







1. Introduction
In the era of the Internet, online communities are inundated with a vast amount of user-generated content, which makes it difficult for users to objectively and accurately assess the quality of the comment threads. Video games are no exception, where player reviews significantly influence game ratings. Although the system can score the game through players’ comments, the diverse nature of the gaming community and malicious comments can compromise the reliability of the system’s scoring results. As a text categorization task and a branch of NLP, sentiment analysis plays a crucial role in understanding these reviews. A five-dimensional classification was formulated where different words are categorized into different lists (community, gameplay, storyline, sound and graphic). To ensure the integrity of our analysis, the TEXTBLOB model is employed to determine whether the comment recommendation tendency is consistent with the positivity or negativity of the comments’ sentiment, thus excluding the influence of malicious comments on the results. In the experiments, the comments of GTAV and 2077 are used as datasets. ChatGPT is employed to systematically derive some near-synonyms for five dimensional keywords. After vectorizing these words through Word2vec, KeyedVectors is used to obtain more near-synonyms and expand the scope of the dictionary. By analyzing the comments with the keywords for sentiment analysis and obtaining the scores, the analysis results of different models are obtained and compared.
Our research focuses on the following questions:
1. How accurately can sentiment analysis identify the meanings expressed in video game reviews?
2. To what extent can our selected models differentiate between various sentiments in these reviews?
3. Are the results of the analysis of the different models feasible?
2. Literature Review
Sentiment analysis, also known as opinion mining, is a crucial technique in NLP that involves identifying and categorizing opinions expressed in text. Early works in this field, such as those by Xu et al. [1] presented the importance of advances in sentiment analysis techniques and the use of artificial intelligence to mine the emotional tendencies of these comments for effectively capturing public opinion in the context of the large amount of comment data generated by the Internet and social media platforms are emphasized. Similarly, Zadeh et al. [2] outlined an emerging field in Natural Language Processing (NLP) - the study of analyzing human multimodal language.
Chakraborty et al. [3] developed a new sentiment analysis model for video game reviews that uses machine learning algorithms such as Naïve Bayes, Support Vector Machines, Logistic Regression, and Stochastic Gradient Descent, trained on Amazon game reviews and applied to Twitter data. It used a customized voting classifier to improve accuracy by selecting the most supported results from the algorithm. This process involved extensive data preprocessing in order to accurately analyze and generate game ratings based on user sentiment. Detailed analysis confirmed that the model outperformed existing techniques.
Xiao et al. [4] described an evaluation model based on Amazon product reviews that categorizes product reviews into good, medium, and bad, reflecting different emotional responses. It emphasizes the exponential growth of online reviews, with beauty and baby products being particularly popular. The study used the Python library TEXTBLOB to perform word frequency statistics and sentiment analysis on these reviews and found that quality and price were the main concerns of consumers. The presence of the word "love" in the reviews was highly correlated with positive ratings.
And Sirbu et al. [5] conducted a similar study. They focused on sentiment analysis and opinion mining in NLP, specifically examining over 9,500 Amazon game reviews. A principal component analysis of the word count index identified eight sentiment components that explained 51.2% of the variance in reviews. A multivariate ANOVA found that these components differed significantly across positive, negative, and neutral reviews. Using these components, discriminant function analysis classified reviews with 55% accuracy.
In addition, Xu et al. [6] explored how Q&A systems in e-commerce can be enhanced by utilizing customer reviews. And Saju et al. [7] discussed extracting data from news stories, social media, user comments and feedback to categorize sentiment as positive, negative and neutral. Raja and Juliet [8] showed a comparison of several deep learning models and provide recommendations for models suitable for customer feedback analysis. Yessenov and Misailovi´c [9] evaluated the effectiveness of feature extraction techniques through four machine learning methods and discuss the observed trends in accuracy. Greaves et al. [10] used sentiment analysis to interpret patient comments about their healthcare experience. Gkillas et al. [11] studied the sentiment analysis of YouTube video comments to explore the relationship between the emotions expressed in the comments and the popularity of the video. Guzsvinecz and Szucs [12] investigated players’ emotional responses to different video game genres by analyzing game reviews. And Guzsvinecz [13] also explored the complexity of player emotions and experiences through sentiment and textual analysis of challenging video game reviews on Steam. Rajini et al. [14] explored the impact of campaigns on voters’ decision-making processes in electoral politics. Viggiato et al. [15] also explored the performance of sentiment analysis in game reviews. Tompson et al. [16] focused on the development and application of SO-CAL, a dictionary-based sentiment analysis tool. Kathleen et al. [17] developed a classifier designed to predict the contextual polarity of subjective phrases in sentences, capable of automatically scoring words. Kumar et al. [18] explored the capabilities and limitations of highlighting sentiment analysis in a business context, enhancing understanding of how it can be used strategically to assess consumer sentiment in real time. Urriza et al. [19] used Python, they developed a method for analyzing and categorizing customer reviews on the Steam platform and categorizing these reviews into specific gameplay aspects such as audio, gameplay, and graphics, and further categorizing the reviews as positive, neutral, and negative based on sentiment. And Bunyamin et al. [20] also used a plain Bayesian approach to categorize sentiment-based words and sentences, using sentiment scores to identify positive and negative aspects of sentences.
