







1. Introduction
AI technology is rapidly reshaping creative domains including literature, art, music, and film. The global AIGC market reached 13.5 billion USD in 2023 and is projected to exceed 70 billion USD by 2027. Technologies like ChatGPT, Midjourney, and DALL-E have moved AIGC from laboratories to public use. However, this poses severe challenges to existing copyright systems, particularly in creator identification, originality requirements, and interest balancing.
AIGC generates content through algorithms that learn and reorganize data, fundamentally differing from human-driven creation. Traditional copyright law emphasizes protecting human creators' rights, but AIGC blurs creator boundaries and challenges originality standards. Complex rights relationships form between AI developers, data providers, model users, and end users, yet existing legal frameworks lack clear attribution mechanisms [1]. The EU, US, and China have adopted different approaches to AIGC copyright protection. The EU emphasizes humanistic copyright stance through regulations like the Digital Single Market Copyright Directive. The US adjusts "originality" standards through judicial practice. China explores innovative systems reflected in policy documents like the "Guidelines on AI-Generated Content Copyright Protection." All three jurisdictions remain in early exploration stages with unresolved issues.
This study conducts comparative analysis of EU, US, and Chinese legislative paths in AIGC copyright protection. It examines historical development, legal texts, and empirical cases, focusing on creator recognition, originality standards, human involvement quantification, and balancing mechanisms. The study assesses each path's advantages and limitations and proposes improvement suggestions.
The research deepens understanding of copyright transformation in the AI age and provides references for improving AIGC copyright legislation. Through comparative analysis, it seeks balance between technological change and legal stability, contributing to copyright protection system construction for the AI era.
2. Dilemmas and challenges in AIGC copyright protection
The emergence of AI-generated content (AIGC) has broken the fundamental assumption of traditional copyright law, which centers on human creation, triggering a series of dilemmas in legal cognition and application. These dilemmas not only challenge the theoretical foundation of the existing copyright system but also test the ability of legislative and judicial institutions to respond to technological change. This chapter will systematically analyze the main dilemmas facing AIGC copyright protection and explore the underlying causes of these challenges.
2.1. Dilemma in the identification of creators: unclear rights attribution in human-ai collaboration
In the AIGC creation model, identifying the creator has become increasingly complex. Traditional copyright law defines creators as natural persons or their legal entities. However, AIGC involves multiple participants—AI developers, data providers, model operators, and users—making copyright attribution challenging. Currently, three main views exis, AI developers should hold copyright for creating the generative algorithm [2]; AI users deserve rights for influencing outputs through inputs;
All parties should share rights proportionally based on their contributions.
In Thaler v. U.S. Copyright Office (2022), Dr. Thaler sought copyright for a work created by his AI "Creativity Machine." The application was rejected, and the court ruled that current laws do not recognize non-human creators. This case illustrates the core dilemma: existing laws cannot accommodate AI as an independent creator.
A WIPO (2023) survey of 50 jurisdictions found over 85% still require "human creators" for copyright. In China, the Supreme People’s Court reaffirmed this in Dream Home v. Baidu, emphasizing that protected works must reflect human originality. This aligns with copyright’s humanistic tradition and its role in incentivizing human creativity. The dilemma stems from a temporal mismatch between law and technology. When copyright laws were formed, AI’s creative potential was unforeseeable. AIGC blurs human-machine boundaries, challenging the traditional “idea-expression” framework. More fundamentally, copyright aims to incentivize human innovation, while AI, lacking such needs, disrupts this foundational principle.
2.2. Originality standards and the challenge of AIGC
Originality, the core of copyright protection, traditionally refers to the unique expression of an author’s personality. AIGC’s generative process—reorganizing existing data—challenges this notion. AI creates content by identifying patterns in existing works, lacking "independent thought" or "creative expression," making originality hard to assess [3]. Studies reveal key differences between human and AI-generated works. For instance, a Stanford (2023) study found 60% of critics failed to distinguish between AI- and human-written stories. In visual arts, AI-generated works from tools like Midjourney have even won art prizes, intensifying debates on originality standards. Legal systems differ in defining originality: the EU requires a "personal imprint," the U.S. accepts "minimal creativity," and China emphasizes "independent completion." Yet all struggle to apply these standards to AI, whose creations stem from learning and imitation rather than personal expression. The core issue lies in the mismatch between human-centered creativity and AI’s data-driven outputs. AI’s "originality" is a recombination of existing elements, blurring the lines between creation and replication. As AI technology advances, subjective methods of assessing originality become increasingly inadequate.
