based on PyBullet is constructed for algorithm training and preliminary verification.
3.2. Reinforcement learning framework design
3.2.1. Action space and state space definition
The action space A is defined as:
where:
•
• The range of rotational speed variation is
def __init__(self):super(DroneGymEnv, self).__init__()self.state_dim = 15self.state_space = Box(low=-np.inf, high=np.inf, shape=(self.state_dim,), dtype=np.float32)self.action_dim = 4self.action_space = Box(low=-0.08, high=0.08, shape=(self.action_dim,), dtype=np.float32)3.2.2. Reward function
The design of the reward function is crucial for the performance of reinforcement learning algorithms. In the task of attitude stabilization control of drones, the reward function $R$ is defined as:
•
•
•
•
•
Here,
which ensures attitude stability is prioritized.
def _calculate_reward(self, state, action):x, y, z, v_x, v_y, v_z, pitch, roll, yaw, omega_x, omega_y, omega_z, wind_x, wind_y, wind_z = statedelta_omega1, delta_omega2, delta_omega3, delta_omega4 = actionr_position = - (abs(x) + abs(y) + abs(z))r_velocity = - (abs(v_x) + abs(v_y) + abs(v_z))r_attitude = - (abs(pitch) + abs(roll) + abs(yaw))r_angular_velocity = - (abs(omega_x) + abs(omega_y) + abs(omega_z))r_action = - (abs(delta_omega1) + abs(delta_omega2) + abs(delta_omega3) + abs(delta_omega4))reward = 0.1 * r_position + 0.2 * r_velocity + 0.3 * r_attitude + 0.3 * r_angular_velocity + 0.1 * r_actionreturn rewardIn the experiments, the weighting parameters will be tuned according to the specific tasks and environmental conditions of the drone, in order to achieve optimal control performance. The reward function is designed to comprehensively account for the drone’s position, velocity, attitude, angular velocity, and control effort, thereby guiding the drone toward stable flight in complex environments.
3.2.3. Model evaluation
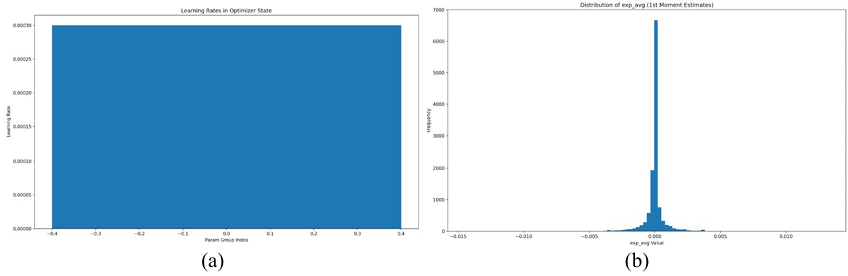
Figure 4(a) illustrates the distribution of learning rates across different parameter groups in the optimizer. It can be observed that all parameter groups share a constant learning rate of
Figure 4(b) shows the histogram of the frequency distribution of exp_avg values, where the horizontal axis represents the exp_avg values and the vertical axis represents frequency. The results indicate that most exp_avg values are concentrated around zero, forming a sharp peak. This distribution suggests that the algorithm tends to reduce the magnitude of policy updates during training, thereby promoting more stable policy improvement. The sharpness of the distribution also implies relatively low variance in updates, which benefits learning efficiency and stability. However, such a distribution may limit the algorithm’s ability to explore new strategies, since most update steps are small. Future research may focus on balancing exploration and exploitation to enhance adaptability and flexibility in more complex environments.
