







1. Introduction
In the rapid development of artificial intelligence, WeChat, Twitter, blogs, and Amazon's constantly fashionable human-computer interaction have become increasingly popular, social media platforms generate more than 5 billion tweets daily, and e-commerce review systems process tens of thousands of user feedback. The phenomenon of data explosion makes the importance of Textual Emotion Analysis (TEA) technology increasingly prominent. The important branch of natural language processing, textual emotion processing research, is becoming increasingly popular. TEA helps numerous fields develop effectively, such as artificial intelligence, finance, marketing, advertising and interdisciplinary [1]. It mainly uses computational models to automatically identify, extract and quantify the textual subjective emotional tendencies. This cross-field has enabled TEA to be upgraded from a single technical tool to a vital research paradigm in social cognitive science. Its current application scenarios have covered key dimensions of social governance, such as business decision support, policy effect evaluation, and mental health intervention.
The TEA has numerous application scenarios. One of the earliest uses of TEA in finance was on Yahoo stock forums [1]. The core value of this application scene is to transform unstructured text data into quantifiable emotion indicators, providing data-driven insights for market forecasting, risk management and investment decisions. The application of TEA in the market field has gradually matured. Enterprises can conduct emotion mining on massive text data such as consumer evaluations, social media comments and news reports, use mainstream models for large-scale pre-training to learn rich contextual semantic information, and then fine-tune with emotion annotation data to capture market emotion in real-time and optimize brand strategies and investment decisions. Moreover, TEA technology provides a wealth of training signals and ways to improve semantic understanding capabilities for large language model development. In particular, incorporating emotion annotation data into pre-trained models significantly improves the grasp of the model of complex language phenomena. TEA can also be used in human-computer interaction research to interact with people based on their emotional state. It benefits any company or organization that wants to evaluate the impact of its commodities and actions on people. Observing people's emotional reactions also helps manage those businesses or organisations.
Natural language processing has a tremendous impact on TEA research. Sezai Tunca et al. use the Valence Aware Dictionary and sentiment reasoner model for emotion classification and analyze the content and emotion of 158 Metaverse articles from The Guardian in 2021-2022 using natural language processing technology [2]. Many researchers use emotion lexicons for relevant research. As a key step in the lexicon and rule-based approaches, this method matches text keywords with positive and negative emotion scores using pre-built vocabulary lists. Then, it calculates overall emotion scores using weighted averaging. Birjali et al. proposed an emotion lexicon and rule-based framework by systematically summarising textual analysis studies [3]. They established search criteria, filtered databases, categorized approaches into pure lexicon and enhanced rule-based methods, demonstrating how rules overcome lexicon limitations in complex language contexts. Recent TEA research has shifted toward hybrid approaches, combining traditional and advanced machine learning techniques [3]. This blend maintains transparency and interpretability while improving accuracy and generalisation. In TEA research, textual emotion recognition and detection are crucial for researchers to conduct relevant research. As shown in Figure 1, Jiawen Deng and Fuji Ren make a detailed summary of textual emotion recognition, many advanced methods enhance the precision of emotion recognition. However, these methods still have Challenges to solve.
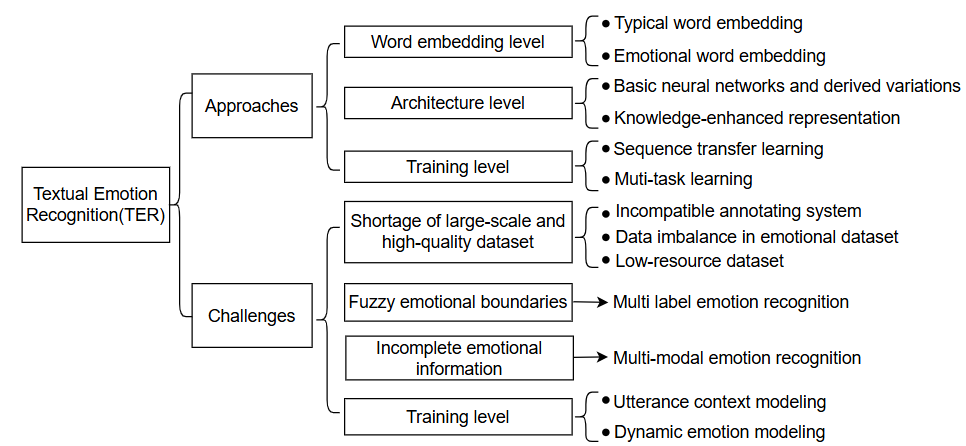
Figure 1: Framework of textual emotion recognition reviewed in this paper [4]
As this paper expresses, TEA has solved many interesting problems. It has also raised many new issues that are worth thinking about finding a solution to. The main goal of this review is to describe and summarise related research on its mainstream methods and their development in TEA, as well as the strengths, weaknesses, and prospects of its methods. This paper enriches the review with a detailed summary of mainstream models of TEA. This paper summarises the concepts and the process of using various research methods and how they are applied in typical application scenarios in TEA. Furthermore, this paper analyses the attention mechanism, context-aware model, fine-grained emotion classification, and so on, and it shows how these techniques can be studied in conjunction with the modelling of TEA. The paper summarises the basic technologies and the mainstream technology models which are widely used methods and how the researchers use them in the field of TEA in Section 2, Then, the paper discusses the strengths and weaknesses of these techniques and strategies, current main challenges and issues and the prospects for their future development in Section 3. Finally, the paper is concluded with a detailed summary in Section 4.
