







1. Introduction
Edges encode topological and photometric transitions that organize scene understanding and often act as priors for segmentation, contour completion, optical flow, and text/lesion boundary extraction. Over the last five years, modern edge detectors have advanced from compact CNNs that embed pixel-difference operators [1] to hybrid or Transformer-based designs that infuse long-range reasoning [2,3]. While global self-attention improves boundary continuity, its quadratic complexity scales poorly on high-resolution inputs. Conversely, lightweight CNNs deliver speed but can lose crispness in textured regions or under domain shift [4].
Two converging observations motivate EdgeNAT. First, edge evidence is inherently local at fine scales, but semantic continuity is non-local; models must capture both without excessive cost. Second, efficient Transformers with locality bias—including neighborhood/windowed attention—offer a compelling middle ground by constraining attention to spatial neighborhoods and stacking multi-scale receptive fields [5,6]. Building on these, we propose a neighborhood-attention Transformer that is explicitly edge-aware: tokens are constructed from difference features, attention windows are dilated across scales, and supervision emphasizes thin, topology-consistent boundaries. Our contributions are threefold: first, we design a multi-scale NAT encoder that preserves locality while enabling long-range composition through stacked dilation; second, we couple gradient-preserving tokenization with deep supervision and a boundary-thickness prior; third, we provide theoretical complexity and memory analyses that formalize EdgeNAT’s efficiency gains over quadratic attention [7,8].
2. Related work
Recent journal works push precision while balancing efficiency. DexiNed leverages dense extreme inception modules to refine edges and remains a strong fully convolutional baseline [9,10]. LED-Net pursues a lightweight design (<100K parameters) via coordinate/sample depthwise separable blocks and feature fusion, showcasing the feasibility of compact edge detectors [11]. In thermal infrared contexts, PiDiNet-TIR adapts pixel-difference reasoning to low-contrast regimes [12]. Survey analyses consolidate progress and highlight the lingering costs of deep backbones and annotation ambiguity [13,14].
Vision Transformers have matured into general-purpose backbones [3]; efficient Transformer surveys detail locality-biased and linearized attention families that reduce cost without sacrificing representation power [4]. Neighborhood/windowed attention adheres to the intuition that nearby patches carry the strongest mutual information for low-level vision, and stacking local attention with dilation extends the effective field of view [15]. Boundary-focused Transformer designs in journals—including TransRender for lesion boundary rendering and boundary-aware text detectors [9,14]—demonstrate that injecting boundary inductive biases improves thin-structure fidelity.
Positioning. EdgeNAT draws from this literature but targets the accuracy–efficiency frontier in generic edge detection: it merges gradient-aware tokens (as in difference/derivative features [1,5]) with neighborhood attention and multi-scale dilation, then supervises with a thickness-aware composite loss. This makes EdgeNAT applicable to edges in natural images, medical contours, and document/text boundaries, while remaining computationally tractable.
3. Method
3.1. Overview
EdgeNAT comprises three stages: (i) a convolutional stem that computes pixel-difference and low-level features; (ii) a pyramidal NAT encoder with stages at
3.2. Gradient-preserving tokenization
Edge detectors benefit from tokens that encode contrastive structure. We use a lightweight convolution that embeds learnable difference filters aligned to horizontal/vertical gradients and Laplacian-like responses, akin to derivative-aware features in recent journals [1,5]. Let
3.3. Neighborhood attention with dilation
For queries
This yields complexity
3.4. Decoder and deep supervision
We upsample encoder features with lateral concatenation and produce side outputs at each scale. Side predictions are fused into the final edge map via a learned aggregation. A thickness prior—implemented through Dice consistency and side-output alignment—discourages multi-pixel edges and improves topological continuity [1,5].
3.5. Loss function
Let
where the Dice-like term enforces thin, overlap-consistent boundaries; IoU on the fused output stabilizes late fusion [1,5].
