


Volume 185
Published on May 2025Volume title: Proceedings of ICEMGD 2025 symposium: Innovating in Management and Economic Development
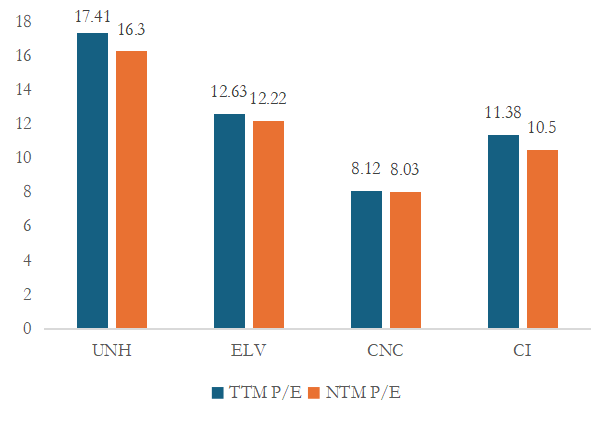
Under the background of intensifying competition in the health insurance industry, it is of great significance to analyze the financial status and development potential of enterprises for investors to make decisions. This paper takes the four major American Health insurance companies (UnitedHealth Group, Centene Corporation, Elevance Health Corporation and Cigna Group) as the research object. The purpose of financial index analysis (profitability, growth ability, valuation level) is to evaluate the competitive potential of enterprises and provide basis for investment decisions. CI achieves high growth through refined cost control and business expansion, while UNH is slowing down due to diminishing marginal effects of scale, and other companies (such as CNC) have potential investment opportunities due to low valuations. Investors should prioritize Cigna Group (CI) because of its high profitability, strong growth and low valuation with long-term return potential, while keeping an eye on industry policy changes and market volatility risks. There is still some room for improvement in this study, which needs to be improved gradually in the follow-up work.