3. Data Sources
The review data for GTAV and Cyberpunk 2077 was from the game publishing platform Steam, which can provide centralized place for game developers to market their games to wide audience, and players can buy, download, and install the games and review games through it. The datasets were downloaded from the website Kaggle, which is a data science competition community focused on providing rich datasets to help machine learning engineers, with 612,380 reviews for Cyberpunk 2077 and 73,339 for GTAV. Since many of these columns were not useful for the study, only the main body of the review and the recommended columns were chosen to be kept. Finally, due to the large amount of raw data, 50,000 comments were randomly selected from the two datasets as the original datasets.
4. Methodology
4.1. Models
Word2Vec
Word2Vec is a natural language processing technique for learning word vectors. It converts words into vectors by training neural networks so that they can be understood and processed by computers. Word vectors from Word2Vec are useful for many NLP tasks such as text categorization, sentiment analysis, and machine translation.
KeyedVector
The KeyedVectors model is a way to map words or phrases in a vocabulary to vectors of real numbers. This concept is at the core of the Word2Vec model. These embeddings efficiently capture the semantic meaning of words, and semantically similar words have similar vector positions in the multidimensional space. KeyedVectors are storage-efficient, storing only word vectors rather than the full model, facilitating operations such as similarity checking, and storing them efficiently for later use without reloading the entire model.
WordNetLemmatizer
WordNetLemmatizer is a natural language processing tool for reducing words to their base forms or lexical elements. Such a tool utilizes the WordNet database, a large lexical network of nouns, verbs, adjectives, and adverbs in the English language, through which the semantic relationships of words can be understood.
TEXTBLOB
TEXTBLOB is an easy-to-use Python-based library designed to quickly handle a wide range of text-related natural language processing tasks. Built on top of the NLTK and Pattern libraries, it provides a rich set of features including sentiment analysis, lexical annotation, noun phrase extraction, translation and language detection, etc. TEXTBLOB’s interface is clean and simple, making it easy for even users without in-depth knowledge of NLP to get started with effective text analysis and processing.
VADER
VADER is a specialized model for analyzing the sentiment of social media texts. It is a lexicon and rule-based tool that recognizes whether a text is positive, negative, or neutral in sentiment and is particularly well suited to deal with informal language in social media. VADER combines a lexicon containing sentiment-related words with a set of heuristic rules, which makes it possible to perceive the polarity and intensity of the sentiment.
4.2. Data Pre-processing
As illustrated in Fig. 1, the data must be preprocessed through the following steps.
Step1 Clean Text
In this step, all non-alphabetic characters are removed and converted into whitespace, keeping only the characters from A to Z and a to z in ASCII. This cleans all punctuations, numbers and special characters. And all letters will be made lower case.
Step2 Sentiment Match
For the dataset of all comments, the possibility of malicious comments was considered, i.e., the sentiment positivity and negativity in main body is opposite to recommendation or not. In order to remove the impact of such data on the study and to clean the database, corrupted information was removed. The following was performed for all reviews: a library called TEXTBLOB was imported. It will be responsible for determining the sentiments in the comments, categorizing it into “positive” and “negative”. Then corresponding “positive” to “Recommended” and “negative” to “Not Recommended”. And finally, delete the comments whose recommendations do not match the sentiment analysis given by TEXTBLOB.
Step3 Stopwords
Stopwords are the words that are often used in natural language but need to be removed in text processing. They are usually prepositions, correlatives, for examples: ‘in’ ‘the’ ‘how’ ‘and’. They also do not have sentiment value, so these words were removed.
Step4 WordNetLemmatization
To reduce the amount of processing, it is necessary to decrease the diversity of the vocabulary by reducing the words with different lexical properties. In the research, WordNetLemmatizer was used to lemmatize all words in the text. It can switch different forms of words to their original form.
