


Volume 176
Published on September 2025Volume title: Proceedings of the 3rd International Conference on Machine Learning and Automation
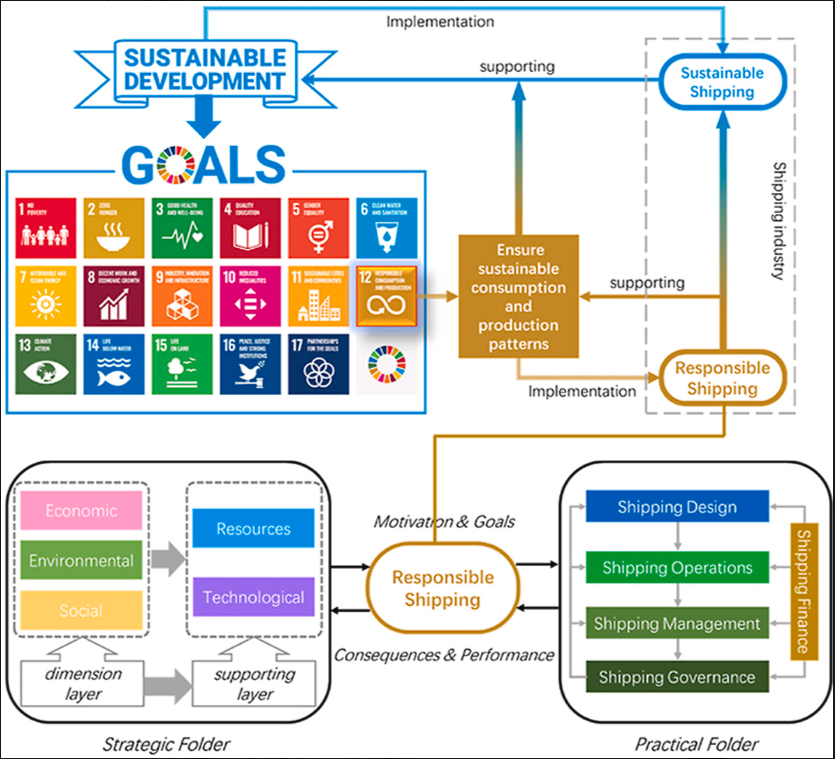
In corporate sustainable development practice, how to accurately align independently disclosed key performance indicators (KPIs) with the United Nations Sustainable Development Goals (SDGs) has long faced challenges such as ambiguous standards and complex operations. This research develops an intelligent analysis model. By integrating natural language processing and knowledge graph technology, it automatically maps ESG disclosure data and SDGs. The semantic analysis system, built from 200 cross-industry ESG reports, applies a text vectorization algorithm and dynamic weight adjustment mechanism, achieving a matching accuracy of 91% in identifying environmental governance indicators and a coverage rate of 86% in social indicators. The model innovatively introduces the GRI standard knowledge graph, effectively solving the problem of differences in information disclosure standards across industries. This system provides audit institutions with automated verification tools, assists regulators in establishing dynamic monitoring mechanisms, and promotes the transformation of companies' ESG practices from formal compliance to substantive innovation. The research results have practical value in breaking the current fragmented situation of information disclosure for sustainable development and provide technical support for building a reliable global accountability governance system.



