







1. Introduction
With the wide application of motors in industry, transportation, home appliances and other fields, the requirements for motor performance are getting higher and higher, among which the excitation current of constant speed AC motor is one of its important performance indicators [1]. Although the traditional physical model-based method can accurately calculate the motor’s excitation current, it requires a large number of physical parameters and experimental data, which is costly and difficult to popularize [2]. Therefore, the research of predicting the excitation current of constant speed AC motor based on machine learning algorithm has important practical significance.
The machine learning algorithm can automatically learn the pattern and rule of the excitation current of constant speed AC motor by learning a large amount of data, so as to achieve the prediction of the excitation current [3,4]. For example, the constant speed AC motor excitation current prediction model based on support vector regression algorithm can make use of a large amount of historical data to establish a nonlinear regression model, so as to achieve the prediction of excitation current [5]. In addition, the constant speed AC motor excitation current prediction model based on neural network can automatically learn the nonlinear characteristics of the motor by learning a large amount of data, so as to achieve the prediction of excitation current [6]. In addition, there are also constant speed AC motor excitation current prediction models based on machine learning algorithms such as decision tree and random forest [7,8].
Some researchers conducted a research on the prediction of constant speed AC motor excitation current based on support vector regression algorithm. By collecting a large number of motor operation data and experimental data, a support vector regression model was established, and experimental verification and error analysis of the model were carried out. The results show that the model has high prediction accuracy and robustness. [9] In addition, other researchers have conducted research on the prediction of constant-speed AC motor’s excitation current based on neural network, established a multi-layer perceptron model by collecting a large amount of motor operation data and experimental data, and conducted experimental verification and error analysis of the model. The results show that the model has high prediction accuracy and generalization ability [10].
Based on various machine learning algorithms for the excitation current of constant speed AC motor, this paper uses evaluation indexes to evaluate the prediction effect of each model.
2. Data set introduction
This Synchronous motor data set:
(http://archive.ics.uci.edu/dataset/607/synchronous+machine+data+set), ac SM is constant speed motor, this task is to create data sets of machine learning model to estimate the excitation current of the SM, The dataset consists of five features, They are Load current, Power factor, Power factor error, Change of excitation current of Synchronous motor and Synchronous motor excitation current, where Synchronous motor excitation current is the target variable, the synchronous motor dataset contains 471 data.The result is shown in Table 1.
Table 1. Data set introduction.
Load current | Power factor | Power factor error | Change of excitation current of synchronous motor | Synchronous motor excitation current |
1 | 66 | 34 | 397 | 577 |
1 | 68 | 32 | 414 | 594 |
1 | 7 | 3 | 442 | 622 |
1 | 72 | 28 | 369 | 549 |
1 | 74 | 26 | 385 | 565 |
1 | 76 | 24 | 31 | 49 |
1 | 78 | 22 | 325 | 505 |
1 | 8 | 2 | 349 | 529 |
1 | 82 | 18 | 27 | 45 |
3. Various machine learning algorithms
In the field of machine learning, Decision tree regression model, Random forest regression model, adaboost regression model, Gradient lifting tree regression model, ExtraTrees regression model, CatBoost regression model and K nearest neighbo r regression models are common regression models.
3.1. Decision tree regression model
A decision tree regression model is a tree-based model that predicts results by splitting data. Each node of the decision tree represents a feature, each branch represents a value of this feature, and the final leaf node represents the prediction result. The decision tree model can handle both discrete and continuous features, and it performs well in processing high-dimensional data. The disadvantage of decision tree model is that it is easy to overfit, and pruning operations are needed to improve the generalization ability of the model.
3.2. Random forest regression model
Random forest regression model is a model based on ensemble learning, which improves the accuracy of the model by combining multiple decision trees. Each decision tree is built based on different samples and features, so each tree is independent. When forecasting, the random forest model averages or votes on the predicted results of each decision tree to get the final predicted result. The random forest model can handle high-dimensional data and missing values, and it performs well when dealing with complex data.
3.3. Adaboost regression model
The adaboost regression model is an ensemble learning method that builds multiple weak classifiers by constantly adjusting sample weights and combining them into one strong classifier. In each iteration, the adaboost model adjusts the sample weights according to the classification results of the previous round, so that the sample weights of the classification errors are higher. It then builds new weak classifiers based on the adjusted sample weights. The final prediction is the weighted sum of all the weak classifiers. adaboost model is suitable for processing high-dimensional data and complex data, but it is sensitive to noisy data.
