







1. Introduction
Machine learning stands as a prominent, burgeoning technology that emulates and operationalizes human learning processes [1, 2]. This is achieved through extensive research and the development of algorithms and statistical models, enabling the acquisition of new knowledge and skills. In turn, these capabilities empower computers to autonomously analyze and decipher intricate patterns and relationships within data, subsequently facilitating predictions and informed decisions [3]. Through continuous development, artificial intelligence has gradually gained applications in individual's daily lives, among which machine learning greatly enhances people's ability to search for information [4]. Machine learning provides many possibilities for retrieval and other services, which can optimize retrieval programs and improve their scalability [5]. In the past, machine learning has had the function of assisting retrieval in many fields, such as Machine learning based retrieval of day and night cloud macroscopic parameters over East Asia [6], or Automatic Thesaurus construction by machine learning from retrieval sessions [7]. As a result, machine learning has spurred the advancement of numerous domains, rendering people's lives increasingly convenient.
Although artificial intelligence has played a role in many fields, there are still some blank areas that require the help of artificial intelligence. For example, in the NBA, people mainly learn about NBA players based on their performance on the field. Previous cases have shown that machine learning collects datasets for NBA playoff predictions [8], but lacks comparative performance among players. For instance, gathering a comprehensive set of personal information, transfer records, transfer amounts, and preferred playing hands of a specific NBA player can be a challenging task for individuals. While some websites do offer this information, the search results are often convoluted and challenging to process. Machine learning, on the other hand, has the capacity to enable machines to comprehend the intricate details of NBA players, simplifying the process and delivering users the precise knowledge they seek. Therefore, compared to traditional methods of searching for relevant information on certain websites, machine learning has more retrieval advantages, which can help users quickly obtain accurate information. In addition, comparisons between players are also needed by users. In some web pages, users are unable to compare the differences between players and can only compare them through user memory, which may lead to comparison errors and give users incorrect judgments. However, through machine learning, machines can access the information of NBA players in the database and integrate it, making it complete and easy for users to understand in plain language. Therefore, machine learning can make NBA player retrieval more convenient.
This study aims to use Meta's llama-2 model [9] on the basis of machine learning. By building a database for the machine, NBA player information is included, and the training model is trained to automatically generate the content that users need. If player information needs to be compared, all information of the compared players is generated, and the required content is presented to users in simple and easy to understand language. Ultimately, it can clearly meet the needs of users.
2. Method
2.1. Data preparation
To establish an NBA player retrieval system, a dataset must be constructed. The database is manually built by searching the web for information on NBA players [10]. Sample database of 632 pieces of information about NBA players, and currently being updated, this database collects the names, ages, teams, years of NBA games, and first-time NBA handedness of NBA players. The following is a screenshot of the database section.
The language model used in this study is llama2-13b of meta. The llama model is a large language model from meta AI, similar to OPT. It is a fully open-source language model trained on trillions of tokens. It is worth mentioning that although llama only uses public datasets, it still achieves strong performance. The llama-13b outperforms GPT-3 in most benchmark tests. The guiding principle of llama is to train with large data based on small llm, with reference quantities ranging from 7B to 65B. This approach permits the language model to achieve stronger performance without being overly large in size. Additionally, the llama model only utilizes publicly available datasets and can be replicated after being open-sourced. It can also be customized for different systems based on a user's database. The pre-training data of llama contains approximately 1.4t tokens shown in Table 1, and the tokenizer is based on the sentencepieceprocessor method. The result shows the content and distribution of pre-training data for llama. The content of commoncrawl accounts for 67%, c4 accounts for 15%, github accounts for 4.5%, wikipedia accounts for 4.5%, gutenberg and books3 account for 4.5%, arxiv accounts for 2.5%, and stack exchange accounts for 2%.
Table 1. Percentage of pre-trained data
Dataset | Sampling prop | Epochs | Disk size |
CommonCrawl | 67.0% | 1.10 | 3.3TB |
C4 | 15.0% | 1.06 | 783TB |
Github | 4.5% | 0.64 | 328TB |
Wikipedia | 4.5% | 2.45 | 83TB |
Books | 4.5% | 2.23 | 85TB |
ArXiv | 2.5% | 1.06 | 92TB |
StackExchange | 2.0% | 1.03 | 78TB |
The experimental results of llama were evaluated on 20 standard zero-shot and few-shot tasks. It performed better than GPT-3, chinchilla, and palm. The remaining closed-question answering, reading comprehension, data reasoning, and code generation experimental results were relatively satisfactory.