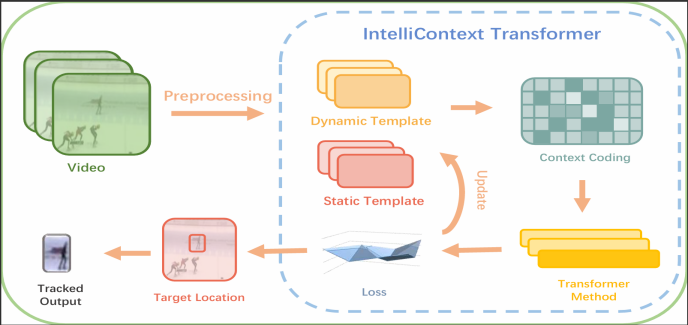
In video content analysis, accurate tracking and recognition of objects is a complex task. Current research has primarily focused on the development of complex scenes and fast-moving targets. Yet, there are challenges of small objects, long time-series dependencies, and object occlusion. In this paper, we propose the Intelli-context transformer to detect objects in a dynamic environment. Addressing this challenge, attention mechanisms, contextual information, and semantic information are integrated into Intelli-Context Transformer to enhance the accuracy of video object tracking. Intelli-Context Transformer employs an end-to-end training approach and incorporates a Contextual Spatiotemporal Attention Module, which dynamically adjusts the focus on different information to improve recognition accuracy. The proposed method is capable of capturing and analyzing the spatiotemporal features of a single target in videos in real time, effectively handling tracking tasks in complex scenes. Compared with state-of-the-art methods, Intelli-Context Transformer demonstrates its strong generalization capability in video object recognition. This research provides an efficient and reliable approach for dynamic target tracking in complex scenes and offers technical support for functions such as behavior analysis and anomaly detection, contributing to the development of intelligent video surveillance and navigation.
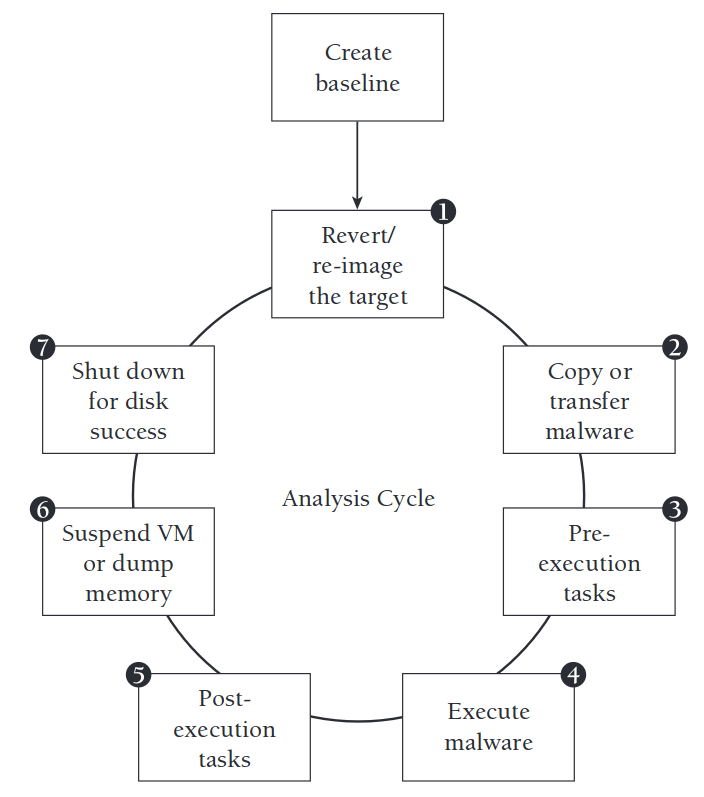
This study proposes a novel malware detection framework integrating dynamic and static analysis, and realizes the collaborative processing of bi-modal data through a unified graph neural network architecture. Specifically: extracting the control flow and data dependency features from binary disassembly, and capturing the system call sequence with time attributes in the sandbox environment; After encoding the two types of features into heterogeneous relationship graphs, a two-branch network is adopted to process the static topology (graph convolutional layer) and dynamic sequence (graph attention layer) respectively; Finally, the classification decision-making is achieved by the feature fusion module. In the benchmark test set of EMBER, VirusShare, and CIC-MalMem, the accuracy rate of the framework exceeded 95%, which is 4 to 7 percentage points higher than the single-modal baseline. The recall rate of unknown malware families remained above 92%, and the single-sample detection time was less than 50 milliseconds. The ablation experiment confirmed that static features effectively resist shell confusion and dynamic temporal attributes improve the recognition of distorted viruses. The current system has limitations on anti-sandbox detection technology. Further research suggests combining reinforcement learning to dynamically adjust the sandbox depth and introducing contractive learning to optimize the discriminative ability of graph embedding.