2. Methodology
2.1. Dataset description
The research ways of TEA mainly use lexicon-based traditional machine learning and deep learning based on the emotion lexicon and hybrid methods. Researchers mainly used the International Survey on Emotion Antecedents and Reactions (ISEAR), the Stanford Sentiment Treebank (SST), and the SemEval-2018 Task 1 dataset [4]. The University of Geneva developed the ISEAR dataset in the 1990s, which can be used to study emotion antecedents and cross-cultural responses. ISEAR classifies seven emotions: joy, fear, anger, sadness, disgust, shame, and guilt, based on situational event descriptions and participant demographics. This dataset can be used in emotion classification, text analysis, cross-cultural psychology research and as the basic data of knowledge bases such as EmotiNet. It can make a cluster analysis of emotions through language similarity. SST is a dataset designed for TEA by Richard Socher and his team from Stanford University. This dataset provides rich structural information for TEA. Its features include tree-structured annotations and fine-grained emotion labels. Each sentence is parsed as a syntactic tree and labelled with emotion labels from word and phrase to sentence level, providing local and global emotion supervision information. This dataset is mainly applied in emotion classification model training and optimisation, semantic composition research, and model performance benchmarking. The SemEval-2018 Task 1 dataset comes from the social media Twitter, which contains tweets in English, Arabic, and Spanish, with emotion categories and intensity values annotated, covering multi-classification, regression, and multi-lingual emotion polarity grading. This dataset is suitable for studying emotion recognition, multi-label emotion coexistence, and cross-lingual emotion expression analysis of informal texts in social media.
2.2. Proposed approach
This paper mainly summarises and compares the standard methods of TEA. Its main aim is to analyze the basic and mainstream technical model of TEA research and how to use it. This paper mainly summarises a basic technology, the emotional lexicon, and three mainstream technical models, traditional machine learning models, deep learning models and hybrid models, by summarising and accumulating numerous relevant papers. As shown in Figure 2, this paper first introduces the background of TEA, the standard methods used in TEA and a detailed description of how the researchers make the TEA. Then, this paper analyses how the researchers utilise each model to make the TEA and the detailed process of using the model. Subsequently, this paper organises and compares the findings and results to provide a comprehensive overview and summarise the advantages and disadvantages of each technical model. Finally, this paper discusses the possible challenges, solutions, and future prospects of each model of TEA and draws a detailed conclusion.
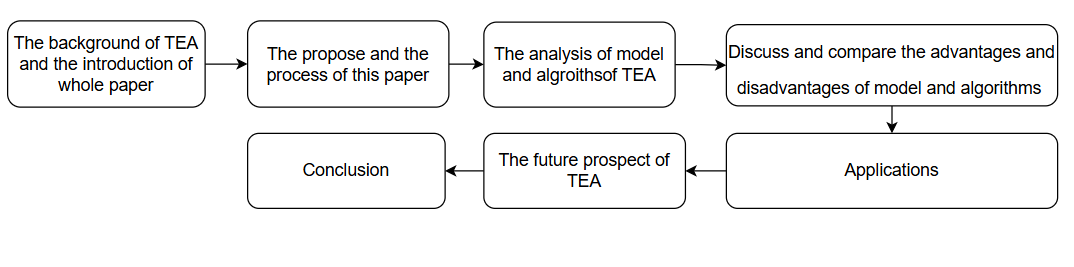
Figure 2: The pipeline of the study of this paper (picture credit: original)
2.2.1. Introduction of basic technology
Various methodological approaches have been developed to tackle the task of TEA, each with its strengths and limitations. Figure 3 broadly categorises the basic technology (emotion lexicon) and the mainstream models (Traditional machine learning, deep learning, and hybrid models). As the basic technology of TEA, the effective usage mode of lexicon-based emotion analysis is to use a pre-built lexicon containing emotion words and their corresponding emotion polarity to judge the overall emotion tendency of the text. The lexicon is a collection of words and their associated emotion scores or polarities [5]. Researchers use this method to calculate the frequency and emotion intensity of emotion words in the text and combine specific rules to obtain the emotion score or emotion category of texts.
