


Volume 163
Published on July 2025Volume title: Proceedings of the 3rd International Conference on Software Engineering and Machine Learning
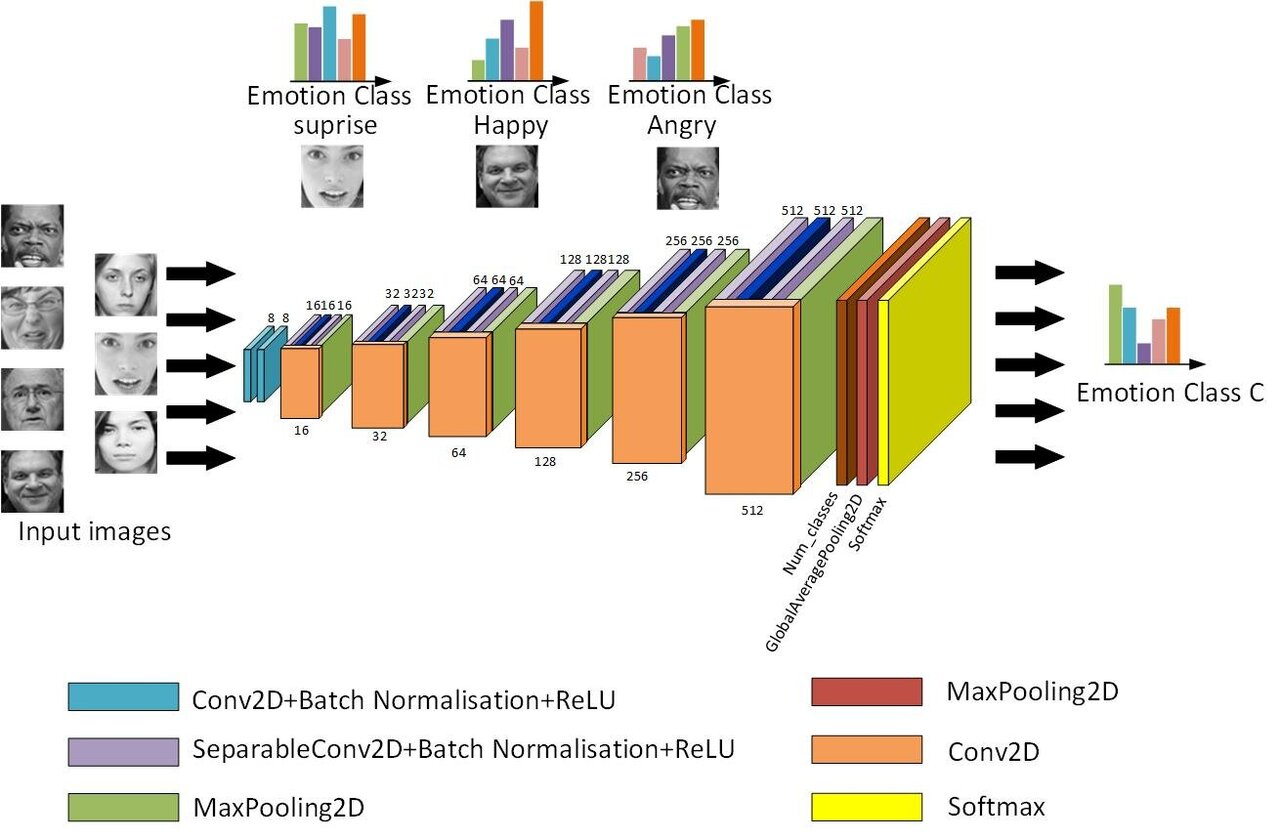
License plate recognition in foggy environments is one of the core challenges in Intelligent Transportation Systems (ITS). Fog causes blurred license plate images and reduced contrast, severely degrading recognition accuracy. This paper systematically reviews the key technologies for foggy license plate recognition, covering traditional and deep learning-based image dehazing methods, as well as advances in license plate localization and recognition algorithms, while analyzing their strengths and limitations. The study highlights that current methods face bottlenecks in dynamic fog density adaptation and generalization in extreme weather conditions. Future improvements require multi-modal data fusion and adaptive optimization to enhance performance. This work aims to provide theoretical references for optimizing and deploying license plate recognition technologies in foggy environments.



Accurate carbon price forecasting plays a key role in promoting emission reductions and advancing the low-carbon economy. Given the strong nonlinear nature of carbon prices and the subjective challenge in tuning hyperparameters for traditional LSTM networks, this study introduces a prediction framework combining a Hybrid Particle Swarm Optimization (HPSO) algorithm with an LSTM neural network. Using China’s national carbon market data, both univariate and multivariate time series predictions are conducted. Results demonstrate that the HPSO algorithm efficiently tunes LSTM hyperparameters, enhancing performance compared to multilayer perceptron (MLP) models. Moreover, incorporating multiple variables yields superior predictive outcomes over using historical prices alone.
