







1. Introduction
The landscape of Natural Language Processing (NLP) has been profoundly reshaped by the emergence and evolution of large language models (LLMs). The genesis of these models can be traced back to the early neural network architectures that laid the groundwork for subsequent advancements. The introduction of models such as the Transformer by Vaswani et al. marked a pivotal shift, enabling significantly more effective handling of sequential data through self-attention mechanisms [1]. This innovation paved the way for the development of more sophisticated models like GPT (Generative Pre-trained Transformer) by OpenAI and BERT (Bidirectional Encoder Representations from Transformers) by Google, which have set new benchmarks in various NLP tasks [2][3].
Large language models have revolutionized the field of NLP by demonstrating unprecedented effectiveness in a wide range of applications, from simple classification tasks to complex question-answering and text generation. The ability of these models to understand and generate human-like text has not only advanced academic research but also enabled practical applications that impact everyday life, such as chatbots, personal assistants, and more [4]. The core strength of LLMs lies in their deep neural networks, which learn rich representations of language from extensive training on diverse datasets, allowing them to generalize well across different tasks [5].
This review aims to provide a comprehensive examination of the development, capabilities, and applications of large language models in NLP. It is structured first to introduce the foundational concepts and architectures of LLMs, followed by a detailed exploration of their applications in both understanding and generating natural language. Subsequently, the review discusses the optimizations and improvements that enhance the performance and efficiency of these models. Finally, it addresses the challenges LLMs face and anticipates future directions in the field. The goal is to present a structured and detailed overview that serves as both a foundational guide for newcomers and a reference for seasoned researchers in NLP.
2. Large Language Model Foundations
Large Language Models (LLMs) are a class of machine learning models designed to process, understand, and generate human language. Characterized by their vast number of parameters and deep neural network architectures, LLMs are capable of learning from a diverse range of language data in a self-supervised manner. The primary characteristic that distinguishes LLMs from earlier language processing models is their ability to perform "transfer learning," where a model trained on a large dataset can adapt to various NLP tasks with minimal task-specific data [6]. This adaptability is facilitated by their layered architecture, which allows them to capture and represent complex language features.
2.1. Common Architectures of Large Language Models
The most influential architecture underlying many LLMs is the Transformer model, introduced by Vaswani et al. This architecture has become the de facto standard due to its scalability and efficiency in handling long sequences of data [1]. The Transformer employs an encoder-decoder structure, where the encoder maps the input sequence into a latent representation, and the decoder generates the output sequence from this representation. The key innovation of the Transformer is the self-attention mechanism, which allows each position in the sequence to attend to all other positions, enabling the model to capture long-range dependencies.
Following the Transformer, several models have been developed, each with unique characteristics. GPT (Generative Pre-trained Transformer) is developed by OpenAI, which are designed to generate coherent and contextually relevant text based on a given prompt. They are trained using a left-to-right language modeling objective and have been iteratively improved from GPT-1 to GPT-3, with increasing complexity and capability[2]. Unlike GPT, BERT (Bidirectional Encoder Representations from Transformers) learns language patterns in a bidirectional manner, making it particularly effective for tasks that require a deep understanding of context and relationships within the text. BERT's training involves masking parts of the input text and predicting these masked tokens, which helps in learning a rich language representation according to Figure 1[3][7]. In addition, other variants like RoBERTa (a robustly optimized BERT approach) and T5 (Text-to-Text Transfer Transformer) have built upon the strengths of BERT and Transformer architectures to enhance performance across different NLP benchmarks [8][9].
