







1. Introduction
The fusion of Natural Language Processing (NLP) and Information Retrieval (IR) has revolutionized our interaction with large volumes of textual data and the extraction of knowledge in today's fast-changing technological environment. Natural Language Processing (NLP), a specialized branch of artificial intelligence, is dedicated to comprehending and manipulating human language. On the other hand, Information Retrieval (IR) deals with the effective extraction of pertinent information from extensive collections of documents. The development of this interdisciplinary field has led to significant advancements in several areas, including search engines, language translation systems, and more.
Recently, the practical cases of NLP have expanded significantly, covering areas such as sentiment analysis, machine translation, text summarization, and others, resulting in substantial growth. Basic methodologies like named entity recognition, part-of-speech tagging, and syntactic analysis have laid the groundwork for sophisticated language comprehension systems [1]. Moreover, the introduction of machine learning techniques has significantly accelerated the progress of this domain, allowing NLP models to acquire knowledge from vast amounts of data and generate precise forecasts.
The importance of investigating the convergence of NLP and IR rests in its capacity to profoundly revolutionize diverse fields, such as healthcare, banking, and education. Through the utilization of NLP techniques, researchers have the ability to create more intelligent search engines, recommendation systems, and tools for managing knowledge. This not only improves the user's experience but also creates new opportunities for making decisions based on data and discovering knowledge.
Hence, the objective of this study is to examine the collaboration between NLP and IR, delving into the underlying principles, essential technologies, and real-world applications within this domain. This research explores the inherent difficulties and potential benefits in this interdisciplinary field, and aims to improve the development of smarter and more efficient information retrieval systems. This will open up new possibilities in the digital era.
2. An overview of Natural Language Processing (NLP)
NLP is a branch of artificial intelligence aimed at enabling computers to understand, analyze, and generate natural language. It involves interdisciplinary fields such as computer science, linguistics, and artificial intelligence.
The development of NLP has undergone several stages. Initially, rule-based methods were used for natural language processing but were limited by the complexity and coverage of rules. Subsequently, the rise of statistical methods enabled the development of data-driven models, such as Hidden Markov Models (HMM) and Maximum Entropy Models (MaxEnt). In the 21st century, with the emergence of deep learning technologies, particularly models like Recurrent Neural Networks (RNNs), Long Short-Term Memory Networks (LSTMs), and attention mechanisms, NLP has made significant progress. Deep learning models have not only achieved breakthroughs in tasks such as text representation, language modeling, and sequence-to-sequence modeling but have also demonstrated remarkable achievements in applications like machine translation, sentiment analysis, and question answering systems.
Since its inception, NLP has become an important research direction in computer science and plays a crucial role in various practical applications such as intelligent assistants, machine translation, and information retrieval [2]. With continuous technological advancements and expanding application scenarios, research and development in NLP continue to advance.
In the field of natural language processing, the application of deep learning has made significant progress.Deep learning models such as Word2Vec and GloVe are widely used technologies for representing text. These models can convert vocabulary into dense vector representations, effectively capturing the semantic relationships between words. They are particularly useful for tasks such as information retrieval, recommendation systems, and text classification.
The BERT model, introduced in 2018, is noteworthy for its utilization of the Transformer architecture and its introduction of bidirectional encoders. The BERT model achieves a high level of performance in contemporary NLP tasks by training on unlabeled text, allowing it to acquire extensive semantic knowledge. This makes it a prominent leader in the field, offering robust semantic representation abilities for a wide range of tasks.