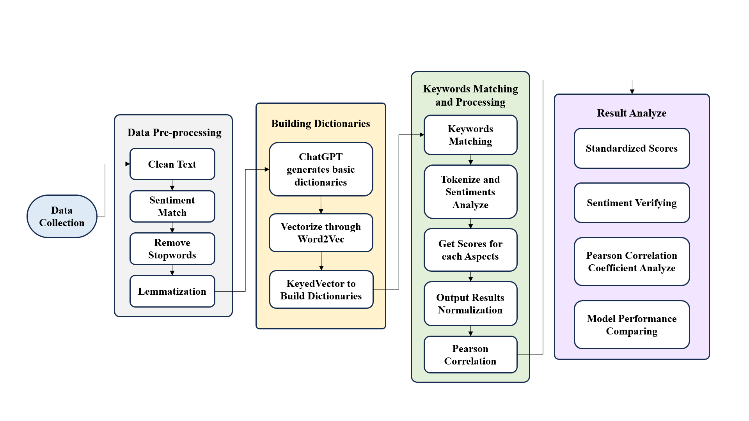
Figure 1. Flowchart of the entire methodology, including pre-experimental preparation and post-experimental analysis.
4.3. Building Dictionaries
Step1 ChatGPT generates basic dictionaries
Visualization based on API Applying OpenAI's universal API programming library, the base dictionaries are constructed, referring to five gaming assessment aspects, namely graphics, soundtrack, gameplay, community, and storytelling. The API initializes each dimension with an initial dictionary formed of 30-50 words that are lexicographically consistent with the relevant overall assessment criteria, which together represent the essential features of the corresponding dimension.
Step2 Vectorize through Word2Vec
Transitioning with the help of Word2Vec The next stage of the process involves transferring the dictionaries into a form accepted by computers through the Word2Vec model. Hyper-parameters of a neural network model, which transforms words into a high-dimensional space, are selected so that the semantic content is well protected, and similar words are located apart in the space. This kind of range describes cleverly small semantic distinctions, which is critical for the subsequent exploration and analysis.
Step3 KeyedVector to Build Dictionaries
Extending a dictionary to Non-Database Word Representation The dictionaries are expanded as needed by use of the most similar words from KeyedVectors. This is done through a process that involves looking up each word in the dictionaries, mapping it to a corresponding vector in the vector space so that from 600 to 980 words in each dimension's dictionary form suits the type of sentiment. Such coverage achieves completeness and is very supportive to perform deep qualitative analysis of sentiment.
4.4. Keywords Matching and Processing
Step1 Keywords Matching
The sentiments learned from the various models are then applied to a sentiment model that has undergone training on a given dataset. The model will establish a systematic process where words in the dictionaries of every perception will be matched with specific words forming the keywords; these words will help in spotting pertinent oral exchange or reviews. Hence, this process will give allowance to the fact that words that address the same evaluation dimension are placed in the same directories.
Step2 Tokenize and Sentiments Analyze
Once this is done, the sentiment analysis model further requires a tokenizer to segregate the content of the comment and eliminate those parts requiring detailed study with regard to the keywords mentioned by the user. Thus, these sentences are evaluated for their sentiment by the model, which first looks on whether these words are positive, negative, or neither, and then measures the intensity of the words that are associated with.
Step3 Get Scores for each Aspects
The model collects the sentiment scores that spread the parcel of the dataset. The final scores should be calculated over all so that you are able to calculate the final value of each. This calculation will be helping researchers to make a quantitative sentiment analysis that is reflective of the different evaluation criteria rated by the users.
Step4 Output Results Normalization
Through the standardization of the scores, the issue of reliability due to variance in data is overcome, making the end results more consistent and justifiable. For the fact that, the scores are first pounded into the range within 0 and 5, and that is followed by slowly adjusting the result to fit within a given minimum and maximum range. The results in this standardization approach provide between-calculations and further interpretation.
Step5 Pearson Correlation Coefficient
In the end, Pearson's correlation coefficient allows us to examine the interconnections among the designated components of the system. This statistic represents the strength of linear association between two variables, and it gives out a number between -1 and 1. If the number is 0, that means the selected variables are uncorrelated, while positive values indicate a strong positive relationship between the two, and negative values represent a negative one.
These processes have been vital to establish an in-depth analysis of users' sentiments towards the gaming experience, uncovering their thoughts and feelings on each aspect and the relationships between them.
\( r=\frac{∑({x_{i}}-\bar{x})({y_{i}}-\bar{y})}{\sqrt[]{∑{({x_{i}}-\bar{x})^{2}}Σ{({y_{i}}-\bar{y})^{2}}}} \) (1)
Where the Pearson correlation formula is as follows:
• \( {x_{i}} \) and \( {y_{i}} \) represent individual data points for variables \( x \) and \( y \) , respectively;
• \( \bar{x} \) and \( \bar{y} \) are the means of \( x \) and \( y \) .
1. Positive Correlation: When \( r \) is between \( 0 \) and \( 1 \) , it indicates a positive correlation, meaning that as the value of \( x \) increases (or decreases), the value of \( y \) also increases (or decreases).
2. Negative Correlation: When \( r \) is between \( -1 \) and \( 0 \) , it indicates a negative correlation, meaning that as the value of \( x \) increases, the value of \( y \) decreases, and vice versa.