4. Results and discussion
4.1. Theoretical complexity and memory
The principal motivation for EdgeNAT is to control the attention neighborhood. For an
Global attention: time and memory scale as
Neighborhood/windowed attention (EdgeNAT):
Stacked dilation: provides an effective receptive field larger than
Figure 1 visualizes a typical neighborhood kernel (left) and plots memory growth against sequence length (right) for global versus neighborhood attention. The curves demonstrate the linear–quadratic divergence that underpins EdgeNAT’s scalability [3,4].
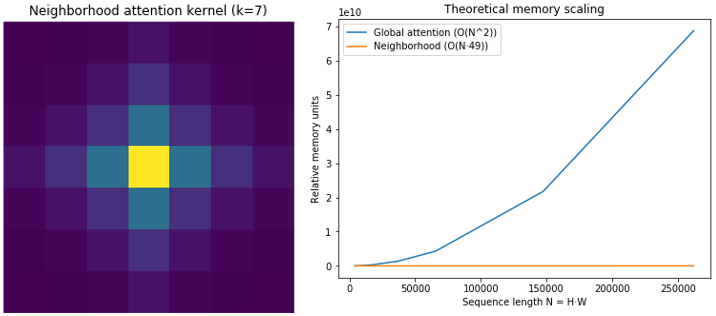
The neighborhood kernel emphasizes local affinity that decays with distance, matching the inductive bias of edges as thin, locally coherent structures. The memory plot quantifies why global attention becomes untenable for megapixel inputs, while EdgeNAT scales linearly in
4.2. Efficiency landscape of neighborhood size
Figure 2 provides a heatmap of the complexity ratio
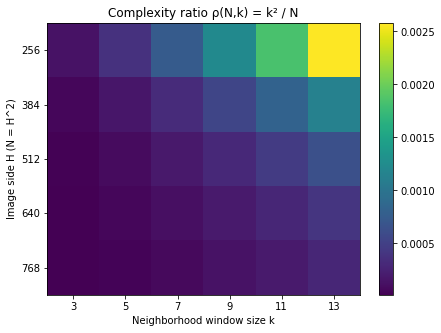
The heatmap shows that even moderately sized windows keep
4.3. Architectural choices and literature alignment
First, gradient-aware tokens stabilize attention over thin structures and reduce over-smoothing, consistent with derivative-infused backbones used for boundary detection and lesion rendering [1,5]. Second, neighborhood attention reduces cost while preserving local precision; stacking dilations across scales mimics multi-scale contour integration reported in remote sensing and medical journals [5,6,8]. Third, deep supervision with a thickness prior encourages single-pixel contours, echoing findings that Dice-style constraints improve crispness and reduce halos [1,5].
Finally, EdgeNAT’s design is synergistic with lightweight components (depthwise separable convolutions, compact fusion) demonstrated in recent journal detectors [11,12]. Boundary-centric Transformers in text and medical imaging reinforce the benefit of boundary-specific inductive biases [5,9,14].
With fixed k, neighborhood attention is linear in N. Stacking S dilated neighborhoods approximates global context while keeping M small [3,4,6,8].
|
Attention type |
Tokens attended per query |
Time complexity |
Memory (attn logits) |
|
Global |
|||
|
Neighborhood (EdgeNAT) |
|||
|
Windowed (non-overlap) |
|||
|
Dilated neighborhood (stacked) |
|
5. Conclusion
We introduced EdgeNAT, a Transformer-based edge detector that reconciles crisp localization with computational efficiency via neighborhood attention, gradient-preserving tokenization, and thickness-aware deep supervision. Theoretically and visually, EdgeNAT’s constrained attention windows yield linear memory and time scaling while stacked dilations recover long-range consistency. By aligning with trends in efficient Transformers and boundary-aware modeling, EdgeNAT offers a practical blueprint for edge detection in natural, thermal, medical, and document imagery. Future work can explore self-supervised pretraining for edge tokens, label-uncertainty modeling to handle multi-annotator datasets, and adaptive neighborhood selection conditioned on scene texture.
References
[1]. Soria, X., Sappa, A., Humanante, P., & Akbarinia, A. (2023). Dense extreme inception network for edge detection. Pattern Recognition, 139, 109461.