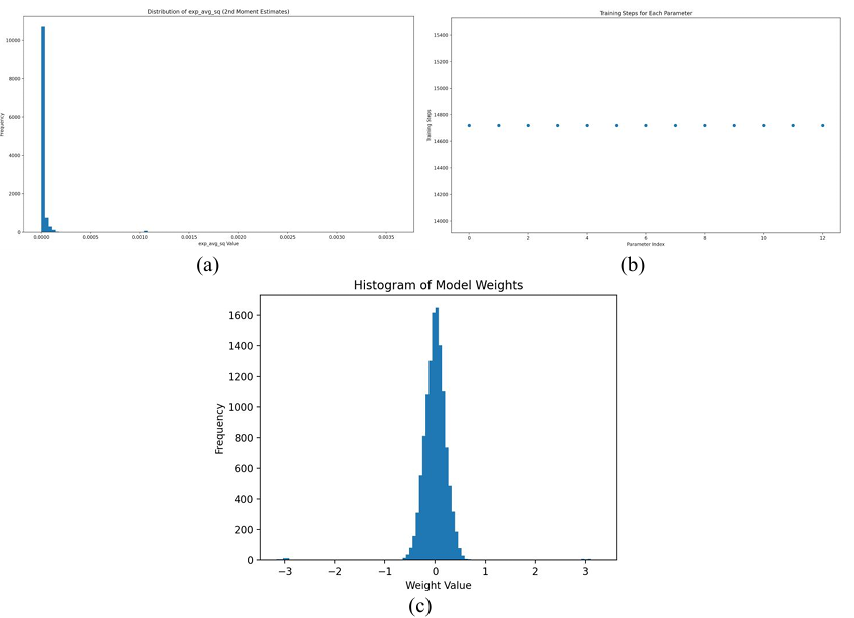
Figure 5(a) presents the histogram of the frequency distribution of exp_avg_sq values. The results show an even sharper concentration around zero, with nearly all estimates clustered extremely close to zero. This highly concentrated distribution indicates effective control over the second-moment estimates of policy updates, which likely helps reduce variance in updates and further improves training stability.
Figure 5(b) depicts the number of training steps corresponding to each parameter index. The data reveal that all parameters were updated at a relatively stable rate of approximately
In this setup, the total number of time steps was set to
Figure 5(c) reveals that the weight values are primarily concentrated around zero and approximately follow a normal distribution, with the highest frequency occurring between
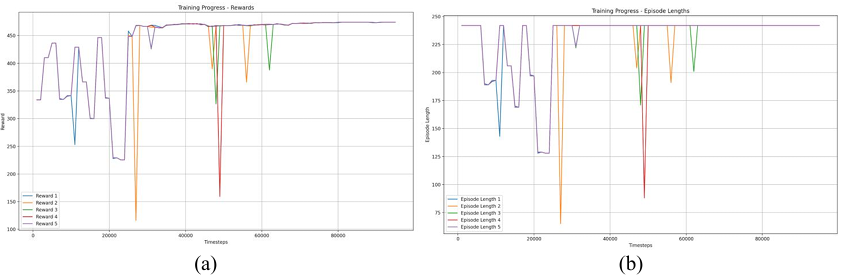
PPO training exhibits an early exploratory phase followed by convergence; Reward
Episode lengths show high variability during exploration but converge to stable values across all five episode types as training proceeds, indicating policy maturation and consistent task performance.
3.3. Experimentation
3.3.1. Simulation verification
|
Wind Level |
Wind Speed(unit: m/s) |
|
level 0 |
0 |
|
level 1 |
[0.3, 1.5] |
|
level 2 |
[1.6, 3.3] |
|
level 3 |
[3.4, 5.4] |
|
level 4 |
[5.5, 7.9] |
|
level 5 |
[8.0, 10.7] |
* There are more levels, but for the purposes of this research, up to level 5 is enough.