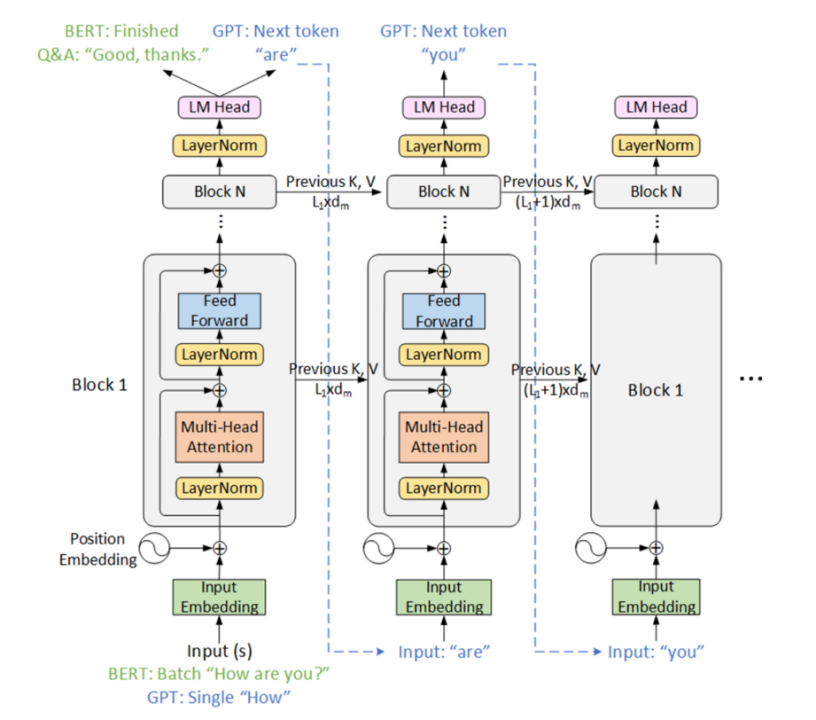
Figure 1. Transformer architectures of BERT and GPT. [10]
These models differ in their architectures, training objectives, and the direction of the language modeling (unidirectional vs bidirectional). However, they all leverage the power of the Transformer architecture and self-attention to learn rich language representations from vast amounts of text data.
2.2. Training Methods and Datasets for Large Language Models
Training LLMs involves significant computational resources and large-scale datasets. The most common method for training these models is unsupervised learning, whereby the models learn language patterns by having them learn to predict other parts of the text based on one part of the text. Models like GPT and BERT are primarily trained on unlabeled text drawn from a wide array of sources, including books, articles, and websites. This training enables the models to develop a generalized understanding of language [2][3]. The selection of datasets for training LLMs is crucial for their performance and generalizability. Popular datasets include the "BookCorpus," "English Wikipedia," and "Common Crawl," which provide diverse linguistic contexts [10]. After pre-training on large datasets, LLMs are often fine-tuned on specific tasks like sentiment analysis or question answering, using smaller, task-specific datasets. This fine-tuning adjusts the model's weights to better perform on the task at hand [11].
3. Applications of Large Language Models in Natural Language Understanding Tasks
Natural Language Understanding (NLU) encompasses the range of computational techniques that aim at interpreting, analyzing, and deriving meaning from human language. A core area within NLP, NLU focuses on enabling machines to understand and respond to text or voice data in a way that is contextually and semantically appropriate. Large-scale language models, which utilize their extensive training on a wide range of linguistic data to handle complex linguistic tasks, have greatly advanced the development of NLU technology..
3.1. Key NLU Tasks Addressed by Large Language Models
The key NLU tasks handled by large language models include sentiment analysis, named entity recognition (NER), question answering (QA), and text summarization. Sentiment analysis aims to analyze the content of text and determine its sentiment tendency, such as positive, negative, or neutral, through models. Models like BERT and GPT have shown remarkable accuracy in understanding subtle nuances of sentiment, largely due to their deep contextual learning capabilities. In NER tasks, the model identifies key information in the text and assigns it to predefined categories such as names of people, organizations, locations, temporal expressions, quantities, monetary values, and percentages. BERT and its variants have been particularly effective in improving the precision and recall in NER tasks across various domains. For QA, LLMs like BERT and T5 have been employed to develop systems that can answer questions posed in natural language, drawing information from a given text. These models understand the query's context and retrieve or generate the correct answers based on the content they have been trained on. In addition, text summarization is another strength of LLMs, enabling the automatic generation of concise and meaningful summaries of long texts. Techniques involve extractive summarization, where key sentences are selected from the text, and abstractive summarization, where new sentences are generated to encapsulate the main points.
3.2. Example Applications and Case Studies
In the field of customer service automation, businesses can utilize LLM to automatically respond to customer inquiries and provide timely and contextually relevant support. Models trained on specific company data can understand and respond to customer needs with high accuracy, reducing operational costs and improving customer satisfaction [12]. In legal and healthcare document processing, LLMs can help parse and interpret large volumes of text to extract relevant information, aiding in decision-making and documentation processes. This application is crucial for managing detailed and sensitive information that requires high accuracy [13].
