







1. Introduction
Music recommender systems (MRSs) have become more and more popular as research in the field has expanded. Music streaming services like Spotify, Pandora, and Apple Music offer hundreds of millions of songs to music lovers. While MRSs can provide music that meets the patrons' requirements, they are still far from perfect and frequently generate unsatisfactory recommendations. This is because current MRS methods, which are usually focused on user-item interactions or content-based item descriptors, do not account for a user's musical preferences. We claim that to satisfy the customers' musical entertainment needs researchers and designers must consider three aspects of the listeners: intrinsic, extrinsic, and contextual. For example, psychologists and counsellors have demonstrated that people's musical interests and needs are influenced by factors such as age, gender, and sociocultural background. Because MRSs are almost always focused on user-item interactions, they do not sufficiently account for a user's musical preferences. Within the music recommendation domain, we investigate three main issues namely, cold start, automatic playlist continuation, and evaluation of MRS, which are all to some extent prevalent in other recommendation systems. We also observe these issues to some extent in other recommendation systems, but certain characteristics of music make these domains particularly difficult. For example, music has a brief lifespan and a strong emotional connection, which makes it more challenging to recommend duplicates. In the second part of our discussion, we discuss future research initiatives. We investigate psychologically inspired music recommendations (in consideration of human personality and emotion) as well as situation- and culture-aware music recommendations. A recommendation algorithm and software tool that connects to numerous real-world applications to give users the best choices for items they are most interested in. Recommendations for music selections, books to read, and music to listen to are connected to numerous real-world applications, such as what to buy, what music to listen to, and what current news to read. The music industry's transformation from commodity sales to subscriptions and streaming because of Apple's acquisition of Beats Music in 2014 resulted in a valuable digital music resource. Music providers must sell more diverse music as well as increase customer satisfaction by offering song selections that are most appropriate to users.
We can use lifestyle, age, gender, and other factors to identify a user's music preferences. To suggest music to users, we may use user profiling to determine their preferences. Audio metadata can include editorial, cultural, and acoustic metadata. We can model users with user modelling, which estimates the percentage difference in user profiles to determine their music preferences. For instance, Bogdanov et al used genre metadata to increase listener satisfaction. Collaborative filtering and content-based filtering are two methods for matching algorithm matching. Collaborative filtering relies on the assumption that users rate music items similarly or similarly in terms of usage, for them to rate other items similarly.
Because the assessments are harder to determine, collaborative filtering methods are more difficult to use because most users perceive only a small portion of all library material, making most assessments less prominent. On the other hand, content-based strategies determine music preferences using features of music items. "Content" in this context refers to the data in the files. Content-based approaches typically employ a two-step procedure, first extracting audio content features from audio material and then predicting user preferences by using them as a test. The extraction and comparison of audio characteristics such as timbre and rhythm have been the focus of a lot of research.
2. Related Work
A good music recommender aims to help users filter and discover music based on their tastes, Y Song states in his paper published in 2012 [1]. A good music recommender system should be able to automatically detect preferences and generate playlists accordingly. Furthermore, the development of recommender systems provides a great opportunity for the music industry to aggregate the users who are interested in music. We have to better understand and model people's preferences in music to develop recommender systems that are better able to satisfy them. In concert with the use of content-based modelling, the user can obtain lists of similar music based on acoustic features such as rhythm, pitch, or other fundamental features. A music recommender system is made up of three key components - users, items, and user-item matching algorithms. User profiling is used to distinguish users' tastes from each other. This step distinguishes users' tastes by using basic information. Item profiling, on the other hand, describes three different types of metadata - editorial, cultural, and acoustic, which are used in different recommendation strategies [2]. A better approach is to combine the existing two-stage procedure with an automated process to learn features automatically, resulting in the creation of a unified and automated procedure: features are learned automatically and directly from the audio content. People have already begun employing deep learning to learn features for other music tasks such as music genre classification and music emotion detection with promising results. In existing content-based methods and