







1. Introduction
Object tracking, as an important branch of computer vision, aims to analyze videos to identify and track objects belonging to one or more categories. In recent years, it has received increasing attention and importance. Traditional object detection aims to identify objects within an image and generate a bounding box to mark the objects of interest. Digital video, however, is a collection of static image frames arranged in a certain temporal sequence. Each frame, as the smallest unit, contains RGB two-dimensional image information. Unlike traditional image object detection, object tracking emphasizes finding the trajectory of an object's position within a sequence [1]. The integration of information across frames, background information of the target, and intrinsic features of the object itself is referred to as context information [2]. The selection of video frames and the handling of context information play a crucial role in improving the accuracy of video object detection.
Significant progress has been made in object detection over the past decade, from early CNN-based methods to current approaches such as ResNet [3]. Object tracking, as a subsequent task, includes both traditional and modern optical flow methods (e.g., FGFA), YOLO, and deep learning-based multi-object detection approaches [4]. However, existing object tracking faces challenges such as track creation, re-identification (ReID) [5], and complex detail expression [6], which make video object detection in real-world applications more challenging. The introduction of Transformer architecture has been a recent significant advancement, showing strong robustness in handling variable-length inputs and target occlusion..
The Self-Attention mechanism of the Transformer can capture dependencies between features on a global scale, unlike CNNs, which are limited to local receptive fields. This global perceptual ability is especially important for tasks involving long-range dependencies [7]. Due to the transformer’s excellent capability in handling sequential data, it has been applied to object tracking and has demonstrated good performance in visual target tracking [8]. In object tracking, the design of dynamic and static templates aims to address the issue of how the object changes and is effectively tracked throughout the video sequence. The dynamic template is used to capture features under dynamic changes, while the static template captures the fixed parts of the target. By combining the contextual information from both, the Transformer model can update the dynamic changes of the target in each frame while maintaining its static features for better object matching. Subsequently, Transformer-based improved models began to emerge, such as SwinTrack [9], which improved input image size and proposed a local window self-attention mechanism to reduce computational complexity, and MixFormer [10], which adopted a more efficient hybrid mechanism that allows the model to share information across multiple modalities. These networks further optimized feature extraction, temporal modeling, and matching strategies, making Transformer a mainstream approach in the field of object tracking.
Despite significant progress in video object tracking, object detection and tracking remain major challenges. The root cause of the problem lies in attention allocation for contextual information and instability in long video object tracking. To address these issues, we propose a novel adaptive attention allocation strategy, Intelli-Context Transformer (ICT), an end-to-end strategy that leverages a Transformer-based Contextual Spatiotemporal Attention Module (CSAM) to improve object detection accuracy. It can adaptively adjust attention scores for object-related information, enhancing both computational efficiency and accuracy.
The main contributions of this study are as follows:
• We propose an adaptive attention allocation strategy to enhance the accuracy and stability of video object tracking.
• We introduce the CSAM based on the Transformer architecture, which strengthens the model’s ability to capture spatiotemporal context information in video sequences.
• We evaluate proposed method on Single Object Tracking (SOT) challenge datasets. The evaluation results show significant advantages in both tracking accuracy and computational efficiency of our method.
2. Related work
Video object recognition is a critical task in computer vision, aiming to identify and track target objects from video sequences. Over the past decade, video object recognition algorithms have made significant progress, largely due to the rapid development of deep learning. In 2015, Shaoqing Ren et al. proposed Faster R-CNN based on convolutional neural networks [11], which achieved high detection accuracy but had slower speed and was primarily used for static object detection. In 2016, Bewley et al. introduced the Simple Online and Realtime Tracking (SORT) algorithm [12] for dynamic tracking. This algorithm combines a Kalman filter and the Hungarian algorithm for real-time object tracking and replaces the detection results computed by Faster R-CNN with those obtained using Aggregated Channel Features (ACF) [13].