The efficient implementation of llama includes fast attention mechanism and manual implementation of the backpropagation process, without using pytorch autograd. The fast attention mechanism used by LLaMa adopts an efficient causal multi-head attention (based on xformers), which does not store attention weights and does not calculate the values of masked query and key. The process of manually implementing backpropagation uses checkpointing techniques to reduce the computation of activation values in backpropagation. More precisely, LLaMa saves computationally expensive activation values, such as the output of linear layers.
By using model and sequence parallelism, memory usage of the model is reduced. In addition, LLaMa also maximizes overlap between activation computation and communication between GPUs on the network.
The method of this study is to imitate the database format of llama, write a new database and insert it into the llama model, so that it can learn and output information about NBA players. In the llama model, its database format is as follows.
According to the model’s database format, write a dataset based on it and use pandas for batch processing to obtain a new database. According to the newly created database, import the new database into the model using vector insertion method, ensuring that the format of the new database does not conflict with the model's database. Monitor whether the database is successfully inserted in Pinecone, and monitor how many records have been successfully inserted into the dataset. Pinecone provides a fully managed cloud-native vector database, allowing developers to store and retrieve vector embeddings more efficiently.
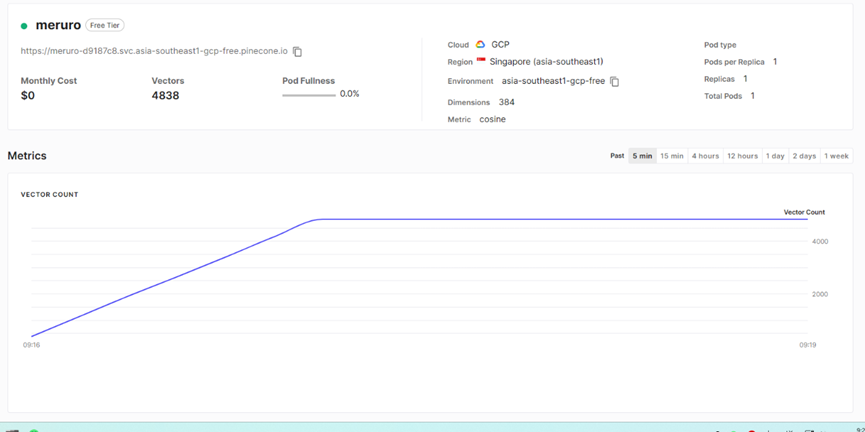
Figure 1. The data has been successfully inserted
After successfully inserting the vector database shown in Figure 1, the model learns based on the inserted data in order to output information that meets user expectations.
3. Results and discussion
In this study, a total of 20 experimental result tests were conducted, with 18 results meeting expectations and 2 results showing errors. The reasons for the errors were database information insertion failure and network malfunction. The following Figure 2 shows the experimental results answered using the newly inserted database and the results answered without inserting into the database.


Figure 2. Testing and comparison of models
In this experimental result, using the newly inserted database can obtain Kyle Lowry's personal information, team information, and personal habits that meet the user's retrieval needs. Without inserting the database, the model only outputs the information about Kyle Lowry contained in its original database without specific personal information. Therefore, the output after inserting the database is more satisfactory to users. There is another example shown in Figure 3.


Figure 3. Another example of comparison
In this example, the personal information about Stephen Curry outputted through the pipeline contains his personal habits and other information. On the other hand, in the output without using a pipeline, it only shows that Stephen Curry is an NBA player. Therefore, in this comparison, it can be seen that after inserting vector database, the model can output the desired information for users.
Although there are still significant differences in the results after successful database insertion, some results are still unsatisfactory to users. The following example is a comparison of NBA players. Although the model knows the information about the players, it only represents their differences and cannot display complete information. Therefore, in some comparative situations, the answers provided by the model are not complete and clear. Further inquiries from users are needed to display their information. Therefore, continuous improvement is required in this stage. Figure 4 shows the comparison of two players.

Figure 4. Compare and contrast the two players
Although there are some instances where the results may not meet expectations, the majority of the outcomes are indeed satisfactory. This model consistently demonstrates its ability to accurately and clearly present the information that users require in a wide range of scenarios. This study can be considered a resounding success, as it clearly demonstrates the model's exceptional performance in handling user inquiries and delivering pertinent and beneficial responses. The model's aptitude for comprehending and deciphering user input, coupled with its adeptness at producing coherent and contextually fitting responses, significantly contributes to its overall triumph. With ongoing enhancements and enhancements, there's ample room for this model to evolve into an even more indispensable tool for streamlining efficient communication and enhancing information retrieval.