hybrid methods, traditional features still play a significant role. The authors in the paper Deep content-based music recommendation state that the characteristics of songs that influence user preference are difficult to ascertain from audio signals because much usage data is unavailable [3]. To address this issue, a latent factor vector can be constructed that describes the differences in users’ tastes and the corresponding characteristics of the items. It is often impossible to estimate these vectors, so they can be predicted from music audio content. The similarities between the characteristics of a song that affects user preference and the corresponding audio signals are great. A powerful model that captures the hierarchical, complex structure of music is required to extract high-level properties such as genre, mood, instrumentation, and literary themes from audio signals. Furthermore, the popularity of the artist, their reputation, and their location cannot be inferred from audio signals by themselves. The paper by Markus Schedl, talks about some grand challenges to be tackled in the development and evaluation of music recommendation systems [4]. Challenges such as the duration of music have a high fluctuation from genre to genre and artist to artist. The volume or amount of music is also exponentially large. People usually hear music in a sequential order, where the order might also be of influence to some. Avoiding older recommendations to the same listener. Consumption habits and listening intent such as duration, frequency, the purpose of listening, etc. Emotions influence the listener to play a major role in the music he/she likes. These challenges are the major limitations of recommendation systems. Adiyansjah, mention about the availability of features on music streaming applications like Spotify and Pandora to recommend music to users [5]. These features can help users find music that fits their tastes by recommending music that has been previously enjoyed. This ensures that streaming music remains popular by keeping track of music that has been previously listened to. The music recommender system must be able to find appealing new music for all audiences, and it must do this in a way that matches the users' musical preferences. This is more complex than a general recommender system because the music-personalized recommender system must take into account the individual preferences of the user. As deep learning has developed, the results of deep neural networks have been promising in different fields, including music recognition. Mohamadreza state in their paper written in 2021 [6]. They produced spectrograms from music pieces and scaled them on Mel-scale and created patches for all music pieces. The patches were fed to a convolutional neural network. They achieved better accuracy by combining acoustic and visual features. This paper also proposes an architecture for collecting required features (feature vectors) from intermediate layers of the CNN and then using Cosine similarity and Euclidean distance to classify music types. To have a feature vector with good quality, both max and average pooling are used. No filters have been used, such as collaborative filtering and user filtering. All of the decisions for recommending similar music are left to the system itself. Athulya K M talk about extracting meaningful spectrograms such as Spectral centroid, Spectral roll-off, Zero-crossing rate, Spectral bandwidth, and Chromo frequencies from slices of spectrograms such as Mel-spectrograms [7]. Spectral centroid, Spectral roll-off, Zero-crossing rate, Spectral bandwidth, and Chromo frequencies are among the many rich features that spectrograms offer. It is a valuable activity for studying and understanding the connections between songs and genres. Using librosa Python library, we can extract the feature values from spectrograms.
3. Methodology
3.1. Autoencoders
An autoencoder is a neural network that learns to represent data by constraining the network's output. To do this, we will design a neural network architecture that restricts the flow of information through the network. Because each input feature is independent of all the others, compressing and re-creating the input data would be a difficult task if it were not for the structure that may be discovered in the data (correlations between input features). This structure can then be used to force the input through the bottleneck of the network.
3.2. Convolutional Networks
A Convolutional Neural Network can identify features in an image and adjust the weights and biases to learn to recognize them. In comparison to other classifiers, the processing required by a convolution network is significantly reduced. Because filters are hand-crafted in primitive methods rather than being constructed through training, they can recognize these filters/characteristics through training. The structure of a convolutional network is like that of the visual cortex of a human brain and is inspired by the organization of the visual cortex. A receptive field is in a small region of the visual field and responds to stimuli only. A collection of such receptive fields, which overlap the entire visual field, is known as the Visual Field. A Basic CNN consists of a Feature Extraction block of Convolution layers and Pooling layers, along with a Classification block of Fully Connected layers. Compared to other neural networks, the performance of convolutional neural networks is particularly impressive with image data, thus should perform well in our case of Mel-Spectrogram data.