3. No Correlation: When \( r \) is \( 0 \) , it indicates no linear correlation between \( x \) and \( y \) .
5. Result Analyze
5.1. Standardized Scores
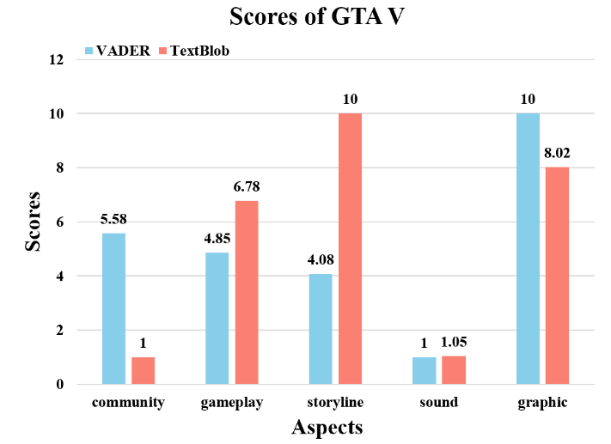
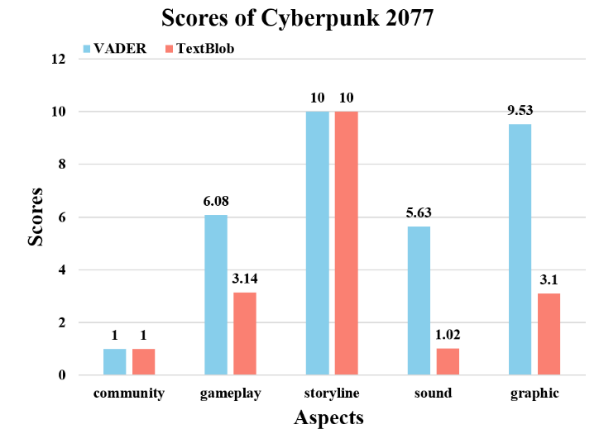
(b)
Figure 2. Overall caption for the two figures: (a) the normalized scores of GTAV in two models, (b) the normalized scores of 2077 in two models.
Figures 2 shows the normalized scores for the five dimensions of GTAV and 2077. In Figure 1, the highest score in the VADER model is graphic, and the lowest score is sound. The highest score in the TEXTBLOB model was Storyline, and the lowest score was Community. In Figure 2, the highest score in both models is storyline, and the lowest score is community. Looking at the figure, it can be seen that the Vader model scores higher than TEXTBLOB across the board, but due to the different ways the two models calculate, it can be observed that the two models do not score exactly the same trend for the two games, which is considered reasonable.
5.2. Sentiment Verifying
Table 1. Sentiment Counters
positive counts | negative counts | |||
GTA V | VADER | community | 16032 | 7805 |
gameplay | 6136 | 3489 | ||
storyline | 8244 | 4727 | ||
sound | 12073 | 7546 | ||
graphic | 5737 | 2612 | ||
TEXTBLOB | community | 12016 | 11072 | |
gameplay | 4271 | 3394 | ||
storyline | 4114 | 2871 | ||
sound | 5165 | 5067 | ||
graphic | 3216 | 2328 | ||
2077 | VADER | community | 20971 | 2591 |
gameplay | 8496 | 1270 | ||
storyline | 14207 | 1653 | ||
sound | 13696 | 1892 | ||
graphic | 9036 | 1892 | ||
TEXTBLOB | community | 18031 | 5109 | |
gameplay | 6698 | 2001 | ||
storyline | 11687 | 2637 | ||
sound | 5448 | 1691 | ||
graphic | 5951 | 1672 |
Table1 presents a count of the number of positive and negative comments for each dimension, as calculated by two different models. It is evident that there are far more positive than negative reviews for all dimensions of the two games across different models, which makes the overall game reviews show a positive sentiment. And that means the public has a positive attitude towards both games, which is also the same as the actual results on Steam.
5.3. Pearson Correlation Coefficient Analyze
Table 2. GTA V in VADER and TEXTBLOB model
VADER | storyline | gameplay | community | sound | graphic | |
community | 1 | 0.672408 | 0.712824 | 0.725463 | 0.67007 | |
gameplay | 0.672408 | 1 | 0.643651 | 0.689745 | 0.617535 | |
storyline | 0.712824 | 0.643651 | 1 | 0.825229 | 0.606267 | |
sound | 0.725463 | 0.689745 | 0.825229 | 1 | 0.626679 | |
graphic | 0.67007 | 0.617535 | 0.606267 | 0.626679 | 1 | |
TEXTBLOB | storyline | gameplay | community | sound | graphic | |
community | 1 | 0.429474 | 0.31283 | 0.239143 | 0.336488 | |
gameplay | 0.429474 | 1 | 0.305509 | 0.260136 | 0.28269 | |
storyline | 0.31283 | 0.305509 | 1 | 0.391187 | 0.285947 | |
sound | 0.239143 | 0.260136 | 0.391187 | 1 | 0.208384 | |
graphic | 0.336488 | 0.28269 | 0.285947 | 0.208384 | 1 |
Table 2 shows the correlation coefficient matrix obtained by running on the GTAV dataset under the VADER model and TEXTBLOB model.
