


Volume 175
Published on August 2025Volume title: Proceedings of CONF-CDS 2025 Symposium: Application of Machine Learning in Engineering
Machine learning (ML) has become a key driver of innovation in industrial manufacturing, enhancing quality control, predictive maintenance, and process optimization. Manufacturers can achieve improved efficiency, reduced costs, and enhanced operational reliability by leveraging advanced ML algorithms, such as deep learning and traditional models. However, challenges remain in the large-scale deployment of ML, including issues with data privacy, legacy system interoperability, and the need for high-quality datasets. This paper investigates three core research questions: the enhancement of manufacturing processes via ML algorithms, the technical impediments to ML implementation, and the resolution of these challenges through emerging technologies such as digital twins and IoT. The study reveals that ML has significantly improved fault diagnosis, reduced downtime, and optimized energy use. However, it also highlights ongoing concerns around data privacy and system integration. The paper concludes by discussing the potential of future technologies to advance ML adoption in manufacturing further while emphasizing sustainability and innovative manufacturing initiatives.



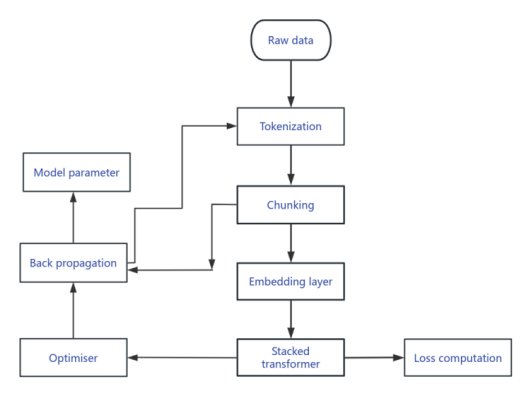
The transformer model was used to train and generate story text this time because certain parts or endings of the original story were not satisfactory. This study tried to use the model training to obtain other story paths. The main purpose is to study two paths: one is how to use pre-trained models for fine-tuning to achieve the desired effect, and the other is how to build a model trained from scratch to achieve the desired effect. DeepSeek R1 will be used as a control group to evaluate the generation effect.According to the results, the pre-trained model performs better on smaller datasets, generating logical sentences and paragraphs, while the model trained from scratch has not yet achieved good results on smaller datasets. As an improvement measure, a larger dataset will be used to enhance the model's generation performance, while adjusting new hyperparameters to fit the dataset.
With the rapid advancement of wireless communication technologies, the increasing diversity of modulation schemes poses significant challenges for traditional modulation recognition methods in complex communication environments. To address this, this research proposes a hybrid deep learning model that integrates Convolutional Neural Networks (CNN) and Transformers. The CNN module is employed to extract local time-frequency features from the modulated signals, enhancing the model's capacity to capture short-term dependencies. Meanwhile, the Transformer module leverages its self-attention mechanism to model global temporal dependencies, improving recognition accuracy for complex modulation patterns. The model is trained and validated using the publicly available DeepSig RadioML 2018.01A dataset across various Signal-to-Noise Ratio (SNR) conditions, ranging from -20 dB to 30 dB. Experimental results demonstrate that our hybrid model achieves a remarkable recognition accuracy of up to 91% in environments with SNRs above 10 dB, highlighting its robustness and effectiveness in modulation recognition tasks.
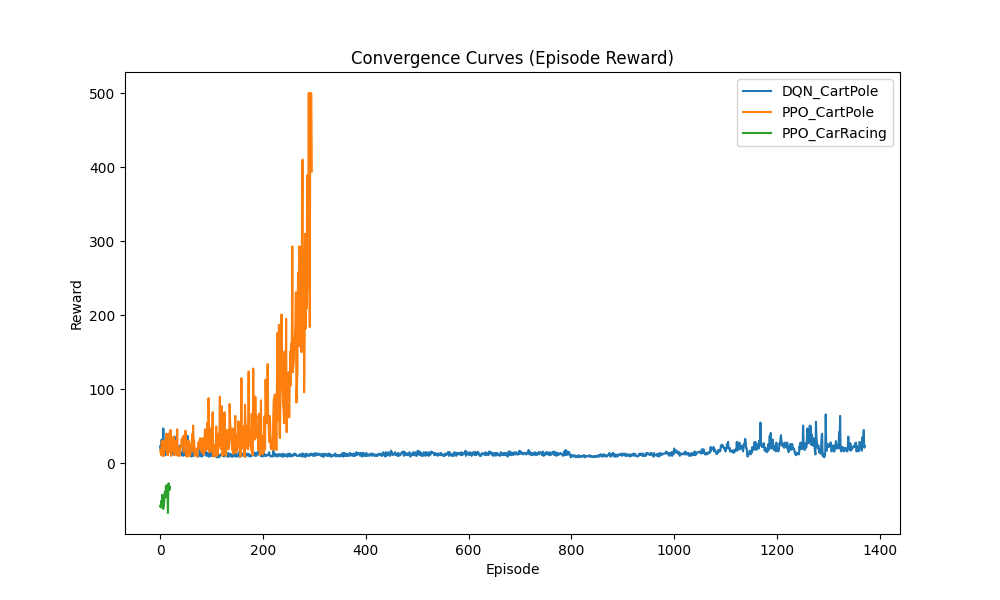
With the rapid development of artificial intelligence technology, reinforcement learning (RL) has emerged as a core research direction in the field of intelligent decision-making. Among numerous reinforcement learning algorithms, Deep Q-Network (DQN) and Proximal Policy Optimization (PPO) have gained widespread attention due to their outstanding performance. These two algorithms have been extensively applied in areas such as autonomous driving and game AI, demonstrating strong adaptability and effectiveness. However, despite numerous application instances, systematic comparative studies on their specific performance differences remain relatively scarce. This study aims to systematically evaluate the differences between DQN and PPO algorithms across four performance metrics: convergence speed, stability, sample efficiency, and computational complexity. By combining theoretical analysis and experimental validation, we selected classic reinforcement learning environments—CartPole (for discrete action testing) and CarRacing (for continuous action evaluation)—to conduct a detailed performance assessment. The results show that DQN exhibits superior performance in discrete action environments with faster convergence and higher sample efficiency, whereas PPO demonstrates greater stability and adaptability in continuous action environments.
