







1. Introduction
Unmanned aerial vehicle (UAV) demonstrates extensive application and research in tasks such as urban planning, traffic monitoring, and video capturing. Oriented object detection (OOB) in RSI collected by UAVs’ optical sensors includes several challenges. RSI normally includes objects with arbitrary orientations and shapes, and they might be captured in severe weather conditions. General Detectors, such as the YOLO series [1-3] utilize a horizontal bounding box (HBB) for object localization. However, because RSI includes objects with various scales and orientations, HBB usually covers regions not parts of the object. To solve this issue, OOB applies the oriented bounding box that includes angles for regression. Therefore, utilizing convolutional neural networks for OOB will significantly enhance the detection accuracy.
Two distinct modules are introduced: The efficient atrous attention module EAAM and the decision aggregation module MOEHM. Multi-scale feature fusion, assessment and decision aggregation efficiently enhance a detector's performance. Multi-scale feature enhancement generally includes fusing deeper-level semantic information with shallower-level contextual information and placing a feature enhancement module within the feature fusion module. RSI often includes small objects with various shapes and orientations, posing significant challenges for detectors. The detectors commonly utilize FPN [4] after a feature extraction module for multi-scale feature enrichment and fusion. Decision aggregation means aggregating the decision from the detector's head, which predicts the classification and localization result. We used the mixture of experts training techniques for large language models to enhance feature representation while introducing minimal computational cost to aggregate the decision from different head structure structures adaptively.
2. Oriented Object Detection of Remote Sensing Images with Deep Learning
2.1. Oriented Object Detection of Remote Sensing Images
Oriented Object Detection (OOD) provides significant insight into RSI because it can detect objects with various orientations and shapes. RRPN [5] utilizes angled anchors to produce rotated proposals that align with the object's orientations. The ROI Transformer [6] convert the horizontal bounding boxes into rotated ones. However, the conventional approaches always introduce extra computational costs. Improvements such as the Gliding Vertex [7] adjust the vertex's position to enhance oriented object detection, introducing less computational cost. However, although these detectors introduce angled predictions for RSI, more robust OOD frameworks are still needed to boost detection performance.
2.2. Attention Mechanism
The Attention Mechanism typically highlights the crucial aspects of feature maps, spatial-wise or channel-wise. The Squeeze-and-Excitation (SENet) [8] is a form of channel attention that emphasizes the significant channel of feature maps. The convolutional block attention module (CBAM) [9] has channel-wise attention followed by spatial-wise attention, enhancing the features by sequentially focusing on essential channels and regions. Many two-stage detectors use the CBAM to perform feature refinement during the feature extraction stage. In order to highlight the crucial channels, the ECANet [10] utilizes the one-dimensional convolutional kernel to learn local cross-channel interaction. The SENet, CBAM, and ECANet are generally used as feature selection and enhancement techniques within the feature extraction stage.
2.3. Multi-scale Feature Enhancement and Fusion
The convolutional neural networks comprise several layers; the deeper layers generally have more semantic information, and the shallower layers have more contextual information than the deeper layers. Feature enhancement and fusion means having a feature selection or enhancement module used to refine multi-scale feature representations and fusing deeper-level features with shallower-level features. The FPN introduces a top-down pathway to aggregate semantic information to contextual information, enriching the feature representations from the CNN backbone. PANet [11] introduces a bottom-up and top-down path to further aggregate features from the CNN backbone. NAS-FPN [12] uses architectural search to configure the multi-scale feature fusion. Nonetheless, these feature fusion schemes are effective for natural images, but they lack customization for RSI due to the inherent challenging nature of RSI.
2.4. Mixture of Experts
The Mixture of Experts (MoE) is an adaptive ensemble technique, and it is widely used in natural language processing, particularly for the training of large-language models. The approaches divide the networks into submodules, each called “expert”. A gating mechanism will decide which experts will be used in learning and aggregate the results from each expert. For each input feature representation, only a few experts will be selected, and the selected experts are chosen according to the top-k selection algorithm, which will return the indices of experts with the highest gating scores. The selected experts will aggregate their weighted predictions and generate the final prediction result. The Switch Transformer [13] introduces more parameters to enrich feature representations with negligible computational cost.