4. Experiment
4.1. Dataset
The GTZAN dataset was used [11]. This dataset consists of 1000 music samples of 30 seconds each, with a total of 10 genres. We are aware of the problems and nuances of the GTZAN dataset, but firmly believe that it is still good enough to be used for working on our concept [12-14]. The audio files were in .wav format [15]. We generated Mel-Spectrograms of all our 1000 music samples using the librosa package available in Python. The Mel-Spectrogram was generated with n_mels=128 and f_max=sr/2 (where sr is sampling rate of the audio clip). These Mel-Spectrograms were then saved with a resolution of 224 x 244 pixels which includes a white padding of 0.1 x screen dpi (96 in our case, thus 9.6 ≈ 10 pixels). The colour map used was magma. This process was done using pyplot library in matplotlib package for Python. The files were stored in .png format.
|
Figure 1. Few Examples of the Mel-Spectrograms. |
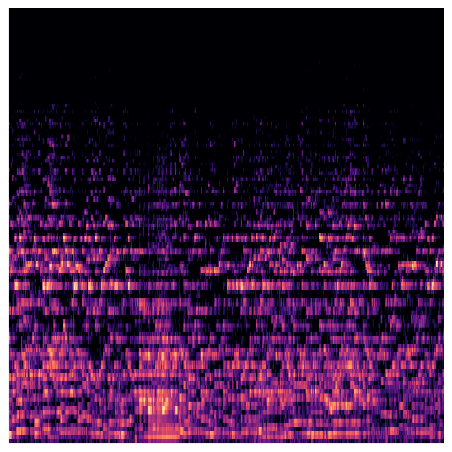
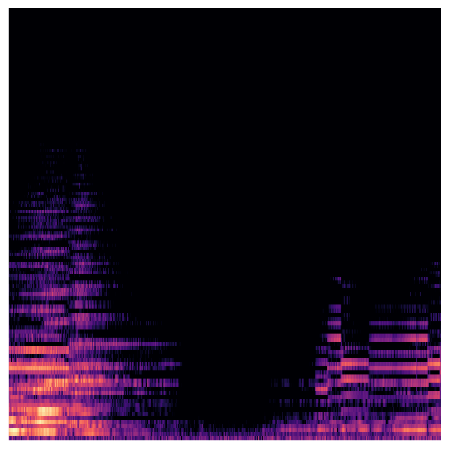
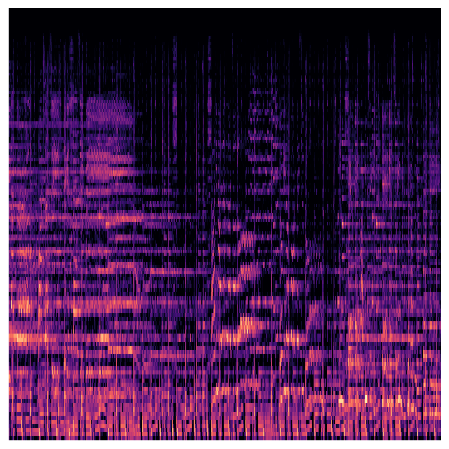
4.2. Model
We are using the pre-trained VGG-19 network available in Tensorflow for the encoder [16-19]. The VGG-19 network consists of Convolutional layers followed by Fully Connected Layers. We removed the Fully Connected Layers which were used for class prediction in the original approach. Then the remaining network was partially training-locked by setting the layers.trainable parameter set to False, with only the last 5 layers set to True. The decoder part was trained from scratch. The original VGG-19 has total 143,667,240 trainable parameters. After removing the fully connected layers in our encoder we are left with 20,024,384 total parameters. For our decoder we have 1,572,259 total parameters. The original VGG-19 is trained on ImageNet database that contains a million image of 1000 categories.