4. Applications of Large Language Models in Natural Language Generation Tasks
Natural Language Generation (NLG) involves the computational process of producing coherent text from structured data. Unlike Natural Language Understanding (NLU), which focuses on interpreting and analyzing text, NLG is about creating text that is syntactically correct, semantically meaningful, and contextually appropriate. Large language models have been particularly influential in advancing NLG capabilities, offering a wide range of applications from automated content creation to personalized communication.
4.1. Key NLG Tasks Enhanced by Large Language Models
LLMs significantly enhance several key NLG tasks. In terms of content creation, LLMs like GPT-3 have the capability to generate articles, reports, and even creative works like poetry and prose. By training on a diverse corpus, these models can produce text that is not only grammatically correct but also stylistically varied. For language translation tasks, models such as T5 and BERT have been fine-tuned for translation tasks, where the goal is to convert text from one language to another while maintaining the original meaning, style, and cultural nuances. Moreover, in the realm of e-commerce and media, LLMs generate personalized product descriptions or film summaries tailored to individual user preferences, enhancing user engagement and satisfaction. The use of automated email responses represents another application of LLM. By understanding the context of received emails, LLMs can draft appropriate and helpful responses, significantly reducing the workload on human employees and improving response times.
4.2. Example Applications and Case Studies
LLMs have demonstrated a wide range of application potential in a number of domains. In automated journalism, news organizations use LLMs to automatically generate news reports on topics like sports and finance. These models can integrate real-time data, such as sports scores or stock prices, to produce timely and factual articles as shown in Figure 2[14].
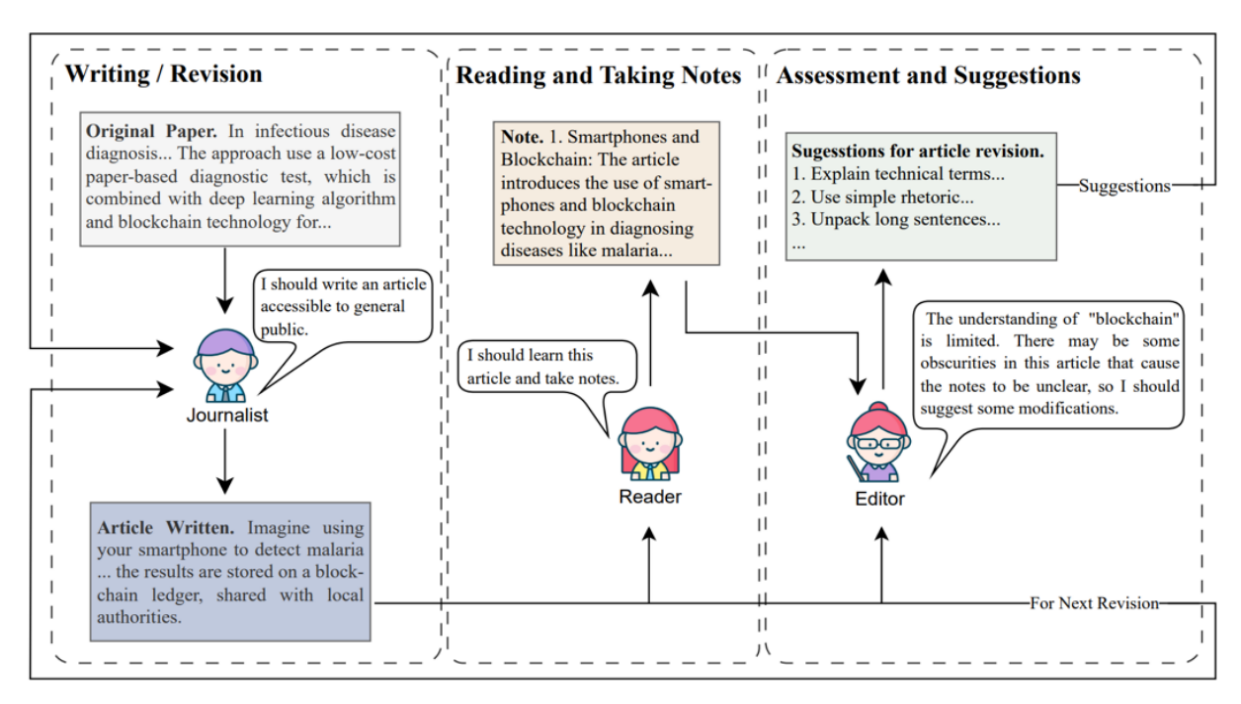
Figure 2. Structure of LLM-Collaboration Automated Journalism Framework[15]
In addition, LLMs can be used for educational content generation to assist in the creation of educational materials, such as customized learning texts that adapt to the student's learning pace and style. This application not only streamlines content creation but also enhances learning experiences by providing personalized educational content. LLMs are also widely used in game and movie script writing. In the entertainment industry, they are employed to draft scripts for video games and movies. These models can generate dialogue and narrative arcs, reducing the initial creative burden on human writers and speeding up the development process [15].