In the current context where the digital social movement increasingly influences the shape of political discourse, artificial intelligence demonstrates a dual effect by capturing and guiding collective emotions. This study explores the intersection of affective computing and strategic communication, revealing how AI reconstructs the emotional mobilization mechanism and ethical framework in protest activities. Based on an interdisciplinary theoretical perspective, we apply facial recognition models, transformative text classifiers, and multimodal fusion technologies to conduct sentiment mapping of protest content on social platforms. Experimental data show that the emotion recognition scheme integrating multiple modalities has the highest classification accuracy (F1= 0.89), which makes it possible to accurately anchor emotions. The communication strategy designed from emotional portraits such as anger and fear increased the interactive participation rate by up to 42%. However, technological empowerment comes with profound ethical risks—emotional manipulation can undermine the authenticity of public discussions, and data collection also faces litigation for privacy violations. The research empirically reveals the reshaping effect of emotional intelligence tools on the shape of collective actions and proposes a framework for ethical application that considers both emotional resonance and social responsibility, delineating the limits of technological intervention in the public domain.
The rapid development of AIGC technology has opened a new avenue for personalized visual communication. This study builds a deep learning framework that integrates adaptive image generation and user-driven content arrangement, aiming to improve the expressiveness and delivery efficiency of visual creation. The technical architecture consists of two modules: the image generation engine based on Stable Delivery and the content scheduling system driven by the GRU algorithm. The two modules are connected by a feedback loop and can dynamically optimize image quality and push timing based on user interaction data. Experiments based on the LAION-400M dataset and real user logs show that this system performs remarkably well in indicators such as image fidelity and semantic fit, and the click-through rate and user satisfaction score have significantly improved. Compared with the static scheduling system, the system achieved an FID score of 12.4, and the average click-through rate increased by 18.7%. This solution not only promotes technological innovation in AIGC, but also provides practical tools for scenarios such as brand communication and digital marketing in the new media environment.
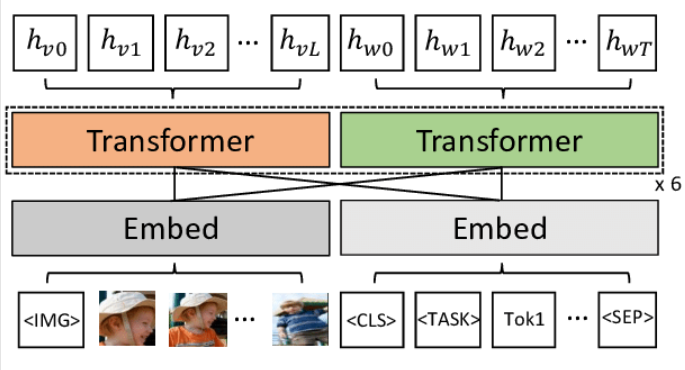
This paper proposes an efficient expansion scheme for the multimodal transformer architecture. By integrating sparse attention and low-rank adaptation technology, a distributed training framework is constructed. In response to the efficiency requirements of multimodal understanding tasks, this scheme reduces computational complexity while maintaining performance benchmarks for text, image, and audio tasks. The sparse attention mechanism reduces memory and computational energy consumption by limiting the attention span, while the low-rank adaptation technology enables rapid task migration without the need for complete parameter retraining. The distributed training mechanism, combining model and data parallelism, ensures the system's adaptability to large-scale datasets and heterogeneous hardware environments. Experiments on standard datasets such as MSCOCO and VGGSound show that this scheme achieves significant improvements over traditional methods in terms of accuracy, memory usage, and training speed. The ablation experiment verified the synergistic effect of sparse attention and low-grade adaptation technology, and the scalability test showed a nearly linear acceleration effect among multiple devices. This research provides a feasible technical route for building intelligent systems suitable for real-time reasoning and multimodal fusion scenarios, and promotes the practical application of resource-saving multimodal technologies.
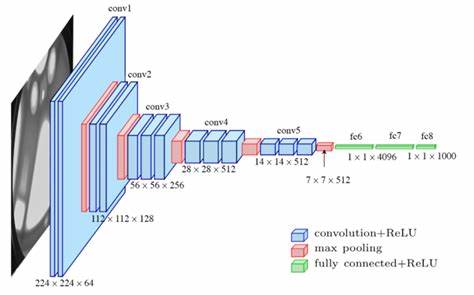
Computer vision, as a crucial branch of artificial intelligence, is profoundly transforming various aspects of human society. This paper provides a systematic exploration of the key technologies, application domains, challenges, and future development trends in computer vision. We begin with a detailed analysis of core technologies including convolutional neural networks, Transformer architectures, and edge computing. Subsequently, we conduct an in-depth investigation of innovative applications in healthcare, autonomous driving, smart agriculture, and security surveillance. Furthermore, we examine critical challenges such as data scarcity, ethical privacy concerns, and computational energy consumption. Finally, we present future research directions including neuromorphic vision systems and quantum machine learning. By synthesizing insights from 15 authoritative references, this study aims to provide comprehensive technical references and application guidance for both academia and industry.