3. Methodology
3.1. Overall Pipeline
Figure 1 demonstrates the overall architecture of the SkyNet. SkyNet comprises the feature extraction module ResNet, a multi-scale feature fusion module PAFPN, our proposed feature selection and enhancement module EAAM, the proposal network Oriented RPN, and our proposed decision aggregation module MOEHM. Our proposed EAAM are integrated with PAFPN for multi-scale feature fusion and enhancement, and our proposed MOEHM module incorporates a mixture of experts to aggregate the predictions from different expert structures adaptively.
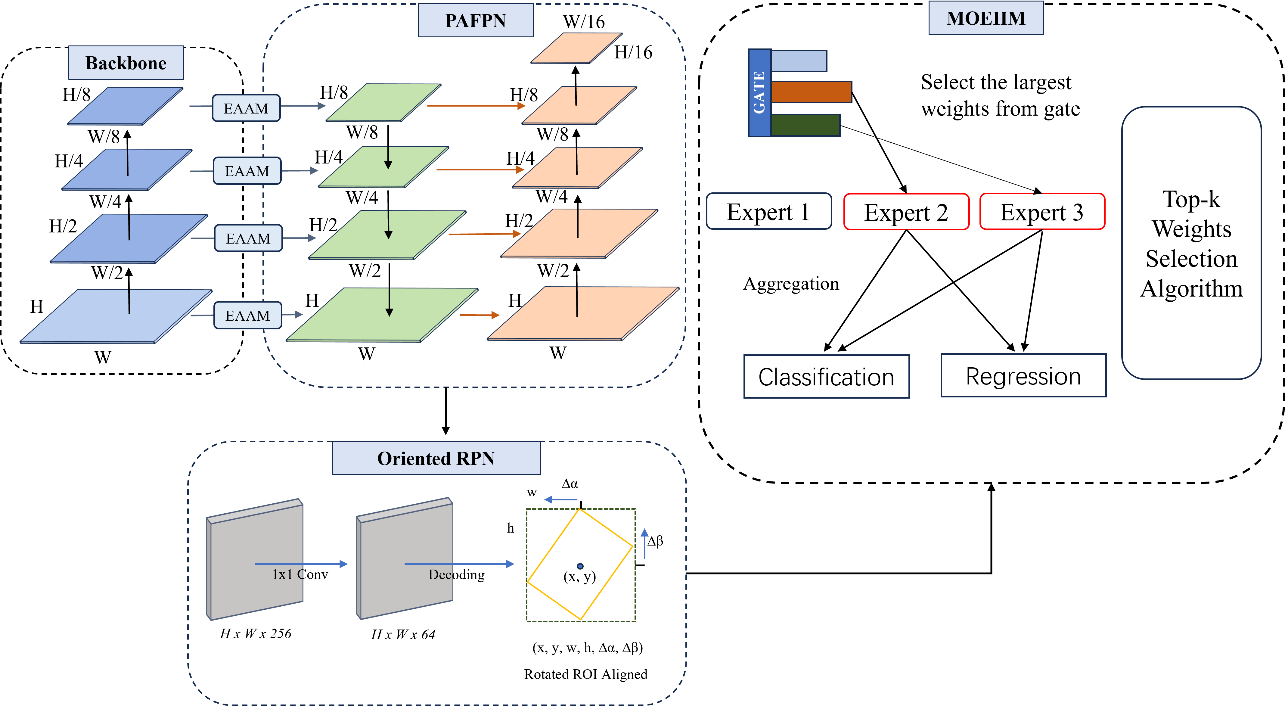
Figure 1. The overall architecture of SkyNet
We propose the EAAM for feature enhancement and refinement, which is utilized after the feature extraction stage of Resnet. The EAAM focus on essential channels and help to reduce noise and irrelevant information from each stage of Resnet. The baseline module utilizes FPN for feature fusion, but we decided to use PAFPN for enhanced feature fusion since PAFPN introduces another bottom-up path. For the MOEHM, the input feature maps from PAFPN will be fed into the gate unit, and the gate will generate scores for each expert structure we proposed. A top-k selection mechanism will select the expert for prediction based on the generated scores.
