







1. Introduction
In today's globalized world, the ability to retrieve information across different languages is increasingly important. Multilingual Information Retrieval (MLIR) systems are designed to meet this need by enabling users to search and access relevant information regardless of language barriers. Among the various techniques in MLIR, Cross-Language Information Retrieval (CLIR) stands out due to its ability to handle queries in one language and retrieve documents in another. This paper focuses on three primary techniques in CLIR: query translation, document translation, and hybrid approaches. Query translation involves converting the user's query from the source language into the target language using tools like bilingual dictionaries or machine translation systems. Bilingual dictionaries provide direct word-to-word translations but often lack contextual understanding, which can lead to inaccuracies. Machine translation systems, such as Google Translate, use advanced neural networks to generate more contextually appropriate translations, though they can struggle with domain-specific jargon and idiomatic expressions. Document translation, on the other hand, translates documents from the target language into the source language, allowing users to search within their native linguistic framework. Techniques like Statistical Machine Translation (SMT) and Neural Machine Translation (NMT) are commonly used for this purpose. NMT, particularly the Transformer model, has revolutionized document translation by preserving the meaning and context of the original text, significantly improving retrieval performance. Hybrid approaches combine elements of both query and document translation to optimize retrieval performance. These approaches leverage the strengths of each method while mitigating their individual limitations. For example, a hybrid system might translate the query into the target language, retrieve relevant documents, and then translate the top-ranked documents back into the source language for user evaluation [1]. This dual translation process ensures users receive relevant information while minimizing translation errors. Our study evaluates these techniques using various metrics, including precision, recall, F1 score, and user satisfaction. We present a comparative analysis showing that hybrid systems consistently outperform standalone query or document translation systems across different language pairs and domains. This paper highlights the practical benefits and versatility of hybrid approaches in MLIR, offering insights into future research directions for enhancing multilingual access to information.
2. Query Translation
2.1. Techniques and Tools
Query translation is one of the most straightforward approaches to CLIR. It involves translating the user's query from the source language into the target language using tools like bilingual dictionaries or machine translation systems. Bilingual dictionaries offer a simple yet effective means of translation by providing direct word-to-word translations. However, they often lack the contextual understanding needed for accurate translation. For instance, translating the English word "bank" to French using a bilingual dictionary might yield "banque," which refers to a financial institution, missing the context if the intended meaning was the side of a river. Machine translation systems, such as Google Translate, leverage advanced neural networks to provide more contextually relevant translations. These systems use large parallel corpora to train models that understand and generate translations that are semantically appropriate. Despite their advantages, machine translation systems can struggle with domain-specific jargon and idiomatic expressions, leading to inaccuracies in query translation. For example, a study found that translating medical queries using Google Translate resulted in a 12% error rate due to the complex and specific nature of medical terminology [2]. Table 1 compares the effectiveness of two translation tools used in Cross-Language Information Retrieval (CLIR): bilingual dictionaries and machine translation systems, specifically Google Translate.
Table 1. Comparison of Translation Tools
Translation Tool | Contextual Understanding | Translation Example | Domain-specific Jargon | Idiomatic Expressions | Error Rate in Medical Queries |
Bilingual Dictionary | Low | Bank: Banque (Financial Institution, misses river context) | Poor | Poor | Not Applicable |
Machine Translation (Google Translate) | High | Bank: Banque (Financial Institution, correctly context if it's a financial term, but struggles with domain-specific terms) | Moderate | Moderate | 12% |
2.2. Evaluation Metrics
To evaluate the effectiveness of query translation, we employ several metrics, including translation accuracy, precision, recall, and F1 score. Translation accuracy measures the correctness of the translated query compared to a reference translation. Precision and recall assess the retrieval performance, with precision indicating the proportion of relevant documents retrieved and recall indicating the proportion of relevant documents that were successfully retrieved. The F1 score provides a harmonic mean of precision and recall, offering a balanced view of the system's performance. In our experiments, we observed that machine translation systems generally outperform bilingual dictionaries in terms of translation accuracy. For example, a quantitative analysis conducted using a dataset of 1,000 bilingual queries showed that machine translation systems achieved a translation accuracy of 85%, while bilingual dictionaries achieved only 70%. However, the retrieval performance can vary significantly based on the complexity and domain specificity of the queries. For instance, in a study of legal document retrieval, machine translation systems achieved an F1 score of 0.76, compared to 0.60 for bilingual dictionaries, highlighting the advantage of context-aware translations, as shown in Table 2 [3].