3.4. Gradient lifting tree regression model
The gradient lift tree regression model is also a model based on ensemble learning, which improves the accuracy of the model by combining multiple decision trees. Different from random forests, the gradient tree model builds multiple decision trees iteratively. In each iteration, the model builds a new decision tree based on the residuals from the previous round. The final prediction is the weighted sum of all decision trees. The gradient lifting tree model can deal with high dimensional data and complex data, and it performs well in nonlinear data processing.
3.5. ExtraTrees regression model
The ExtraTrees regression model is also a model based on ensemble learning, which is similar to the random forest model, but uses more randomness in building the decision tree. At each node, the ExtraTrees model randomly selects some features for segmentation, rather than selecting the optimal feature. This method can effectively reduce the variance of the model and improve the generalization ability of the model. The ExtraTrees model can handle high-dimensional data and missing values, and it performs well when dealing with noisy data.
3.6. CatBoost regression model
The CatBoost regression model is a gradient lift tree model that automatically handles classification features and missing values and performs well when dealing with large data. Unlike other gradient lift tree models, the CatBoost model uses a special optimization method that reduces the risk of overfitting the model. CatBoost model can handle high-dimensional data and complex data, and it performs well when dealing with nonlinear data.
3.7. K nearest neighbor regression model
K nearest neighbor regression model is a distance-based model that performs classification or regression by calculating the distance between samples. When predicting, the model selects the K training samples that are closest to the test sample and uses their labels or values to predict the labels or values of the test sample. The K nearest neighbor model is suitable for processing high-dimensional and complex data, but more data is needed to achieve better performance.
To sum up, Decision tree regression model, Random forest regression model, adaboost regression model, Gradient lifting tree regression model, ExtraTrees regression model, CatBoost regression model and K nearest neighbo r regression models have their own characteristics and application scenarios, we need to choose the right model according to the specific problems.
4. Machine learning results analysis
Divide the data set into the training set and the test set in a 7:3 ratio. Decision tree regression model, Random forest regression model, adaboost regression model, Gradient lifting tree regression model, ExtraTrees regression model, CatBoost regression model and K nearest are used respectively neighbor regression model was trained, and evaluation indexes MSE, RMSE, MAE, MAPE and R² of the model were calculated. The calculation results were shown in Figure 1 and Figure 2:
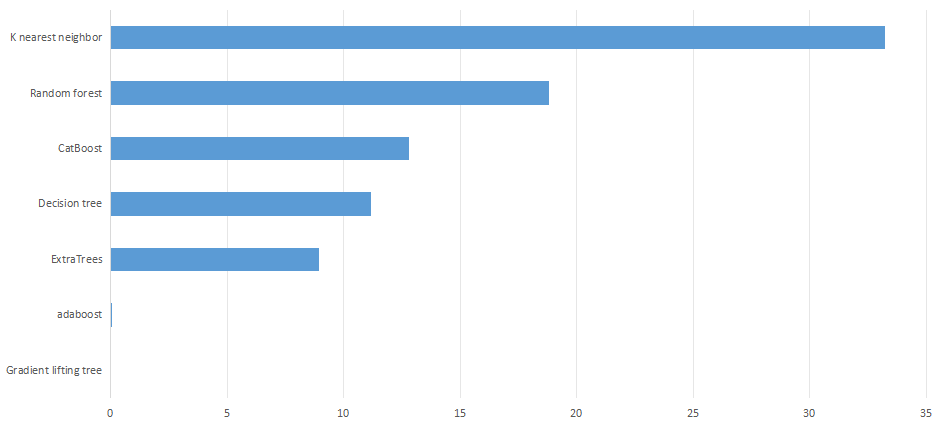
Figure 1. MAE. (Photo credit : Original)
Table 2. Machine learning results.
