







1. Introduction
Against intensifying climate change and planetary pressure to make green transitions at the national level, national fiscal instruments in the form of carbon taxes, green subsidies, and public investments are being increasingly utilized to meet climate targets. These policies, however, create unintended transboundary fiscal spillover effects that unsettle macroeconomic stability and fiscal space of other nations through trade linkages, capital flows, and regulatory arbitrage [1]. These produce sophisticated interdependencies that confront traditional macroeconomic coordination in conventional terms. Classic macroeconomic frameworks of Dynamic Stochastic General Equilibrium (DSGE) or enlarged IS-LM structures do offer partial understanding of cross-border policy interactions, yet their rigidity, equilibrium bent, and static presumptions make them inadequate to embrace adaptive, nonlinear, high-dimensional fiscal dynamics in the real world. On the other hand, new breakthroughs in artificial intelligence, specifically Graph Neural Networks (GNNs) and Deep Reinforcement Learning (DRL) have created new openings for modeling and management of these phenomena. GNNs can effectively embed inter-country fiscal interdependencies while DRL can facilitate autonomous agents to discover optimal counterstrategies through experimentation in complex dynamical environments. Through these methods in combination, this work advocates an adaptive policy response generation framework customized to climate fiscal spillovers [2]. The model emulates national behavior in multi-agent policy regimes and generates countermeasures dynamically in a contextually aware and forward-thinking manner. By employing IMF and OECD fiscal data in an empirical setting, we create a cross-national fiscal influence network and compare the model's performance in carbon tax spillover and green subsidy rivalry scenarios. These findings support a learning-oriented paradigm for international macroeconomic policy coordination and deliver strong and scalable instruments for intelligent climate policy management.
2. Literature review
2.1. Fiscal climate spillover dynamics
Climate fiscal instruments like carbon prices and green subsidies typically produce international spillover impacts through shaping international trade prices, carbon leakages, and relocation of industries. Literature reveals that these instruments produce distributional effects among nations with direct burdens inflicted mostly on developing nations with low fiscal capacity [3]. Empirical methods mostly use panel regressions of data, spatial econometrics, and structural frameworks in an endeavor to measure direct and indirect transmission links. These frameworks usually neglect institutional differences and policy feedbacks that evolve over time. Other studies further venture into competitive subsidy games and carbon border taxation schemes with findings that recognize how unchecked fiscal measures stimulate retaliatory or distortionary impacts in international economies [4].
2.2. Macroeconomic coordination models
Traditional models of Mundell-Fleming and DSGE have been extensively utilized for the simulation of international policy spillovers but suffer from limitations of rational agents, symmetric institutions, andstatic structures, reducing their practical relevance in reality [5]. Recent research introduces heterogeneous agents, dynamical systems, and network representations to make models more adaptable. These typically rely upon rule-based behavior and static settings and therefore become less appropriate for environments with unknown policy shocks or dynamically changing interdependencies [6]. Game-theoretic upgrades do account for certain kinds of strategic behavior but fail to deal with high-dimensional problems of coordination in various macroeconomic systems.
2.3. Artificial intelligence in policy modeling
Graph neural networks and reinforcement learning have been explored for fiscal allocation, monetary policy simulation, and regulatory design with significant potential in simulating high-dimensional decision environments [7]. GNNs are particularly effective in conveying cross-country fiscal dependencies and network structures that change dynamically. Most existing applications are for single-country applications or static simulations with omission of feedback and inter-agent strategy development. Implementation of institutional rules, policy interpretability, and cross-level governance constraints remains a principal technical barrier to applying AI models in real macroeconomic policymaking [8].
3. Methodology
3.1. Architecture design
To address the complex interdependencies arising from international climate fiscal policy spillovers, we construct a hybrid framework that integrates Graph Neural Networks (GNNs) and Deep Reinforcement Learning (DRL). The model comprises two core components, a GNN module that captures the structural relations among countries’ fiscal policy profiles, and a DRL agent that learns optimal adaptive countermeasures [9]. Each country is modeled as a node vi∈V in a weighted policy network G=(V,E,A), where A∈RN×N is the adjacency matrix capturing fiscal dependencies. Node embeddings are updated through graph convolution as:
Where
These embeddings are used to augment the state representation st for the DRL agent. We adopt an Actor-Critic structure, where the policy network πθ(at∣st) outputs fiscal responses and the value network Vπ(st) estimates future rewards. The policy is updated using an advantage-weighted objective:
This architecture allows the agent to internalize topological structures of fiscal influence while learning context-sensitive countermeasures under varying spillover conditions.
3.2. Dataset and variable construction
The training dataset integrates quarterly fiscal indicators from the IMF Government Finance Statistics and the OECD Climate Finance Database, covering 38 countries between 2010 and 2023. Each country is encoded as a node, and edges represent fiscal interdependencies based on carbon tax rate, green expenditure share, and GDP elasticity [10]. These continuous variables are normalized and transformed into adjacency weights as:
Where α is a scaling hyperparameter, and xi,xj represent fiscal policy vectors.
The action space At includes carbon tax adjustments and shifts in green spending levels. Rewards are computed to incentivize coordinated, stable, and effective policy responses. The reward function is defined as:
Each term is computed from internal model diagnostics. Spillover cost is estimated via neighboring volatility propagation, while coordination score quantifies policy convergence across nodes in the network.
3.3. Training mechanism and evaluation metrics
Training is conducted using the Proximal Policy Optimization (PPO) algorithm, chosen for its stability in high-dimensional policy environments and its robustness against overfitting [11]. The clipped objective function ensures conservative updates:
Where rt(θ)=πθold(at∣st)πθ(at∣st) is the probability ratio between new and old policies, and ϵ is a clipping threshold to limit policy divergence.