This study explores the application of generative artificial intelligence in the public service sector and its impact on social policies. By combining a systematic literature review and controllable scenario simulation, the technical and policy effectiveness of five typical scenarios (medical triage, welfare qualification review, driver's license renewal, municipal consultation, and emergency preparedness) were evaluated. The results show that the optimized model increased the response speed by 70% and the manual verification success rate reached 88%. The simulation calculation shows that the initial resolution rate increased by 40% and the policy development cycle was shortened by ten days. Despite the significant improvement in efficiency, occasional content distortions were observed in the model, while revealing governance challenges in terms of fairness, transparency, and accountability. Based on this, it is proposed to implement three measures: hierarchical manual supervision, continuous algorithm auditing, and dynamic regulatory sandboxes, to achieve responsible technology deployment. This study, for the first time, verified the correlation mechanism between generative AI performance and policy indicators through experimental data, providing an operational solution to equip technological innovation and institutional safeguards. Detailed simulation parameters are provided in Appendix B.
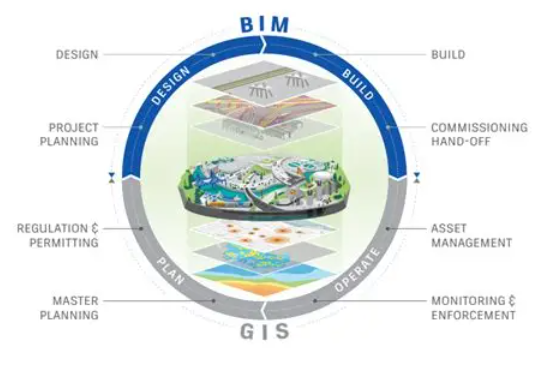
Smart buildings generate massive spatial and operational data, but existing facility management systems are often not fully utilized due to the separation of geographic information system (GIS) and building information modeling (BIM) platforms. This paper proposes a data integration framework integrating GIS and BIM, providing support for AI-driven predictive maintenance and dynamic inventory management of smart buildings. By aligning the Internet of Things sensor data with the fine-grained BIM asset model and GIS spatial background, this system constructs rich feature vectors and introduces the gradient hoist stacked model and long short-term memory network to achieve accurate fault time prediction. Meanwhile, the prediction results stimulate the real-time dynamic replenishment strategy and adjust the spare parts inventory threshold. For large commercial facilities, this method reduced the mean absolute error of defect prediction at 12 hours (a 30% increase over the baseline model), reduced the inventory shortage rate by 40%, and reduced the number of inventory days on hand by 25%. Overall, this integration solution accelerated maintenance response by 20% and saved an average of US$50,000 in annual holding costs. These achievements demonstrate the value of GIS-BIM integration in promoting the shift from passive operations and maintenance to active and efficient supply chain strategies. Subsequent work will focus on real-time flow processing and the multi-facility collaboration mechanism.