3.2. Efficient Atrous Attention Mechanism
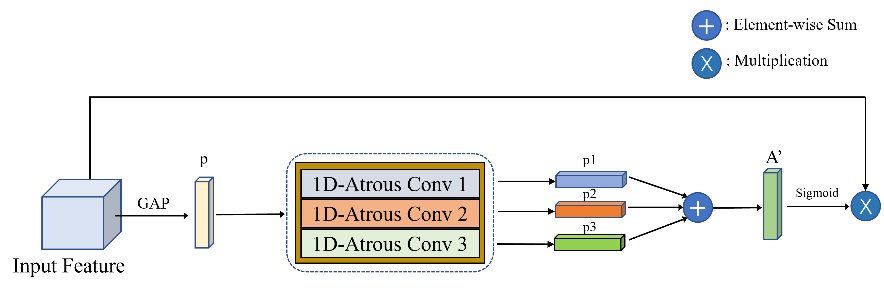
Figure 2. The structure our proposed feature refinement module EAAM
Figure 2 shows the overall structure of the EAAM. The input will be average pooled and generate the feature descriptor p, and the p will go through one-dimensional atrous convolution with different atrous rates. The atrous convolution will enhance the receptive field, so they will learn different local cross-channel interactions and generate p1, p2, and p3, which will be fused and become the enriched feature representation A’. The entire workflow of the EAAM can be expressed in Equation 1, where p = GAP(Input) and \( σ \) denotes the sigmoid function.
\( Result Feature Map=σ(AtrousConv1(p)+AtrousConv2(p)+AtrousConv3(p))\cdot Input\ \ \ (1) \)
We use the atrous convolution to generate multi-scale feature descriptors to enhance the receptive field for the input sequence. The atrous convolution can increase the receptive field of the convolutional kernels without introducing extra parameters, which is achieved by inserting zeros between the filter weights. Figure 3 visualizes the one-dimensional and atrous convolution kernels with an atrous rate equal to 2. The red boxes in Figure 3 denote the regions of the standard convolution kernel and the regions of the atrous convolutional kernel. We utilize standard convolution and atrous convolution with atrous rates equal to 2 and 3 in our attention mechanism, and this setting generates optimal results.

Figure 3. The visualization of one-dimensional standard convolution and atrous convolution
3.3. Mixture of Experts Head Module
Our proposed mixture of detector head modules aggregates the classification and localization results from different detector head “expert”. These experts have different structures; two are single-branched, and one is double-branched. A double-branch head structure uses a convolutional head for regression and linear layers for classification. The logic of a mixture of experts starts from input to experts, which can be formulated as Equation 2, where yi denotes the output of the ith expert.
\( { y_{i}}={f_{i}}(x) \ \ \ (2)\ \ \ \)
Equation 3 illustrates the gating network computes the gating values gi for each expert based on the input x, and Wg and bg denote the weights and biases. In our experiment, we set the bias to zero. After the gating scores are generated, the Softmax function ensures the gating values sum to one.
\( {g_{i}}=\frac{exp{\lbrace ({W_{g}}\cdot x + {b_{g}})\rbrace }}{\sum _{\lbrace j=1\rbrace }^{\lbrace N\rbrace }exp{\lbrace ({W_{g}}\cdot x + {b_{g}})\rbrace }}\ \ \ (3) \)
Equation 4 means that each expert’s prediction yi is aggregated by its gating value gi, generating the weighted output zi.