In 2017, the introduction of Graph Convolutional Networks (GCN) [14] by Thomas Kipf and others marked an expansion of convolutional neural network applications, opening a new chapter in the field of Graph Neural Networks (GNNs). In the same year, Ashish Vaswani et al. proposed the Transformer architecture [15], which discarded traditional recurrent neural networks (RNNs) and convolutional neural networks (CNNs), using self-attention mechanisms to model the relationships between input data, particularly the long-range dependencies in sequential data. In 2018, Zhang et al. proposed a tracking method based on the Spatio-Temporal Graph Convolutional Networks (ST-MAP) [16], which focused on the temporal continuity of object behaviors. ST-MAP treated video frames as nodes in a graph and connected adjacent frames using graph convolution operations, thereby incorporating more temporal contextual information to improve object detection performance.
Also in 2018, Joseph Redmon et al. introduced YOLOv3 [17], which improved upon the shortcomings of the previous versions in multi-scale feature detection. It adopted the concept of Feature Pyramid Networks (FPN) [18] and used Darknet-53 as the backbone network [19] to extract more features, significantly improving the model's accuracy. In 2020, Nicolas Carion et al. introduced Detection Transformers (DETR) [20], which was the first application of Transformers in video object detection. By utilizing the self-attention mechanism, DETR performed global context modeling, laying the foundation for subsequent applications of Transformers in video object tracking..
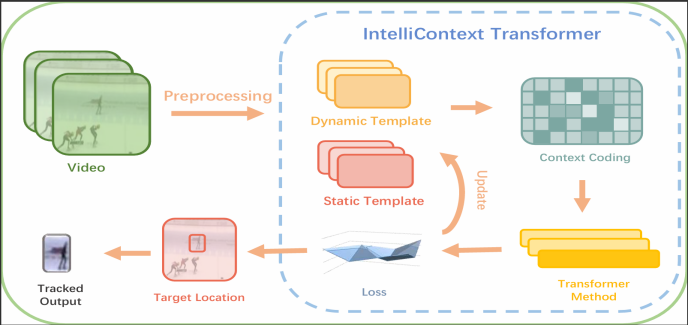
3. Methodology
As shown in Figure 1, this work develops an innovative video object detection and tracking method by utilizing cutting-edge technology. It integrates spatial and temporal information of moving objects through a self-attention module to enhance tracking accuracy. The model incorporates more contextual information into tokens and deeply learns the target’s appearance and motion patterns, optimizing the robustness and accuracy of object tracking.
3.1. Data preprocessing
The preprocessing of video frame data includes grayscale conversion, image masking, and dynamic-static image fusion. The color video is converted into grayscale to reduce the data dimensions. Image masking techniques are applied to enhance the edge information, improving the clarity of object contours and recognition accuracy. To fully utilize the temporal information in the video frames, the frames are divided into dynamic image
3.2. Intelli-context transformer
This study proposes an innovative Transformer architecture, called Intelli-Context Transformer (ICT), aimed at improving the accuracy of video object tracking by integrating attention mechanisms, contextual information, and semantic cues. The core of ICT lies in its adaptive attention allocation strategy, which dynamically adjusts the attention to different information to adapt to the complexity of the video content. The ICT model is trained end-to-end, combining position prediction errors and feature alignment scores to ensure that the model can effectively learn to track objects across different video sequences.
ICT is based on the standard transformer architecture but introduces the CSAM. The self-attention mechanism in Transformer is as follows:
where
In ICT, we perform feature extraction through 12 transformer layers, each followed by a residual connection after the MLP to accelerate training speed and improve model generalization. To further reduce the computational load and enhance the model's speed, we prune the computed tokens by calculating the similarity matrix of the tokens and retaining the top
where
Additionally, ICT normalizes after the LayerNorm (LN) layer to accelerate training speed. For the pruned tokens, we apply zero-padding and flatten them into a 5x5 tensor for further processing. The ICT tracking head consists of a Score Head, Offset Head, and Size Head, responsible for calculating the tracking score, optimizing the position on the score map, and adjusting the offset of the bounding box size. Through this structure, ICT effectively captures the dynamic changes of the target and maintains stable tracking performance in complex video environments.
