







1. Introduction
Natural Language Processing (NLP) stands at the forefront of artificial intelligence, aiming to bridge the gap between human communication and machine understanding. Over the years, the evolution of NLP has been marked by significant advancements in machine learning models, with deep learning emerging as a powerful paradigm shift in the field. This introduction provides a comprehensive overview of the journey of NLP, from its early reliance on statistical models to the transformative impact of deep learning architectures. The early days of NLP were characterized by the dominance of statistical models, such as Hidden Markov Models (HMMs) and Conditional Random Fields (CRFs). These models relied heavily on handcrafted features and linear classifiers to process textual data. While effective to some extent, they faced limitations in capturing the intricate linguistic patterns and contextual nuances inherent in language. The transition to neural network architectures marked a significant turning point in NLP, heralding a shift towards data-driven methodologies and unlocking new possibilities for language understanding and generation. Neural network architectures, particularly Recurrent Neural Networks (RNNs) and Long Short-Term Memory networks (LSTMs), revolutionized NLP by offering a more flexible and robust framework for processing textual data. These models excel in capturing long-range dependencies and contextual information, enabling them to comprehend and generate natural language text with unprecedented levels of accuracy and sophistication. Moreover, the introduction of transformer-based models, such as BERT (Bidirectional Encoder Representations from Transformers) and GPT (Generative Pre-trained Transformer), has further pushed the boundaries of NLP, enabling deep contextual understanding and generation of text at scale. The integration of deep learning in traditional NLP tasks has catalyzed significant advancements across various domains, including sentiment analysis, machine translation, and automated content generation [1]. Deep learning models have demonstrated remarkable prowess in capturing the complexities of language, facilitating more nuanced analysis and generation of textual data. Furthermore, the quantitative analysis of deep learning models has provided valuable insights into their performance metrics, computational efficiency, and optimization techniques, driving continuous innovation in the field.
2. Evolution of Machine Learning Models in NLP
2.1. Statistical Models to Neural Networks: Exploring the Transition and Implications
The transition from statistical models to neural networks in Natural Language Processing (NLP) signifies a paradigm shift towards data-driven methodologies. Early NLP systems relied heavily on handcrafted features and linear classifiers, embodying models such as Hidden Markov Models (HMMs) and Conditional Random Fields (CRFs). While effective to some extent, these approaches faced limitations in capturing intricate linguistic patterns and contextual nuances inherent in language. The emergence of neural network architectures, particularly Recurrent Neural Networks (RNNs) and Long Short-Term Memory networks (LSTMs), revolutionized the field by offering a more flexible and robust framework for language processing [2]. These models excel in capturing long-range dependencies and contextual information, thereby enhancing the capability to comprehend and generate natural language text. The adoption of neural networks has empowered NLP systems to achieve unprecedented levels of performance across various tasks, ranging from sentiment analysis to machine translation.
2.2. Advancements in Language Modeling: A Deep Dive into Transformer-Based Models
The advent of transformer-based models, exemplified by architectures like BERT (Bidirectional Encoder Representations from Transformers) and GPT (Generative Pre-trained Transformer), has ushered in a new era of language understanding and generation. These models leverage the self-attention mechanism and large-scale pre-training on vast corpora to learn rich, contextual representations of text. By capturing bidirectional relationships within sequences, transformer-based models excel in tasks requiring comprehensive understanding of context, such as question answering and text summarization. Moreover, the success of transformer-based models underscores the importance of pre-training techniques in NLP, wherein models are initially trained on large-scale datasets before fine-tuning on task-specific data [3]. This pre-training paradigm not only facilitates knowledge transfer across domains but also mitigates the need for extensive labeled data, making it a cost-effective and scalable approach to NLP.