To comprehensively evaluate the performance of Proximal Policy Optimization (PPO) versus a conventional PID controller for drone attitude stabilization, we conducted a set of simulation experiments in the PyBullet environment. Simulations covered a range of wind conditions from Beaufort-scale equivalent level
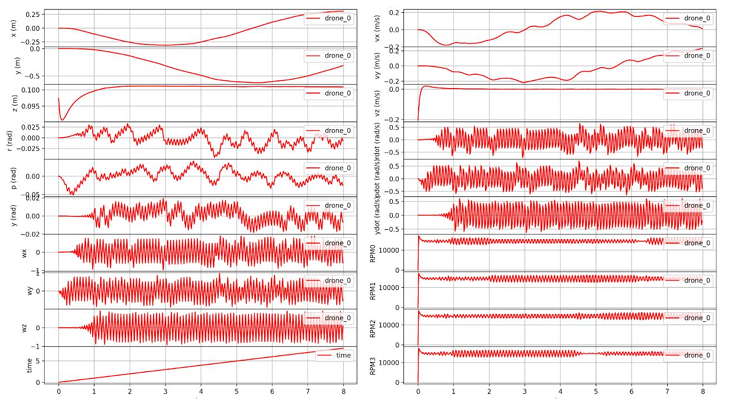
In simulations with progressively increasing wind speed, the PPO controller exhibited superior attitude stability. Even under strong winds equivalent to Beaufort scale
Position-error measurements further confirm PPO’s advantage. Across wind levels, the PPO-controlled vehicle maintained lower position deviations. For example, under level-3 winds (
3.3.2. Physical experimentation

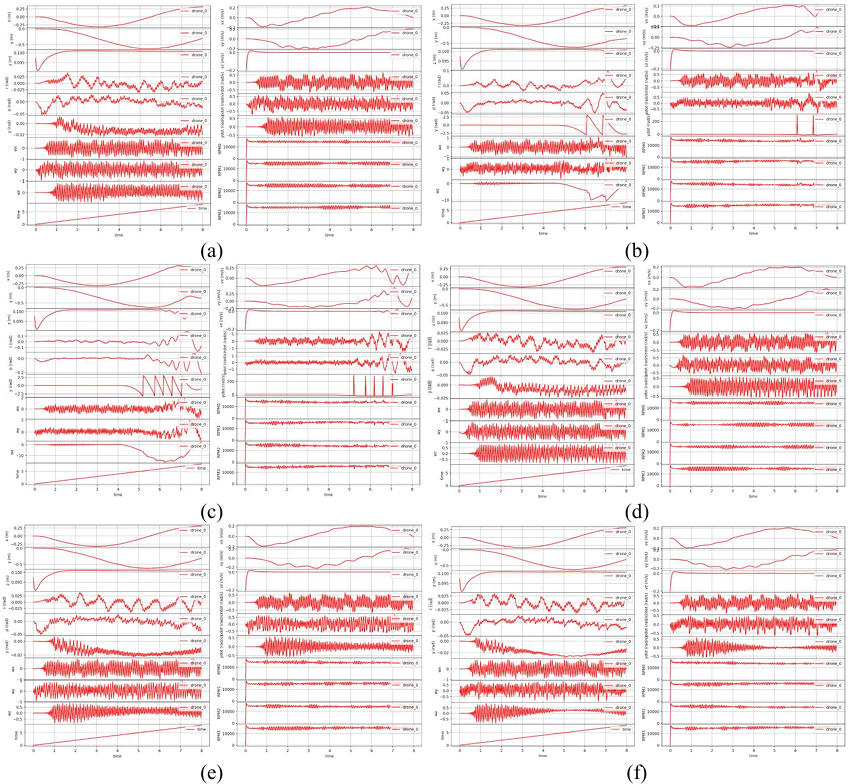
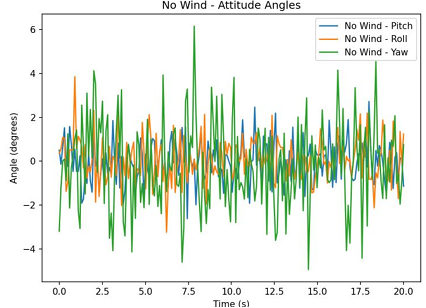
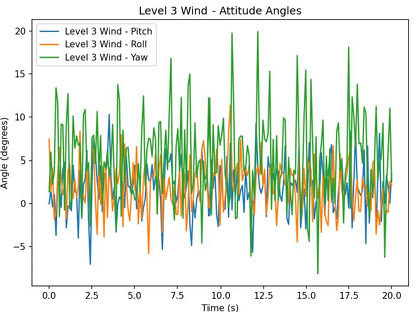
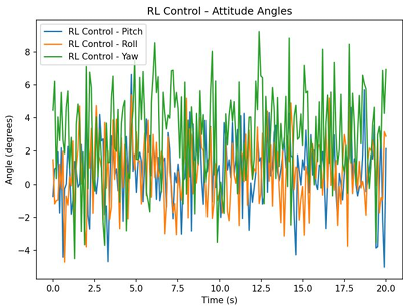
Due to environmental constraints and the power limitations of household fans, the UAV state under level-3 wind conditions,as shown in Figure 10.