Table 3. 2077 in VADER and TEXTBLOB model
VADER | storyline | gameplay | community | sound | graphic | |
community | 1 | 0.658052 | 0.69608 | 0.700398 | 0.649069 | |
gameplay | 0.658052 | 1 | 0.582414 | 0.647305 | 0.587935 | |
storyline | 0.69608 | 0.582414 | 1 | 0.705043 | 0.581938 | |
sound | 0.700398 | 0.647305 | 0.705043 | 1 | 0.607741 | |
graphic | 0.649069 | 0.587935 | 0.581938 | 0.607741 | 1 | |
TEXTBLOB | storyline | gameplay | community | sound | graphic | |
community | 1 | 0.473815 | 0.340565 | 0.235691 | 0.33706 | |
gameplay | 0.473815 | 1 | 0.285728 | 0.207654 | 0.278554 | |
storyline | 0.340565 | 0.285728 | 1 | 0.277565 | 0.276273 | |
sound | 0.235691 | 0.207654 | 0.277565 | 1 | 0.201087 | |
graphic | 0.33706 | 0.278554 | 0.276273 | 0.201087 | 1 |
Table 3 shows the correlation coefficient matrix run on the 2077 dataset under the VADER model and TEXTBLOB model.
For the results of different models.
For GTAV: The correlation coefficients between sound and community were 0.825 (VADER) and 0.391 (TEXTBLOB), respectively. The correlation between storyline and community is 0.713 (VADER) and 0.313 (TEXTBLOB) is always high, which indicates that there is a strong correlation between the evaluations of GTA V, sound and community, and between storyline and community, and they have a great influence on each other. The correlation coefficients of sound and graphic are 0.627 (VADER) and 0.208 (TEXTBLOB), respectively, and the correlation between them is always low, which indicates that the degree of interaction between sound and graphic is small, and the user’s evaluation of them is usually more independent.
For 2077: The correlation coefficients for gameplay and storyline were 0.658 (VADER) and 0.474 (TEXTBLOB), respectively, 0.696 (VADER) and 0.341 (TEXTBLOB) for storyline and community, respectively. The correlation is always high, which indicates that for 2077, gameplay and storyline, and storyline and community evaluations have a strong correlation, and they influence each other greatly. 2077 does not always have a pair of dimensions with low correlation, which also indicates that there is a certain correlation between the dimensions of 2077.
5.4. Model Performance Comparing
By comparing the results of different models for the dimensional correlation of different games, it can be found that the VADER scores the sentiment analysis of reviews significantly higher than that of the TEXTBLOB, and the VADER model shows more sensitivity to the positive emotion while TEXTBLOB is more sensitive to the negative emotion. VADER is also more closely correlated across dimensions. These differences stem from the differences in sentiment analysis methods between the two models. VADER is based on dictionaries and rules, and is better suited for handling short texts and social media comments, while TEXTBLOB is more focused on the cumulative effect of emotional words. A conclusion can be drawn from the sentiment analysis between VADER and TEXTBLOB: The VADER model is better at capturing emotional changes in game reviews. It is especially good at correlation analysis, which looks more unified and cohesive. TEXTBLOB also performs well, but in some dimensions, it shows a lower correlation in certain areas. As a result, it may not fully represent the user’s emotional inclination towards various aspects related to the game. This discovery is significant for game creators and UX architects. The VADER model can be used to get closer to the user’s actual emotion towards the game, which makes it easier to optimize the game design and further improve user satisfaction.
6. Conclusion
In our research, five specialized dictionaries are developed to assess different dimensions of video games, namely community, gameplay, storyline, sound and graphics. Based on the existing game evaluation system on the Steam platform, a more in-depth sentiment analysis of user reviews is conducted through two sentiment analysis models: TEXTBLOB and VADER. Compared with the original evaluation system, our multi-dimensional evaluation system can evaluate in detail to comprehensively present the strengths and weaknesses of various aspects of the game, which helps users make more correct judgments when browsing game details. The model was employed to score GTAV and Cyberpunk 2077 across multiple dimensions, scoring each dimension separately. The results, analyzed through correlation matrices, revealed notable relationships between different facets of the games. And the differences between the TEXTBLOB and VADER sentiment analysis models are compared. Looking forward, we aim to enhance the accuracy of our sentiment analysis by refining our dictionaries and incorporating advanced weighting mechanisms. This improvement will further augment the reliability of our multi-dimensional evaluation system, ultimately providing a robust tool for both consumers and developers to gauge the multifaceted quality of video games.