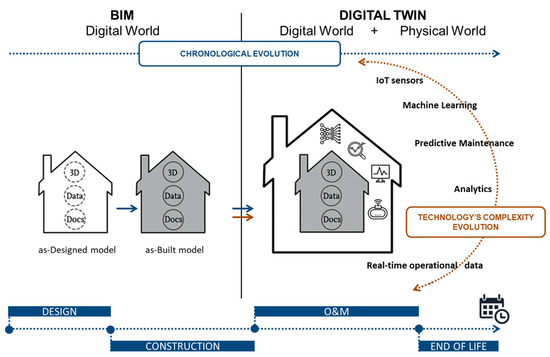
This study explores the integrated application of virtual guidance and digital twin technology in the cultural tourism metaverse, and builds an immersive guidance system based on intelligent semantic analysis and 3D reconstruction of real scenes. This system integrates four main modules: intelligent tour guide dialogue engine, high-precision scene rendering platform, multi-terminal interaction system, and content delivery scheduling algorithm. Through UAV lidar scanning and image modeling technology, a millimeter-level three-dimensional replication of a 0.5 square kilometer cultural heritage site was realized, which enabled inter-terminal access by mobile phones and VR devices. Test data from the recruitment of 150 experimenters shows that compared with traditional digital tour guides, the new system increased tourist guidance efficiency by 37.1%, reduced voice interaction time by 57.9%, and increased willingness to share content on social platforms by 62.4%. The intelligent dissemination algorithm optimizes the push strategy based on user behavior. At 10:00 a.m., the click-through rate reached a daily high of 44.8%. This system verifies the feasibility of virtual-real integration technology in cultural dissemination, providing a reusable technical framework for the digital upgrade of scenic spots. Its multimodal interaction mechanism and intelligent dissemination model can be extended and applied in fields such as digital cultural relic protection and virtual exhibitions.
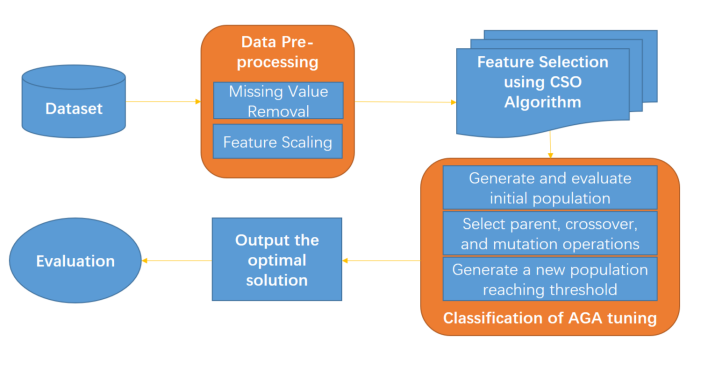
Traffic sign recognition is a critical component in the field of autonomous driving. In practice, recognising a wide range of different symbol classes with very high accuracy, robust performance, and rapid processing speed is essential. Traffic signs are designed for human readability, however, for computer systems, classifying traffic signs remains a complex pattern recognition problem. Image processing and machine learning algorithms are continually improving to improve this capability. Among them, deep-reinforcement learning (DRL) has become a cutting-edge technology that excels in feature extraction and offers practical solutions for various object recognition challenges. This article has four major contributions: firstly, we integrate CSO and AGA in traffic sign recognition, achieving highly favourable results. Secondly, we refine parameters, reducing training time while improving accuracy from 96.44% to 97.97%. Thirdly, we utilise multiple publicly available traffic sign datasets from various countries and regions to train our model, which achieves high accuracy and demonstrates strong robustness. Finally, we combines CSO for data filtering and training with AGA algorithm to improve both accuracy and efficiency. Overall, our analysis underscores the effectiveness of our proposed technology, highlights its potential in achieving precise traffic sign recognition, and positions it as a viable solution for real-time applications in autonomous systems.