MSE | RMSE | MAE | MAPE | R² | |
Decision tree | 11.182 | 3.344 | 2.737 | 1.258 | 1 |
Random forest | 18.806 | 4.337 | 1.782 | 1.301 | 1 |
adaboost | 0.055 | 0.234 | 0.036 | 0.016 | 1 |
Gradient lifting tree | 0.002 | 0.006 | 0.005 | 0.005 | 1 |
ExtraTrees | 8.929 | 2.988 | 1.425 | 1.236 | 1 |
CatBoost | 12.799 | 3.578 | 2.879 | 1.686 | 1 |
K nearest neighbor | 33.205 | 5.762 | 2.836 | 1.963 | 0.999 |
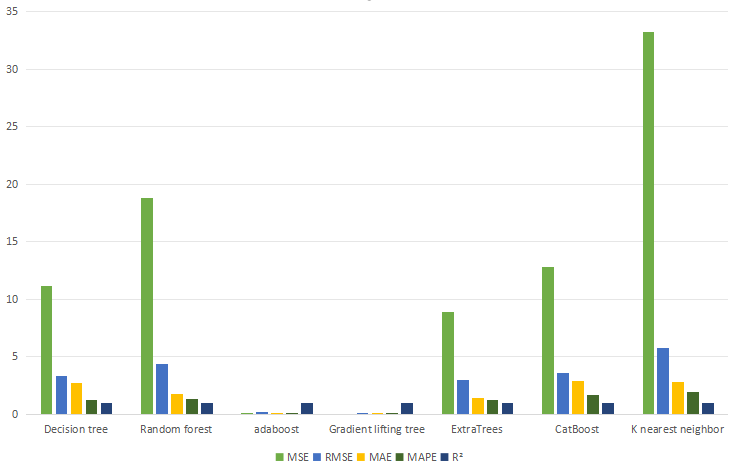
Figure 2. Machine learning results. (Photo credit : Original)
According to the results of model evaluation parameters, the best prediction effect is Gradient lifting tree model, whose MSE reaches 0.002. The adaboost model has the second best performance, and its MSE reaches 0.055. The performance of CatBoost, Decision tree and CatBoost is average, while the performance of K nearest neighbor is the worst, with an MSE of 33.205.
5. Conclusion
In the field of machine learning, choosing the right model is critical to the performance of the model. Here, this paper compares five different models: Gradient lifting tree model, adaboost model, CatBoost model, Decision tree model and K nearest neighbor model. As can be seen from the parameter results of model evaluation, the Gradient lifting tree model performs best, followed by the adaboost model, and the K nearest neighbor model performs worst.
The Gradient lifting tree model is an ensemble learning method that improves the accuracy of the model by combining multiple decision trees. Each decision tree is built based on the error of the previous tree, so each tree improves on the previous tree, resulting in a more accurate model. In contrast, the adaboost model is also an ensemble learning method, but its thinking is different from the Gradient lifting tree model. The adaboost model builds multiple weak classifiers by constantly adjusting the sample weights and combining them into one strong classifier. This method can effectively improve the accuracy of the model, especially when dealing with complex data.
The CatBoost model is a gradient lift tree model that automatically handles classification features and missing values and performs well when dealing with large data. The Decision tree model is a tree-based model that can predict the result by dividing the data. K nearest neighbor model is a distance-based model, which calculates the distance between samples to perform classification or regression. All three of these models are common machine learning models, but their performance is relatively mediocre, probably because they don’t handle complex data well or require more data to perform better.
Gradient lifting tree model and adaboost model are both models based on ensemble learning method, which can effectively improve the accuracy of the models. Both of these models are more suitable for dealing with complex data, so they perform better on this dataset. In contrast, CatBoost, Decision tree, and K nearest neighbor models perform relatively poorly when dealing with complex data, probably because they don’t handle this type of data well. In addition, the K nearest neighbor model requires more data to perform better, and the amount of data on this dataset may not be large enough.
In summary, choosing the right machine learning model is critical to the accuracy of the model. Here, we compare five different models and analyze why they perform well. In practical application, it is necessary to select the appropriate model according to the specific problem, and adjust and optimize it to achieve better performance.
References
[1]. Runyu Z ,Lei L ,Zhaojing W , et al. Guaranteed cost fault-tolerant control for uncertain stochastic systems via dynamic event-triggered adaptive dynamic programming[J]. Journal of the Franklin Institute,2023,360(16).
[2]. Qian L ,Seng C P . An Extended McKean–Vlasov Dynamic Programming Approach to Robust Equilibrium Controls Under Ambiguous Covariance Matrix[J]. Applied Mathematics & Optimization,2023,88(3).
[3]. Arezoo R ,Mahboobeh H ,Abed S H . A dynamic programming approach to multi-objective logic synthesis of quantum circuits[J]. Quantum Information Processing,2023,22(10).
[4]. Silabrata P ,Yu-Ting L ,Shuhao L , et al. Stochastic optimal control of mesostructure of supramolecular assemblies using dissipative particle dynamics and dynamic programming with experimental validation[J]. Chemical Engineering Journal,2023,475.
[5]. Mani G ,Gnanaprakasam J A ,Guran L , et al. Some Results in Fuzzy b -Metric Space with b -Triangular Property and Applications to Fredholm Integral Equations and Dynamic Programming[J]. Mathematics,2023,11(19).
[6]. Ming L ,Qiuhong L ,Lixian Z , et al. Adaptive dynamic programming-based fault-tolerant attitude control for flexible spacecraft with limited wireless resources[J]. Science China Information Sciences,2023,66(10).