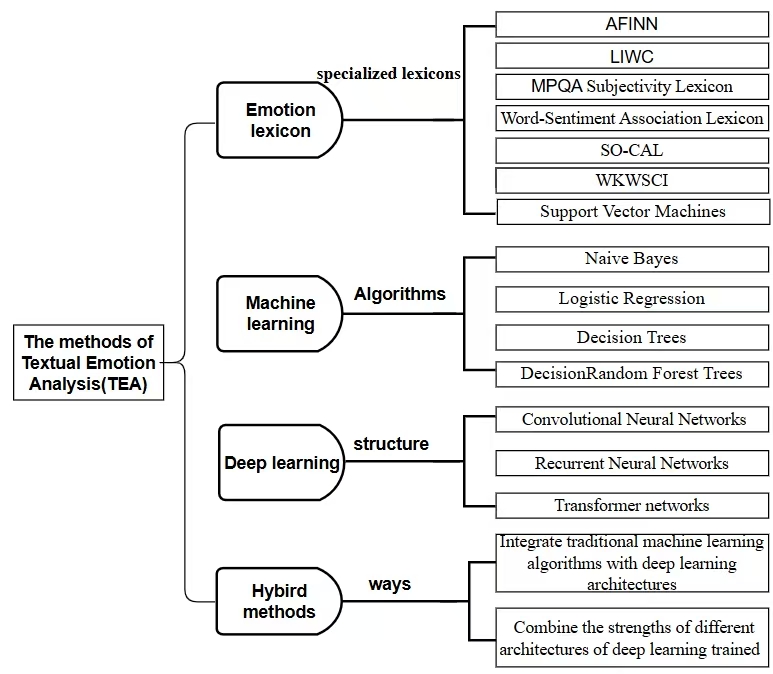
Figure 3: A broad classification of the basic technology and the mainstream models of TEA (picture credit: original)
Figure 4 demonstrates the utilisation of the lexicon-based TEA. Numerous emotion lexicons have been developed over time, including Affective INdex for Norwegian (AFINN), SentiWordNet, Linguistic Inquiry and Word Count (LIWC), General Inquirer, Multi-perspective Question Answering (MPQA) Subjectivity Lexicon, Word-Sentiment Association Lexicon, Semantic Orientation Calculator (SO-CAL), and Wee Kim Wee School of Communication and Information (WKWSCI) Sentiment Lexicon. These specialized lexicons often provide more accurate emotion scores for terms relevant to a particular domain. Also, Researchers have explored techniques to improve the accuracy of lexicon-based methods by incorporating contextual information and developing strategies for handling acronyms and emoticons, which are prevalent in online communication [6].
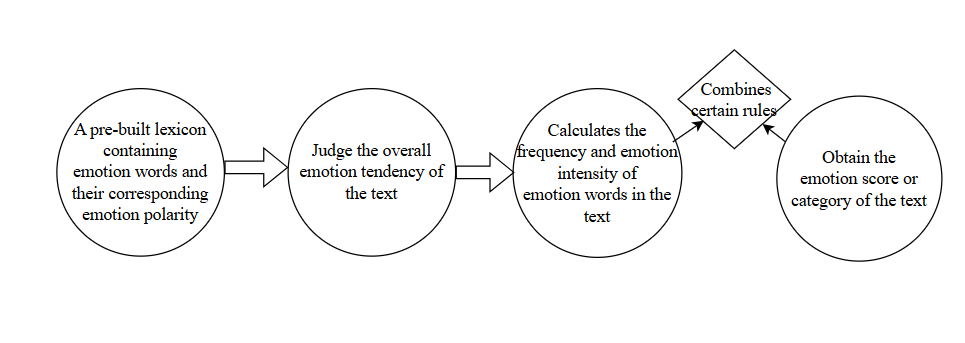
Figure 4: Using the lexicon-based TEA (picture credit: original)
2.2.2. Traditional machine learning methods of TEA
Traditional machine learning methods of TEA training machine learning classifiers on labelled datasets, where each text sample is labelled with the relevant emotion. Once trained, these classifiers can then predict the emotion of new and unseen text. The core feature is extracting a numerical representation that usually transforms raw text into structured feature vectors through the Bag-of-Words (BOW) method. As shown in Figure 5, the traditional machine learning process for TEA generally encompasses preprocessing the text and subsequently extracting features with sentiment lexicons to enhance the semantics. The feature vectors are then used to train a classification model optimally by cross-validating hyperparameters to predict the text sentiment categories. This focus on feature engineering underpins the entire traditional machine learning approach in TEA. Traditional machine learning methods employed for TEA include the use of algorithms like Naive Bayes (NB), Support Vector Machines (SVM), Logistic Regression, Decision Trees and Random Forest [5]. A crucial step in using these methods is feature engineering, in which the text data is transformed into a numerical expression that machine learning models can understand. The feature extraction techniques include BOW, which depicts text as an assemblage of its words, neglecting grammar and syntax; Term Frequency-Inverse Document Frequency (TF-IDF), which assigns weights to words according to their frequency within a document and their inverse frequency throughout the corpus; N-grams, which consider sequences of several words.