2.3. Integration of Deep Learning in Traditional NLP Tasks: Harnessing the Power of Neural Architectures
Deep learning has permeated traditional NLP tasks, catalyzing significant advancements in areas such as part-of-speech tagging, named entity recognition, and syntactic parsing. Convolutional Neural Networks (CNNs) and RNNs have emerged as instrumental tools in this integration, offering distinct advantages in terms of feature extraction and sequential modeling, respectively. In part-of-speech tagging, CNNs have demonstrated prowess in capturing local contextual information, enabling accurate and efficient tagging of word categories. Similarly, in named entity recognition, the sequential nature of RNNs facilitates the identification of entity boundaries and relationships within a sentence. Furthermore, the advent of hybrid architectures, combining CNNs and RNNs, has showcased synergistic effects, yielding superior performance on complex NLP tasks [4]. Overall, the integration of deep learning in traditional NLP tasks underscores the transformative potential of neural architectures in enhancing both accuracy and efficiency, thereby paving the way for more sophisticated and adaptive language processing systems.
3. Quantitative Analysis of Deep Learning Models
3.1. Performance Metrics: Deeper Dive into Evaluation Criteria
When quantitatively assessing the performance of deep learning models in NLP, a comprehensive range of performance metrics is employed to provide a nuanced understanding of their effectiveness. While metrics like accuracy offer a straightforward measure of model correctness, the F1 score provides a balanced assessment of precision and recall, particularly valuable in scenarios with imbalanced class distributions. Additionally, the area under the ROC curve (AUC) serves as a robust indicator of a model's ability to discriminate between classes, especially in binary classification tasks. For instance, in sentiment analysis, where the identification of subtle nuances in language is crucial, the F1 score may offer a more informative evaluation metric than accuracy alone [5]. Similarly, in tasks like named entity recognition, where correctly identifying entities while minimizing false positives is essential, precision and recall metrics provide valuable insights into model performance. Moreover, the comparison of performance metrics across different models facilitates a quantitative assessment of advancements in NLP, enabling researchers to identify state-of-the-art approaches and areas for improvement. Table 1 presents performance metrics for four different deep learning models in NLP tasks.
Table 1. Performance Metrics for Deep Learning Models in NLP
Model | Accuracy | F1 Score | Precision | Recall | AUC |
LSTM-based Sentiment | 0.85 | 0.87 | 0.89 | 0.85 | 0.92 |
Transformer for NER | 0.82 | 0.84 | 0.83 | 0.85 | 0.89 |
BERT for Sentiment | 0.88 | 0.90 | 0.87 | 0.93 | 0.91 |
CNN for Text Categorization | 0.81 | 0.82 | 0.85 | 0.80 | 0.88 |
3.2. Computational Efficiency: Balancing Complexity and Deployment
The computational efficiency of deep learning models is a paramount consideration, particularly in the deployment of NLP applications at scale. Analyzing computational efficiency involves evaluating the trade-offs between model complexity and resource consumption, including memory usage and inference speed. Techniques such as model pruning, which involves removing redundant parameters from trained models, and quantization, which reduces the precision of model weights and activations, have emerged as effective strategies to enhance computational efficiency without compromising performance significantly. For example, in large-scale language modeling tasks, where model size directly impacts memory consumption and inference latency, pruning techniques can lead to substantial reductions in model size and computational overhead [6]. Furthermore, advancements in hardware architectures, such as specialized accelerators for deep learning tasks, have further contributed to improvements in computational efficiency, enabling the deployment of complex NLP models in resource-constrained environments. Table 2 illustrates various techniques employed to enhance the computational efficiency of deep learning models in NLP applications.
Table 2. Computational Efficiency Techniques for Deep Learning Models in NLP
Technique | Description | Impact |
Model Pruning | Removal of redundant parameters from trained models | Reduction in model size |
Quantization | Reduction of precision in model weights and activations | Decreased memory usage |
Hardware Acceleration | Specialized hardware architectures for deep learning tasks | Improved inference speed |
3.3. Mathematical Modeling of Language Tasks: Optimization and Training Paradigms
In deep learning for NLP, mathematical models play a pivotal role in optimizing complex loss functions over high-dimensional parameter spaces. Techniques such as gradient descent and backpropagation are foundational to training deep neural networks, allowing models to iteratively update parameters based on the observed training data. The mathematical formulation of language tasks, including sequence prediction and classification, has been enriched by the development of loss functions tailored to the unique characteristics of language data:
{θ_{t+1}}={θ_{t}}-η{∇_{θ}}τ({θ_{t}}) (1)
Where {θ_{t}} represents the parameters at iteration t. η denotes the learning rate, determining the size of the parameter updates. {∇_{θ}}τ({θ_{t}}) is the gradient of the loss function with respect to the parameters, computed using backpropagation. For instance, in sequence-to-sequence tasks like machine translation, loss functions such as the cross-entropy loss are commonly employed to measure the discrepancy between predicted and target sequences [7]. Moreover, advancements in optimization algorithms, such as adaptive learning rate methods like Adam, have further refined the training process, accelerating convergence and improving the robustness of deep learning models in NLP tasks.