2.3. The dilemma of quantifying human participation: the uncertainty of evaluating creative contributions
Human involvement in AIGC creation varies widely—from simple prompts to complex edits—making it difficult to quantify creative input [4]. This variability poses a challenge for assigning copyright in human-AI collaboration. Research shows human guidance significantly impacts AIGC outputs. For instance, prompt changes in ChatGPT led to 65% variation in text uniqueness (MIT, 2023), while Midjourney’s founder claimed prompts could enhance image quality by 300%. These findings highlight that human input affects not just content, but also its creativity and cultural value. Legal systems differ in addressing human participation. The U.S. requires "creative contributions from human authors" and outlines assessment criteria. The EU emphasizes "substantial human intervention," while China adopts a flexible "human-led creation" approach, allowing some copyright space for AIGC. The core challenge lies in traditional copyright’s assumption of human creativity, lacking tools to measure contributions objectively. As AI blurs the human-machine boundary, subjective evaluation becomes inadequate—especially across diverse content types like text, images, or code. Moreover, creativity’s inherently subjective nature, shaped by cultural and value systems, further complicates quantification.
2.4. Coordination dilemma with the traditional copyright system: conflicts between rights balancing and social values
AIGC disrupts not only copyright concepts but also system coordination in rights balancing, term setting, and exceptions [5]. This reflects tensions between innovation and legal adaptation. Training data use is a central issue. Over 20 global lawsuits, such as Getty Images v. Stability AI, allege unauthorized use of copyrighted works in model training. These cases reveal the conflict between AI’s data needs and copyright protection. AIGC also challenges copyright duration. Traditional terms are linked to human life spans, but AI creates content at unprecedented speed. Some scholars suggest shorter terms for AIGC to balance innovation and public interest. Exceptions like fair use need redefinition. AI’s large-scale data use complicates traditional standards. For example, OpenAI claims fair use, while publishers dispute this. Such cases highlight the need to update fair use criteria in the AI era. At root, the dilemma stems from copyright law’s historical rigidity and AI’s disruptive nature. Beyond legal mechanics, it reflects deeper value conflicts: fostering innovation vs. protecting creators, promoting efficiency vs. preserving cultural diversity, enabling information flow vs. avoiding algorithmic monopolies. Resolving these requires institutional innovation (Figure 1).
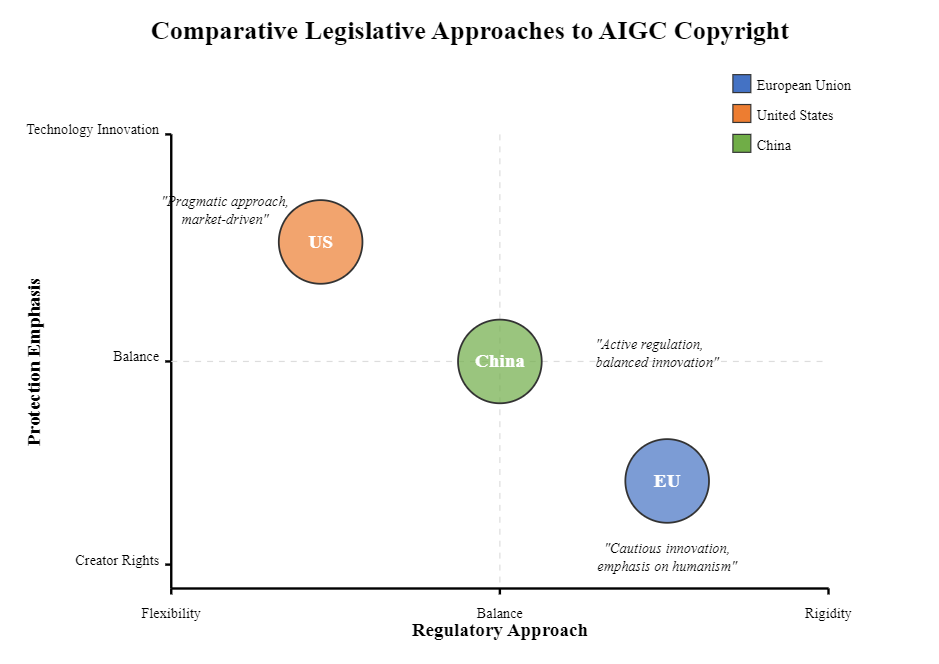
3. Comparison of legislative approaches to AIGC copyright protection in the EU, the US, and china
With the rise of AI-generated content (AIGC), legal systems across the European Union, the United States, and China are taking distinct approaches to regulating copyright. These differences reflect not only divergent legal traditions but also varying policy orientations toward innovation, human authorship, and digital sovereignty. This chapter compares their legal paths in terms of legislative frameworks, human authorship standards, and training data governance [6].