Acknowledgement
Liwei Yuan, Maoxiang Ding, Feiyang Meng, and Yumin Tian contributed equally to this work and should be considered co-first authors.
References
[1]. Xu, G., Meng, Y., Qiu, X., Yu, Z., Wu, X. (2019). Sentiment Analysis of Comment Texts Based on BiLSTM. IEEE Access, 7, 51522–51532. IEEE Access. https://doi.org/10.1109/ACCESS.2019.2909919
[2]. Bagher Zadeh, A., Liang, P. P., Poria, S., Cambria, E., Morency, L.-P. (2018a). Multimodal Language Analysis in the Wild: CMU-MOSEI Dataset and Interpretable Dynamic Fusion Graph. In I. Gurevych Y. Miyao (Eds.), Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (pp. 2236–2246). Association for Computational Linguistics. https://doi.org/10.18653/v1/P18-1208
[3]. Chakraborty, S., Mobin, I., Roy, A., Khan, M. H. (2018). Rating Generation of Video Gamesusing Sentiment Analysis and Contextual Polarity from Microblog. 2018 International Conference on Computational Techniques, Electronics and Mechanical Systems (CTEMS), 157–161. https://doi.org/10.1109/CTEMS.2018.8769149
[4]. Xiao, Y., Qi, C., Leng, H. (2021a). Sentiment analysis of Amazon product reviews based on NLP. 2021 4th International Conference on Advanced Electronic Materials, Computers and Software Engineering (AEMCSE), 1218–1221. https://doi.org/10.1109/AEMCSE51986.2021.00249
[5]. Sirbu, D., Secui, A., Dascalu, M., Crossley, S. A., Ruseti, S., Trausan-Matu, S. (2016). Extracting Gamers’ Opinions from Reviews. 2016 18th International Symposium on Symbolic and Numeric Algorithms for Scientific Computing (SYNASC), 227–232. https://doi.org/10.1109/SYNASC.2016.044
[6]. Xu, H., Liu, B., Shu, L., Yu, P. S. (2019). BERT Post-Training for Review Reading Comprehension and Aspect-based Sentiment Analysis (arXiv:1904.02232). arXiv. https://doi.org/10.48550/arXiv.1904.02232
[7]. Saju, B., Jose, S., Antony, A. (2020). Comprehensive Study on Sentiment Analysis: Types, Approaches, Recent Applications, Tools and APIs. 2020 Advanced Computing and Communication Technologies for High Performance Applications (ACCTHPA), 186–193. https://doi.org/10.1109/ACCTHPA49271.2020.9213209
[8]. Raja, J. G. J. S., Juliet, S. (2023). Deep Learning-based Sentiment Analysis of Trip Advisor Reviews. 2023 2nd International Conference on Applied Artificial Intelligence and Computing (ICAAIC), 560–565. https://doi.org/10.1109/ICAAIC56838.2023.10140848
[9]. Yessenov, K., Misailovic, S. (2009). Sentiment Analysis of Movie. https://www.semanticscholar.org/paper/Sentiment-Analysis-of-Movie-Yessenov-Misailovic/cbad1c16d8270f1f1ecd542518ee933922bd647c
[10]. Greaves, F., Ramirez-Cano, D., Millett, C., Darzi, A., Donaldson, L. (2013). Use of Sentiment Analysis for Capturing Patient Experience From Free-Text Comments Posted Online. Journal of Medical Internet Research, 15(11), e2721. https://doi.org/10.2196/jmir.2721
[11]. Gkillas, A., Simos, M. A., Makris, C. (2023). Popularity Inference Based on Semantic Sentiment Analysis of YouTube Video Comments. 2023 14th International Conference on Information, Intelligence, Systems Applications (IISA), 1–6. https://doi.org/10.1109/IISA59645.2023.10345963
[12]. Guzsvinecz, T., Szűcs, J. (2023). Length and sentiment analysis of reviews about top-level video game genres on the steam platform. Computers in Human Behavior, 149, 107955. https://doi.org/10.1016/j.chb.2023.107955
[13]. Guzsvinecz, T. (2023). Sentiment Analysis of Souls-like Role-Playing Video Game Reviews. Acta Polytechnica Hungarica, 20(5), 149–168. https://doi.org/10.12700/APH.20.5.2023.5.10
[14]. A, R., Kommarajula, R., Pranav, C. N., Prasanna, M. S. (2023). Analyzing the Voters’ View: Emotional Sentiment vs Long Run Development, of Casting Votes in Elections Using NLP. 2023 International Conference on Computational Intelligence, Networks and Security (ICCINS), 1–5. https://doi.org/10.1109/ICCINS58907.2023.10450030
[15]. Viggiato, M., Lin, D., Hindle, A., Bezemer, C.-P. (2022). What Causes Wrong Sentiment Classifications of Game Reviews? IEEE Transactions on Games, 14(3), 350–363. IEEE Transactions on Games. https://doi.org/10.1109/TG.2021.3072545