VGG-19 has 16 convolutional layers which are used for feature extraction and 3 fully-connected layers which are used for classification. We remove the last 3 classification layers. The layers used for feature extraction are segregated into 5 groups (or blocks). We lock these blocks and train only the last block of convolutional layers.
|
Figure 2. The autoencoder architecture representation. The Conv2D layers are depicted by yellow, MaxPooling2D by red and UpSampling2D by blue. |
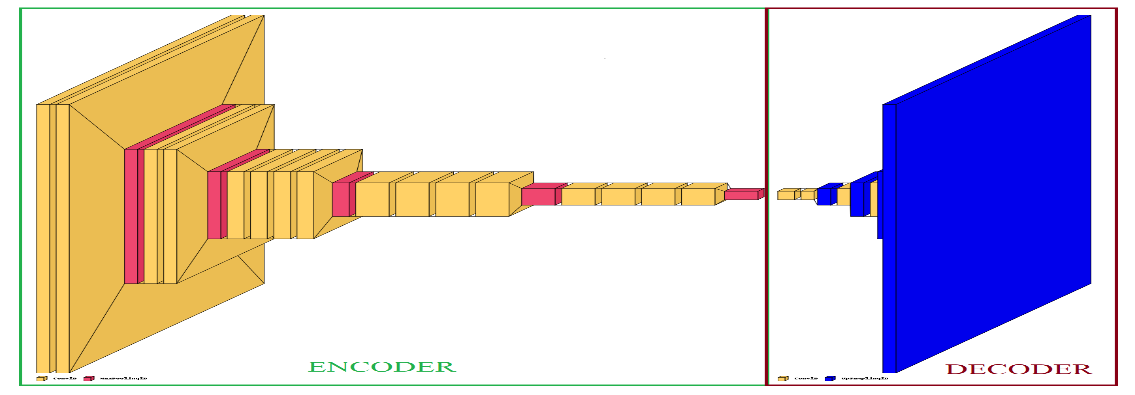
We combine both the encoders and decoders into an autoencoder. Autoencoder are commonly used for finding similar images in an unlabelled image dataset. Autoencoders compress the input data, and reconstructs it as an output. This makes autoencoders excellent for dimensionality reduction and helps us to focus on areas of important features. Since we are working with spectrogram data, autoencoders help us in picking up the most pronounced parts of a spectrogram which can be used as a feature set.
4.3. Training
The data was split into training and testing set in the ratio of 90%:10% respectively. The autoencoder was then trained for 500 epochs using the Adam optimiser, with lr=0.001 and use_ema=True. Mean Squared Error (MSE) was used as the loss metric for training along with Mean Absolute Error (MAE) as an additional metric just to monitor. The training loss, MSE was 0.0147, while we also achieved MAE of 0.0640. The testing set achieved MSE=0.0216 and MAE=0.0812.
5. Results and discussion
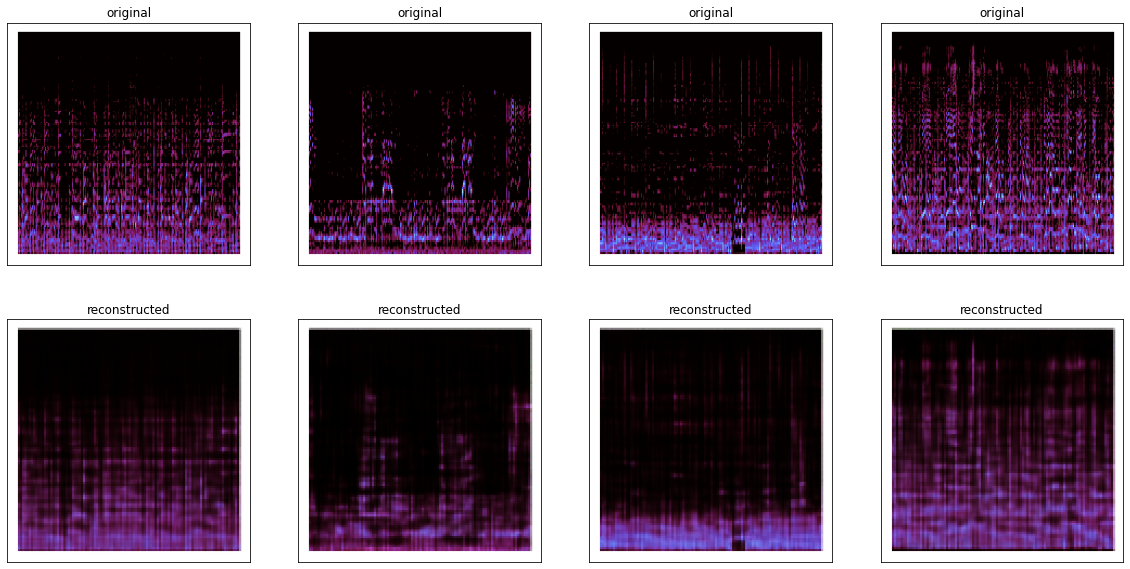
The reconstructed images showed that the Autoencoder manages to reconstruct our spectrograms highlighting the feature regions in the original images. The reconstruction has an overall blurriness to it due to the loss of low-level features during the encoding process. This was partially intentional as our motivation was to use this architecture to obtain encodings of high-level features of our spectrograms, which will later be used for our similarity checks. Now to select similar songs, first encodings for our dataset was obtained using the trained encoder. The encoder outputs a 7 x 7 x 512 matrix. This matrix is flattened for similarity measurement. Then songs were randomly selected with the motive being to find a song similar to every randomly selected song. Cosine Similarity & TS-SS Similarity, which has shown great performance, was used for measurement. On measuring, the encodings managed to find a couple of similar songs with a Cosine Similarity of 0.6 - 0.7. TS-SS Similarity ranges from 0 to ∞, thus the encoding which managed the smallest TS-SS relative to the others, was selected as a similar song.
6. Conclusion
From this experiment, we see it is possible to use a neural network such as an Autoencoder, which self-learns features, which can later be used as a representation of individual audio clips and compared with. On further speculation of our experiment, we noticed that the songs which came up in our selection, often managed to overlap in genre. On listening to the audio, we usually found our songs to have an overlapping instrument or sounds, for example a fast drum region, or a loud bass line, etc. It seems as if the encodings did manage to capture the nature of the song and our similarity measurement is find of other encodings with similar nature. This is to be tested further in the future with more computational power and a larger dataset. Furthermore, statistically testing the potency of our approach is also very difficult. Finding if two musical audio clips are similar or not is somewhat of a personal choice and changes from person to person. We can compare certain features which match and consider them to be similar, but still finding true similarity between music will require a more deep and extensive approach.