Recently, many researchers have focused on comparing the efficiency of different traditional machine learning models for TEA in various domains, examining the impact of different feature extraction techniques on model performance, and gradually applying these methods to specific areas, like financial market analysis and social media monitoring.
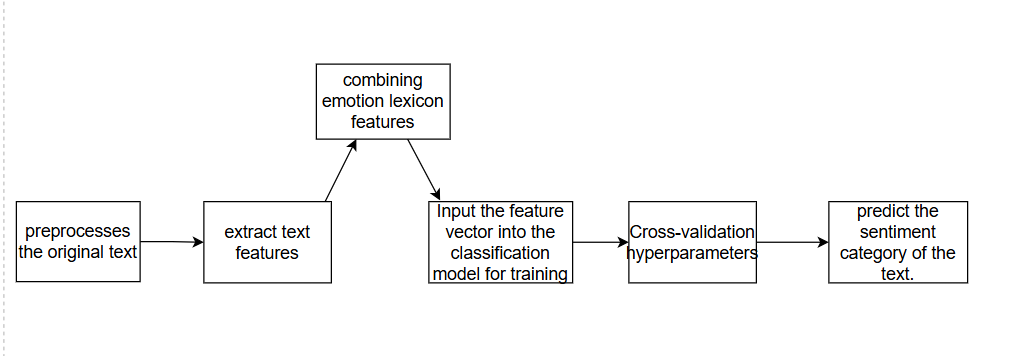
Figure 5: The main process of using traditional machine learning methods (picture credit: original)
2.2.3. Deep learning-based TEA
Deep learning has emerged as a powerful set of techniques for TEA, with its core feature being the ability to automatically learn hierarchical representations from raw textual data, extracting complex semantic and contextual features and eliminating the need for manual feature engineering in many scenarios. This automatic feature extraction allows the model to capture subtle linguistic patterns, long-distance dependencies, and interactions between words that traditional methods may miss, making it greatly effective in detecting a wide range of emotional states [7]. Various deep learning architectures have been applied to TEA, including Convolutional Neural Networks (CNNS), Recurrent Neural Networks (RNNS) such as Long Short-Term Memory (LSTM) and Transformer networks such as Bidirectional Encoder Representations from Transformers (BERT) [5]. Word embedding and contextual embedding also play a crucial role in enhancing the performance of deep learning models for TEA. Word bedding like Global Vectors for Word Representation (GloVe) and Fast Text depict words as dense vectors in a continuous vector space to capture their semantic relationships. Contextual bedding like that generated by BERT goes a step further by considering the context in which a word is situated inside sentences, allowing for a more nuanced understanding of word meaning and emotion [7].
Deep learning models often outperform traditional machine learning methods in TEA, particularly when large amounts of labelled data are available [7]. As shown in Figure 6, deep learning methods automatically learn the deep semantic features of text through neural networks. First, the text is segmented and mapped into word vectors, and input into the neural network architecture. The contextual dependencies and long-distance semantics are captured through multi-layer nonlinear transformations, such as the self-attention mechanism of the Transformer, which can associate global information. Training is performed end-to-end, combining loss functions and optimiser backpropagation to adjust parameters, and pre-trained language models can be used for fine-tuning to improve the effect.
Researchers increasingly use Transformer networks and LLMs like BERT and GPT for TEA, achieving strong benchmark results. Transformers perform in TEA by their attention mechanism, which captures local or global word context and leverages pre-trained knowledge. Pre-trained Transformers achieve high accuracy via fine-tuning on task-specific datasets. Also, the relevant research has recently made significant progress in multimodal feature fusion and representation. Researchers proposed a decoupled-language-focusing (DLF) framework, which aims to separate modality-shared and modality-specific information and enhance language representation through geometric measurements and language-focusing attractors [8].