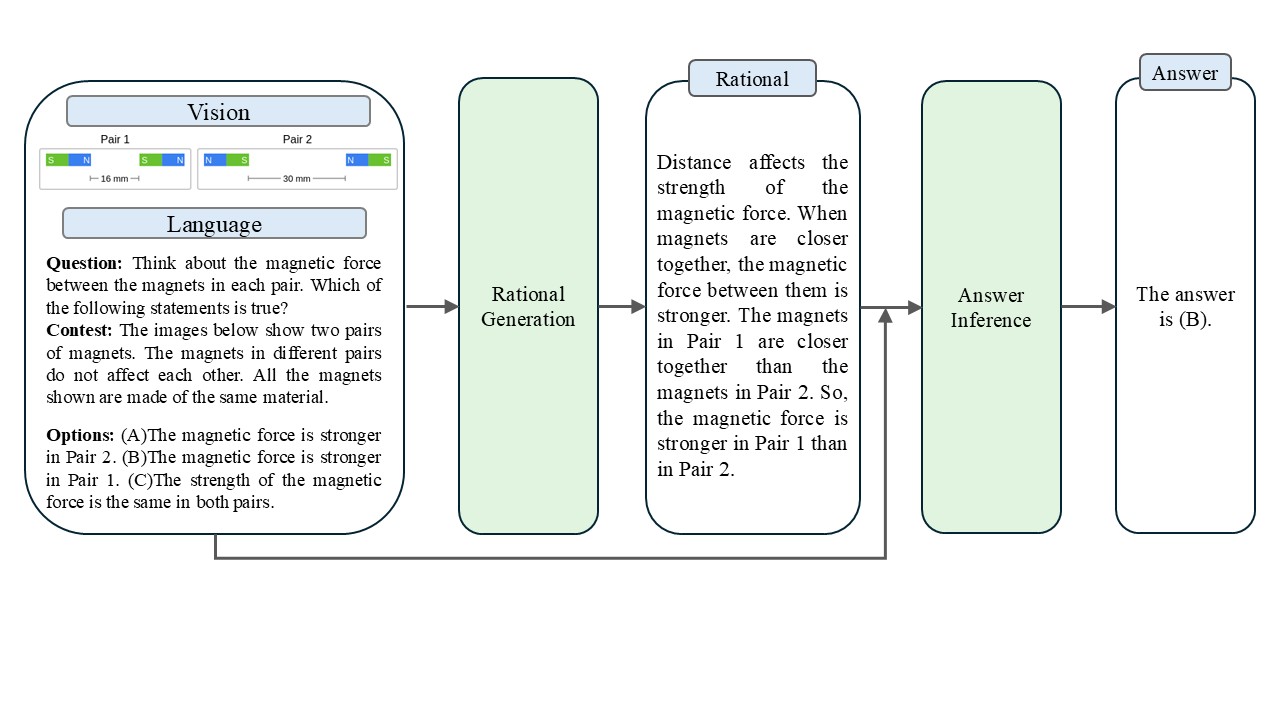
Chain-of-Thought (CoT) reasoning enhances the performance of large language models (LLMs) on complex tasks such as solving mathematical problems, logical inference, and question answering by guiding models to generate intermediate reasoning steps rather than directly producing final answers. This approach simulates human-like, step-by-step thinking, significantly improving the stability and accuracy of the reasoning process. By moving beyond the “black box" nature of traditional LLM outputs, CoT also lays the foundation for more controllable and multimodal reasoning. However, most existing research has focused on unimodal (text-only) CoT, leaving the multimodal setting underexplored. Multimodal CoT (MMCoT) addresses this gap by separating rationale generation and answer inference through a two-stage architecture that integrates visual and textual inputs. However, due to the limited semantic richness of visual features extracted by the Vision Transformer (ViT), its performance remains suboptimal. In this work, we propose C-MMCoT, a model that leverages CLIP-extracted visual features to generate rationales, thereby enhancing the semantic alignment of visual reasoning. Experiments on the ScienceQA test set demonstrate that C-MMCoT outperforms baseline models. Compared to GPT-4, it achieves higher accuracy on key categories such as SOC, TXT, and IMG, culminating in an overall accuracy that is 0.57 percentage points higher.