The electronic gaming industry has developed rapidly, with horror games from "Fatal Frame" to "Outlast" gradually emerging, gaining popularity among players and expanding the market size. This study aims to delve into the strategies employed by horror games to achieve high levels of player immersion. At the same time, it analyzes the characteristics of the target audience and the potential effects of these games on player behavior. The results of, this research provides valuable insights for game designers. By optimizing game visuals, design concepts, player emotion manipulation, and integrating real-life integration, game designers can greatly enhance player immersion. Simultaneously, they should also focus on players’ perception of immersion in the game and the potential impacts of the games on player behavior. A deep understanding of these factors enables game designers to create games that attract players and enhance their gaming experience. In conclusion, this study offers a new perspective and approach for research in the gaming field, holding significant theoretical and practical implications for game design, player experience, and the impact of games on player behavior.
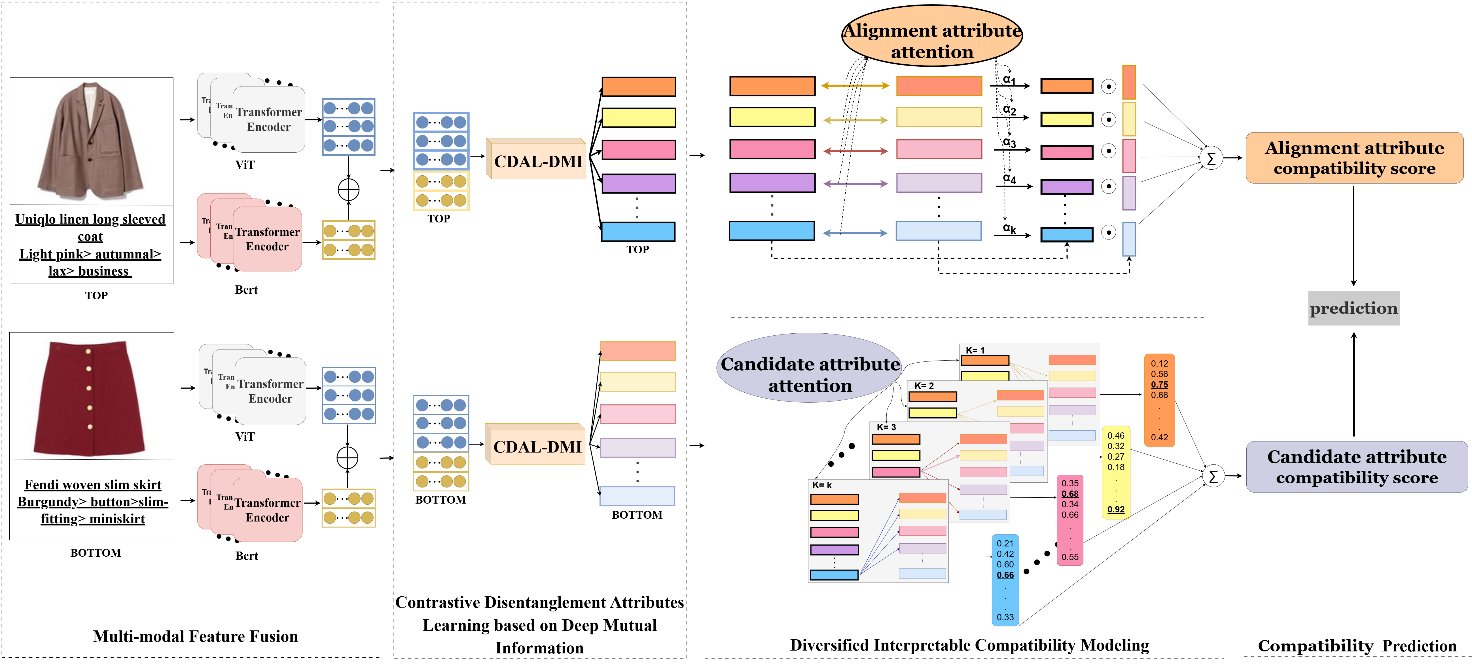
In recent years, compatibility modeling for evaluating whether fashion items match has received widespread attention. The existing compatibility modeling methods typically model the compatibility between fashion items based on multi-modal information. However, these methods often fail to disentangle the rich attribute information in the high-dimensional continuous representations of items, resulting in a lack of interpretability in recommendations. At the same time, they also overlook the diverse matching methods among the attributes of complementary items. This article proposes a Diversified Interpretable Compatibility Modeling based on a Multi-modal Disentanglement model (DICM-MD). In DICM-MD, we adopt disentanglement representation learning technology to disentangle the complex attribute information of fashion items and comprehensively evaluate the compatibility of items through diverse attribute matching methods. Specifically, we use deep neural networks to estimate the mutual information among the dimensions of high-dimensional continuous representations and adopt contrastive loss to encourage each dimension in the item representation to learn independent attribute information. Then, we learn the diverse attribute matching methods between complementary items from the alignment and non-alignment perspectives to model the compatibility of items more comprehensively. We conducted extensive experiments on the IQON3000 and Polyvore datasets, demonstrating that DICM-MD outperforms state-of-the-art methods.