4. Case Studies and Applications
4.1. Sentiment Analysis: In-depth Analysis of Deep Learning Approaches
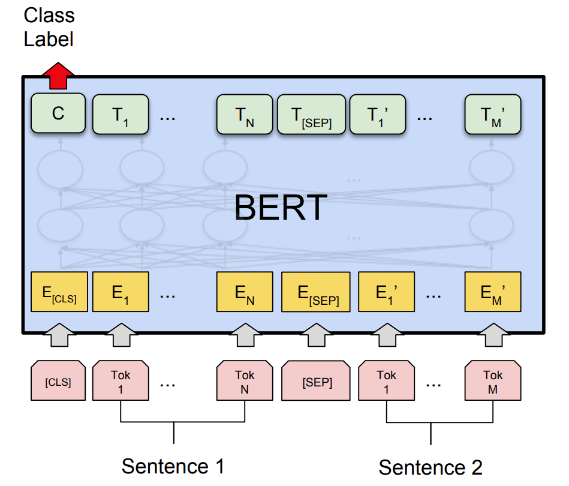
Figure 1. A Primer in BERTology: What we know about how BERT works (Source:deepai.org)
Sentiment analysis, a fundamental task in NLP, has witnessed a significant transformation with the advent of deep learning models. Deep learning architectures such as Long Short-Term Memory networks (LSTMs) and transformer-based models like BERT have propelled sentiment analysis to new heights by enabling more nuanced understanding of textual sentiment. In the realm of sentiment analysis, the utilization of LSTM networks has revolutionized the processing of sequential data, allowing models to capture long-range dependencies and contextual nuances inherent in natural language. By considering the sequential nature of text, LSTMs excel in understanding sentiment in longer passages, facilitating finer-grained analysis of complex emotional expressions. Similarly, transformer-based models like BERT have revolutionized sentiment analysis through their ability to capture bidirectional context, as shown in Figure 1. By pre-training on vast amounts of text data, BERT learns deep contextual representations of language, enabling more accurate and nuanced sentiment analysis across various domains and languages [8]. Moreover, the integration of attention mechanisms in transformer architectures further enhances sentiment analysis by enabling models to focus on relevant parts of the input text, thereby improving the interpretability and effectiveness of sentiment predictions.
4.2. Machine Translation: Deep Learning Paradigms in Translation
Machine translation, a cornerstone application of NLP, has undergone a profound transformation with the advent of deep learning techniques. Traditional statistical methods for machine translation relied on rule-based approaches and handcrafted features, often failing to capture the complex linguistic patterns and nuances of language. In contrast, deep learning-based neural machine translation (NMT) systems have revolutionized the field by adopting end-to-end training approaches, where models learn to translate text directly from one language to another without the need for intermediate representations or alignment models. This approach enables NMT systems to capture complex syntactic and semantic relationships between languages, resulting in translations that are more fluent and contextually accurate. Furthermore, the introduction of attention mechanisms in NMT architectures has further improved translation quality by allowing models to focus on relevant parts of the source sentence during the translation process [9]. This attention-based approach enables NMT systems to handle long sentences and effectively capture dependencies between words, leading to more coherent and accurate translations. Overall, deep learning-based approaches have propelled machine translation to unprecedented levels of accuracy and fluency, making it an indispensable tool for cross-lingual communication and information exchange. Table 3 illustrates the transformation of machine translation with deep learning paradigms.