|
|
|
|
Figure 11. (a)Attitude angle of PID at Level 0 wind. (b) Attitude angle of PID at level 3 wind. (c)Attitude angle of PPO at level 3 wind
Under no-wind conditions, the drone’s horizontal displacements in both the X and Y axes were tightly regulated, with mean values effectively zero and a standard deviation of approximately
|
|
|
|
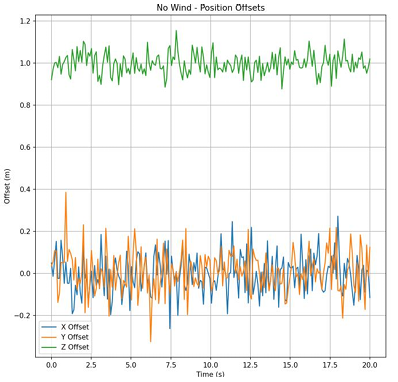
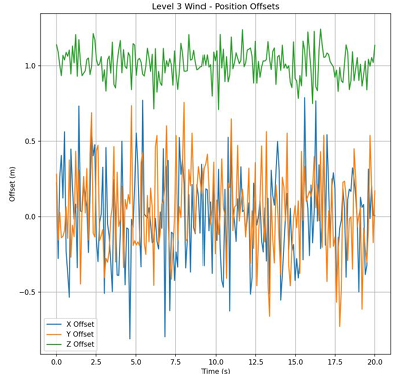
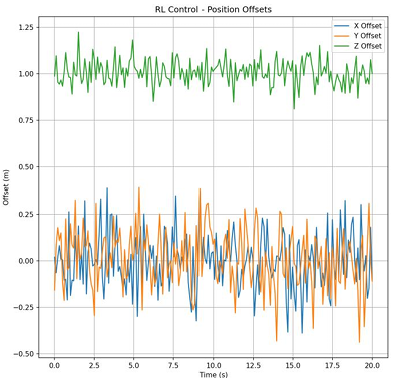
Figure 12. (a) Positional offset of PID at level 0 wind. (b) Positional offset of PID at level 3 wind. (c) Positional offset of PPO at level 3 wind
With no wind, the drone's
4. Conclusion and outlook
4.1. Summary of research results
This study compared a learned controller (PPO) against a conventional cascaded PID baseline for attitude stabilization and position holding on a small quadrotor platform (CQ230-style hardware in simulation). Key findings are:
• Attitude stability under wind. In progressively stronger simulated winds PPO maintained attitude excursions within
• Position accuracy. Under level-3 winds (
• Practical observation. PPO’s advantage stems from its ability to (1) implicitly learn nonlinear compensation for wind and actuator effects, (2) optimize multi-objective trade-offs encoded in the reward, and (3) generalize across a range of simulated disturbances when trained with sufficient scenario variety.
These results demonstrate that reinforcement learning, when carefully trained, can improve robustness and stability for small consumer drones relative to traditional control tuned around a single operating point.
4.2. Deficiencies and future work
All experiments used simulated wind (PyBullet) and household-fan test with limited uniformity and power. The learned policy may not directly transfer to physical hardware without domain randomization, system identification, or real-world fine tuning. Also, the simulator and the household wind setup do not fully reproduce turbulent, spatially varying wind fields, ground effect, or detailed propeller aerodynamics. These unmodeled effects can degrade real-world performances of PPO [11].
Also, due to using Reinforcement Learning Algorithms, important safety behaviors require additional verification, fallback controllers (which still have to be tuned), or runtime monitors. Also, training required many interactions: on-board learning or frequent re-training is impractical unless sample efficiency improves or efficient online adaptation schemes are implemented. Additionally, deploying neural network policies onboard requires attention to latency, quantization, and computational power on embedded platforms. Performance depends strongly on reward engineering. Learned behaviors can be brittle if reward terms are misaligned. Interpreting why a learned policy behaves a certain way also remains difficult. Experiments covered a finite set of wind magnitudes and conditions. Generalization to all other payloads, motor faults, and extreme maneuvers was not evaluated, and therefore lead to degraded performances in those scenarios [12].