Contextual Spatiotemporal Attention Module
The CSAM module calculates the attention weight for each token as follows:
where
The operation for fusing semantic and contextual features is represented as:
where
4. Experiment
4.1. Datasets
GOT-10k is a large-scale generic object tracking dataset, containing over 10,000 video sequences, with each sequence averaging 300 frames, totaling more than 3 million frames. The dataset provides precise annotations for the target bounding boxes and covers a wide range of scenes, object types, and challenges, such as deformation, occlusion, and lighting changes, making it ideal for evaluating and comparing the performance of object tracking algorithms.
Due to the common limitation in temporal sampling of traditional object tracking models, we sampled the dataset every 200 frames and divided the sampled video frames into dynamic and static images through preprocessing methods, incorporating more contextual information to improve tracking accuracy.
4.2. Experimental setup
1) Evaluation Metrics: To evaluate the tracking accuracy, we used the following matching measures between the predicted target bounding boxes and the ground truth boxes.
a) Average Overlap (AO)
This metric computes the average overlap between the predicted target box and the ground truth box for each frame, where
b) Area Under the Curve (AUC)
This metric plots the success rate (SR) against the
In quantifying the results, the following metrics were used to determine the model's accuracy:
c) Success Rate (SR)
This metric measures the proportion of frames in which the tracking model successfully tracks the object within the video sequence.
2) Implementation Details: All experiments are conducted on the Nvidia GeForce 2080Ti GPU using the PyTorch framework. All models are trained for 300 epochs, and the batch size is set to 32. Each training period samples 60,000 frames, and each validation period samples 10,000 frames. Training results are printed every 50 steps. The learning rate is initialized to 0.0004 with a step decay factor of 0.1, and the AdamW is used. The learning rate decay is enabled after 240 epochs. The loss function uses
4.3. Analysis results
In this study, the proposed ICT is compared with the two methods SwinTrack and AQATrack[21]. SwinTrack uses Swin Transformer as the backbone network and has certain performance in target tracking tasks. AQATrack is a Transformer-based target tracking method. By comparing these two methods on the GOT-10K dataset, the ability of the ICT model in terms of tracking accuracy and model efficiency can be comprehensively evaluated.
Experimental results are shown in Table 1. Proposed ICT shows excellent performance on the GOT-10K dataset. Its average overlap rate (AO) reaches 74.1%, 3.2% and 0.3% higher than SwinTrack and AQATrack, respectively. In terms of success rate metrics, ICT's
|
Method |
AO (%) |
|
|
|
SwinTrack |
70.9 |
81.2 |
64.9 |
|
AQATrack |
73.8 |
83.2 |
72.1 |
|
ICT (ours) |
74.1 |
84.3 |
72.4 |
|
Method |
Backbone |
Number of Parameters (M) |
Speed(fps) |
|
SwinTrack |
Swin Transformer |
22.7 |
98 |
|
AQATrack |
Transformer |
72 |
67.6 |
|
ICT (ours) |
Transformer |
48.9 |
94.2 |
Table 2 compares the architectures of each model. The ICT uses Transformer as the backbone, with a parameter number of 48.9M, which is less than 72M of AQATrack, while maintaining a high speed, reaching 94.2fps, close to SwinTrack's 98fps. This shows that the ICT model has achieved a good balance between model efficiency and performance and is more practical.
Fig.2 shows the success rate curves of each model on the GOT-10K dataset. It can be seen that the curve of the ICT is above the entire overlap threshold range, especially in the high overlap threshold area, with more obvious advantages. This further verifies the tracking capability of the ICT model in complex scenarios.
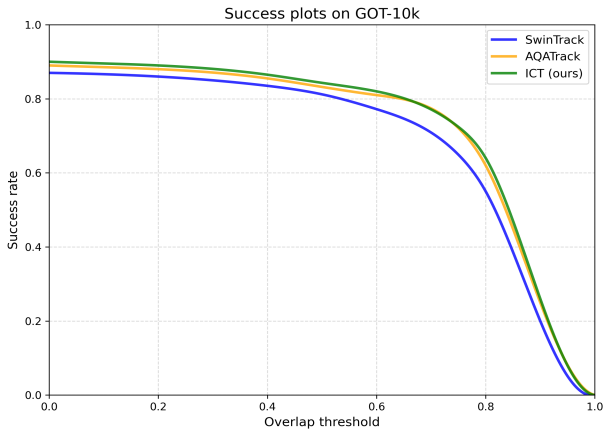
Fig.3 shows the attention graph comparison of CSAM on the GOT-10k dataset. CSAM accurately focuses on the target key areas and suppresses background interference through self-attention. As can be seen from the figure, the self-attention mechanism of the ICT model can focus more accurately on the target area and match the real labels more accurately.