|
Figure 3. Original & Reconstructed Spectrograms. |
7. Future scope
Unlike using predefined characteristics of a sound wave like pitch, frequency and wavelength, our approach made use of the patterns made by the waves themselves, and features were learnt autonomously. It would be interesting to see how this performs on a very large dataset which would represent a real-world scenario. Our motivation to use GTZAN over the other, more recent and larger datasets, was the fact that GTZAN had a representation of how real-world music and playlists are. From our research, the newer datasets we were able to find were more audio oriented and less music oriented. It would also be exciting to test this with existing music recommendation solutions. Not in competition, but rather as an addition for improved recommendations. Us, the authors, have personally felt how lacklustre recommendations get. The current system just cannot do justice to the human nature of having a particular ‘taste’ in music.
References
[1]. Sathishkumar V E, Jaehyuk Cho, Malliga Subramanian, Obuli Sai Naren, ”Forest fire and smoke detection using deep learning based Learning without Forgetting”, Fire Ecology, vol. 10, pp. 1-17, 2023,
[2]. Malliga Subramanian, Sathishkumar V E, Jaehyuk Cho, Obuli Sai Naren, ”Multiple types of Cancer classification using CT/MRI images based on Learning without Forgetting powered Deep Learning Models”, IEEE Access, vol. 11, pp. 10336-10354, 2023,
[3]. Natesan P, Sathishkumar V E, Sandeep Kumar M, Maheswari Venkatesan, Prabhu Jayagopal, Shaikh Muhammad Allayear, ”A Distributed Framework for Predictive Analytics using Big Data and Map-Reduce Parallel Programming”, Mathematical Problems in Engineering, pp. 1-10, 2023,
[4]. Malliga Subramanian, Vani Rajasekar, Sathishkumar V E, Kogilavani Shanmugavadivel, PS Nandhini, ”Effectiveness of Decentralized Federated Learning Algorithms in Healthcare: A Case Study on Cancer Classification”, Electronics, vol. 11, no. 24, pp. 4117, 2022,
[5]. Kogilavani Shanmugavadivel, Sathishkumar V E, Sandhiya Raja, T Bheema Lingaiah, S Neelakandan, Malliga Subramanian, ”Deep learning based sentiment analysis and offensive language identification on multilingual code-mixed data”, Scientific Reports, vol. 12, no. 1, pp. 1-12, 2022,
[6]. Prakash Mohan, Sathishkumar V E, Neelakandan Subramani, Malliga Subramanian, Sangeetha Meckanzir, ”Handcrafted Deep-Feature-Based Brain Tumor Detection and Classification Using MRI Images”, Electronics, vol. 11, no. 24, pp. 4178, 2022,
[7]. Kogilavani Shanmugavadivel, Sathishkumar V E, M. Sandeep Kumar,V. Maheshwari,J. Prabhu,Shaikh Muhammad Allayear, ”Investigation of Applying Machine Learning and Hyperparameter Tuned Deep Learning Approaches for Arrhythmia Detection in ECG Images”, Computational and Mathematical Methods in Medicine, 2022.