Therefore, some suggested next steps includes:
• Add domain randomization (mass, sensor noise, delay, wind patterns) and system identification to narrow simulation-to-real gap.
• Explore more hybrid architectures (such as PPO with PID/LQR as fallback) in the case of PPO failure.
• Investigate explainability tools and systematic ablation studies to better understand reward-term contributions.
References
[1]. T. D. Company, “No Fear of Storms: New DJI M30 Enterprise Can Operate in Heavy Weather [Image].” 2025.
[2]. P. Gui, L. Tang, and S. C. Mukhopadhyay, “MEMS Based IMU for Tilting Measurement: Comparison of Complementary and Kalman Filter Based Data Fusion, ” in Proceedings of the 2015 IEEE 10th Conference on Industrial Electronics and Applications (ICIEA), Auckland, New Zealand, 2015, pp. 2004–2009. doi: 10.1109/ICIEA.2015.7334442.
[3]. P.-J. Bristeau, F. Callou, D. Vissière, and N. Petit, “The Navigation and Control Technology Inside the AR.Drone Micro UAV, ” in Preprints of the 18th IFAC World Congress, Milano, Italy, 2011, pp. 1477– 1484. [Online]. Available: https: //www.asprom.com/drone/PJB.pdf
[4]. W. Koch, R. Mancuso, R. West, and A. Bestavros, “Reinforcement Learning for UAV Attitude Control, ” ACM Transactions on Cyber-Physical Systems, vol. 3, no. 2, pp. 1–21, 2019, doi: 10.1145/3301273.
[5]. M. Okasha, J. Kralev, and M. Islam, “Design and Experimental Comparison of PID, LQR and MPC Stabilizing Controllers for Parrot Mambo Mini-Drone, ” Aerospace, vol. 9, no. 6, p. 298, 2022, doi: 10.3390/aerospace9060298.
[6]. J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and OpenAI, “Proximal Policy Optimization Algorithms, ” 2017.
[7]. J. Schulman, S. Levine, P. Moritz, M. I. Jordan, and P. Abbeel, “Trust Region Policy Optimization, ” arXiv preprint arXiv: 1502.05477, 2015, [Online]. Available: https: //arxiv.org/abs/1502.05477
[8]. W. Chen, K. K. L. Wong, S. Long, and Z. Sun, “Relative Entropy of Correct Proximal Policy Optimization Algorithms with Modified Penalty Factor in Complex Environment, ” Entropy, vol. 24, no. 4, p. 440, 2022, doi: 10.3390/e24040440.
[9]. J. Panerati, H. Zheng, S. Zhou, J. Xu, A. Prorok, and A. P. Schoellig, “Learning to Fly—a Gym Environment with PyBullet Physics for Reinforcement Learning of Multi-agent Quadcopter Control, ” in 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2021, pp. 7512–7519. doi: 10.1109/IROS51168.2021.9635857.
[10]. J. Peksa and D. Mamchur, “A Review on the State of the Art in Copter Drones and Flight Control Systems, ” Sensors, vol. 24, no. 11, p. 3349, 2024, doi: 10.3390/s24113349.
[11]. F. Santoso, M. A. Garratt, and S. G. Anavatti, “State-of-the-Art Intelligent Flight Control Systems in Unmanned Aerial Vehicles, ” IEEE Transactions on Automation Science and Engineering, vol. 15, no. 2, pp. 613–627, 2018, doi: 10.1109/TASE.2017.2651109.
[12]. A. Zulu and S. John, “A Review of Control Algorithms for Autonomous Quadrotors, ” Open Journal of Applied Sciences, vol. 4, no. 14, pp. 547–556, 2014, doi: 10.4236/ojapps.2014.414053.
Cite this article
Wang,S. (2025). Optimization Application of PPO Algorithm in Reinforcement Learning in Drone Attitude Balance. Lecture Notes in Education Psychology and Public Media,125,1-16.
Data availability
The datasets used and/or analyzed during the current study will be available from the authors upon reasonable request.
Disclaimer/Publisher's Note
The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of EWA Publishing and/or the editor(s). EWA Publishing and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content.