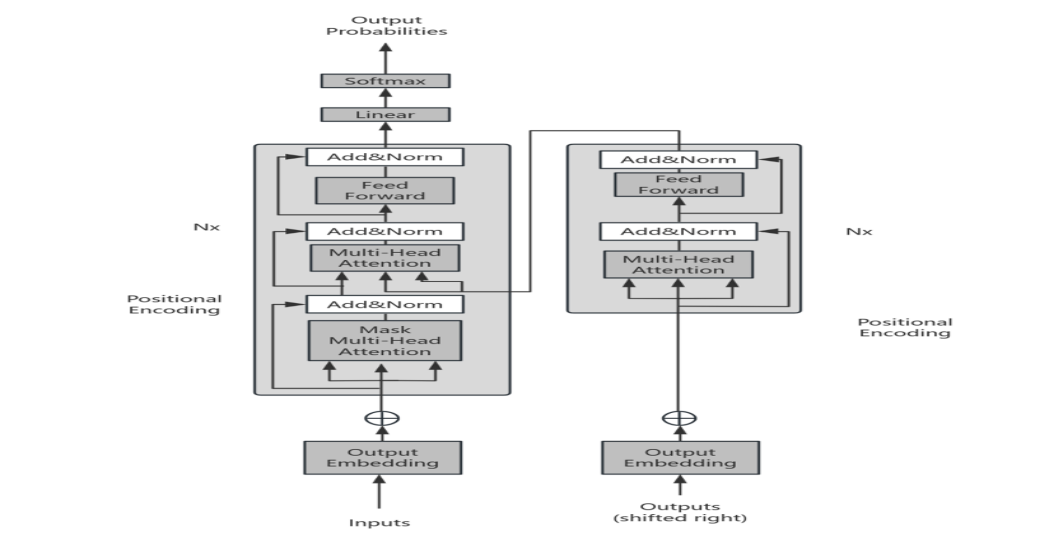
Figure 1. Transformer Model Architecture [3]
Furthermore, significant progress has been made in deep learning models for sequence modeling. For instance, the Transformer-XL model, introduced in 2019, overcame limitations in handling long sequence data, effectively enhancing the model's ability to learn long-term dependencies. Additionally, RNNs and their variants such as LSTM and GRU have demonstrated powerful potential in sequence modeling, especially in tasks like speech recognition involving sequence prediction [3].
In the field of natural language processing, there is a current focus on adversarial techniques for text generation tasks. Some studies indicate that pre-trained language models can learn from examples to generate adversarial text, thereby improving the success rate of attacks and enhancing the model's robustness. Other approaches concentrate on adversarial text generation techniques constrained by tree-structured recursive neural networks, deceiving the model by altering critical information in the text structure. These studies reveal vulnerabilities even in advanced language processing systems, necessitating further research to enhance their resilience against adversarial attacks.
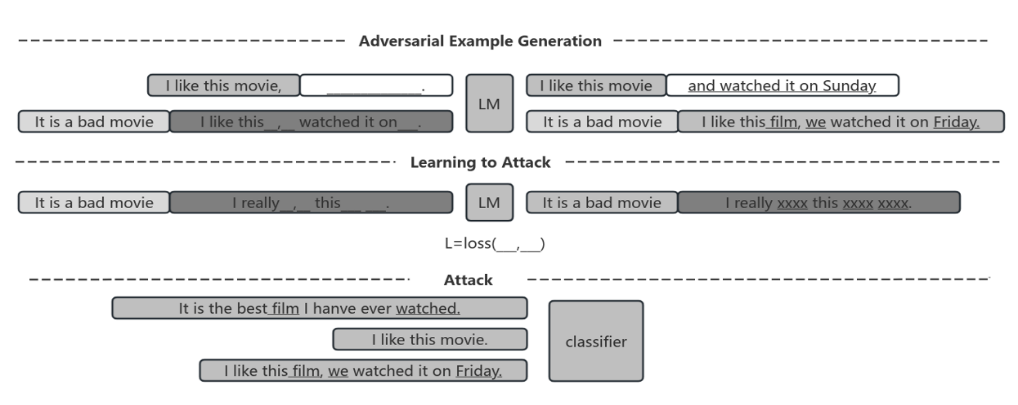
Figure 2. Adversarial Text Sample Generation and Attack Process Diagram[3]
At the same time, NLP technology has had significant impacts on academic journal publishing. First, it plays a crucial role in content production. NLP technology can identify and understand text, assisting editors in generating abstracts, titles, and keywords more quickly. It also conducts multidimensional checks and refinements of grammar, semantics, and discourse structure in papers, thereby enhancing the quality and accuracy of the content. Additionally, NLP technology intelligently handles typesetting, addressing formatting issues, thus improving the efficiency of academic content production.
Secondly, NLP technology enhances the scientific rigor and effectiveness of academic peer review. By automatically matching reviewers with expertise in specific fields, editors can expedite the process of finding suitable reviewers, thereby improving the accuracy and professionalism of peer review [4]. Furthermore, NLP technology can provide rapid, high-quality review feedback for reviewers, reducing professional biases and review cycles, thereby enhancing the scientific rigor and efficiency of paper evaluation.
3. Overview of Information Retrieval
Information retrieval refers to the process of retrieving relevant information from large-scale datasets based on user needs. Its development can be traced back to the early days of computing. With the rise of the internet, information retrieval has become increasingly important. Early information retrieval heavily relied on keyword matching, but with technological advancements, information retrieval systems are increasingly inclined towards utilizing techniques such as semantic analysis, machine learning, and artificial intelligence to enhance the quality and accuracy of search results. With the rapid increase in digital academic literature resources, researchers often face challenges of insufficiently comprehensive or mismatched initial query terms when searching academic literature databases, leading to reduced recall rates in search results. For example, when searching for English biological literature related to "microorganisms," using only the keyword "microorganism" may not cover all relevant literature. Therefore, to improve retrieval effectiveness, query expansion techniques have emerged.