[8]. J. Chinna Babu, M. Sandeep Kumar, Prabhu Jayagopal,Sathishkumar V E , Sukumar Rajendran, Sanjeev Kumar, Alagar Karthick, Akter Meem Mahseena, ”IoT-Based Intelligent System for Internal Crack Detection in Building Blocks”, Journal of Nanomaterials, 2022.
[9]. Bharat Subedi,Sathishkumar V E, V. Maheshwari, M. Sandeep Kumar, Prabhu Jayagopal, Shaikh Muhammad Allayear, ”Feature Learning-Based Generative Adversarial Network Data Augmentation for Class-Based Few-Shot Learning”, Mathematical Problems in Engineering, 2022.
[10]. N. Shanthi, Sathishkumar V E, K. Upendra Babu, P. Karthikeyan, Sukumar Rajendran, Shaikh Muhammad Allayear, ”Analysis on the Bus Arrival Time Prediction Model for Human-Centric Services Using Data Mining Techniques”, Computational Intelligence and Neuroscience, 2022.
[11]. E. Pavithra, Janakiramaiah, L.V.NarasimhaPrasad, D.Deepa, N.Jayapandian, Sathishkumar V E, ”Visiting Indian Hospitals Before, During and After Covid”, International Journal of Uncertainity, Fuzziness, and Knowledge- Based Systems, 2022.
[12]. Rajalaxmi R R, Narasimha Prasad, B. Janakiramaiah, C S Pavankumar, N Neelima, Sathishkumar V E, ”Optimizing Hyperparameters and Performance Analysis of LSTM Model in Detecting Fake News on Social media”,ACM Transactions on Asian and Low-Resource Language Information Processing, 2022,
[13]. Malliga Subramanian, M Sandeep Kumar, Sathishkumar V E, Jayagopal Prabhu, Alagar Karthick, S Sankar Ganesh, Mahseena Akter Meem, ”Diagnosis of Retinal Diseases Based on Bayesian Optimization Deep Learning Network Using Optical Coherence Tomography Images”, Computational Intelligence and Neuroscience, 2022,
[14]. Yufei, Liu, Sathishkumar V E, Adhiyaman Manickam, ”Augmented reality technology based on school physical education training”, Computers & Electrical Engineering, Vol. 99, 2022,
[15]. Malliga Subramanian, L.V. Narasimha Prasad, B. Janakiramaiah, A. Mohan Babu, Sathishkumar V E, ”Hyperparameter Optimization for Transfer Learning of VGG16 for Disease Identification in Corn Leaves Using Bayesian Optimization”, Big Data, 2021,
[16]. Kalaivani P C D, Sathishkumar V E, Wesam Atef Hatamleh, Kamel Dine Haouam, B. Venkatesh, Dirar Sweidan„ ”Advanced lightweight feature interaction in deep neural networks for improving the prediction in click through rate”, Annals of Operations Research, 2021,
[17]. Chen Zhongshan, Feng Xinning, Adhiyaman Manickam, Sathishkumar V E, ”Facial landmark detection using artificial intelligence techniques”, Annals of Operations Research, 2021,
[18]. Sita Kumari Kotha, Meesala Shobha Rani, Bharat Subedi, Anilkumar Chunduru, Aravind Karrothu, Bipana Neupane , Sathishkumar V E, ”A comprehensive review on secure data sharing in cloud environment”, Wireless Personal Communications, 2021,
[19]. Krishnamoorthy, L.V.Narasimha Prasad, C.S.Pavan Kumar, BharatSubedi, Haftom Baraki Abrahae, Sathishkumar V E, ”Rice Leaf Diseases Prediction using deep neural networks with transfer learning”, Environmental Research, Vol. 198, 111275, 2021.