About volume
Volume title: Proceedings of CONF-CIAP 2026 Symposium: International Conference on Atomic Magnetometer and Applications
© 2024 by the author(s). Licensee EWA Publishing, Oxford, UK. This article is an open access article distributed under the terms and
conditions of the Creative Commons Attribution (CC BY) license. Authors who
publish this series agree to the following terms:
1. Authors retain copyright and grant the series right of first publication with the work simultaneously licensed under a Creative Commons
Attribution License that allows others to share the work with an acknowledgment of the work's authorship and initial publication in this
series.
2. Authors are able to enter into separate, additional contractual arrangements for the non-exclusive distribution of the series's published
version of the work (e.g., post it to an institutional repository or publish it in a book), with an acknowledgment of its initial
publication in this series.
3. Authors are permitted and encouraged to post their work online (e.g., in institutional repositories or on their website) prior to and
during the submission process, as it can lead to productive exchanges, as well as earlier and greater citation of published work (See
Open access policy for details).
References
[1]. T. D. Company, “No Fear of Storms: New DJI M30 Enterprise Can Operate in Heavy Weather [Image].” 2025.
[2]. P. Gui, L. Tang, and S. C. Mukhopadhyay, “MEMS Based IMU for Tilting Measurement: Comparison of Complementary and Kalman Filter Based Data Fusion, ” in Proceedings of the 2015 IEEE 10th Conference on Industrial Electronics and Applications (ICIEA), Auckland, New Zealand, 2015, pp. 2004–2009. doi: 10.1109/ICIEA.2015.7334442.
[3]. P.-J. Bristeau, F. Callou, D. Vissière, and N. Petit, “The Navigation and Control Technology Inside the AR.Drone Micro UAV, ” in Preprints of the 18th IFAC World Congress, Milano, Italy, 2011, pp. 1477– 1484. [Online]. Available: https: //www.asprom.com/drone/PJB.pdf
[4]. W. Koch, R. Mancuso, R. West, and A. Bestavros, “Reinforcement Learning for UAV Attitude Control, ” ACM Transactions on Cyber-Physical Systems, vol. 3, no. 2, pp. 1–21, 2019, doi: 10.1145/3301273.
[5]. M. Okasha, J. Kralev, and M. Islam, “Design and Experimental Comparison of PID, LQR and MPC Stabilizing Controllers for Parrot Mambo Mini-Drone, ” Aerospace, vol. 9, no. 6, p. 298, 2022, doi: 10.3390/aerospace9060298.
[6]. J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and OpenAI, “Proximal Policy Optimization Algorithms, ” 2017.
[7]. J. Schulman, S. Levine, P. Moritz, M. I. Jordan, and P. Abbeel, “Trust Region Policy Optimization, ” arXiv preprint arXiv: 1502.05477, 2015, [Online]. Available: https: //arxiv.org/abs/1502.05477
[8]. W. Chen, K. K. L. Wong, S. Long, and Z. Sun, “Relative Entropy of Correct Proximal Policy Optimization Algorithms with Modified Penalty Factor in Complex Environment, ” Entropy, vol. 24, no. 4, p. 440, 2022, doi: 10.3390/e24040440.
[9]. J. Panerati, H. Zheng, S. Zhou, J. Xu, A. Prorok, and A. P. Schoellig, “Learning to Fly—a Gym Environment with PyBullet Physics for Reinforcement Learning of Multi-agent Quadcopter Control, ” in 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2021, pp. 7512–7519. doi: 10.1109/IROS51168.2021.9635857.
[10]. J. Peksa and D. Mamchur, “A Review on the State of the Art in Copter Drones and Flight Control Systems, ” Sensors, vol. 24, no. 11, p. 3349, 2024, doi: 10.3390/s24113349.
[11]. F. Santoso, M. A. Garratt, and S. G. Anavatti, “State-of-the-Art Intelligent Flight Control Systems in Unmanned Aerial Vehicles, ” IEEE Transactions on Automation Science and Engineering, vol. 15, no. 2, pp. 613–627, 2018, doi: 10.1109/TASE.2017.2651109.
[12]. A. Zulu and S. John, “A Review of Control Algorithms for Autonomous Quadrotors, ” Open Journal of Applied Sciences, vol. 4, no. 14, pp. 547–556, 2014, doi: 10.4236/ojapps.2014.414053.