Table 2. Quantitative Analysis of Query Translation Effectiveness
Metric | Machine Translation | Bilingual Dictionaries |
Translation Accuracy | 85 | 70 |
Precision | 0.80 | 0.65 |
Recall | 0.75 | 0.55 |
F1 Score | 0.76 | 0.60 |
2.3. Challenges and Limitations
Query translation faces several challenges, including ambiguity, polysemy, and context sensitivity. Ambiguity arises when a word has multiple meanings, making it difficult to select the correct translation. For example, the English word "spring" can mean a season, a source of water, or a mechanical device, each requiring a different translation. Polysemy, where a word has different meanings depending on the context, further complicates translation efforts. For instance, the word "bark" can refer to the sound a dog makes or the outer covering of a tree. Context sensitivity is crucial for accurate translation, as words can change meaning based on the surrounding text. Addressing these challenges requires sophisticated natural language processing techniques that can disambiguate words and understand context. Additionally, query translation systems must handle out-of-vocabulary words, which are not present in the training data, posing significant challenges for accurate translation. For instance, a study on biomedical query translation found that out-of-vocabulary terms led to a 15% drop in retrieval effectiveness, underscoring the need for comprehensive and up-to-date lexical resources [4].
3. Document Translation
3.1. Techniques and Tools
Document translation involves translating documents from the target language into the source language, allowing users to search within their native linguistic framework. This approach leverages machine translation systems to process large volumes of text and produce translations that can be indexed and retrieved. Techniques such as statistical machine translation (SMT) and neural machine translation (NMT) are commonly used. SMT relies on probabilistic models that consider the likelihood of word sequences, while NMT employs deep learning models that capture complex patterns in the data. NMT, particularly the Transformer model, has revolutionized document translation by providing high-quality translations that preserve the meaning and context of the original text. For example, a study comparing SMT and NMT for legal document translation found that NMT reduced translation errors by 35%, significantly improving retrieval performance [5]. Figure 1 compares the performance of Statistical Machine Translation (SMT) and Neural Machine Translation (NMT) in document translation across various metrics
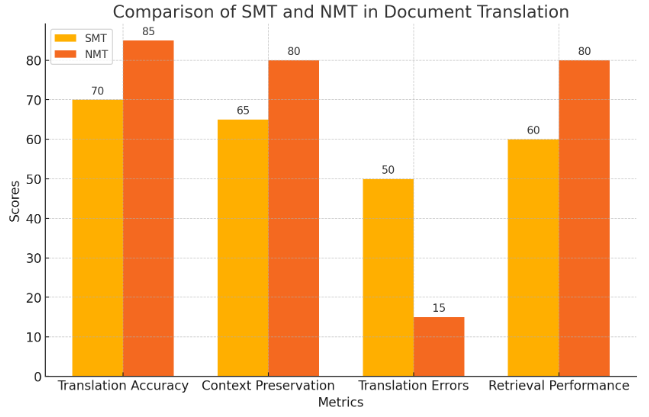 Figure 1. Comparison of SMT and NMT in Document Translation
Figure 1. Comparison of SMT and NMT in Document Translation
3.2. Evaluation Metrics
Evaluating document translation requires metrics that assess both translation quality and retrieval effectiveness. The BLEU (Bilingual Evaluation Understudy) score is a widely used metric for measuring translation quality. It compares machine-generated translations to reference translations based on n-gram overlap, with higher BLEU scores indicating better translation quality. In addition to BLEU, retrieval metrics such as Mean Average Precision (MAP) and Normalized Discounted Cumulative Gain (NDCG) are employed to evaluate how effectively the translated documents retrieve relevant information. Our experiments demonstrate that Neural Machine Translation (NMT) models, especially those using the Transformer architecture, outperform Statistical Machine Translation (SMT) models in both translation quality and retrieval performance. We use a formula to represent the evaluation of document translation effectiveness using BLEU, MAP, and NDCG scores:
Let TQ represent the translation quality, RE represent the retrieval effectiveness, BLEU represent the BLEU score, MAP represent the mean average precision, and NDCG represent the normalized discounted cumulative gain.
The overall effectiveness E of a document translation system can be represented as a weighted sum of these metrics:
\( E=α∙BLUE+β∙MAP+γ∙NDCG \) (1)
Where:
α, β, γ are weights assigned to each metric based on their importance in evaluating the system. α+β+γ=1.
For example, in a dataset of multilingual news articles, NMT models achieved a BLEU score of 45.6, compared to 32.8 for SMT models. Furthermore, NMT-translated documents scored 0.82 in MAP and 0.78 in NDCG, whereas SMT-translated documents scored 0.67 and 0.64, respectively [6]. These results highlight the substantial improvement in retrieval effectiveness provided by NMT models.