5. Applications of Large Language Models in Other Natural Language Processing Tasks
Beyond the core tasks of natural language understanding (NLU) and natural language generation (NLG), large language models (LLMs) are instrumental in advancing various other domains within natural language processing (NLP). These models, due to their vast training datasets and sophisticated architectures, excel in tasks that require a deep semantic understanding and contextual awareness.
5.1. Text Style Transfer
Text style transfer involves altering the style of a text (e.g., from formal to informal) while preserving its original content and meaning. Large language models (LLMs) excel in this task due to their deep learning of linguistic nuances and styles from diverse datasets. For instance, transforming customer reviews into a more formal tone for report generation or converting legal documents into layman's terms for general understanding. In terms of technical approach, LLMs are trained using techniques such as adversarial training and style-specific embedding in order to perform style transformations without losing the semantic essence of the text.
5.2. Text Correction
Text correction is another area where LLMs demonstrate significant value, offering corrections for grammar, spelling, punctuation, and style inconsistencies. For example, real-time correction in word processors, email clients, and communication platforms, enhancing clarity and professionalism in written communication. In terms of technical approach, LLMs are trained on a corpus of corrected texts or through reinforcement learning where the model learns from its errors to improve over time.
5.3. Language Model Pre-training
Pre-training involves training a language model on a large corpus of text before fine-tuning it on a specific task. This pre-training step is crucial as it provides a strong foundational understanding of language, which can be adapted to numerous specific tasks. For example, pre-trained models like BERT and GPT are further fine-tuned for tasks like sentiment analysis, question answering, and more, benefiting from the generalized language understanding acquired during pre-training. In terms of technical approach, techniques such as masked language modeling (MLM) and autoregressive language modeling are common. These involve predicting some parts of the text given other parts, thus learning a comprehensive representation of the language.
6. Optimization and Improvement of Large Language Models
As the deployment and application of large language models (LLMs) continue to expand across various sectors, the focus on optimizing and improving these models has intensified. Enhancements in model architecture, training methodologies, and efficiency measures are crucial for advancing their capabilities and reducing their environmental impact.
6.1. Model Compression Techniques
Quantization is one of the most effective techniques for model compression. By reducing the precision of the weights from 32-bit floats to 8-bit integers, quantization can reduce the model size by 75% with minimal impact on performance. For example, Zafrir et al. showed that an 8-bit quantized BERT model retains 99.9% of the original model's accuracy on the GLUE benchmark while being 4x smaller [16]. Pruning is another powerful technique. Sanh et al. demonstrated that pruning 70% of the weights from a BERT model results in only a 3% drop in performance on the MNLI task, while reducing the model size by 3.3x [17]. This highlights the redundancy present in large models and the potential for significant compression. Knowledge distillation has also yielded promising results Sanh et al. used knowledge distillation to train a 6-layer BERT model (DistilBERT) that retains 97% of the performance of the original 12-layer model, while being 2x faster and 40% smaller [18].