Scientifically assessing the true effect of government subsidies on the performance of agricultural enterprises and deeply revealing its mechanism of action and restrictive factors holds significant theoretical and practical value for optimizing agricultural policy design, enhancing the efficiency of fiscal resource allocation, and promoting high-quality agricultural development. To precisely analyze this impact, this study innovatively designed a Transformer classification algorithm that integrates adaptive feature interaction and adversarial robustness. Through empirical testing with four sets of comparison models including random forest, decision tree, XGBoost, and CatBoost, the results show that in the benchmark model, XGBoost has the best predictive performance with an accuracy rate of 85.3%. However, the new model proposed in this paper has achieved significant improvements in key performance indicators: accuracy (Accuracy) increased by 3.6%, recall (Recall) improved by 4.3%, precision (Precision) rose by 3.9%, and the F1 score increased by 4.1%. This research not only provides advanced analytical tools and empirical evidence for a deeper understanding of the complex relationship between government subsidies and the performance of agricultural enterprises but also offers important data support and decision-making references for precise policy implementation to enhance subsidy effectiveness and promote agricultural modernization.
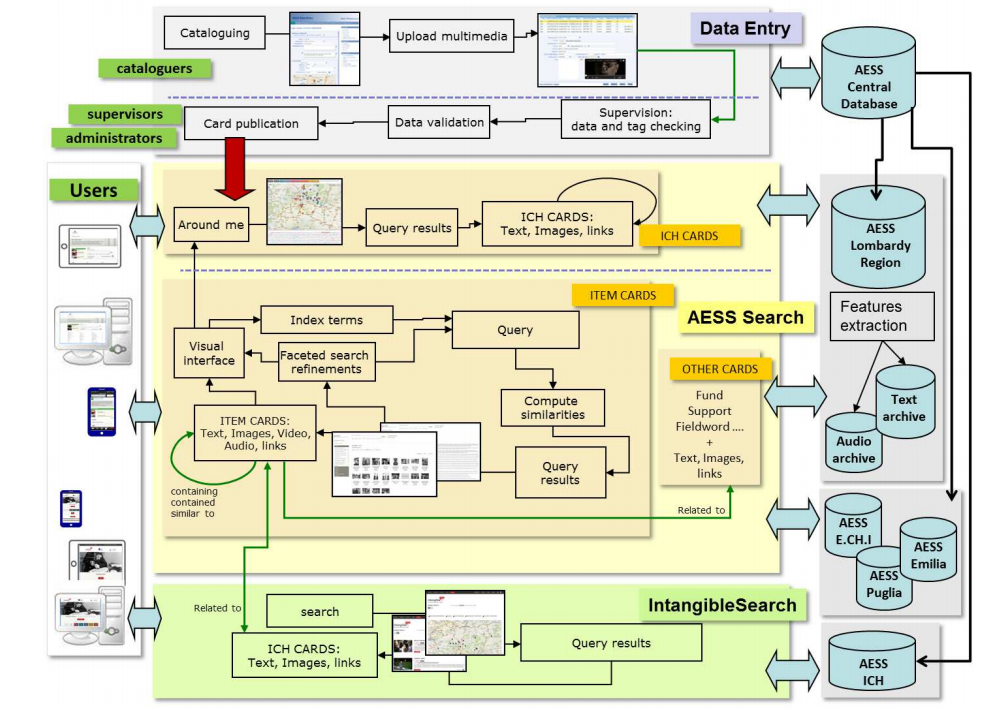
Safeguarding intangible heritage music increasingly depends on endtoend digital value chains that can faithfully model, generate, track, and remunerate culturally embedded musical knowledge. This paper proposes a generative AI framework that jointly (i) learns a multilayer, ethnomusicologyaware representation across raw audio, symbolic structure, and contextual metadata, (ii) constrains a controllable transformer–diffusion pipeline to preserve modality, microtonal tuning, ornamentation practice, and rhythmic grammar, and (iii) embeds blockchainanchored provenance and smartcontract royalty logic inside the creative pipeline. Using 1,842 recordings (126.3 hours) spanning Southeast Asian gamelan, Chinese Buddhist chant, and Andean panpipe repertoires, we compare our system against an archiveonly baseline and an unconditioned generative baseline. Conditioned generation reduces average modal deviation from canonical tunings from 12.3 ± 4.1 cents to 4.9 ± 1.8 cents, decreases rhythmic dynamictimewarping distance by 44.5%, and raises expert authenticity ratings from 3.12 ± 0.61 to 4.47 ± 0.28 (ICC(2,k)=0.82). On the valuechain layer, median royalty settlement time drops from 23.7 days to 1.92 days, the Theil inequality index falls from 0.218 to 0.071, and Jain’s fairness index rises from 0.63 to 0.89. Listenerside evaluation shows higher longtail coverage (+31.4%), improved NDCG@20 (0.382→0.497), and a 26% reduction in the hazard of early session abandonment. The findings demonstrate that culturally bounded, rightssensitive generative pipelines can simultaneously enhance preservation fidelity, creative reuse, and equitable community remuneration.