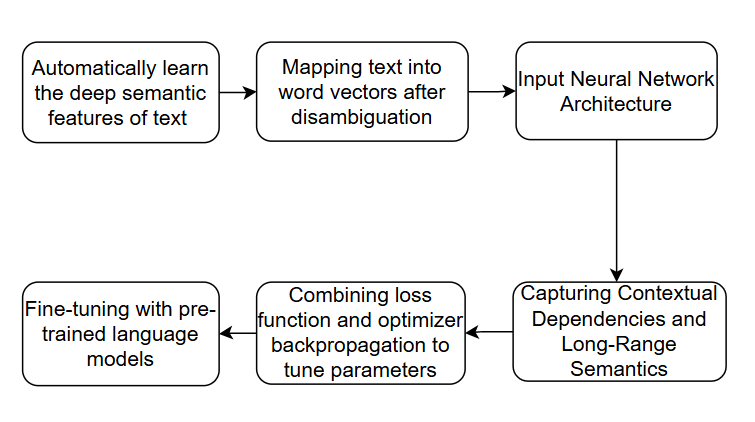
Figure 6: The pipeline of how the researchers use the deep learning methods (picture credit: original)
2.2.4. Hybrid methods-based TEA
As a widely used methodology, Hybrid methods to TEA aim to integrate traditional machine learning algorithms with deep learning architectures. Alternatively, combining the strengths of different architectures of deep learning training is also an essential method for analysing complex emotional expressions of TEA. The goal of these combinations is often to overcome the limitations of individual methods and achieve better overall performance in terms of accuracy, robustness, and generalizability. Figure 7 shows the usage mode of these two hybrid methods.
In TEA, researchers often combine Transformer models (such as BERT) with traditional machine learning methods. By fusing the high-dimensional context embedding features generated by the Transformer with traditional text features and its classifiers or adopting a stacking integration strategy, such as processing Transformer output with traditional classifiers, the classification performance has been significantly improved. Itay Etelis et al. combined the lightweight Transformer model Distilbert with a machine learning classifier to analyse the emotional dynamics in chat conversations [9]. This hybrid method can capture deep semantic associations while taking advantage of traditional methods' interpretability and low resource advantages, showing complementary advantages in cross-domain emotion classification tasks and fine-grained emotion recognition tasks [10].
The Fusion of multiple neural network architectures is an effective hybrid TEA method. The hybrid method of CNNS and RNNS in TEA combines the strengths of both architectures to capture complementary features from textual data. This method, CNNs, is first employed to automatically extract local features and n-gram patterns from the input text, effectively learning spatial hierarchies within short phrases. These high-level features are then passed to RNNs. RNNs handle sequential data by maintaining a hidden state that captures information from previous time steps. This hybrid mechanism enables the model to understand the immediate expression of emotions in isolated phrases and how these expressions are modulated by the surrounding context, leading to a more nuanced and robust detection of emotional states in textual data.
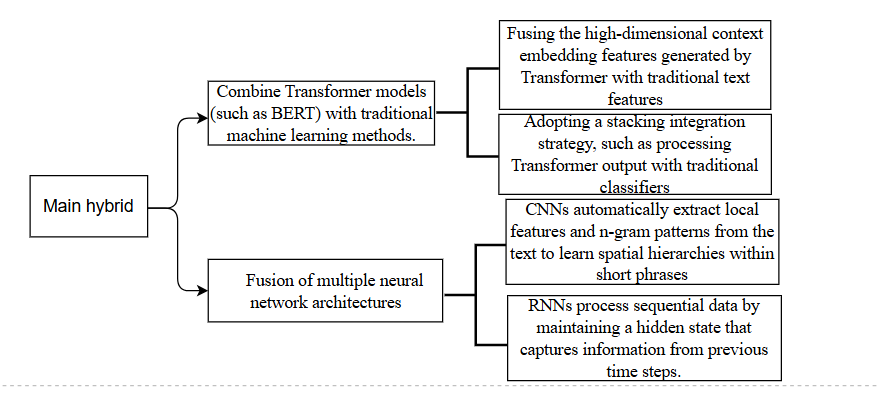
Figure 7: The usage mode of the two hybrid methods (picture credit: original)
2.2.5. The evolution of TEA techniques
The progression of TEA techniques demonstrates a clear trend from simple, knowledge-driven, lexicon-based and traditional machine learning methods to more sophisticated data-driven approaches using deep learning and hybrid methods. This evolution results from the growing accessibility of large labelled datasets and computational resources.