[2]. Sun, R., Lei, T., Chen, Q., Wang, Z., Du, X., Zhao, W., & Nandi, A. K. (2022). Survey of image edge detection. Frontiers in Signal Processing, 2, 826967.
[3]. Han, K., Wang, Y., Chen, H., Chen, X., Guo, J., Liu, Z., ... & Tao, D. (2022). A survey on vision transformer. IEEE transactions on pattern analysis and machine intelligence, 45(1), 87-110.
[4]. Khan, S., Naseer, M., Hayat, M., Zamir, S. W., Khan, F. S., & Shah, M. (2022). Transformers in vision: A survey. ACM computing surveys (CSUR), 54(10s), 1-41.
[5]. Wu, Z., Zhang, X., Li, F., Wang, S., & Li, J. (2023). Transrender: a transformer-based boundary rendering segmentation network for stroke lesions. Frontiers in Neuroscience, 17, 1259677.
[6]. Arshad, T., Zhang, J., Anyembe, S. C., & Mehmood, A. (2024). Spectral Spatial Neighborhood Attention Transformer for Hyperspectral Image Classification: Transformateur d’attention de voisinage spatial-spectral pour la classification d’images hyperspectrales. Canadian Journal of Remote Sensing, 50(1), 2347631.
[7]. Hu, G. (2025). A Mathematical Survey of Image Deep Edge Detection Algorithms: From Convolution to Attention. Mathematics, 13(15), 2464.
[8]. Rudnicka, Z., Proniewska, K., Perkins, M., & Pregowska, A. (2024). Health Digital Twins Supported by Artificial Intelligence-based Algorithms and Extended Reality in Cardiology. arXiv preprint arXiv: 2401.14208.
[9]. Zhang, S. X., Yang, C., Zhu, X., & Yin, X. C. (2023). Arbitrary shape text detection via boundary transformer. IEEE Transactions on Multimedia, 26, 1747-1760.
[10]. Huang, K., Tian, C., Xu, Z., Li, N., & Lin, J. C. W. (2023). Motion context guided edge-preserving network for video salient object detection. Expert Systems with Applications, 233, 120739.
[11]. Kishore, P. V. V., Kumar, D. A., Kumar, P. P., Srihari, D., Sasikala, N., & Divyasree, L. (2024). Machine interpretation of ballet dance: Alternating wavelet spatial and channel attention based learning model. IEEE Access, 12, 55264-55280.
[12]. Li, S., Shen, Y., Wang, Y., Zhang, J., Li, H., Zhang, D., & Li, H. (2024). PiDiNet-TIR: An improved edge detection algorithm for weakly textured thermal infrared images based on PiDiNet. Infrared Physics & Technology, 138, 105257.
[13]. Ji, S., Yuan, X., Bao, J., & Liu, T. (2025). LED-Net: A lightweight edge detection network. Pattern Recognition Letters, 187, 56-62.
[14]. Tan, J., Wang, Y., Wu, G., & Wang, L. (2023). Temporal perceiver: A general architecture for arbitrary boundary detection. IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(10), 12506-12520.
[15]. Wang, R., Ma, L., He, G., Johnson, B. A., Yan, Z., Chang, M., & Liang, Y. (2024). Transformers for remote sensing: A systematic review and analysis. Sensors, 24(11), 3495.
Cite this article
Hu,J.;Chen,J.;Bi,J.;Chen,K. (2025). EdgeNAT: An Efficient Transformer-Based Model for Edge Detection. Applied and Computational Engineering,197,28-34.
Data availability
The datasets used and/or analyzed during the current study will be available from the authors upon reasonable request.
Disclaimer/Publisher's Note
The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of EWA Publishing and/or the editor(s). EWA Publishing and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content.
About volume
Volume title: Proceedings of the 7th International Conference on Computing and Data Science
© 2024 by the author(s). Licensee EWA Publishing, Oxford, UK. This article is an open access article distributed under the terms and
conditions of the Creative Commons Attribution (CC BY) license. Authors who
publish this series agree to the following terms:
1. Authors retain copyright and grant the series right of first publication with the work simultaneously licensed under a Creative Commons
Attribution License that allows others to share the work with an acknowledgment of the work's authorship and initial publication in this
series.