[16]. Thompson, J. J., Leung, B. H., Blair, M. R., Taboada, M. (2017). Sentiment analysis of player chat messaging in the video game StarCraft 2: Extending a lexicon-based model. Knowledge-Based Systems, 137, 149–162. https://doi.org/10.1016/j.knosys.2017.09.022
[17]. McKeown, K., Agarwal, A., Biadsy, F. (2009). Contextual Phrase-Level Polarity Analysis using Lexical Affect Scoring and Syntactic N-grams. https://doi.org/10.7916/D88G8V15
[18]. Kumar, S., Kanshal, S., Sharma, V., Talwar, R. (2022). Sentiment Analysis on Amazon Alexa Reviews Using NLP Classification. 2022 4th International Conference on Advances in Computing, Communication Control and Networking (ICAC3N), 353–358. https://doi.org/10.1109/ICAC3N56670.2022.10074086
[19]. Urriza, I. M., Clariño, M. A. A. (2021). Aspect-Based Sentiment Analysis of User Created Game Reviews. 2021 24th Conference of the Oriental COCOSDA International Committee for the Co-Ordination and Standardisation of Speech Databases and Assessment Techniques (O-COCOSDA), 76–81. https://doi.org/10.1109/OCOCOSDA202152914.2021.9660559
[20]. Bunyamin, M. A. F., Pudjiantoro, T. H., Renaldi, F., Hadiana, A. I. (2022). Analyzing Sentiments on Indonesia’s New National Palace using The Combination of Naive Bayes and Sentiment Scoring. 2022 International Conference on Science and Technology (ICOSTECH), 1–6. https://doi.org/10.1109/ICOSTECH54296.2022.9829075
Cite this article
Yuan,L.;Ding,M.;Meng,F.;Tian,Y. (2025). Sentiment Analysis and Rating Video Game Dimensions via NLP. Applied and Computational Engineering,132,1-10.
Data availability
The datasets used and/or analyzed during the current study will be available from the authors upon reasonable request.
Disclaimer/Publisher's Note
The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of EWA Publishing and/or the editor(s). EWA Publishing and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content.
About volume
Volume title: Proceedings of the 2nd International Conference on Machine Learning and Automation
© 2024 by the author(s). Licensee EWA Publishing, Oxford, UK. This article is an open access article distributed under the terms and
conditions of the Creative Commons Attribution (CC BY) license. Authors who
publish this series agree to the following terms:
1. Authors retain copyright and grant the series right of first publication with the work simultaneously licensed under a Creative Commons
Attribution License that allows others to share the work with an acknowledgment of the work's authorship and initial publication in this
series.
2. Authors are able to enter into separate, additional contractual arrangements for the non-exclusive distribution of the series's published
version of the work (e.g., post it to an institutional repository or publish it in a book), with an acknowledgment of its initial
publication in this series.
3. Authors are permitted and encouraged to post their work online (e.g., in institutional repositories or on their website) prior to and
during the submission process, as it can lead to productive exchanges, as well as earlier and greater citation of published work (See
Open access policy for details).
References
[1]. Xu, G., Meng, Y., Qiu, X., Yu, Z., Wu, X. (2019). Sentiment Analysis of Comment Texts Based on BiLSTM. IEEE Access, 7, 51522–51532. IEEE Access. https://doi.org/10.1109/ACCESS.2019.2909919
[2]. Bagher Zadeh, A., Liang, P. P., Poria, S., Cambria, E., Morency, L.-P. (2018a). Multimodal Language Analysis in the Wild: CMU-MOSEI Dataset and Interpretable Dynamic Fusion Graph. In I. Gurevych Y. Miyao (Eds.), Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (pp. 2236–2246). Association for Computational Linguistics. https://doi.org/10.18653/v1/P18-1208
[3]. Chakraborty, S., Mobin, I., Roy, A., Khan, M. H. (2018). Rating Generation of Video Gamesusing Sentiment Analysis and Contextual Polarity from Microblog. 2018 International Conference on Computational Techniques, Electronics and Mechanical Systems (CTEMS), 157–161. https://doi.org/10.1109/CTEMS.2018.8769149
[4]. Xiao, Y., Qi, C., Leng, H. (2021a). Sentiment analysis of Amazon product reviews based on NLP. 2021 4th International Conference on Advanced Electronic Materials, Computers and Software Engineering (AEMCSE), 1218–1221. https://doi.org/10.1109/AEMCSE51986.2021.00249