3. Discussion
3.1. The strengths and weaknesses of each method
Lexicon-based methods offer numerous advantages, including simplicity, ease of interpretation, and domain independence [5]. They usually have clear rules and transparent logic, making the results easy to trace and adjust. Furthermore, it has flexible adaptation, it can adapt to specific scenarios quickly by custom domain lexicon, so it has a strong ability to cover emotional expressions unique to the field. However, this makes the methods have weaknesses in cross-domain generalisation capability and limitations in lexicon coverage. Compared to the machine learning methods, the emotion lexicon methods can avoid the cost of data annotation and model training and have high computing efficiency and low resource consumption due to their often requiring less training data [11]. However, this method faces numerous weaknesses, it has a low upper limit of accuracy compared to machine and deep learning methods. Moreover, they can struggle with handling context-dependent emotion, where the meaning of a word can change based on its surrounding words [5]. It usually only supports coarse-grained emotion classification (positive, negative, neutral) but has difficulty supporting fine-grained emotion recognition (angry, sad) or emotion intensity quantification.
Traditional machine learning excels at learning complex patterns from data and typically achieves higher accuracy than lexicographic methods, especially on large datasets. Algorithms like Random Forest are fast, while SVMs excel at sentiment recognition. These methods provide strong interpretability through clear feature-result relationships, which helps in manual analysis and debugging. An advantage of machine learning over deep learning is that it requires less computational power and, as a result, can be used in scenarios where computational resources are limited. Additionally, they demonstrate a capacity to avoid overfitting on small datasets, which can be stabilised by regularisation and ensemble methods. However, they rely heavily on labelled data training and performing manual feature engineering for optimal performance. Furthermore, traditional machine learning has limited expressiveness for modelling nonlinear relationships and deep semantics, the modelling assumptions are relatively simple. Such approaches face challenges in dealing with long and complex texts, implicit emotions (irony, metaphor), and weak multilingual and cross-domain generalisation.
Deep learning models frequently do better than traditional machine learning methods in TEA tasks, particularly when large amounts of labelled data are available [7]. They excel at automatically learning relevant features from the data and can capture long-range dependencies in text, which can be crucial for understanding emotion in longer documents [7]. This removes the necessity for manual feature engineering and allows the models to capture subtle semantic and syntactic patterns, even in noisy data. Architectures such as LSTM and bidirectional Transformers excel at modelling long-range dependencies and contextual cues. This enables them to understand emotional nuances [5]. Deep learning approaches often achieve superior accuracy, precision, and recall on TEA benchmarks compared to traditional machine learning methods. Their non-linear modelling capability allows them to capture intricate patterns in large-scale datasets, improving overall performance. However, this method has limitations in terms of interpretability. Deep neural networks' complex, layered structure often makes them "black boxes" [12]. While they achieve high performance, understanding how they reach a particular decision remains challenging, which can hinder interpretability and trust in sensitive applications. Moreover, Deep learning models are susceptible to choices in hyperparameters and network architecture [12]. They are prone to overfitting without careful tuning and regularisation, especially when training data is insufficient or not representative, resulting in poor generalisation.
Hybrid methods in TEA significantly improve the performance of complex texts by integrating the interpretability and domain expertise of lexicon-based methods with the nuanced, context-aware capabilities of machine learning models. The machine learning models based on emotion-lexicon, particularly deep learning models like LSTM or CNN, can learn complex patterns and resolve ambiguities by considering broader context, thereby enhancing classification accuracy. When hybrid methods are applied, overall performance metrics obtain significant improvements and give full play to complementary advantages. While deep learning methods are highly effective in data dependency, they are also data-hungry. Compared to it, hybrid methods can alleviate the need for enormous annotated corpora by incorporating knowledge-based rules, making them more feasible in domains with limited labelled data. However, although hybrid systems can reduce data dependency, this method risks overfitting when training data are scarce [13]. Furthermore, combining disparate methods introduces additional layers of complexity. It is difficult to determine the optimal balance between rule-based and data-driven components. Integrating lexicon-based rules with machine learning models requires careful calibration, which can complicate model design and maintenance.
3.2. The current challenges and future research of TEA
As an essential field in Natural Language Processing, TEA plays an irreplaceable role in people's communication, decision-making, stock prediction, data training of large language models, etc. TEA has seen remarkable progress over the past decade, driven by advances in deep learning and transformer-based models. Despite these developments, many challenges remain. For instance, current systems often struggle with capturing subtle emotional nuances due to inherent ambiguity and contextual variability in text. Additionally, most approaches do not adequately account for the impact of cultural and demographic factors on emotional expression. There is also a persistent issue with data quality and scarcity, as large-scale annotated datasets can be inconsistent or incomplete. Moreover, many state-of-the-art models act as "black boxes" [12], which limit the ability to understand and trust their predictions. These challenges persist and shape the roadmap for future research.