6.2. Research on Explainability of Large Language Models
In terms of explainability techniques, attention visualization has been widely used to interpret the behavior of Transformer-based models. Vig developed a visualization tool called BertViz that allows interactive exploration of the attention patterns in BERT models. This tool has provided valuable insights into how BERT attends to different parts of the input for different tasks. Besides, layer-wise Relevance Propagation (LRP) has also been applied to language models. Voita et al. used LRP to analyze the contributions of individual tokens to the final prediction in a machine translation model as show in figure 3[19]. They found that the model pays more attention to content words than function words, aligning with human intuition.
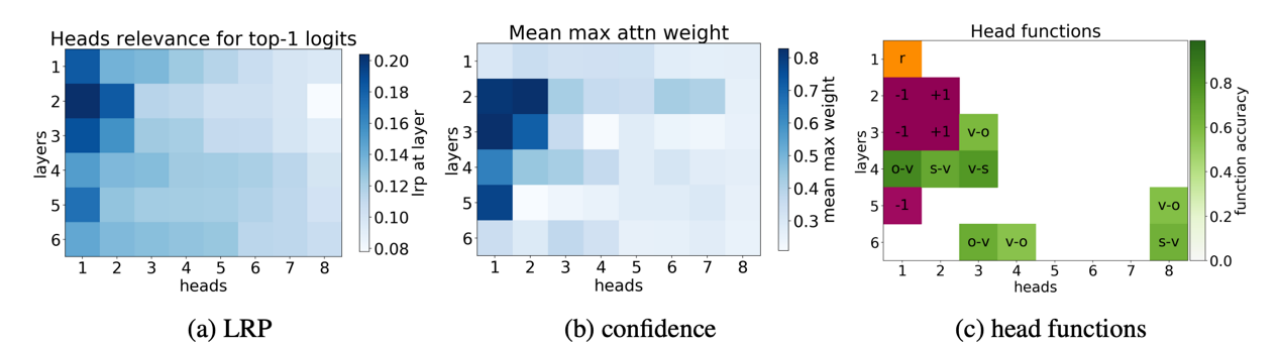
Figure 3. Importance (according to LRP), confidence, and function of self-attention heads. In each layer, heads are sorted by their relevance according to LRP. [19]
7. Challenges and Future Directions for Large Language Models
7.1. Computational Resources and Training Efficiency
As large language models (LLMs) become increasingly powerful, they also demand more computational resources, which can be costly and environmentally unsustainable In particular, the issue of high energy consumption is of significant concern. Training state-of-the-art models requires substantial amounts of electricity, often sourced from non-renewable energy. In addition, the high computational cost limits the popularity of LLM techniques, primarily making them available only to well-funded organizations. To address these issues, further research should include investigating more efficient model architectures to reduce the amount of computation required for training and inference. It is also crucial to promote the concept of green AI. The use of renewable energy sources should be promoted to optimize hardware for energy efficiency.
7.2. Sample Efficiency and Few-Shot Learning
Improving the sample efficiency of LLMs, that is, their ability to learn from limited data, is crucial for applications where large datasets are unavailable or impractical to obtain. Specifically, most LLMs require massive datasets for training, which are not always available. In the future, meta-learning is a technique that allows models to learn how to learn, which can dramatically reduce the number of examples needed to achieve high performance. Furthermore, research in the field of transfer learning is progressing, aiming to develop methods to efficiently transfer knowledge from one domain to another.
7.3. Model Fairness, Ethics, and Privacy
Ensuring that LLMs are fair, ethical, and respect user privacy is increasingly important as these models are deployed in more sensitive and impactful domains. LLMs can inadvertently learn and perpetuate biases present in their training data. At the same time, LLMs trained on large amounts of data sometimes remember and repeat private information, posing a privacy risk. In the future, the development and implementation of bias-reducing techniques is critical to identify and mitigate biases in training data and model outputs. In addition, randomization techniques should be added to the training process to prevent the model from learning specifics about individual data points, thus enhancing privacy.
8. Conclusion
There is no denying that LLMs have changed the landscape of natural language processing with their ability to understand, generate, and process human language with unprecedented accuracy and fluency, which opens up a wide range of potential applications from automating customer service to enhancing creative writing. However, it is evident that these models pose significant challenges. The computational resources required to train and deploy them are immense, raising concerns about energy consumption and accessibility. As these models are increasingly used in sensitive domains, important questions about fairness, bias, and privacy must also be addressed.