In current research, deep learning-based query expansion techniques have become a notable approach. This technique is achieved through word vector representation and semantic similarity calculation. Firstly, word vector representation maps vocabulary to low-dimensional, dense, real-valued vector spaces, trained using tools such as word2vec, thereby capturing semantic information and grammatical relationships of words. Secondly, methods like Euclidean distance and cosine similarity are used to measure the similarity between word vectors, focusing on the semantic relationships between words. In the field of information retrieval, normalized Euclidean distance or cosine similarity is utilized to measure the similarity between word vectors, thereby selecting representative feature words for query expansion to improve retrieval effectiveness and accuracy.
Euclidean distance, also known as Euclidean metric, is a common method to measure the absolute distance between two points in multidimensional space. This distance measurement is widely used in K-means clustering and outlier detection algorithms. The formula for calculating Euclidean distance is as follows [5]:
\( {D_{E}}(X,Y)=\sqrt[]{\sum _{k=1}^{n}({X_{k}}-{Y_{k}}{)^{2}}} \)
On the other hand, cosine similarity is a method used to measure the cosine value of the angle between two vectors in vector space, utilized for assessing the similarity between two words. In contrast to Euclidean distance, cosine similarity focuses more on the difference in direction between two vectors. Its calculation formula is as follows [5]:
\( cos(θ)=\frac{\sum _{i=1}^{n}({x_{i}}∙{y_{i}})}{\sqrt[]{\sum _{i=1}^{n}({x_{i}}{)^{2}}} ∙\sqrt[]{\sum _{i=1}^{n}({y_{i}}{)^{2}}}} \)
These two distance measurement methods are commonly used in fields such as information retrieval for calculating word vector similarity.
In an era of explosive growth in digital literature, the challenge lies in how to swiftly and accurately retrieve the desired information from vast amounts of literature. While advancements have been made in the application of word vector technology in query expansion and indexing, challenges remain in handling massive data, multimodal expressions, and domain-specific semantics. Effectively establishing indexing systems, processing multimedia data, conducting cross-lingual retrieval, and improving retrieval accuracy in specialized domains are all challenges that the field of information retrieval must address [5]. Continuous innovation in technology is necessary to adapt to this era of information explosion and achieve more precise and efficient information retrieval.
4. Application of Natural Language processing in information retrieval
Natural language retrieval plays a significant role in modern information retrieval but also presents challenges and issues. Firstly, it faces the richness of synonyms and polysemy, leading to a plethora of semantically similar but differently expressed terms during the search process, thus reducing retrieval accuracy and precision. Additionally, problems such as incorrect collocations, false associations, and broadened search scopes are common, resulting in poor quality search results. Furthermore, many search engines suffer from inaccurate categorization, chaotic knowledge systems, and other issues during design and setup, further affecting the quality and speed of retrieval [6].
For Chinese, its complexity presents additional challenges as words lack clear delimiters, and a single character can express multiple meanings when combined with other characters, increasing the difficulty for computers during processing. Moreover, understanding the mood particles in sentences poses further challenges, impacting retrieval accuracy.
In addressing these issues, intelligent retrieval technology emerges as a solution. Intelligent retrieval technology aims to simulate human search behavior, automatically identifying user intent and providing accurate search results through steps such as semantic understanding, knowledge management, and knowledge search. Among these, intelligent agent technology, by analyzing and learning user preferences and requirements, coupled with relevant search systems, achieves rapid and accurate retrieval, significantly enhancing user experience and retrieval efficiency.
On the other hand, to better understand user retrieval preferences, the application of hybrid retrieval technology is gaining attention. Hybrid retrieval technology combines characteristics of controlled language and natural language, making retrieval more targeted and accurate. By integrating natural language retrieval with controlled language retrieval, this technology leverages the strengths of both, effectively improving retrieval efficiency and accuracy [7].
Furthermore, optimizing natural language retrieval technology is crucial. The application of pre-control and post-control techniques brings new possibilities to natural language retrieval. Pre-control techniques establish a correspondence library between natural language and retrieval language, enhancing retrieval accuracy and fault tolerance. Post-control techniques intelligently analyze user natural language and transform it into computer-readable, standardized retrieval requests, greatly enhancing retrieval precision and speed.