A recent comprehensive review by Flor Miriam Plaza-del-Arco et al. examines 154 Neuro-Linguistic Programming (NLP) publications over the past decade, highlighting significant trends, current challenges, and future research directions in this field [14]. The study emphasises the need for more nuanced emotion modelling, improved datasets, and interdisciplinary approaches to advance the field. Future research should focus on developing models that integrate multidimensional emotion frameworks, capturing not only polarity but also arousal, dominance and intensity to improve contextual understanding [14]. Researchers are encouraged to incorporate demographic and cultural metadata, ensuring that models generalize across diverse linguistic contexts. Data augmentation and semi-supervised learning techniques also offer promising avenues to address the limitations of annotated datasets, enabling models to leverage vast amounts of unlabeled text to enhance performance [15]. Furthermore, by developing context-aware, culturally sensitive, and interpretable systems and integrating insights from multimodal approaches, future research can overcome existing limitations and expand the practical applications of TEA.
4. Conclusion
As an essential research field, TEA potentially contributes to marketing, public opinion monitoring, financial markets, healthcare, and other fields by utilizing emotion lexicon, machine learning, and hybrid methods to automatically identify and classify emotion in text for analysis. This study aims to provide a detailed summary and analysis of the basic and mainstream technical model of research in TEA and how researchers use it effectively. This review has provided a comprehensive overview of TEA, tracing its evolution from early lexicon-based methods to the current era dominated by deep learning and large language models. This paper describes emotion lexicon methods, traditional machine learning methods, deep learning methods and hybrid methods of TEA and its detailed structures and usage mode, providing their strengths and weaknesses. The review has also highlighted the significant challenges and open research questions that still need to be addressed in the field, including handling data quality and scarcity, understanding the subtle emotional nuances of context, performing multilingual emotion analysis, and addressing ethical considerations. In the future, summarising and organising the experience of predecessors and trying to solve the current challenges will be considered as the research objective for the next stage. The research will focus on improving and comparing the solutions to previous problems and solving the remaining difficulties by integrating the experience of the predecessors and the advanced techniques.
References
[1]. Seyeditabari, A., Tabari, N., & Zadrozny, W. (2018). Emotion Detection in Text: A Review. ArXiv print,674.
[2]. Tunca, S., Sezen, B., & Wilk, V. (2023). An exploratory content and sentiment analysis of the guardian metaverse articles using leximancer and natural language processing. Journal of Big Data, 10(1), 82.
[3]. Kaltenbrunner, A., & Gómez, V. (2021). Uncovering the Limits of Text-based Emotion Detection. ArXiv print,1900.
[4]. Deng, J., & Ren, F. (2021). A survey of textual emotion recognition and its challenges. IEEE Transactions on Affective Computing, 14(1), 49-67.
[5]. Nandwani, P., & Verma, R. (2021). A review on sentiment analysis and emotion detection from text. Social network analysis and mining, 11(1), 81.
[6]. Prakash, T. N., & Aloysius, A. (2021). Textual sentiment analysis using lexicon based approaches. Annals of the Romanian Society for Cell Biology, 25(4), 9878-9885.
[7]. Zhang, L., Wang, S., & Liu, B. (2018). Deep learning for sentiment analysis: A survey. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery, 8(4), e1253.
[8]. Wang, P., Zhou, Q., Wu, Y. (2024). DLF: Disentangled-Language-Focused Multimodal Sentiment Analysis. ArXiv print, 12225.
[9]. Etelis, I., Rosenfeld, A., Weinberg, A. I., & Sarne, D. (2024). Generating Effective Ensembles for Sentiment Analysis. ArXiv print:16700.
[10]. Igali, A., Abdrakhman, A., Torekhan, Y. (2024). Tracking Emotional Dynamics in Chat Conversations: A Hybrid Approach using DistilBERT and Emoji Sentiment Analysis. ArXiv print,1838.
[11]. Gunasekaran, K. P. (2023). Exploring Sentiment Analysis Techniques in Natural Language Processing: A Comprehensive Review. ArXiv print, 14842.
[12]. Jim, J. R., Talukder, M. A. R., Malakar, P. (2024). Recent advancements and challenges of NLP-based sentiment analysis: A state-of-the-art review. Natural Language Processing Journal, 6(100059), 2949-7191.
[13]. Li, Y., Chan, J., Peko, G., & Sundaram, D. (2023). Mixed emotion extraction analysis and visualisation of social media text. Data & Knowledge Engineering, 148(102220).