Cite this article
Bordoloi,A.;Prasad,M.;Thumar,H.;Saloi,M.;Joshi,D.;Mahajan,S.;Abualigah,L. (2023). Feature Selection based Music Selection using Artificial Intelligence. Applied and Computational Engineering,8,761-767.
Data availability
The datasets used and/or analyzed during the current study will be available from the authors upon reasonable request.
Disclaimer/Publisher's Note
The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of EWA Publishing and/or the editor(s). EWA Publishing and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content.
About volume
Volume title: Proceedings of the 2023 International Conference on Software Engineering and Machine Learning
© 2024 by the author(s). Licensee EWA Publishing, Oxford, UK. This article is an open access article distributed under the terms and
conditions of the Creative Commons Attribution (CC BY) license. Authors who
publish this series agree to the following terms:
1. Authors retain copyright and grant the series right of first publication with the work simultaneously licensed under a Creative Commons
Attribution License that allows others to share the work with an acknowledgment of the work's authorship and initial publication in this
series.
2. Authors are able to enter into separate, additional contractual arrangements for the non-exclusive distribution of the series's published
version of the work (e.g., post it to an institutional repository or publish it in a book), with an acknowledgment of its initial
publication in this series.
3. Authors are permitted and encouraged to post their work online (e.g., in institutional repositories or on their website) prior to and
during the submission process, as it can lead to productive exchanges, as well as earlier and greater citation of published work (See
Open access policy for details).
References
[1]. Sathishkumar V E, Jaehyuk Cho, Malliga Subramanian, Obuli Sai Naren, ”Forest fire and smoke detection using deep learning based Learning without Forgetting”, Fire Ecology, vol. 10, pp. 1-17, 2023,
[2]. Malliga Subramanian, Sathishkumar V E, Jaehyuk Cho, Obuli Sai Naren, ”Multiple types of Cancer classification using CT/MRI images based on Learning without Forgetting powered Deep Learning Models”, IEEE Access, vol. 11, pp. 10336-10354, 2023,
[3]. Natesan P, Sathishkumar V E, Sandeep Kumar M, Maheswari Venkatesan, Prabhu Jayagopal, Shaikh Muhammad Allayear, ”A Distributed Framework for Predictive Analytics using Big Data and Map-Reduce Parallel Programming”, Mathematical Problems in Engineering, pp. 1-10, 2023,
[4]. Malliga Subramanian, Vani Rajasekar, Sathishkumar V E, Kogilavani Shanmugavadivel, PS Nandhini, ”Effectiveness of Decentralized Federated Learning Algorithms in Healthcare: A Case Study on Cancer Classification”, Electronics, vol. 11, no. 24, pp. 4117, 2022,
[5]. Kogilavani Shanmugavadivel, Sathishkumar V E, Sandhiya Raja, T Bheema Lingaiah, S Neelakandan, Malliga Subramanian, ”Deep learning based sentiment analysis and offensive language identification on multilingual code-mixed data”, Scientific Reports, vol. 12, no. 1, pp. 1-12, 2022,
[6]. Prakash Mohan, Sathishkumar V E, Neelakandan Subramani, Malliga Subramanian, Sangeetha Meckanzir, ”Handcrafted Deep-Feature-Based Brain Tumor Detection and Classification Using MRI Images”, Electronics, vol. 11, no. 24, pp. 4178, 2022,
[7]. Kogilavani Shanmugavadivel, Sathishkumar V E, M. Sandeep Kumar,V. Maheshwari,J. Prabhu,Shaikh Muhammad Allayear, ”Investigation of Applying Machine Learning and Hyperparameter Tuned Deep Learning Approaches for Arrhythmia Detection in ECG Images”, Computational and Mathematical Methods in Medicine, 2022.