Table 3. Evolution of Machine Translation with Deep Learning Paradigms
Method | Description | Benefits |
Traditional Statistical Methods | Reliance on rule-based approaches and handcrafted features | Limited ability to capture linguistic nuances |
Deep Learning-based Neural Machine Translation (NMT) | Adoption of end-to-end training approaches without intermediate representations | Captures complex syntactic and semantic relationships |
Attention Mechanisms | Introduction of mechanisms to focus on relevant parts of the source sentence | Improved translation quality and coherence |
4.3. Automated Content Generation: Advancements in Natural Language Generation
The emergence of deep learning models like GPT-3 has revolutionized automated content generation, enabling machines to generate human-like text with remarkable fluency and coherence. These models leverage large-scale pre-training on diverse text corpora to learn rich representations of language, enabling them to generate contextually relevant and grammatically correct text across a wide range of topics and styles. One of the key advancements in automated content generation is the ability of deep learning models to understand and replicate the stylistic nuances of human-written text. By training on diverse datasets, including books, articles, and internet text, GPT-3 and similar models can capture the intricacies of language, including vocabulary usage, sentence structure, and tone, enabling them to produce text that is indistinguishable from that written by humans. Furthermore, the controllability and flexibility of deep learning-based content generation models allow users to specify desired attributes such as tone, style, and topic, enabling personalized and tailored content generation for various applications, including chatbots, content recommendation systems, and creative writing assistants[10].
5. Conclusion
In summary, this paper has provided an in-depth exploration of the evolution and advancements in deep learning models for Natural Language Processing (NLP). From the transition away from statistical models towards the adoption of neural networks, to the integration of deep learning techniques into traditional NLP tasks, the field has undergone substantial transformation. The examination of quantitative analysis methods has offered valuable insights into the performance and efficiency of deep learning models, facilitating the identification of state-of-the-art approaches and areas for further improvement. Moreover, through the presentation of case studies and applications, we have witnessed the tangible impact of deep learning in various NLP domains. Tasks such as sentiment analysis, machine translation, and automated content generation have seen significant advancements, with deep learning models consistently outperforming traditional methods. These case studies serve as compelling examples of the transformative potential of deep learning in addressing real-world NLP challenges. Looking ahead, the future of NLP lies in continued research and innovation in deep learning methodologies. As the field continues to evolve, we anticipate further breakthroughs in model architectures, optimization techniques, and training paradigms. These advancements will not only enhance the performance and efficiency of NLP systems but also pave the way for more sophisticated and adaptive language processing systems capable of tackling increasingly complex linguistic tasks. In conclusion, deep learning has revolutionized NLP, enabling unprecedented levels of accuracy, efficiency, and adaptability. With ongoing advancements and a growing understanding of deep learning principles, the potential for further innovation in NLP is limitless.
6. Contribution
Yingxuan Chai and Liangning Jin: Conceptualization, Methodology, Data curation, Writing- Original draft preparation, Visualization, Investigation.
References
[1]. Khurana, Diksha, et al. "Natural language processing: State of the art, current trends and challenges." Multimedia tools and applications 82.3 (2023): 3713-3744.
[2]. Fanni, Salvatore Claudio, et al. "Natural language processing." Introduction to Artificial Intelligence. Cham: Springer International Publishing, 2023. 87-99.
[3]. Hossain, Elias, et al. "Natural language processing in electronic health records in relation to healthcare decision-making: a systematic review." Computers in Biology and Medicine 155 (2023): 106649.
[4]. Phatthiyaphaibun, Wannaphong, et al. "Pythainlp: Thai natural language processing in python." arXiv preprint arXiv:2312.04649 (2023).
[5]. Treviso, Marcos, et al. "Efficient methods for natural language processing: A survey." Transactions of the Association for Computational Linguistics 11 (2023): 826-860.
[6]. William, P., et al. "Framework for design and implementation of chat support system using natural language processing." 2023 4th International Conference on Intelligent Engineering and Management (ICIEM). IEEE, 2023.