[14]. Miriam, F., Curry, A., Curry, A. C. (2024). Emotion Analysis in NLP: Trends, Gaps and Roadmap for Future Directions. ArXiv print, 1222.
[15]. Kusal, S., Patil, S., Choudrie, J. (2022). A Review on Text-Based Emotion Detection -- Techniques, Applications, Datasets, and Future Directions. ArXiv print, 3235.
Cite this article
Miao,P. (2025). Analysis of the Technologies and Methods of Textual Emotion Analysis. Applied and Computational Engineering,162,112-121.
Data availability
The datasets used and/or analyzed during the current study will be available from the authors upon reasonable request.
Disclaimer/Publisher's Note
The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of EWA Publishing and/or the editor(s). EWA Publishing and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content.
About volume
Volume title: Proceedings of CONF-FMCE 2025 Symposium: Semantic Communication for Media Compression and Transmission
© 2024 by the author(s). Licensee EWA Publishing, Oxford, UK. This article is an open access article distributed under the terms and
conditions of the Creative Commons Attribution (CC BY) license. Authors who
publish this series agree to the following terms:
1. Authors retain copyright and grant the series right of first publication with the work simultaneously licensed under a Creative Commons
Attribution License that allows others to share the work with an acknowledgment of the work's authorship and initial publication in this
series.
2. Authors are able to enter into separate, additional contractual arrangements for the non-exclusive distribution of the series's published
version of the work (e.g., post it to an institutional repository or publish it in a book), with an acknowledgment of its initial
publication in this series.
3. Authors are permitted and encouraged to post their work online (e.g., in institutional repositories or on their website) prior to and
during the submission process, as it can lead to productive exchanges, as well as earlier and greater citation of published work (See
Open access policy for details).
References
[1]. Seyeditabari, A., Tabari, N., & Zadrozny, W. (2018). Emotion Detection in Text: A Review. ArXiv print,674.
[2]. Tunca, S., Sezen, B., & Wilk, V. (2023). An exploratory content and sentiment analysis of the guardian metaverse articles using leximancer and natural language processing. Journal of Big Data, 10(1), 82.
[3]. Kaltenbrunner, A., & Gómez, V. (2021). Uncovering the Limits of Text-based Emotion Detection. ArXiv print,1900.
[4]. Deng, J., & Ren, F. (2021). A survey of textual emotion recognition and its challenges. IEEE Transactions on Affective Computing, 14(1), 49-67.
[5]. Nandwani, P., & Verma, R. (2021). A review on sentiment analysis and emotion detection from text. Social network analysis and mining, 11(1), 81.
[6]. Prakash, T. N., & Aloysius, A. (2021). Textual sentiment analysis using lexicon based approaches. Annals of the Romanian Society for Cell Biology, 25(4), 9878-9885.
[7]. Zhang, L., Wang, S., & Liu, B. (2018). Deep learning for sentiment analysis: A survey. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery, 8(4), e1253.
[8]. Wang, P., Zhou, Q., Wu, Y. (2024). DLF: Disentangled-Language-Focused Multimodal Sentiment Analysis. ArXiv print, 12225.
[9]. Etelis, I., Rosenfeld, A., Weinberg, A. I., & Sarne, D. (2024). Generating Effective Ensembles for Sentiment Analysis. ArXiv print:16700.
[10]. Igali, A., Abdrakhman, A., Torekhan, Y. (2024). Tracking Emotional Dynamics in Chat Conversations: A Hybrid Approach using DistilBERT and Emoji Sentiment Analysis. ArXiv print,1838.
[11]. Gunasekaran, K. P. (2023). Exploring Sentiment Analysis Techniques in Natural Language Processing: A Comprehensive Review. ArXiv print, 14842.
[12]. Jim, J. R., Talukder, M. A. R., Malakar, P. (2024). Recent advancements and challenges of NLP-based sentiment analysis: A state-of-the-art review. Natural Language Processing Journal, 6(100059), 2949-7191.
[13]. Li, Y., Chan, J., Peko, G., & Sundaram, D. (2023). Mixed emotion extraction analysis and visualisation of social media text. Data & Knowledge Engineering, 148(102220).
[14]. Miriam, F., Curry, A., Curry, A. C. (2024). Emotion Analysis in NLP: Trends, Gaps and Roadmap for Future Directions. ArXiv print, 1222.
[15]. Kusal, S., Patil, S., Choudrie, J. (2022). A Review on Text-Based Emotion Detection -- Techniques, Applications, Datasets, and Future Directions. ArXiv print, 3235.