[8]. J. Chinna Babu, M. Sandeep Kumar, Prabhu Jayagopal,Sathishkumar V E , Sukumar Rajendran, Sanjeev Kumar, Alagar Karthick, Akter Meem Mahseena, ”IoT-Based Intelligent System for Internal Crack Detection in Building Blocks”, Journal of Nanomaterials, 2022.
[9]. Bharat Subedi,Sathishkumar V E, V. Maheshwari, M. Sandeep Kumar, Prabhu Jayagopal, Shaikh Muhammad Allayear, ”Feature Learning-Based Generative Adversarial Network Data Augmentation for Class-Based Few-Shot Learning”, Mathematical Problems in Engineering, 2022.
[10]. N. Shanthi, Sathishkumar V E, K. Upendra Babu, P. Karthikeyan, Sukumar Rajendran, Shaikh Muhammad Allayear, ”Analysis on the Bus Arrival Time Prediction Model for Human-Centric Services Using Data Mining Techniques”, Computational Intelligence and Neuroscience, 2022.
[11]. E. Pavithra, Janakiramaiah, L.V.NarasimhaPrasad, D.Deepa, N.Jayapandian, Sathishkumar V E, ”Visiting Indian Hospitals Before, During and After Covid”, International Journal of Uncertainity, Fuzziness, and Knowledge- Based Systems, 2022.
[12]. Rajalaxmi R R, Narasimha Prasad, B. Janakiramaiah, C S Pavankumar, N Neelima, Sathishkumar V E, ”Optimizing Hyperparameters and Performance Analysis of LSTM Model in Detecting Fake News on Social media”,ACM Transactions on Asian and Low-Resource Language Information Processing, 2022,
[13]. Malliga Subramanian, M Sandeep Kumar, Sathishkumar V E, Jayagopal Prabhu, Alagar Karthick, S Sankar Ganesh, Mahseena Akter Meem, ”Diagnosis of Retinal Diseases Based on Bayesian Optimization Deep Learning Network Using Optical Coherence Tomography Images”, Computational Intelligence and Neuroscience, 2022,
[14]. Yufei, Liu, Sathishkumar V E, Adhiyaman Manickam, ”Augmented reality technology based on school physical education training”, Computers & Electrical Engineering, Vol. 99, 2022,
[15]. Malliga Subramanian, L.V. Narasimha Prasad, B. Janakiramaiah, A. Mohan Babu, Sathishkumar V E, ”Hyperparameter Optimization for Transfer Learning of VGG16 for Disease Identification in Corn Leaves Using Bayesian Optimization”, Big Data, 2021,
[16]. Kalaivani P C D, Sathishkumar V E, Wesam Atef Hatamleh, Kamel Dine Haouam, B. Venkatesh, Dirar Sweidan„ ”Advanced lightweight feature interaction in deep neural networks for improving the prediction in click through rate”, Annals of Operations Research, 2021,
[17]. Chen Zhongshan, Feng Xinning, Adhiyaman Manickam, Sathishkumar V E, ”Facial landmark detection using artificial intelligence techniques”, Annals of Operations Research, 2021,
[18]. Sita Kumari Kotha, Meesala Shobha Rani, Bharat Subedi, Anilkumar Chunduru, Aravind Karrothu, Bipana Neupane , Sathishkumar V E, ”A comprehensive review on secure data sharing in cloud environment”, Wireless Personal Communications, 2021,
[19]. Krishnamoorthy, L.V.Narasimha Prasad, C.S.Pavan Kumar, BharatSubedi, Haftom Baraki Abrahae, Sathishkumar V E, ”Rice Leaf Diseases Prediction using deep neural networks with transfer learning”, Environmental Research, Vol. 198, 111275, 2021.