[7]. Jiménez-Zafra, Salud María, Francisco Rangel, and M. Montes-Y. Gómez. "Overview of IberLEF 2023: Natural Language Processing Challenges for Spanish and other Iberian Languages." Proceedings of the Iberian Languages Evaluation Forum (IberLEF 2023), co-located with the 39th Conference of the Spanish Society for Natural Language Processing (SEPLN 2023), CEURWS. org. 2023.
[8]. Taye, Mohammad Mustafa. "Understanding of machine learning with deep learning: architectures, workflow, applications and future directions." Computers 12.5 (2023): 91.
[9]. Prince, Simon JD. Understanding Deep Learning. MIT press, 2023.
[10]. Soori, Mohsen, Behrooz Arezoo, and Roza Dastres. "Artificial intelligence, machine learning and deep learning in advanced robotics, a review." Cognitive Robotics (2023).
Cite this article
Chai,Y.;Jin,L.;Feng,S.;Xin,Z. (2024). Evolution and advancements in deep learning models for Natural Language Processing. Applied and Computational Engineering,77,144-149.
Data availability
The datasets used and/or analyzed during the current study will be available from the authors upon reasonable request.
Disclaimer/Publisher's Note
The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of EWA Publishing and/or the editor(s). EWA Publishing and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content.
About volume
Volume title: Proceedings of the 2nd International Conference on Software Engineering and Machine Learning
© 2024 by the author(s). Licensee EWA Publishing, Oxford, UK. This article is an open access article distributed under the terms and
conditions of the Creative Commons Attribution (CC BY) license. Authors who
publish this series agree to the following terms:
1. Authors retain copyright and grant the series right of first publication with the work simultaneously licensed under a Creative Commons
Attribution License that allows others to share the work with an acknowledgment of the work's authorship and initial publication in this
series.
2. Authors are able to enter into separate, additional contractual arrangements for the non-exclusive distribution of the series's published
version of the work (e.g., post it to an institutional repository or publish it in a book), with an acknowledgment of its initial
publication in this series.
3. Authors are permitted and encouraged to post their work online (e.g., in institutional repositories or on their website) prior to and
during the submission process, as it can lead to productive exchanges, as well as earlier and greater citation of published work (See
Open access policy for details).
References
[1]. Khurana, Diksha, et al. "Natural language processing: State of the art, current trends and challenges." Multimedia tools and applications 82.3 (2023): 3713-3744.
[2]. Fanni, Salvatore Claudio, et al. "Natural language processing." Introduction to Artificial Intelligence. Cham: Springer International Publishing, 2023. 87-99.
[3]. Hossain, Elias, et al. "Natural language processing in electronic health records in relation to healthcare decision-making: a systematic review." Computers in Biology and Medicine 155 (2023): 106649.
[4]. Phatthiyaphaibun, Wannaphong, et al. "Pythainlp: Thai natural language processing in python." arXiv preprint arXiv:2312.04649 (2023).
[5]. Treviso, Marcos, et al. "Efficient methods for natural language processing: A survey." Transactions of the Association for Computational Linguistics 11 (2023): 826-860.
[6]. William, P., et al. "Framework for design and implementation of chat support system using natural language processing." 2023 4th International Conference on Intelligent Engineering and Management (ICIEM). IEEE, 2023.
[7]. Jiménez-Zafra, Salud María, Francisco Rangel, and M. Montes-Y. Gómez. "Overview of IberLEF 2023: Natural Language Processing Challenges for Spanish and other Iberian Languages." Proceedings of the Iberian Languages Evaluation Forum (IberLEF 2023), co-located with the 39th Conference of the Spanish Society for Natural Language Processing (SEPLN 2023), CEURWS. org. 2023.
[8]. Taye, Mohammad Mustafa. "Understanding of machine learning with deep learning: architectures, workflow, applications and future directions." Computers 12.5 (2023): 91.
[9]. Prince, Simon JD. Understanding Deep Learning. MIT press, 2023.
[10]. Soori, Mohsen, Behrooz Arezoo, and Roza Dastres. "Artificial intelligence, machine learning and deep learning in advanced robotics, a review." Cognitive Robotics (2023).