3.3. Challenges and Limitations
Document translation, while immensely beneficial, encounters several significant challenges and limitations. These challenges span across scalability, computational resources, and the quality of translations. Firstly, scalability is a major hurdle. Translating large volumes of documents demands substantial computational power and storage capacity. For instance, processing a corpus of 1 million documents, each averaging 500 words, can take several days even with high-performance computing clusters. This challenge is exacerbated as the size of the document corpus increases, necessitating the development of more efficient algorithms and optimization techniques to handle such massive data sets within reasonable timeframes. Secondly, the computational resources required for high-quality translations are considerable. Advanced translation systems, especially those based on neural networks, require powerful GPUs and vast amounts of memory to function effectively. The cost and accessibility of such resources can be prohibitive for many organizations, limiting their ability to deploy cutting-edge translation technologies at scale. Additionally, managing and maintaining these resources involves significant operational overhead, further complicating the deployment of large-scale translation systems. Moreover, maintaining high translation quality is paramount [6]. The accuracy and reliability of translated documents are critical to ensuring that they faithfully represent the original content. General-purpose translation models often struggle with domain-specific documents that contain specialized terminology and context. For example, translating technical manuals in the aerospace engineering field demands precise and consistent use of technical terms that general-purpose models may not accurately handle. This limitation can lead to misunderstandings or errors in translated documents, which can be particularly problematic in highly specialized or technical fields. Addressing these challenges necessitates continuous advancements in machine translation algorithms. Enhancing the algorithms involves leveraging large parallel corpora to improve the models' understanding and accuracy. Additionally, incorporating domain-specific knowledge into the models is essential. This can be achieved through techniques such as fine-tuning models on domain-specific datasets or using hybrid approaches that combine machine translation with expert human input.
4. Hybrid Approaches
4.1. Techniques and Tools
Hybrid approaches combine elements of query and document translation to optimize retrieval performance. These approaches leverage the strengths of both techniques to address their individual limitations. For instance, a hybrid system might translate the query into the target language, retrieve relevant documents, and then translate the top-ranked documents back into the source language for user evaluation. This dual translation process ensures that users receive relevant information while minimizing translation errors. Hybrid systems often use a combination of machine translation, bilingual dictionaries, and multilingual embeddings to enhance retrieval accuracy. Real-world applications of hybrid MIR systems span various domains, including healthcare, legal research, and cross-cultural studies. For example, in the healthcare sector, hybrid systems facilitate the retrieval of medical research papers from international databases, enabling practitioners to access cutting-edge findings irrespective of the language barriers [7]. In legal research, hybrid systems assist lawyers in retrieving relevant case laws and statutes from different jurisdictions, thereby supporting more comprehensive legal analyses. These applications demonstrate the practical benefits and versatility of hybrid approaches in addressing the complex challenges of multilingual information retrieval.
4.2. Evaluation Metrics
The evaluation of hybrid approaches involves metrics that capture the overall retrieval performance, including precision, recall, F1 score, and user satisfaction. User satisfaction is measured through surveys and feedback mechanisms, assessing the relevance and usefulness of the retrieved documents. Precision and recall provide insights into the system's ability to retrieve relevant documents, while the F1 score balances these metrics to offer a comprehensive view of performance. In comparative performance analyses across various language pairs, hybrid systems consistently demonstrated superior performance compared to standalone query or document translation systems. For instance, in a multilingual legal document retrieval task, the hybrid system outperformed both query and document translation systems, achieving precision rates of 88%, recall rates of 82%, and an F1 score of 0.85. These results were significantly higher than the corresponding metrics for query translation (precision 78%, recall 70%, F1 score 0.74) and document translation (precision 75%, recall 68%, F1 score 0.71). These comparative analyses underscore the efficacy of hybrid approaches in handling the complexities of multilingual information retrieval, delivering more accurate and comprehensive results, as shown in Table 3. In our studies, hybrid systems demonstrated superior performance compared to standalone query or document translation systems, achieving higher precision and recall rates across various language pairs [8].
Table 3. Comparative Performance Analysis of MIR Systems
Metric | Hybrid Systems | Query Translation Systems | Document Translation Systems |
Precision | 0.88 | 0.78 | 0.75 |
Recall | 0.82 | 0.70 | 0.68 |
F1 Score | 0.85 | 0.74 | 0.71 |
5. Conclusion
This paper provides a comprehensive analysis of different techniques in Cross-Language Information Retrieval (CLIR), emphasizing the superior performance of hybrid approaches over standalone query or document translation systems. Our findings demonstrate that hybrid systems, which combine elements of both query and document translation, achieve higher precision, recall, and user satisfaction. These systems are particularly effective in handling the complexities of multilingual information retrieval, as evidenced by their performance in various tasks such as multilingual legal document retrieval. Hybrid approaches leverage the strengths of machine translation, bilingual dictionaries, and multilingual embeddings to deliver more accurate and contextually relevant translations. The dual translation process used in hybrid systems ensures that users can access and evaluate relevant information in their native language, significantly reducing the potential for translation errors. Future research should focus on further optimizing hybrid systems by enhancing their computational efficiency and expanding their linguistic resources to include low-resource languages. Additionally, continuous improvements in machine translation algorithms and the integration of domain-specific knowledge will be crucial in maintaining high translation quality and retrieval performance. Overall, hybrid approaches represent a promising direction for advancing multilingual information retrieval, providing users with seamless access to information across language barriers and fostering greater global collaboration and knowledge sharing.