Gamification refers to the application of game - design elements in non - game contexts. It has become popular in fields such as education and business because it has the potential to improve efficiency. This paper critically analyzes the impact of gamification on efficiency, covering both its strengths and limitations. The analysis in this essay is based on literature reviews, sources range from academic papers to well-known real-life examples like the popular language learning app Duolingo. Studies finds that gamification can increase efficiency by enhancing motivation, interactivity, and attention on task, but they also reveal that poorly designed gamification strategies may undermine intrinsic motivation, distract users from core goals, and even induce addiction. The essay concludes that the effectiveness of gamification depends on careful implementation aligned with psychological principles and user context., otherwise it may lead to adverse effects such as distractions and misled goals. In order to successfully use gamification as a tool, practitioners need to fully understand its nature.
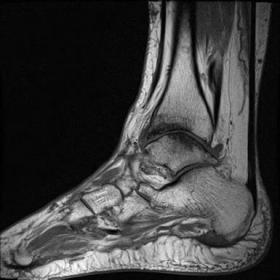
Although high-resolution MRI provides excellent anatomical detail, existing segmentation approaches possess a requisite yet inadequate level of precision, require substantial human effort, and fail to accurately represent the intricate 3D structure. To address these limitations, this work develops a novel 3D Faster R-CNN engine that automatically detects and segments the main ankle joint components from volumetric MRI. The proposed design combines a 3D ResNet-50 transformer with a 3D Region Proposal Network and 3D ROI Align components to analyze MRI scans. The model trained with experiments based on ankle MRI datasets from second-party repositories used data processing steps to normalize image size and enhance dataset collection. The assessment metrics consisted of Dice Similarity Coefficient, Intersection over Union, and mean Average Precision (mAP). By evaluating several models, the system achieves a Dice coefficient score of 91.4% alongside an mAP of 89.6% at IoU 0.5 which beats previous 2D and 3D segmentation techniques. Scientific images showed that the method could precisely detect body structures in different MRI views while keeping their correct shapes.
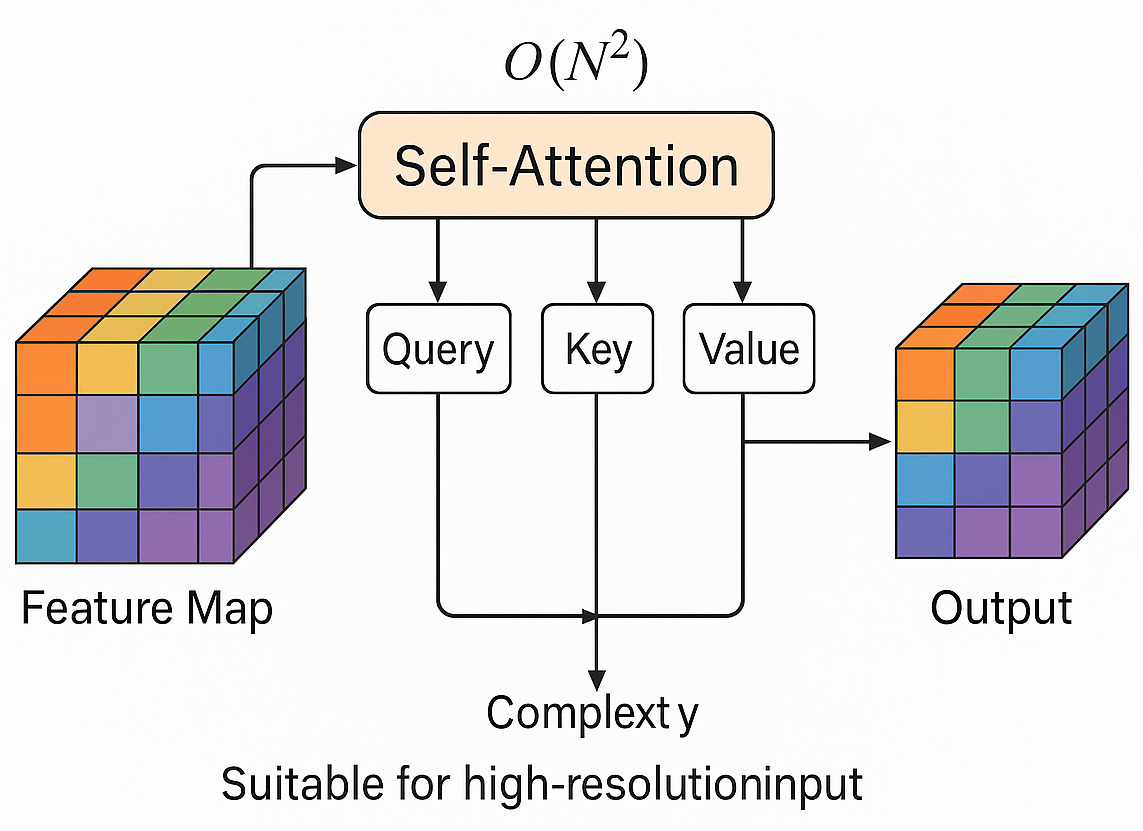
To enhance the structural reconstruction capabilities and semantic consistency of generative adversarial networks (GANs) in high-resolution image generation, this study focuses on the integration methods and performance differences of various attention mechanisms within GAN architectures. A systematic analysis was conducted on four mainstream mechanisms—self-attention, SE, CBAM, and non-local—across the generator, discriminator, and bidirectional embedding paths. Using the COCO and CelebA-HQ datasets, with a unified image resolution of 256×256, controlled experiments were designed with parameter increases kept within ±10%. Evaluation metrics included inception score, FID, PSNR, SSIM, and loss variance. The results show that self-attention and non-local modules have significant advantages in modeling long-range dependencies and global semantics, with FID reduced to 41.5 and 39.8, PSNR improved to 26.9 dB and 27.1 dB, SSIM reaching 0.834 and 0.839, and training stability metrics such as loss variance reduced to 0.049 and 0.047. In contrast, SE and CBAM achieve performance improvements with extremely low parameter growth, making them suitable for model lightweight requirements. The dual-end embedding path performed optimally across all metrics, demonstrating the effectiveness of collaborative modeling between the generator and discriminator. Analysis suggests that different attention mechanisms significantly impact model performance, with integration methods and embedding positions determining the ability to restore image details and model semantic consistency. This provides theoretical support and experimental evidence for future optimization of attention mechanism structures and the development of dynamic integration strategies.