4. Conclusion
Overall, in this study, Mata's large language model was used to mimic and learn human conversations, which is more user-friendly and easy to understand in conversations with the user and is much smaller in scale than other large language models, and by building a database to collect personal information about Nba players to build a chatbot that is more specialized based on the model, which will allow the user to retrieve and query more easily. The model still has some shortcomings, for example, the database needs to be constantly updated, and the robot still needs to increase the correctness of the answer, and in contrast to the answer to the question is more rigid, in the future development of the model should continue to increase the correctness of the answer by imitating the human language is more simple and easy to understand the response to the user's question to meet the user's needs, so the model still has a long way to go.
References
[1]. [Qiu Y et al 2022 Pose-guided matching based on deep learning for assessing quality of action on rehabilitation training. Biomedical Signal Processing and Control, 72, 103323.
[2]. Erickson B J et al 2017 Machine learning for medical imaging. Radiographics, 37(2), 505-515.
[3]. Mitchell T M 1997 Machine Learning. McGraw-Hill.
[4]. Zhang C Lu Y 2021 Study on artificial intelligence: The state of the art and future prospects Journal of Industrial Information Integration 23: 100224.
[5]. Zamani H et al 2022 Retrieval-enhanced machine learning Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2022: 2875-2886.
[6]. Yang Y Sun W Chi Y et al 2022 Machine learning-based retrieval of day and night cloud macrophysical parameters over East Asia using Himawari-8 data Remote Sensing of Environment 273: 112971.
[7]. Güntzer U Jüttner G Seegmüller G et al. 1989 Automatic thesaurus construction by machine learning from retrieval sessions Information Processing & Management 25(3): 265-273.
[8]. Wang J Fan Q 2021 Application of machine learning on nba data sets[C]//Journal of Physics: Conference Series. IOP Publishing 1802(3): 032036.
[9]. Roumeliotis K I Tselikas N D Nasiopoulos D K 2023 Llama 2: Early Adopters' Utilization of Meta's New Open-Source Pretrained Model
[10]. Basketball 2023 https://www.basketball-reference.com
Cite this article
Zhang,H. (2024). The investigation and development of chatbot related to NBA players. Applied and Computational Engineering,47,257-261.
Data availability
The datasets used and/or analyzed during the current study will be available from the authors upon reasonable request.
Disclaimer/Publisher's Note
The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of EWA Publishing and/or the editor(s). EWA Publishing and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content.
About volume
Volume title: Proceedings of the 4th International Conference on Signal Processing and Machine Learning
© 2024 by the author(s). Licensee EWA Publishing, Oxford, UK. This article is an open access article distributed under the terms and
conditions of the Creative Commons Attribution (CC BY) license. Authors who
publish this series agree to the following terms:
1. Authors retain copyright and grant the series right of first publication with the work simultaneously licensed under a Creative Commons
Attribution License that allows others to share the work with an acknowledgment of the work's authorship and initial publication in this
series.
2. Authors are able to enter into separate, additional contractual arrangements for the non-exclusive distribution of the series's published
version of the work (e.g., post it to an institutional repository or publish it in a book), with an acknowledgment of its initial
publication in this series.
3. Authors are permitted and encouraged to post their work online (e.g., in institutional repositories or on their website) prior to and
during the submission process, as it can lead to productive exchanges, as well as earlier and greater citation of published work (See
Open access policy for details).
References
[1]. [Qiu Y et al 2022 Pose-guided matching based on deep learning for assessing quality of action on rehabilitation training. Biomedical Signal Processing and Control, 72, 103323.
[2]. Erickson B J et al 2017 Machine learning for medical imaging. Radiographics, 37(2), 505-515.
[3]. Mitchell T M 1997 Machine Learning. McGraw-Hill.
[4]. Zhang C Lu Y 2021 Study on artificial intelligence: The state of the art and future prospects Journal of Industrial Information Integration 23: 100224.
[5]. Zamani H et al 2022 Retrieval-enhanced machine learning Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2022: 2875-2886.
[6]. Yang Y Sun W Chi Y et al 2022 Machine learning-based retrieval of day and night cloud macrophysical parameters over East Asia using Himawari-8 data Remote Sensing of Environment 273: 112971.
[7]. Güntzer U Jüttner G Seegmüller G et al. 1989 Automatic thesaurus construction by machine learning from retrieval sessions Information Processing & Management 25(3): 265-273.
[8]. Wang J Fan Q 2021 Application of machine learning on nba data sets[C]//Journal of Physics: Conference Series. IOP Publishing 1802(3): 032036.
[9]. Roumeliotis K I Tselikas N D Nasiopoulos D K 2023 Llama 2: Early Adopters' Utilization of Meta's New Open-Source Pretrained Model
[10]. Basketball 2023 https://www.basketball-reference.com