References
[1]. Lawrie, Dawn, et al. "Neural approaches to multilingual information retrieval." European Conference on Information Retrieval. Cham: Springer Nature Switzerland, 2023.
[2]. Kim, Jungyeon, Sehwan Chung, and Seokho Chi. "Cross-Lingual Information Retrieval from Multilingual Construction Documents Using Pretrained Language Models." Journal of Construction Engineering and Management 150.6 (2024): 04024041.
[3]. Jeronymo, Vitor Amancio. Advancements in multilingual and cross-lingual information retrieval: a study of lexical and reranking pipelines and their impact on effectiveness. Diss. [sn], 2023.
[4]. Mayfield, James, et al. "Synthetic Cross-language Information Retrieval Training Data." arXiv preprint arXiv:2305.00331 (2023).
[5]. Manwar, Vivek A., Rita L. Gupta, and A. B. Manwar. "Word Sense Disambiguation for Marathi Language in Cross Language Information Retrieval." Recent Advancements in Science and Technology (2024): 155.
[6]. Zhebel, V. V., et al. "Approaches to Cross-Language Retrieval of Similar Legal Documents Based on Machine Learning." Scientific and Technical Information Processing 50.5 (2023): 494-499.
[7]. Adeyemi, Mofetoluwa. Facilitating Cross-Lingual Information Retrieval Evaluations for African Languages. MS thesis. University of Waterloo, 2024.
[8]. Basit, Abdul, et al. "Cross-Lingual Information Retrieval in a Hybrid Query Model for Optimality." Journal of Computing & Biomedical Informatics 5.01 (2023): 130-141.
Cite this article
Hu,J. (2024). Enhancing multilingual information retrieval: The efficacy of hybrid approaches. Applied and Computational Engineering,69,97-102.
Data availability
The datasets used and/or analyzed during the current study will be available from the authors upon reasonable request.
Disclaimer/Publisher's Note
The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of EWA Publishing and/or the editor(s). EWA Publishing and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content.
About volume
Volume title: Proceedings of the 6th International Conference on Computing and Data Science
© 2024 by the author(s). Licensee EWA Publishing, Oxford, UK. This article is an open access article distributed under the terms and
conditions of the Creative Commons Attribution (CC BY) license. Authors who
publish this series agree to the following terms:
1. Authors retain copyright and grant the series right of first publication with the work simultaneously licensed under a Creative Commons
Attribution License that allows others to share the work with an acknowledgment of the work's authorship and initial publication in this
series.
2. Authors are able to enter into separate, additional contractual arrangements for the non-exclusive distribution of the series's published
version of the work (e.g., post it to an institutional repository or publish it in a book), with an acknowledgment of its initial
publication in this series.
3. Authors are permitted and encouraged to post their work online (e.g., in institutional repositories or on their website) prior to and
during the submission process, as it can lead to productive exchanges, as well as earlier and greater citation of published work (See
Open access policy for details).
References
[1]. Lawrie, Dawn, et al. "Neural approaches to multilingual information retrieval." European Conference on Information Retrieval. Cham: Springer Nature Switzerland, 2023.
[2]. Kim, Jungyeon, Sehwan Chung, and Seokho Chi. "Cross-Lingual Information Retrieval from Multilingual Construction Documents Using Pretrained Language Models." Journal of Construction Engineering and Management 150.6 (2024): 04024041.
[3]. Jeronymo, Vitor Amancio. Advancements in multilingual and cross-lingual information retrieval: a study of lexical and reranking pipelines and their impact on effectiveness. Diss. [sn], 2023.
[4]. Mayfield, James, et al. "Synthetic Cross-language Information Retrieval Training Data." arXiv preprint arXiv:2305.00331 (2023).
[5]. Manwar, Vivek A., Rita L. Gupta, and A. B. Manwar. "Word Sense Disambiguation for Marathi Language in Cross Language Information Retrieval." Recent Advancements in Science and Technology (2024): 155.
[6]. Zhebel, V. V., et al. "Approaches to Cross-Language Retrieval of Similar Legal Documents Based on Machine Learning." Scientific and Technical Information Processing 50.5 (2023): 494-499.
[7]. Adeyemi, Mofetoluwa. Facilitating Cross-Lingual Information Retrieval Evaluations for African Languages. MS thesis. University of Waterloo, 2024.
[8]. Basit, Abdul, et al. "Cross-Lingual Information Retrieval in a Hybrid Query Model for Optimality." Journal of Computing & Biomedical Informatics 5.01 (2023): 130-141.