Despite these challenges, the potential of LLMs remains enormous. As research continues into more efficient architectures, few-shot learning, and techniques for mitigating bias and protecting privacy, it is reasonable to anticipate the emergence of even more sophisticated and adaptable models in the future. As such, it is important to develop these models responsibly and with a clear understanding of their implications and limitations.. In short, LLMs represent a major leap forward in our ability to process and generate human language. As these technologies continue to evolve and are applied in new ways, they will undoubtedly shape not just the field of NLP, but the broader landscape of how language is interacted with and used in everyday life.
References
[1]. Vaswani, A., et al. (2017). Attention is All You Need. Neural Information Processing Systems.
[2]. Radford, A., et al. (2018). Improving Language Understanding by Generative Pre-training. OpenAI Blog.
[3]. Devlin, J., et al. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. North American Chapter of the Association for Computational Linguistics.
[4]. Brown, T., et al. (2020). Language Models are Few-Shot Learners. Neural Information Processing Systems.
[5]. Rogers, A., et al. (2020). A Primer in BERTology: What we know about how BERT works. Transactional Association of Computational Linguistics.
[6]. Ruder, S., et al. (2019). Transfer Learning in Natural Language Processing. NAACL HLT 2019 Tutorial.
[7]. Wu, Yuting, Ziyu Wang, and Wei D. Lu. (2024) "PIM GPT a hybrid process in memory accelerator for autoregressive transformers." npj Unconventional Computing 1.1.
[8]. Liu, Y., et al. (2019). RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv preprint arXiv:1907.11692.
[9]. Raffel, C., et al. (2019). Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. Journal of Machine Learning Research.
[10]. Zhu, Y., et al. (2015). Aligning Books and Movies: Towards Story-like Visual Explanations by Watching Movies and Reading Books. ICCV.
[11]. Howard, J., and Ruder, S. (2018). Fine-tuned Language Models for Text Classification. arXiv preprint arXiv:1801.06146.
[12]. Rojas, Santiago. "Automating Customer Service with AI-Powered Large Language Models." Journal of Innovative Technologies 7.1 (2024).
[13]. Chen, Zhiyu Zoey, et al. "A Survey on Large Language Models for Critical Societal Domains: Finance, Healthcare, and Law." arXiv preprint arXiv:2405.01769 (2024).
[14]. Jiang, Gongyao, Xinran Shi, and Qiong Luo.(2024) "LLM-Collaboration on Automatic Science Journalism for the General Audience." arXiv preprint arXiv:2407.09756.
[15]. Weber, Christoph Johannes, Sebastian Burgkart, and Sylvia Rothe.(2024) "wr-AI-ter: Enhancing Ownership Perception in AI-Driven Script Writing." Proceedings of the 2024 ACM International Conference on Interactive Media Experiences.
[16]. Zafrir, O., Boudoukh, G., Izsak, P., & Wasserblat, M. (2019). Q8bert: Quantized 8bit bert. arXiv preprint arXiv:1910.06188.
[17]. Sanh, V., Wolf, T., & Rush, A. M. (2020). Movement pruning: Adaptive sparsity by fine-tuning. arXiv preprint arXiv:2005.07683.
[18]. Sanh, V., Debut, L., Chaumond, J., & Wolf, T. (2019). DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter. arXiv preprint arXiv:1910.01108.
[19]. Voita, E., Talbot, D., Moiseev, F., Sennrich, R., & Titov, I. (2019). Analyzing multi-head self-attention: Specialized heads do the heavy lifting, the rest can be pruned. arXiv preprint arXiv:1905.09418.
[20]. Voita, E., Talbot, D., Moiseev, F., Sennrich, R., & Titov, I. (2019). Analyzing multi-head self-attention: Specialized heads do the heavy lifting, the rest can be pruned. arXiv preprint arXiv:1905.09418.
Cite this article
Ren,M. (2024). Advancements and Applications of Large Language Models in Natural Language Processing: A Comprehensive Review. Applied and Computational Engineering,97,55-63.
Data availability
The datasets used and/or analyzed during the current study will be available from the authors upon reasonable request.
Disclaimer/Publisher's Note
The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of EWA Publishing and/or the editor(s). EWA Publishing and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content.