[5]. Sirbu, D., Secui, A., Dascalu, M., Crossley, S. A., Ruseti, S., Trausan-Matu, S. (2016). Extracting Gamers’ Opinions from Reviews. 2016 18th International Symposium on Symbolic and Numeric Algorithms for Scientific Computing (SYNASC), 227–232. https://doi.org/10.1109/SYNASC.2016.044
[6]. Xu, H., Liu, B., Shu, L., Yu, P. S. (2019). BERT Post-Training for Review Reading Comprehension and Aspect-based Sentiment Analysis (arXiv:1904.02232). arXiv. https://doi.org/10.48550/arXiv.1904.02232
[7]. Saju, B., Jose, S., Antony, A. (2020). Comprehensive Study on Sentiment Analysis: Types, Approaches, Recent Applications, Tools and APIs. 2020 Advanced Computing and Communication Technologies for High Performance Applications (ACCTHPA), 186–193. https://doi.org/10.1109/ACCTHPA49271.2020.9213209
[8]. Raja, J. G. J. S., Juliet, S. (2023). Deep Learning-based Sentiment Analysis of Trip Advisor Reviews. 2023 2nd International Conference on Applied Artificial Intelligence and Computing (ICAAIC), 560–565. https://doi.org/10.1109/ICAAIC56838.2023.10140848
[9]. Yessenov, K., Misailovic, S. (2009). Sentiment Analysis of Movie. https://www.semanticscholar.org/paper/Sentiment-Analysis-of-Movie-Yessenov-Misailovic/cbad1c16d8270f1f1ecd542518ee933922bd647c
[10]. Greaves, F., Ramirez-Cano, D., Millett, C., Darzi, A., Donaldson, L. (2013). Use of Sentiment Analysis for Capturing Patient Experience From Free-Text Comments Posted Online. Journal of Medical Internet Research, 15(11), e2721. https://doi.org/10.2196/jmir.2721
[11]. Gkillas, A., Simos, M. A., Makris, C. (2023). Popularity Inference Based on Semantic Sentiment Analysis of YouTube Video Comments. 2023 14th International Conference on Information, Intelligence, Systems Applications (IISA), 1–6. https://doi.org/10.1109/IISA59645.2023.10345963
[12]. Guzsvinecz, T., Szűcs, J. (2023). Length and sentiment analysis of reviews about top-level video game genres on the steam platform. Computers in Human Behavior, 149, 107955. https://doi.org/10.1016/j.chb.2023.107955
[13]. Guzsvinecz, T. (2023). Sentiment Analysis of Souls-like Role-Playing Video Game Reviews. Acta Polytechnica Hungarica, 20(5), 149–168. https://doi.org/10.12700/APH.20.5.2023.5.10
[14]. A, R., Kommarajula, R., Pranav, C. N., Prasanna, M. S. (2023). Analyzing the Voters’ View: Emotional Sentiment vs Long Run Development, of Casting Votes in Elections Using NLP. 2023 International Conference on Computational Intelligence, Networks and Security (ICCINS), 1–5. https://doi.org/10.1109/ICCINS58907.2023.10450030
[15]. Viggiato, M., Lin, D., Hindle, A., Bezemer, C.-P. (2022). What Causes Wrong Sentiment Classifications of Game Reviews? IEEE Transactions on Games, 14(3), 350–363. IEEE Transactions on Games. https://doi.org/10.1109/TG.2021.3072545
[16]. Thompson, J. J., Leung, B. H., Blair, M. R., Taboada, M. (2017). Sentiment analysis of player chat messaging in the video game StarCraft 2: Extending a lexicon-based model. Knowledge-Based Systems, 137, 149–162. https://doi.org/10.1016/j.knosys.2017.09.022
[17]. McKeown, K., Agarwal, A., Biadsy, F. (2009). Contextual Phrase-Level Polarity Analysis using Lexical Affect Scoring and Syntactic N-grams. https://doi.org/10.7916/D88G8V15
[18]. Kumar, S., Kanshal, S., Sharma, V., Talwar, R. (2022). Sentiment Analysis on Amazon Alexa Reviews Using NLP Classification. 2022 4th International Conference on Advances in Computing, Communication Control and Networking (ICAC3N), 353–358. https://doi.org/10.1109/ICAC3N56670.2022.10074086
[19]. Urriza, I. M., Clariño, M. A. A. (2021). Aspect-Based Sentiment Analysis of User Created Game Reviews. 2021 24th Conference of the Oriental COCOSDA International Committee for the Co-Ordination and Standardisation of Speech Databases and Assessment Techniques (O-COCOSDA), 76–81. https://doi.org/10.1109/OCOCOSDA202152914.2021.9660559
[20]. Bunyamin, M. A. F., Pudjiantoro, T. H., Renaldi, F., Hadiana, A. I. (2022). Analyzing Sentiments on Indonesia’s New National Palace using The Combination of Naive Bayes and Sentiment Scoring. 2022 International Conference on Science and Technology (ICOSTECH), 1–6. https://doi.org/10.1109/ICOSTECH54296.2022.9829075