3.1. European union: a human-centric and cautious approach
The EU emphasizes a human-centric framework, rooted in civil law traditions and cultural diversity. Copyright protection is explicitly tied to “original intellectual creation” by a human author, as reaffirmed in the Infopaq and Painer decisions of the Court of Justice of the European Union (CJEU). This excludes purely machine-generated works from protection under current law. Directive (EU) 2019/790 on Copyright in the Digital Single Market introduces a dual-layered regulation of text and data mining (TDM). While non-commercial uses enjoy a general exception, commercial TDM requires rights holders to opt out explicitly. This reflects a balanced strategy: encouraging AI development through lawful data access while preserving copyright holders’ economic interests. However, the EU has not yet established specific legal categories for AIGC outputs or clarified liability in the context of generative models. The pending AI Act focuses more on risk regulation than on intellectual property, leaving a gap in addressing output authorship and fair use of training data [7].
3.2. United states: innovation-oriented and market-driven
The U.S. adopts a pragmatic, innovation-first approach, underpinned by a common law system that prioritizes economic incentives and market efficiency. Copyright law in the U.S., governed by the Copyright Act of 1976, limits protection to works created by a human author. This principle was reaffirmed in recent USPTO and court rulings, such as Thaler v. Perlmutter, which rejected copyright claims over AI-generated images lacking human creativity. Despite this, the U.S. approach allows greater flexibility under the fair use doctrine. In Authors Guild v. Google, the court deemed large-scale digitization for search indexing as transformative and non-infringing. This precedent has been invoked in defense of using copyrighted material to train generative AI models. Ongoing lawsuits—such as Andersen v. Stability AI—may test these boundaries and determine whether model training constitutes fair use. Unlike the EU, the U.S. lacks specific legislation for TDM or AIGC. Instead, case-by-case judicial interpretations guide application. This legal uncertainty provides room for innovation but also raises compliance and enforcement risks, especially as large language models increasingly replicate original expression.
3.3. China: a proactive and policy-responsive model
China is advancing a more integrated and policy-driven legislative path. Its copyright law retains the requirement of “human intellectual activity,” aligning with the civil law notion of authorial intention. However, administrative agencies and courts have shown greater willingness to protect AIGC under neighboring rights or anti-unfair competition law if substantial human input is involved.
Recent judicial decisions, such as the Guangzhou Internet Court’s ruling on AI-assisted images, suggest that where a user exercises meaningful control over input and model parameters, the resulting output may qualify for copyright protection. This hybrid approach blurs the line between full automation and human-guided generation.
On the legislative front, China has incorporated data governance into its broader digital economy strategy. The Personal Information Protection Law (PIPL) and Data Security Law (DSL) impose strict requirements on data collection, processing, and cross-border transfers. These laws affect the legality of training datasets used in foundation models like Ernie Bot or WuDao.
Moreover, draft regulations on generative AI released by the Cyberspace Administration of China (CAC) require AIGC providers to ensure content truthfulness, respect copyright, and avoid algorithmic discrimination. These rules indicate a governance model that merges content regulation, IP protection, and social responsibility [8].
4. Conclusion
This study highlights the mismatch between traditional human-centric copyright law and the rise of AI-generated content (AIGC). Core challenges include authorship, originality, human input assessment, and legal compatibility. The EU, US, and China adopt distinct but complementary approaches, shaped by their legal traditions. To address these issues, the study proposes: redefining authorship via contribution thresholds, adopting adaptive originality standards, creating tiered rights for AIGC, and balancing interests through coordinated mechanisms. An effective AIGC framework must be adaptive, inclusive, and balanced—supported by legal, technological, and market systems. The research contributes by extending copyright theory and offering practical guidance for future policy in the AI era.
References
[1]. Kuai, J. (2024). Unravelling copyright dilemma of AI-generated news and its implications for the institution of journalism: The cases of US, EU, and China. new media & society, 26(9), 5150-5168.
[2]. Kumar, S. , & Yadav, A. (2024, October). Recent trends in major world jurisdictions regarding copyright law and works generated by artificial intelligence: A comparative analysis of the European union, the United States, and Japan. In AIP Conference Proceedings (Vol. 3220, No. 1). AIP Publishing.
[3]. Zhuk, A. (2024). Navigating the legal landscape of AI copyright: a comparative analysis of EU, US, and Chinese approaches. AI and Ethics, 4(4), 1299-1306.