In the field of target detection, underwater target detection (UTD) still faces many challenges. Although YOLO11 shows excellent real-time detection performance, its direct application in UTD is not satisfactory because it has not been designed for complex scenarios such as excessive object deformation and blurred lighting in underwater environments, and is unable to fully extract and utilize the effective information in images, resulting in low detection accuracy. To overcome this drawback, we developed a new detection model SUD-YOLO (Stable Underwater Detection) based on YOLOv11 to improve the detection accuracy and stability for underwater objects. Compared with YOLOv11, SUD-YOLO provides SRFD (Shallow Robust Feature Downing-sampling) and DRFD (Deep Robust Feature Downing-sampling) modules, which alleviate the problem of important information loss during the deep propagation process due to sampling (Upsampling and Downsampling) or multi-layer convolution by input feature scaling fusion. At the same time, EfficientHead is adopted instead of the traditional mixed detection head to ensure that the output features are not mutually dependent. Experimental results on the URPC2020, Luderick and Deepfish datasets prove that SUD-YOLO has higher stability and faster convergence during training, demonstrating excellent UTD performance. This research proposes an efficient and reliable method for UTD tasks, providing technical support for underwater exploration and marine resource investigation, and contributing to the development of underwater intelligent detection.

This study proposes the integration of BiFPN feature pyramid and CBAM attention module in YOLOv8 to enhance the robustness of traffic sign and signal detection, based on the urgent need for urban road safety and autonomous driving. The experiment was validated on a test set of 801 images and 944 targets, and the overall precision of the model reached 0.739, Recall 0.654,mAP50 0.723,mAP50-95 0.631, Significantly better than the baseline, with improvements of 5.2%, 1%, 2.8%, and 2.15% respectively, confirming that the improvement strategy effectively reduces false positives and improves localization classification consistency. The subdivision results show that the Stop logo achieves almost zero missed detections due to its high contrast and regular shape, with Precision and mAP50 both approaching 1; The mAP50 of the three speed limits of 20, 60, and 70 km/h all exceeded 0.82 under sufficient sample conditions, and remained above 0.75 on the stricter mAP50-95 index, indicating good generalization to scale and lighting changes; Although data is scarce for speed limits of 100 and 120 km/h, mAP50 still reaches 0.77 and 0.85, indicating that the network has fully learned the common features of circular speed limit signs; In contrast, signal lights such as Red Light have a small scale and complex background, with mAP50-95 less than 0.35 and low recall, making them a key focus for future optimization. Overall, the current model has matured for high contrast and regular shape signs. The next step should be to focus on improving the recall rate of small sample categories and traffic lights through difficult case mining, multi-scale training, and targeted data augmentation. The gap between mAP50 and mAP50-95 should be narrowed at higher IoU thresholds to meet the high reliability requirements of real road scenes. This study not only validates the effectiveness of BiFPN+CBAM in traffic sign detection, but also provides a reference for improving low sample category and small object detection, which has positive significance for promoting the safe implementation of intelligent transportation systems and autonomous driving.