\( {z_{i}}={g_{i}}\cdot {y_{i}}\ \ \ (4) \)
The final output y is the weighted sum of each expert’s prediction yi, and the final aggregated result is formulated in Equation 5:
\( y=\sum _{i=1}^{N}{z_{i}}=\sum _{i=1}^{N}{g_{i}}\cdot {y_{i}}\ \ \ (5) \)
In our experiment, we utilize two single-branch experts and one double-branch expert. A Single branch means only one branch of fully connected or convolution layers for the head module. Double-branch means we have one branch full of convolutions for regression and fully connected layers for classification. Because the input feature maps learned by previous stages are of various distributions, as remote sensing images often contain diverse and complex patterns, applying a mixture of experts allows for more customization and specialization. In our design, the model will learn from the distribution of input feature maps and adaptively adjust weights for selected experts to focus on the most relevant features, enhancing overall performance and accuracy.
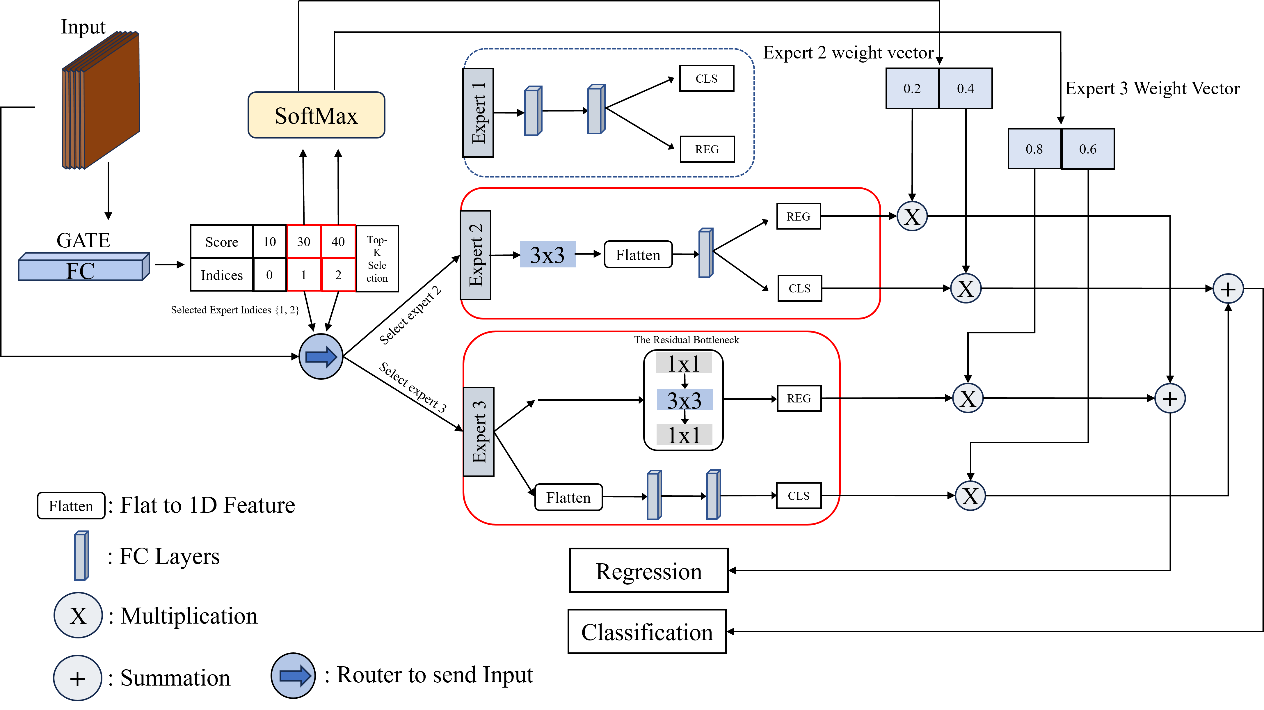
Figure 4. The structure our proposed decision aggregation module MOEHM
Figure 4 visualizes the overall design of MOEHM. The input will be fed into the gate unit, generating scores and indices for each expert. The top-k selection algorithm will select experts with the highest scores, and only the selected experts will be used to generate results, and each result will be aggregated by weights learned from the gate unit. The aggregated results will be the detector's eventual classification and regression results. Because of the memory restrictions of our GPU, we have 3 experts in our final design, and the active experts for each input feature map are 2. These experimental settings generate the best detection performance.