5. Conclusion and future works
The proposed ICT in this study is based on the Transformer architecture for video target tracking. It achieves performance superior to existing models through sampling every 200 frames and preprocessing of dynamic and static images on the GOT-10K dataset and combining appropriate evaluation indicators and training strategies. In terms of quantitative indicators,
References
[1]. O. Abdelaziz, M. Shehata, and M. Mohamed, “Beyond traditional single object tracking: A survey, ” 2024, arXiv: 2405.10439. [Online]. Available: https: //arxiv.org/abs/2405.10439
[2]. X. Wang and Z. Zhu, “Context understanding in computer vision: A survey, ” Comput. Vis. Image Underst., vol. 229, p. 103646, Mar. 2023, doi: 10.1016/j.cviu.2023.103646.
[3]. S. S. A. Zaidi, M. S. Ansari, A. Aslam, N. Kanwal, M. Asghar, and B. Lee, “A survey of modern deep learning based object detection models, ” 2021, arXiv: 2104.11892. [Online]. Available: https: //arxiv.org/ abs/2104.11892
[4]. G. Ciaparrone, F. Luque Sánchez, S. Tabik, L. Troiano, R. Tagliaferri, and F. Herrera, “Deep learning in video multi-object tracking: A survey, ” Neurocomputing, vol. 381, pp. 61–88, Mar. 2020, doi: 10.1016/j.neucom.2019.11.023.
[5]. A. Kamboj, “The progression of transformers from language to vision to MOT: A literature review on multi-object tracking with transformers, ” 2024, arXiv: 2406.16784. [Online]. Available: https: //arxiv.org/ abs/2406.16784
[6]. H. Ouyang, Q. Wang, Y. Xiao, Q. Bai, J. Zhang, K. Zheng, X. Zhou, Q. Chen, and Y. Shen, “Codef: Content deformation fields for temporally consistent video processing, ” 2023.
[7]. A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, "Attention is all you need, " in Proc. 31st Int. Conf. Neural Inf. Process. Syst. (NIPS 2017), pp. 6000–6010, Dec. 2017.
[8]. W. G. C. Bandara and V. M. Patel, “A transformer-based Siamese network for change detection, ” 2022, arXiv: 2201.01293. [Online]. Available: https: //arxiv.org/abs/2201.01293
[9]. L. Lin, H. Fan, Z. Zhang, Y. Xu, and H. Ling, “SwinTrack: A simple and strong baseline for transformer tracking, ” 2022, arXiv: 2112.00995. [Online]. Available: https: //arxiv.org/abs/2112.00995
[10]. Y. Cui, C. Jiang, L. Wang, and G. Wu, “MixFormer: End-to-end tracking with iterative mixed attention, ” 2022, arXiv: 2203.11082. [Online]. Available: https: //arxiv.org/abs/2203.11082
[11]. S. Ren, K. He, R. Girshick, and J. Sun, "Faster R-CNN: towards real-time object detection with region proposal networks, " 2016, arXiv: 1506.01497. [Online]. Available: https: //arxiv.org/ abs/1506.01497
[12]. A. Bewley, Z. Ge, L. Ott, F. Ramos, and B. Upcroft, "Simple online and realtime tracking, " in 2016 IEEE Int. Conf. Image Process. (ICIP), pp. 3464-3468, Sep. 2016, doi: 10.1109/ICIP.2016.7533003.
[13]. G. Ciaparrone, F. Luque Sánchez, S. Tabik, L. Troiano, R. Tagliaferri, and F. Herrera, "Deep learning in video multi-object tracking: A survey, " Neurocomputing, vol. 381, pp. 61-88, Mar. 2020, doi: 10.1016/j.neucom.2019.11.023.