The combination of natural language processing (NLP) and information retrieval is aimed at improving retrieval effectiveness. This combination requires a comprehensive consideration of NLP and information retrieval technologies to construct a unified model. The NLPIR theoretical framework represents an attempt in this direction.
The fundamental assumption of the NLPIR framework is that there exists a certain representation distance between queries and documents, and reducing this distance can enhance retrieval effectiveness. To achieve this goal, the NLPIR framework combines different levels of natural language processing methods, including direct methods, expansion methods, extraction methods, transformation methods, and unified methods.
Direct methods primarily involve removing stop words, stemming, word segmentation, and part-of-speech tagging, while expansion methods utilize dictionaries for query expansion operations. Extraction methods involve extracting important information, such as named entities and facts from the text. Transformation methods include syntactic analysis, coreference resolution, and semantic analysis. Unified methods represent a hypothesis, as the available technologies for this approach are relatively limited [8].
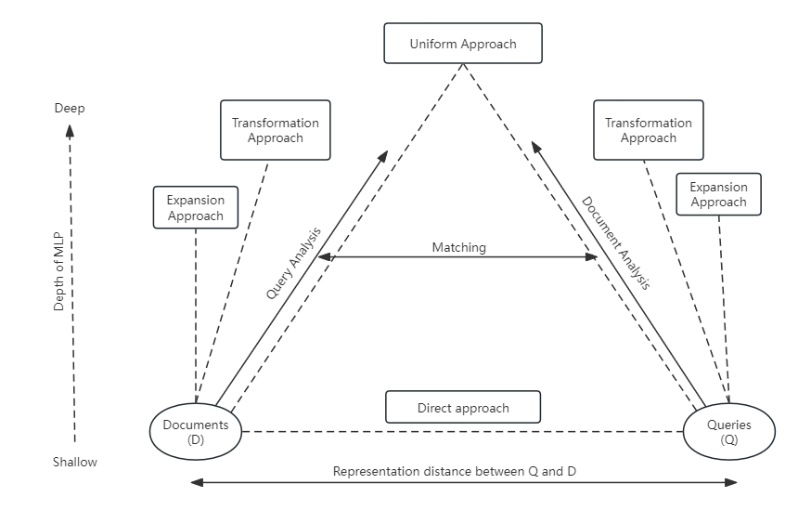
Figure 3. NLPIR Framework [8]
In the NLPIR framework, different levels of natural language processing methods can gradually reduce the representation distance between queries and documents, making them easier to match. However, it is important to note that the NLPIR framework is just a preliminary idea, and there is still a long way to go before a truly practical model is developed.
5. Conclusion
The paper provided a comprehensive analysis of the domains of NLP and Information Retrieval, including their importance and difficulties in real-world implementations. The integration of NLP with Information Retrieval has emerged as a prominent area of research due to the ongoing progress in technology. By examining the present status of implementing NLP techniques in information retrieval, we can deduce the following conclusions:
The advancement of NLP technology has introduced new opportunities for information retrieval, like the nlpir model. By integrating several methodologies and operations of NLP, it is feasible to attain enhanced levels of intelligence and precision in information retrieval. Furthermore, NLP encounters difficulties in its ability to adjust and apply its techniques to various languages, specific subject areas, and information that involves several modes of communication. The existing NLP methodologies have not completely resolved these problems, necessitating additional investigation and discovery.
Finally, future research should prioritize enhancing the precision and effectiveness of NLP technology in retrieving information, while simultaneously tackling the challenges of its usability and adaptability in dealing with certain topics or languages [9]. In order to enhance the advancement of NLP and information retrieval, and offer users superior information retrieval services, it is imperative to intensify research efforts and implement them in real-world situations.
In the future, our focus will be on further advancing NLP technology, bolstering its ability to process multilingual and multimodal data, and enhancing the intelligence and dependability of systems to better cater to users' requirements. We are confident that with persistent dedication and creative thinking, the fields of NLP and information retrieval will bring forth a more promising future. These advancements will provide individuals more convenient and precise methods for obtaining information.
References
[1]. Wen Cai (2024). Research on Intelligent Development Strategy of Academic Journals under the Background of Natural Language Processing Technology. Research on Philosophy and Social Science in Jiangsu Universities.
[2]. Devlin, J., Chang, M. W., Lee, K., et al. (2019). BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (pp. 4171-4186).
[3]. Ma, Tian, Guoliang Zhang, Xiaojun Guo. (2024). A Review of Natural Language Processing Attack and Defense Research on Deep Learning. School of Information Engineering, Tibet University for Nationalities, Xianyang 712082, Shaanxi, China.