4. Experimental Results
4.1. Datasets
DOTA-v1.0 [14] datasets are a large-scale remote sensing benchmark comprising 2806 remote sensing images. The abbreviations of categories are shown as follows: Ground track field (GTF), Soccer-ball field (SBF), Plane (PL), Tennis court (TC), Harbor (HA), Small vehicle (SV), Baseball diamond (BD), Swimming pool (SP), Helicopter (HC), Ship (SH), Basketball court (BC), Roundabout (RA), Large vehicle (LV), Bridge (BR), and Storage tank (ST). HRSC2016 [15] is a dataset that includes only one category: ship. This dataset features six harbors worldwide and is commonly used for object detection for remote sensing imagery.
4.2. Evaluation Metrics
This research uses the mean average precision (mAP) to demonstrate the model performance. The mAP measures the accuracy of detection results, and it is the mean of the average precision (AP) score.
\( mAP=\frac{1}{C}\sum _{c=1}^{C}A{P_{c}}\ \ \ (6) \)
In Equation 6, C denotes the total number of categories, and APc denotes the average precision for each category. The AP measures the precision-recall tradeoff across different threshold values and is a critical metric for detection tasks.
4.3. Comparison with State-of-the-Art Detectors
In this Section, we will demonstrate the result of our proposed framework by comparing our detectors with the previous State-of-the-Art Detectors. All models were trained and tested under uniform conditions, applying the same parameter settings to ensure fairness. The complete comparison result for the DOTA dataset is shown in Table 1. Almost for each category of DOTA, our detector shows improvements compared to the baseline model ORCNN. Our model achieves a 0.87% increment for mAP. We compared our result with ROI-Transformer, DRN, SRCDet,
Table 1. Comparison of our proposed method with other state-of-the-art detectors on DOTA.
Method | Backbone | PL | BD | BR | GTF | SV | LV | SH | TC | BC | ST | SBF | RA | HA | SP | HC | mAP |
ROITrans [6] DRN [16] SCRDeT [17] R4Det [18] ORCNN Ours | R-101 | 88.64 | 78.52 | 43.44 | 75.92 | 68.81 | 73.68 | 83.59 | 90.74 | 77.27 | 81.46 | 58.39 | 53.54 | 62.83 | 58.93 | 47.67 | 69.56 |
H-104 R-101 | 88.91 89.98 | 80.22 80.65 | 43.52 52.09 | 63.35 68.36 | 73.48 68.36 | 70.69 60.32 | 84.94 72.41 | 90.14 90.85 | 83.85 87.94 | 84.11 86.86 | 50.12 65.02 | 58.41 66.68 | 67.62 66.25 | 68.60 68.24 | 52.50 65.21 | 70.70 72.61 | |
R-152 R-50 R-50 | 88.96 89.55 89.62 | 85.42 82.56 83.74 | 52.91 54.65 54.39 | 73.84 73.32 74.20 | 74.86 78.88 78.97 | 81.52 83.53 83.07 | 80.29 88.06 88.23 | 90.79 90.89 90.90 | 86.95 86.28 86.67 | 85.25 83.60 85.75 | 64.05 59.41 62.16 | 60.93 66.12 68.47 | 69.00 74.67 74.68 | 70.55 69.44 69.38 | 67.76 55.69 60.10 | 75.84 75.82 76.69 |
For the HRSC2016 dataset, Table 2 shows the result of each SOTA detector, and we used mAP07 and mAP12 as the evaluation metrics. Based on the mAP07 and mAP12 results, we can see that our proposed detectors demonstrate better detection performance. For both tables, the backbone column denotes the feature extraction network for each detector, and we only used Resnet, which contains 50 layers. Our proposed detectors significantly enhance the detection accuracy and use fewer layers and parameters, indicating our overall framework's effectiveness and our proposed EAAM and MOHEM modules.