[7]. Zhang X ,Liu Z ,Ding T , et al. Multi‐stage stochastic dual dynamic programming to low‐carbon economic dispatch for power systems with flexible carbon capture and storage devices[J]. IET Generation, Transmission & Distribution,2023,17(19).
[8]. Kedi X ,Yiwei Z ,Weiyao L , et al. Adaptive optimal output regulation of unknown linear continuous-time systems by dynamic output feedback and value iteration[J]. Control Engineering Practice,2023,141.
[9]. Chowdary D S ,Sudhakar M . Multi-objective Floorplanning optimization engaging dynamic programming for system on chip[J]. Microelectronics Journal,2023,140.
[10]. Mengshu S ,Yuansheng H . Dynamic planning and energy management strategy of integrated charging and hydrogen refueling at highway energy supply stations considering on-site green hydrogen production[J]. International Journal of Hydrogen Energy,2023,48(77).
Cite this article
Mo,M.;Tan,F.;Ding,H.;Ge,N. (2024). Comparison and analysis of various machine learning algorithms in predicting the excitation current of constant speed AC motor. Applied and Computational Engineering,65,15-20.
Data availability
The datasets used and/or analyzed during the current study will be available from the authors upon reasonable request.
Disclaimer/Publisher's Note
The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of EWA Publishing and/or the editor(s). EWA Publishing and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content.
About volume
Volume title: Proceedings of Urban Intelligence: Machine Learning in Smart City Solutions - CONFSEML 2024
© 2024 by the author(s). Licensee EWA Publishing, Oxford, UK. This article is an open access article distributed under the terms and
conditions of the Creative Commons Attribution (CC BY) license. Authors who
publish this series agree to the following terms:
1. Authors retain copyright and grant the series right of first publication with the work simultaneously licensed under a Creative Commons
Attribution License that allows others to share the work with an acknowledgment of the work's authorship and initial publication in this
series.
2. Authors are able to enter into separate, additional contractual arrangements for the non-exclusive distribution of the series's published
version of the work (e.g., post it to an institutional repository or publish it in a book), with an acknowledgment of its initial
publication in this series.
3. Authors are permitted and encouraged to post their work online (e.g., in institutional repositories or on their website) prior to and
during the submission process, as it can lead to productive exchanges, as well as earlier and greater citation of published work (See
Open access policy for details).
References
[1]. Runyu Z ,Lei L ,Zhaojing W , et al. Guaranteed cost fault-tolerant control for uncertain stochastic systems via dynamic event-triggered adaptive dynamic programming[J]. Journal of the Franklin Institute,2023,360(16).
[2]. Qian L ,Seng C P . An Extended McKean–Vlasov Dynamic Programming Approach to Robust Equilibrium Controls Under Ambiguous Covariance Matrix[J]. Applied Mathematics & Optimization,2023,88(3).
[3]. Arezoo R ,Mahboobeh H ,Abed S H . A dynamic programming approach to multi-objective logic synthesis of quantum circuits[J]. Quantum Information Processing,2023,22(10).
[4]. Silabrata P ,Yu-Ting L ,Shuhao L , et al. Stochastic optimal control of mesostructure of supramolecular assemblies using dissipative particle dynamics and dynamic programming with experimental validation[J]. Chemical Engineering Journal,2023,475.
[5]. Mani G ,Gnanaprakasam J A ,Guran L , et al. Some Results in Fuzzy b -Metric Space with b -Triangular Property and Applications to Fredholm Integral Equations and Dynamic Programming[J]. Mathematics,2023,11(19).
[6]. Ming L ,Qiuhong L ,Lixian Z , et al. Adaptive dynamic programming-based fault-tolerant attitude control for flexible spacecraft with limited wireless resources[J]. Science China Information Sciences,2023,66(10).
[7]. Zhang X ,Liu Z ,Ding T , et al. Multi‐stage stochastic dual dynamic programming to low‐carbon economic dispatch for power systems with flexible carbon capture and storage devices[J]. IET Generation, Transmission & Distribution,2023,17(19).
[8]. Kedi X ,Yiwei Z ,Weiyao L , et al. Adaptive optimal output regulation of unknown linear continuous-time systems by dynamic output feedback and value iteration[J]. Control Engineering Practice,2023,141.
[9]. Chowdary D S ,Sudhakar M . Multi-objective Floorplanning optimization engaging dynamic programming for system on chip[J]. Microelectronics Journal,2023,140.
[10]. Mengshu S ,Yuansheng H . Dynamic planning and energy management strategy of integrated charging and hydrogen refueling at highway energy supply stations considering on-site green hydrogen production[J]. International Journal of Hydrogen Energy,2023,48(77).