[4]. Hao, W. K., Li, Z. C., Qian, Y. C., et al. (2020). The acl fws-rc: A dataset for recognition and classification of sentences about future works. In Proceedings of the ACM/IEEE Joint Conference on Digital Libraries in 2020 (pp. 261-269).
[5]. Yang, Xiyu. (2024). Research review and application prospect of semantic information retrieval based on word vector extension. Party School of Panzhihua Municipal Committee of the Communist Party of China, Panzhihua, Sichuan 617061.
[6]. Guan, B., Cai, R., & Cai, H. (2017). Application of Natural Language Processing in Information Retrieval. Information and Computer, China Computer & Communication, 11, 035-04.
[7]. Zhou, L., & Zhang, D. (2003). NLPIR: A Theoretical Framework for Applying Natural Language Processing to Information Retrieval. Journal of the American Society for Information Science and Technology, 54(2), 115-123.
[8]. Wang, C., Zhang, M., & Ma, S. (2007). Application of Natural Language Processing in Information Retrieval: A Review. Chinese Journal of Information, 21(2), 035-11.
[9]. Huang, E. B.. (2022). Research on Optimization Application of Spatial Information Retrieval Based on Natural Language Processing. Guangdong Provincial General Colleges and Universities Characteristic Innovation Project: Research on Knowledge Mapping Construction and Visualization Technology of Online Courses for Intelligent Education.
Cite this article
Wang,S. (2024). Exploring the fusion of natural language processing and information retrieval. Applied and Computational Engineering,76,27-32.
Data availability
The datasets used and/or analyzed during the current study will be available from the authors upon reasonable request.
Disclaimer/Publisher's Note
The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of EWA Publishing and/or the editor(s). EWA Publishing and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content.
About volume
Volume title: Proceedings of the 2nd International Conference on Software Engineering and Machine Learning
© 2024 by the author(s). Licensee EWA Publishing, Oxford, UK. This article is an open access article distributed under the terms and
conditions of the Creative Commons Attribution (CC BY) license. Authors who
publish this series agree to the following terms:
1. Authors retain copyright and grant the series right of first publication with the work simultaneously licensed under a Creative Commons
Attribution License that allows others to share the work with an acknowledgment of the work's authorship and initial publication in this
series.
2. Authors are able to enter into separate, additional contractual arrangements for the non-exclusive distribution of the series's published
version of the work (e.g., post it to an institutional repository or publish it in a book), with an acknowledgment of its initial
publication in this series.
3. Authors are permitted and encouraged to post their work online (e.g., in institutional repositories or on their website) prior to and
during the submission process, as it can lead to productive exchanges, as well as earlier and greater citation of published work (See
Open access policy for details).
References
[1]. Wen Cai (2024). Research on Intelligent Development Strategy of Academic Journals under the Background of Natural Language Processing Technology. Research on Philosophy and Social Science in Jiangsu Universities.
[2]. Devlin, J., Chang, M. W., Lee, K., et al. (2019). BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (pp. 4171-4186).
[3]. Ma, Tian, Guoliang Zhang, Xiaojun Guo. (2024). A Review of Natural Language Processing Attack and Defense Research on Deep Learning. School of Information Engineering, Tibet University for Nationalities, Xianyang 712082, Shaanxi, China.
[4]. Hao, W. K., Li, Z. C., Qian, Y. C., et al. (2020). The acl fws-rc: A dataset for recognition and classification of sentences about future works. In Proceedings of the ACM/IEEE Joint Conference on Digital Libraries in 2020 (pp. 261-269).
[5]. Yang, Xiyu. (2024). Research review and application prospect of semantic information retrieval based on word vector extension. Party School of Panzhihua Municipal Committee of the Communist Party of China, Panzhihua, Sichuan 617061.
[6]. Guan, B., Cai, R., & Cai, H. (2017). Application of Natural Language Processing in Information Retrieval. Information and Computer, China Computer & Communication, 11, 035-04.
[7]. Zhou, L., & Zhang, D. (2003). NLPIR: A Theoretical Framework for Applying Natural Language Processing to Information Retrieval. Journal of the American Society for Information Science and Technology, 54(2), 115-123.
[8]. Wang, C., Zhang, M., & Ma, S. (2007). Application of Natural Language Processing in Information Retrieval: A Review. Chinese Journal of Information, 21(2), 035-11.
[9]. Huang, E. B.. (2022). Research on Optimization Application of Spatial Information Retrieval Based on Natural Language Processing. Guangdong Provincial General Colleges and Universities Characteristic Innovation Project: Research on Knowledge Mapping Construction and Visualization Technology of Online Courses for Intelligent Education.