Table 2. Comparison of our proposed method with other state-of-the-art detectors on HRSC2016.
Method | Backbone | mAP07 | mAP12 |
ROI Trans Rotated RPN [19] R3Det [20] ORCNN Ours | R-101 R-101 R-101 R-50 R-50 | 86.20 79.08 89.26 90.36 90.60 | - 85.64 96.01 96.40 97.60 |
In this Section, we will demonstrate the result of our proposed framework by comparing our detectors with the previous State-of-the-Art Detectors. All models were trained and tested under uniform conditions, applying the same parameter settings to ensure fairness. The complete comparison result for the DOTA dataset is shown in Table 1. For most categories of DOTA, our detector shows improvements compared to the baseline model ORCNN.
5. Conclusion
In this study, We propose our novel framework, Sky-Net, for oriented object detection of aerial and remote sensing images collected by the optical sensors of UAVs. Compared to the baseline ORCNN model and other state-of-the-art models, our model framework improves the model performance and maintain the computational speed. Sky-Net utilizes EAAM with PAFPN for feature selection enhancement and refinement, and it also utilizes the adaptive and sparsely gated MOEHM for adaptive decision aggregation based on the input data distribution. We validate our framework on two popular public benchmark datasets and demonstrate that our model achieved enhanced performance. This conclusion affirms that integrating feature enhancement and decision aggregation modules will be highly effective for oriented object detection of remote sensing images.
References
[1]. Redmon J, Farhadi A. YOLO9000: better, faster, stronger. Proceedings of the IEEE conference on computer vision and pattern recognition 2017 (pp. 7263-7271).
[2]. Redmon J, Divvala S, Girshick R, Farhadi A. You only look once: Unified, real-time object detection. Proceedings of the IEEE conference on computer vision and pattern recognition 2016 (pp. 779-788).
[3]. Redmon J, Farhadi A. Yolov3: An incremental improvement. arXiv preprint arXiv:1804.02767. 2018 Apr 8.
[4]. Lin TY, Dollár P, Girshick R, He K, Hariharan B, Belongie S. Feature pyramid networks for object detection. Proceedings of the IEEE conference on computer vision and pattern recognition 2017 (pp. 2117-2125).
[5]. Ma J, Shao W, Ye H, Wang L, Wang H, Zheng Y, Xue X. Arbitrary-oriented scene text detection via rotation proposals. IEEE transactions on multimedia. 2018 Mar 23;20(11):3111-22.
[6]. Ding J, Xue N, Long Y, Xia GS, Lu Q. Learning RoI transformer for oriented object detection in aerial images. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition 2019 (pp. 2849-2858).
[7]. Xu Y, Fu M, Wang Q, Wang Y, Chen K, Xia GS, Bai X. Gliding vertex on the horizontal bounding box for multi-oriented object detection. IEEE transactions on pattern analysis and machine intelligence. 2020 Feb 18;43(4):1452-9.
[8]. Hu J, Shen L, Sun G. Squeeze-and-excitation networks. Proceedings of the IEEE conference on computer vision and pattern recognition 2018 (pp. 7132-7141).
[9]. Woo S, Park J, Lee JY, Kweon IS. Cbam: Convolutional block attention module. Proceedings of the European conference on computer vision (ECCV) 2018 (pp. 3-19).
[10]. Wang Q, Wu B, Zhu P, Li P, Zuo W, Hu Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition 2020 (pp. 11534-11542).
[11]. Liu S, Qi L, Qin H, Shi J, Jia J. Path aggregation network for instance segmentation. Proceedings of the IEEE conference on computer vision and pattern recognition 2018 (pp. 8759-8768).