With the advent of the big data era and the rapid advancement of computing power, machine learning has become the core driving force behind the development of artificial intelligence. From medical diagnosis to face recognition payment, and from autonomous driving to intelligent recommendation systems, machine learning algorithms have deeply penetrated various sectors of society. Traditional machine learning algorithms, such as Support Vector Machines and Decision Trees, established the theoretical foundations of the field, while breakthroughs in modern machine learning—particularly the rise of deep learning and the advent of Transformer architectures—have significantly expanded its frontiers. This paper adopts a research methodology combining literature analysis and review to systematically studies the evolutionary path of fundamental machine learning algorithms from traditional to modern approaches. Through historical combing and comparative analysis, it aims to uncover the underlying logic of machine learning algorithm evolution. The study finds that the evolution of algorithms is the result of a synergy between theoretical innovation and engineering demands.
With the rapid development of high-tech technologies in the 21st century, society is increasingly moving toward intelligentization. Intelligentization refers to endowing machines with human-like capabilities, and among these, the foremost is the ability to perceive the external environment—what is known as computer vision. Possessing perceptual capabilities means being able to distinguish and categorize elements within an environment, identifying those with similar attributes while differentiating those with distinct attributes. This involves organizing objects in the environment into cohesive units under unified concepts, enabling recognition of diverse entities. This process requires target instance segmentation methods based on deep learning. This paper primarily summarizes and analyzes early and mainstream approaches to target instance segmentation using deep learning, thoroughly examining existing research to guide future work in this field. Through analysis, this paper finds that diverse innovative strategies, such as parallel mask assembly (YOLACT), instance classification via spatial grids (SOLO), polar coordinate representation (PolarMask), and unified mask classification (MaskFormer), can effectively combine instance distinction with pixel-level classification.
As recent years AI model developed, various new technology have been created, causing the AI model field to gradually become more competitive day after day, since it was born in 2023, DeepSeek gain benefit and was able to compete with other big companies using its benefits in code and mathematics advancement, localization and Chinese optimization, free to use, high performance. This thesis will analyze DeepSeek’s core technology from its model architecture innovation, technology training and innovation, and performance comparison area. It will also explain DeepSeek’s effect on the artificial intelligence area by focusing on DeepSeek’s technology development in AI technology, the change in the competitive field of AI companies and ethical problems. In this thesis, we find that DeepSeek's ability to become a leader in the field of AI macromodels in just a few years is due to Deepseek's model architecture innovations, training strategy optimizations, and outstanding key performance, but like all other AI models, DeepSeek have limitations while having various benefits, these limitations include problems with the timeliness of data updates, as well as doubts about the accuracy and completeness of data and data biases.