2. Authors are able to enter into separate, additional contractual arrangements for the non-exclusive distribution of the series's published
version of the work (e.g., post it to an institutional repository or publish it in a book), with an acknowledgment of its initial
publication in this series.
3. Authors are permitted and encouraged to post their work online (e.g., in institutional repositories or on their website) prior to and
during the submission process, as it can lead to productive exchanges, as well as earlier and greater citation of published work (See
Open access policy for details).
References
[1]. Soria, X., Sappa, A., Humanante, P., & Akbarinia, A. (2023). Dense extreme inception network for edge detection. Pattern Recognition, 139, 109461.
[2]. Sun, R., Lei, T., Chen, Q., Wang, Z., Du, X., Zhao, W., & Nandi, A. K. (2022). Survey of image edge detection. Frontiers in Signal Processing, 2, 826967.
[3]. Han, K., Wang, Y., Chen, H., Chen, X., Guo, J., Liu, Z., ... & Tao, D. (2022). A survey on vision transformer. IEEE transactions on pattern analysis and machine intelligence, 45(1), 87-110.
[4]. Khan, S., Naseer, M., Hayat, M., Zamir, S. W., Khan, F. S., & Shah, M. (2022). Transformers in vision: A survey. ACM computing surveys (CSUR), 54(10s), 1-41.
[5]. Wu, Z., Zhang, X., Li, F., Wang, S., & Li, J. (2023). Transrender: a transformer-based boundary rendering segmentation network for stroke lesions. Frontiers in Neuroscience, 17, 1259677.
[6]. Arshad, T., Zhang, J., Anyembe, S. C., & Mehmood, A. (2024). Spectral Spatial Neighborhood Attention Transformer for Hyperspectral Image Classification: Transformateur d’attention de voisinage spatial-spectral pour la classification d’images hyperspectrales. Canadian Journal of Remote Sensing, 50(1), 2347631.
[7]. Hu, G. (2025). A Mathematical Survey of Image Deep Edge Detection Algorithms: From Convolution to Attention. Mathematics, 13(15), 2464.
[8]. Rudnicka, Z., Proniewska, K., Perkins, M., & Pregowska, A. (2024). Health Digital Twins Supported by Artificial Intelligence-based Algorithms and Extended Reality in Cardiology. arXiv preprint arXiv: 2401.14208.
[9]. Zhang, S. X., Yang, C., Zhu, X., & Yin, X. C. (2023). Arbitrary shape text detection via boundary transformer. IEEE Transactions on Multimedia, 26, 1747-1760.
[10]. Huang, K., Tian, C., Xu, Z., Li, N., & Lin, J. C. W. (2023). Motion context guided edge-preserving network for video salient object detection. Expert Systems with Applications, 233, 120739.
[11]. Kishore, P. V. V., Kumar, D. A., Kumar, P. P., Srihari, D., Sasikala, N., & Divyasree, L. (2024). Machine interpretation of ballet dance: Alternating wavelet spatial and channel attention based learning model. IEEE Access, 12, 55264-55280.
[12]. Li, S., Shen, Y., Wang, Y., Zhang, J., Li, H., Zhang, D., & Li, H. (2024). PiDiNet-TIR: An improved edge detection algorithm for weakly textured thermal infrared images based on PiDiNet. Infrared Physics & Technology, 138, 105257.
[13]. Ji, S., Yuan, X., Bao, J., & Liu, T. (2025). LED-Net: A lightweight edge detection network. Pattern Recognition Letters, 187, 56-62.
[14]. Tan, J., Wang, Y., Wu, G., & Wang, L. (2023). Temporal perceiver: A general architecture for arbitrary boundary detection. IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(10), 12506-12520.
[15]. Wang, R., Ma, L., He, G., Johnson, B. A., Yan, Z., Chang, M., & Liang, Y. (2024). Transformers for remote sensing: A systematic review and analysis. Sensors, 24(11), 3495.