[12]. Ghiasi G, Lin TY, Le QV. Nas-fpn: Learning scalable feature pyramid architecture for object detection. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition 2019 (pp. 7036-7045).
[13]. Fedus W, Zoph B, Shazeer N. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. Journal of Machine Learning Research. 2022;23(120):1-39.
[14]. Xia GS, Bai X, Ding J, Zhu Z, Belongie S, Luo J, Datcu M, Pelillo M, Zhang L. DOTA: A large-scale dataset for object detection in aerial images. Proceedings of the IEEE conference on computer vision and pattern recognition 2018 (pp. 3974-3983).
[15]. Liu Z, Yuan L, Weng L, Yang Y. A high resolution optical satellite image dataset for ship recognition and some new baselines. International conference on pattern recognition applications and methods 2017 Feb 24 (Vol. 2, pp. 324-331). SciTePress.
[16]. Pan X, Ren Y, Sheng K, Dong W, Yuan H, Guo X, Ma C, Xu C. Dynamic refinement network for oriented and densely packed object detection. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition 2020 (pp. 11207-11216).
[17]. Yang X, Yang J, Yan J, Zhang Y, Zhang T, Guo Z, Sun X, Fu K. Scrdet: Towards more robust detection for small, cluttered and rotated objects. Proceedings of the IEEE/CVF international conference on computer vision 2019 (pp. 8232-8241).
[18]. Sun P, Zheng Y, Zhou Z, Xu W, Ren Q. R4 Det: Refined single-stage detector with feature recursion and refinement for rotating object detection in aerial images. Image and Vision Computing. 2020 Nov 1;103:104036.
[19]. Ma J, Shao W, Ye H, Wang L, Wang H, Zheng Y, Xue X. Arbitrary-oriented scene text detection via rotation proposals. IEEE transactions on multimedia. 2018 Mar 23;20(11):3111-22.
[20]. Yang X, Yan J, Feng Z, He T. R3det: Refined single-stage detector with feature refinement for rotating object. Proceedings of the AAAI conference on artificial intelligence 2021 May 18 (Vol. 35, No. 4, pp. 3163-3171).
Cite this article
Chen,Y. (2024). SkyNet: Multi-scale feature augmentation and diverse expert heads for UAV aerial image object detection. Applied and Computational Engineering,86,160-167.
Data availability
The datasets used and/or analyzed during the current study will be available from the authors upon reasonable request.
Disclaimer/Publisher's Note
The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of EWA Publishing and/or the editor(s). EWA Publishing and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content.
About volume
Volume title: Proceedings of the 6th International Conference on Computing and Data Science
© 2024 by the author(s). Licensee EWA Publishing, Oxford, UK. This article is an open access article distributed under the terms and
conditions of the Creative Commons Attribution (CC BY) license. Authors who
publish this series agree to the following terms:
1. Authors retain copyright and grant the series right of first publication with the work simultaneously licensed under a Creative Commons
Attribution License that allows others to share the work with an acknowledgment of the work's authorship and initial publication in this
series.
2. Authors are able to enter into separate, additional contractual arrangements for the non-exclusive distribution of the series's published
version of the work (e.g., post it to an institutional repository or publish it in a book), with an acknowledgment of its initial
publication in this series.
3. Authors are permitted and encouraged to post their work online (e.g., in institutional repositories or on their website) prior to and
during the submission process, as it can lead to productive exchanges, as well as earlier and greater citation of published work (See
Open access policy for details).
References
[1]. Redmon J, Farhadi A. YOLO9000: better, faster, stronger. Proceedings of the IEEE conference on computer vision and pattern recognition 2017 (pp. 7263-7271).
[2]. Redmon J, Divvala S, Girshick R, Farhadi A. You only look once: Unified, real-time object detection. Proceedings of the IEEE conference on computer vision and pattern recognition 2016 (pp. 779-788).