[14]. T. N. Kipf and M. Welling, "Semi-supervised classification with graph convolutional networks, " 2017, arXiv: 1609.02907. [Online]. Available: https: //arxiv.org/abs/1609.02907
[15]. A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, "Attention is all you need, " 2017, arXiv: 1706.03762. [Online]. Available: https: //arxiv.org/abs/ 1706.03762
[16]. B. Yu, H. Yin, and Z. Zhu, "Spatio-temporal graph convolutional networks: a deep learning framework for traffic forecasting, " in Proc. 27th Int. Joint Conf. Artif. Intell. (IJCAI), pp. 3634-3640, Jul. 2018, doi: 10.24963/ijcai.2018/505.
[17]. J. Redmon, S. Divvala, R. Girshick, and A. Farhadi, "You only look once: unified, real-time object detection, " 2016, arXiv: 1506.02640. [Online]. Available: https: //arxiv.org/abs/1506.02640
[18]. T.-Y. Lin, P. Dollár, R. Girshick, K. He, B. Hariharan, and S. Belongie, "Feature pyramid networks for object detection, " 2017, arXiv: 1612.03144. [Online]. Available: https: //arxiv.org/abs/ 1612.03144
[19]. J. Redmon and A. Farhadi, "YOLOv3: an incremental improvement, " 2018, arXiv: 1804.02767. [Online]. Available: https: //arxiv.org/abs/ 1804.02767
[20]. N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, and S. Zagoruyko, "End-to-end object detection with transformers, " 2020, arXiv: 2005.12872. [Online]. Available: https: //arxiv.org/abs/ 2005.12872
[21]. J. Xie, B. Zhong, Z. Mo, S. Zhang, L. Shi, S. Song and R. Ji, “Autoregressive Queries for Adaptive Tracking with Spatio-Temporal Transformers, ” IEEE, 2024, DOI: 10.1109/CVPR52733.2024.01826.
Cite this article
Wang,Y. (2025). Moving Object Tracking Using Context-Aware Attention Transformer. Applied and Computational Engineering,176,8-15.
Data availability
The datasets used and/or analyzed during the current study will be available from the authors upon reasonable request.
Disclaimer/Publisher's Note
The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of EWA Publishing and/or the editor(s). EWA Publishing and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content.
About volume
Volume title: Proceedings of the 3rd International Conference on Machine Learning and Automation
© 2024 by the author(s). Licensee EWA Publishing, Oxford, UK. This article is an open access article distributed under the terms and
conditions of the Creative Commons Attribution (CC BY) license. Authors who
publish this series agree to the following terms:
1. Authors retain copyright and grant the series right of first publication with the work simultaneously licensed under a Creative Commons
Attribution License that allows others to share the work with an acknowledgment of the work's authorship and initial publication in this
series.
2. Authors are able to enter into separate, additional contractual arrangements for the non-exclusive distribution of the series's published
version of the work (e.g., post it to an institutional repository or publish it in a book), with an acknowledgment of its initial
publication in this series.
3. Authors are permitted and encouraged to post their work online (e.g., in institutional repositories or on their website) prior to and
during the submission process, as it can lead to productive exchanges, as well as earlier and greater citation of published work (See
Open access policy for details).
References
[1]. O. Abdelaziz, M. Shehata, and M. Mohamed, “Beyond traditional single object tracking: A survey, ” 2024, arXiv: 2405.10439. [Online]. Available: https: //arxiv.org/abs/2405.10439
[2]. X. Wang and Z. Zhu, “Context understanding in computer vision: A survey, ” Comput. Vis. Image Underst., vol. 229, p. 103646, Mar. 2023, doi: 10.1016/j.cviu.2023.103646.
[3]. S. S. A. Zaidi, M. S. Ansari, A. Aslam, N. Kanwal, M. Asghar, and B. Lee, “A survey of modern deep learning based object detection models, ” 2021, arXiv: 2104.11892. [Online]. Available: https: //arxiv.org/ abs/2104.11892
[4]. G. Ciaparrone, F. Luque Sánchez, S. Tabik, L. Troiano, R. Tagliaferri, and F. Herrera, “Deep learning in video multi-object tracking: A survey, ” Neurocomputing, vol. 381, pp. 61–88, Mar. 2020, doi: 10.1016/j.neucom.2019.11.023.