[4]. Rubaba, H. , Janb, M. , Nisarc, K. , & Noord, S. (2024). Copyright and AI-Generated Content: A Comparative Analysis of Legal Perspectives in China and the United States. International Journal of Social Science Archives (IJSSA), 7(2).
[5]. Le, T. P. V. (2024). Copyright Protection towards Generative AI Artworks: The “Clash” between US v. China and the Implications for the European Union.
[6]. Mushtaq, S. A. , Baig, K. , Bukhari, S. W. R. , & Ahmad, W. (2024). Does Pakistan's Copyright and Antitrust Law Protect Creators of AI-Generated Content? A Comparative Study with European Union Jurisdictions. Pakistan Journal of Criminal Justice, 4(1), 55-76.
[7]. He, T. (2019). The sentimental fools and the fictitious authors: rethinking the copyright issues of AI-generated contents in China. Asia Pacific Law Review, 27(2), 218-238.
[8]. He, X. , & Fang, L. (2024). Regulatory Challenges in Synthetic Media Governance: Policy Frameworks for AI-Generated Content Across Image, Video, and Social Platforms. Journal of Robotic Process Automation, AI Integration, and Workflow Optimization, 9(12), 36-54.
Cite this article
Wang,H. (2025). The Copyright Protection Dilemma of AI-Generated Content: A Comparative Study of Legislative Approaches in the European Union, the United States, and China. Lecture Notes in Education Psychology and Public Media,90,7-12.
Data availability
The datasets used and/or analyzed during the current study will be available from the authors upon reasonable request.
Disclaimer/Publisher's Note
The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of EWA Publishing and/or the editor(s). EWA Publishing and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content.
About volume
Volume title: Proceedings of the 3rd International Conference on Global Politics and Socio-Humanities
© 2024 by the author(s). Licensee EWA Publishing, Oxford, UK. This article is an open access article distributed under the terms and
conditions of the Creative Commons Attribution (CC BY) license. Authors who
publish this series agree to the following terms:
1. Authors retain copyright and grant the series right of first publication with the work simultaneously licensed under a Creative Commons
Attribution License that allows others to share the work with an acknowledgment of the work's authorship and initial publication in this
series.
2. Authors are able to enter into separate, additional contractual arrangements for the non-exclusive distribution of the series's published
version of the work (e.g., post it to an institutional repository or publish it in a book), with an acknowledgment of its initial
publication in this series.
3. Authors are permitted and encouraged to post their work online (e.g., in institutional repositories or on their website) prior to and
during the submission process, as it can lead to productive exchanges, as well as earlier and greater citation of published work (See
Open access policy for details).
References
[1]. Kuai, J. (2024). Unravelling copyright dilemma of AI-generated news and its implications for the institution of journalism: The cases of US, EU, and China. new media & society, 26(9), 5150-5168.
[2]. Kumar, S. , & Yadav, A. (2024, October). Recent trends in major world jurisdictions regarding copyright law and works generated by artificial intelligence: A comparative analysis of the European union, the United States, and Japan. In AIP Conference Proceedings (Vol. 3220, No. 1). AIP Publishing.
[3]. Zhuk, A. (2024). Navigating the legal landscape of AI copyright: a comparative analysis of EU, US, and Chinese approaches. AI and Ethics, 4(4), 1299-1306.
[4]. Rubaba, H. , Janb, M. , Nisarc, K. , & Noord, S. (2024). Copyright and AI-Generated Content: A Comparative Analysis of Legal Perspectives in China and the United States. International Journal of Social Science Archives (IJSSA), 7(2).
[5]. Le, T. P. V. (2024). Copyright Protection towards Generative AI Artworks: The “Clash” between US v. China and the Implications for the European Union.
[6]. Mushtaq, S. A. , Baig, K. , Bukhari, S. W. R. , & Ahmad, W. (2024). Does Pakistan's Copyright and Antitrust Law Protect Creators of AI-Generated Content? A Comparative Study with European Union Jurisdictions. Pakistan Journal of Criminal Justice, 4(1), 55-76.
[7]. He, T. (2019). The sentimental fools and the fictitious authors: rethinking the copyright issues of AI-generated contents in China. Asia Pacific Law Review, 27(2), 218-238.
[8]. He, X. , & Fang, L. (2024). Regulatory Challenges in Synthetic Media Governance: Policy Frameworks for AI-Generated Content Across Image, Video, and Social Platforms. Journal of Robotic Process Automation, AI Integration, and Workflow Optimization, 9(12), 36-54.