[3]. Redmon J, Farhadi A. Yolov3: An incremental improvement. arXiv preprint arXiv:1804.02767. 2018 Apr 8.
[4]. Lin TY, Dollár P, Girshick R, He K, Hariharan B, Belongie S. Feature pyramid networks for object detection. Proceedings of the IEEE conference on computer vision and pattern recognition 2017 (pp. 2117-2125).
[5]. Ma J, Shao W, Ye H, Wang L, Wang H, Zheng Y, Xue X. Arbitrary-oriented scene text detection via rotation proposals. IEEE transactions on multimedia. 2018 Mar 23;20(11):3111-22.
[6]. Ding J, Xue N, Long Y, Xia GS, Lu Q. Learning RoI transformer for oriented object detection in aerial images. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition 2019 (pp. 2849-2858).
[7]. Xu Y, Fu M, Wang Q, Wang Y, Chen K, Xia GS, Bai X. Gliding vertex on the horizontal bounding box for multi-oriented object detection. IEEE transactions on pattern analysis and machine intelligence. 2020 Feb 18;43(4):1452-9.
[8]. Hu J, Shen L, Sun G. Squeeze-and-excitation networks. Proceedings of the IEEE conference on computer vision and pattern recognition 2018 (pp. 7132-7141).
[9]. Woo S, Park J, Lee JY, Kweon IS. Cbam: Convolutional block attention module. Proceedings of the European conference on computer vision (ECCV) 2018 (pp. 3-19).
[10]. Wang Q, Wu B, Zhu P, Li P, Zuo W, Hu Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition 2020 (pp. 11534-11542).
[11]. Liu S, Qi L, Qin H, Shi J, Jia J. Path aggregation network for instance segmentation. Proceedings of the IEEE conference on computer vision and pattern recognition 2018 (pp. 8759-8768).
[12]. Ghiasi G, Lin TY, Le QV. Nas-fpn: Learning scalable feature pyramid architecture for object detection. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition 2019 (pp. 7036-7045).
[13]. Fedus W, Zoph B, Shazeer N. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. Journal of Machine Learning Research. 2022;23(120):1-39.
[14]. Xia GS, Bai X, Ding J, Zhu Z, Belongie S, Luo J, Datcu M, Pelillo M, Zhang L. DOTA: A large-scale dataset for object detection in aerial images. Proceedings of the IEEE conference on computer vision and pattern recognition 2018 (pp. 3974-3983).
[15]. Liu Z, Yuan L, Weng L, Yang Y. A high resolution optical satellite image dataset for ship recognition and some new baselines. International conference on pattern recognition applications and methods 2017 Feb 24 (Vol. 2, pp. 324-331). SciTePress.
[16]. Pan X, Ren Y, Sheng K, Dong W, Yuan H, Guo X, Ma C, Xu C. Dynamic refinement network for oriented and densely packed object detection. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition 2020 (pp. 11207-11216).
[17]. Yang X, Yang J, Yan J, Zhang Y, Zhang T, Guo Z, Sun X, Fu K. Scrdet: Towards more robust detection for small, cluttered and rotated objects. Proceedings of the IEEE/CVF international conference on computer vision 2019 (pp. 8232-8241).
[18]. Sun P, Zheng Y, Zhou Z, Xu W, Ren Q. R4 Det: Refined single-stage detector with feature recursion and refinement for rotating object detection in aerial images. Image and Vision Computing. 2020 Nov 1;103:104036.
[19]. Ma J, Shao W, Ye H, Wang L, Wang H, Zheng Y, Xue X. Arbitrary-oriented scene text detection via rotation proposals. IEEE transactions on multimedia. 2018 Mar 23;20(11):3111-22.
[20]. Yang X, Yan J, Feng Z, He T. R3det: Refined single-stage detector with feature refinement for rotating object. Proceedings of the AAAI conference on artificial intelligence 2021 May 18 (Vol. 35, No. 4, pp. 3163-3171).