About volume
Volume title: Proceedings of the 2nd International Conference on Machine Learning and Automation
© 2024 by the author(s). Licensee EWA Publishing, Oxford, UK. This article is an open access article distributed under the terms and
conditions of the Creative Commons Attribution (CC BY) license. Authors who
publish this series agree to the following terms:
1. Authors retain copyright and grant the series right of first publication with the work simultaneously licensed under a Creative Commons
Attribution License that allows others to share the work with an acknowledgment of the work's authorship and initial publication in this
series.
2. Authors are able to enter into separate, additional contractual arrangements for the non-exclusive distribution of the series's published
version of the work (e.g., post it to an institutional repository or publish it in a book), with an acknowledgment of its initial
publication in this series.
3. Authors are permitted and encouraged to post their work online (e.g., in institutional repositories or on their website) prior to and
during the submission process, as it can lead to productive exchanges, as well as earlier and greater citation of published work (See
Open access policy for details).
References
[1]. Vaswani, A., et al. (2017). Attention is All You Need. Neural Information Processing Systems.
[2]. Radford, A., et al. (2018). Improving Language Understanding by Generative Pre-training. OpenAI Blog.
[3]. Devlin, J., et al. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. North American Chapter of the Association for Computational Linguistics.
[4]. Brown, T., et al. (2020). Language Models are Few-Shot Learners. Neural Information Processing Systems.
[5]. Rogers, A., et al. (2020). A Primer in BERTology: What we know about how BERT works. Transactional Association of Computational Linguistics.
[6]. Ruder, S., et al. (2019). Transfer Learning in Natural Language Processing. NAACL HLT 2019 Tutorial.
[7]. Wu, Yuting, Ziyu Wang, and Wei D. Lu. (2024) "PIM GPT a hybrid process in memory accelerator for autoregressive transformers." npj Unconventional Computing 1.1.
[8]. Liu, Y., et al. (2019). RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv preprint arXiv:1907.11692.
[9]. Raffel, C., et al. (2019). Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. Journal of Machine Learning Research.
[10]. Zhu, Y., et al. (2015). Aligning Books and Movies: Towards Story-like Visual Explanations by Watching Movies and Reading Books. ICCV.
[11]. Howard, J., and Ruder, S. (2018). Fine-tuned Language Models for Text Classification. arXiv preprint arXiv:1801.06146.
[12]. Rojas, Santiago. "Automating Customer Service with AI-Powered Large Language Models." Journal of Innovative Technologies 7.1 (2024).
[13]. Chen, Zhiyu Zoey, et al. "A Survey on Large Language Models for Critical Societal Domains: Finance, Healthcare, and Law." arXiv preprint arXiv:2405.01769 (2024).
[14]. Jiang, Gongyao, Xinran Shi, and Qiong Luo.(2024) "LLM-Collaboration on Automatic Science Journalism for the General Audience." arXiv preprint arXiv:2407.09756.
[15]. Weber, Christoph Johannes, Sebastian Burgkart, and Sylvia Rothe.(2024) "wr-AI-ter: Enhancing Ownership Perception in AI-Driven Script Writing." Proceedings of the 2024 ACM International Conference on Interactive Media Experiences.
[16]. Zafrir, O., Boudoukh, G., Izsak, P., & Wasserblat, M. (2019). Q8bert: Quantized 8bit bert. arXiv preprint arXiv:1910.06188.
[17]. Sanh, V., Wolf, T., & Rush, A. M. (2020). Movement pruning: Adaptive sparsity by fine-tuning. arXiv preprint arXiv:2005.07683.
[18]. Sanh, V., Debut, L., Chaumond, J., & Wolf, T. (2019). DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter. arXiv preprint arXiv:1910.01108.
[19]. Voita, E., Talbot, D., Moiseev, F., Sennrich, R., & Titov, I. (2019). Analyzing multi-head self-attention: Specialized heads do the heavy lifting, the rest can be pruned. arXiv preprint arXiv:1905.09418.
[20]. Voita, E., Talbot, D., Moiseev, F., Sennrich, R., & Titov, I. (2019). Analyzing multi-head self-attention: Specialized heads do the heavy lifting, the rest can be pruned. arXiv preprint arXiv:1905.09418.