[5]. A. Kamboj, “The progression of transformers from language to vision to MOT: A literature review on multi-object tracking with transformers, ” 2024, arXiv: 2406.16784. [Online]. Available: https: //arxiv.org/ abs/2406.16784
[6]. H. Ouyang, Q. Wang, Y. Xiao, Q. Bai, J. Zhang, K. Zheng, X. Zhou, Q. Chen, and Y. Shen, “Codef: Content deformation fields for temporally consistent video processing, ” 2023.
[7]. A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, "Attention is all you need, " in Proc. 31st Int. Conf. Neural Inf. Process. Syst. (NIPS 2017), pp. 6000–6010, Dec. 2017.
[8]. W. G. C. Bandara and V. M. Patel, “A transformer-based Siamese network for change detection, ” 2022, arXiv: 2201.01293. [Online]. Available: https: //arxiv.org/abs/2201.01293
[9]. L. Lin, H. Fan, Z. Zhang, Y. Xu, and H. Ling, “SwinTrack: A simple and strong baseline for transformer tracking, ” 2022, arXiv: 2112.00995. [Online]. Available: https: //arxiv.org/abs/2112.00995
[10]. Y. Cui, C. Jiang, L. Wang, and G. Wu, “MixFormer: End-to-end tracking with iterative mixed attention, ” 2022, arXiv: 2203.11082. [Online]. Available: https: //arxiv.org/abs/2203.11082
[11]. S. Ren, K. He, R. Girshick, and J. Sun, "Faster R-CNN: towards real-time object detection with region proposal networks, " 2016, arXiv: 1506.01497. [Online]. Available: https: //arxiv.org/ abs/1506.01497
[12]. A. Bewley, Z. Ge, L. Ott, F. Ramos, and B. Upcroft, "Simple online and realtime tracking, " in 2016 IEEE Int. Conf. Image Process. (ICIP), pp. 3464-3468, Sep. 2016, doi: 10.1109/ICIP.2016.7533003.
[13]. G. Ciaparrone, F. Luque Sánchez, S. Tabik, L. Troiano, R. Tagliaferri, and F. Herrera, "Deep learning in video multi-object tracking: A survey, " Neurocomputing, vol. 381, pp. 61-88, Mar. 2020, doi: 10.1016/j.neucom.2019.11.023.
[14]. T. N. Kipf and M. Welling, "Semi-supervised classification with graph convolutional networks, " 2017, arXiv: 1609.02907. [Online]. Available: https: //arxiv.org/abs/1609.02907
[15]. A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, "Attention is all you need, " 2017, arXiv: 1706.03762. [Online]. Available: https: //arxiv.org/abs/ 1706.03762
[16]. B. Yu, H. Yin, and Z. Zhu, "Spatio-temporal graph convolutional networks: a deep learning framework for traffic forecasting, " in Proc. 27th Int. Joint Conf. Artif. Intell. (IJCAI), pp. 3634-3640, Jul. 2018, doi: 10.24963/ijcai.2018/505.
[17]. J. Redmon, S. Divvala, R. Girshick, and A. Farhadi, "You only look once: unified, real-time object detection, " 2016, arXiv: 1506.02640. [Online]. Available: https: //arxiv.org/abs/1506.02640
[18]. T.-Y. Lin, P. Dollár, R. Girshick, K. He, B. Hariharan, and S. Belongie, "Feature pyramid networks for object detection, " 2017, arXiv: 1612.03144. [Online]. Available: https: //arxiv.org/abs/ 1612.03144
[19]. J. Redmon and A. Farhadi, "YOLOv3: an incremental improvement, " 2018, arXiv: 1804.02767. [Online]. Available: https: //arxiv.org/abs/ 1804.02767
[20]. N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, and S. Zagoruyko, "End-to-end object detection with transformers, " 2020, arXiv: 2005.12872. [Online]. Available: https: //arxiv.org/abs/ 2005.12872
[21]. J. Xie, B. Zhong, Z. Mo, S. Zhang, L. Shi, S. Song and R. Ji, “Autoregressive Queries for Adaptive Tracking with Spatio-Temporal Transformers, ” IEEE, 2024, DOI: 10.1109/CVPR52733.2024.01826.