Model performance is evaluated using three core metrics. Mean Adaptive Coordination Error (MACE), System Stability Rate (SSR), and Robustness Enhancement Score (RES). MACE quantifies the deviation between the agent’s output and the optimal baseline policy derived from full information scenarios:
Where
4. Results
4.1. Policy response performance
In this paper, we construct a simulation experiment platform containing 38 countries and 12 years of quarterly data, and compare and analyze the response performance of the intelligences in five types of typical shock scenarios (carbon tax hike, green subsidy spillovers, emission shifts, exchange rate perturbations, and fiscal deficit fluctuations), as shown in Table 1.
Among them, the coordination score in the green subsidy spillover scenario reaches 0.87, which is significantly better than the carbon tax shock scenario (0.74). And the fastest strategy convergence is found in the emission transfer scenario, which takes only 9.3 steps on average. The system steady state retention rate is maintained above 85% in all scenarios, indicating that the strategies generated by the intelligentsia have good system control ability and structural adaptability.
|
Scenario Type |
Coordination Score |
Stability Rate (%) |
Convergence Steps |
|
Carbon Tax Hike |
0.74 |
86.1 |
12.7 |
|
Green Subsidy Spillover |
0.87 |
88.9 |
10.5 |
|
Emissions Leakage |
0.81 |
87.6 |
9.3 |
|
Exchange Rate Volatility |
0.76 |
85.3 |
11.9 |
|
Fiscal Deficit Shock |
0.79 |
86.7 |
13.1 |
4.2. Comparative analysis with baseline models
To validate the effectiveness of the proposed GNN-DRL hybrid model, systematic comparisons are made with four baseline models, including the traditional dynamic stochastic general equilibrium (DSGE) model, deep Q-network (DQN), graph-only neural network model (GNN-only), and the stochastic policy benchmark. The performance is evaluated using the three core metrics under the same experimental setup, as shown in Figure 1. The experimental results show that the GNN-DRL model achieves 0.163 on the MACE metric, which is 52.3% lower than the 0.342 of the DSGE model and 43.2% lower than the 0.287 of the DQN. In terms of system stabilization rate, this paper's model reaches 87.2%, which is significantly better than DSGE's 71.8% and pure GNN's 78.4%. When dealing with complex multi-country fiscal policy interactions, the average convergence time of the GNN-DRL model is 11.1 steps, while the traditional DSGE model requires 23.7 steps to reach a stable solution. Robustness tests show that the RES score of this paper's model is 0.834 in the face of uncertainty shocks, which far exceeds that of other baseline models, demonstrating the unique advantage of graph neural networks in capturing international fiscal dependencies.
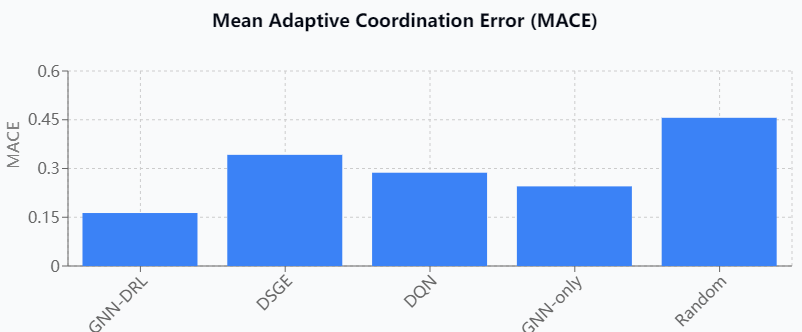
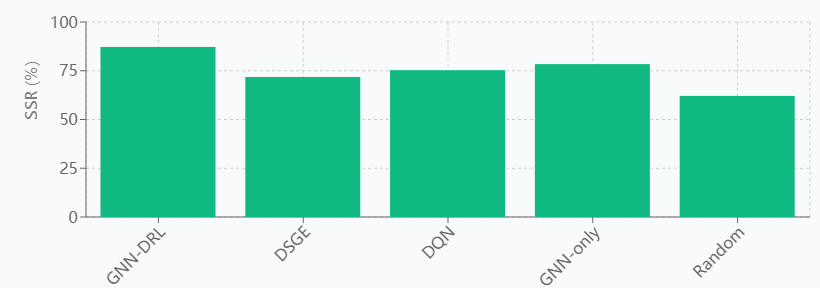
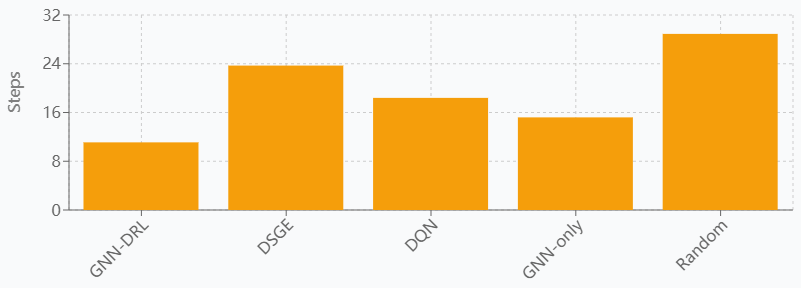
Figure 1. Performance comparison analysis between GNN-DRL model and baseline models
5. Conclusion
The study successfully constructs a hybrid modeling framework based on graph neural networks and deep reinforcement learning, which effectively solves the complex coordination challenges posed by global climate fiscal policy spillovers. Experimental results show that the model significantly outperforms baseline approaches such as traditional dynamic stochastic general equilibrium models, deep Q-networks, and pure graph neural networks in key metrics such as average adaptive coordination error, system stability rate, and convergence efficiency, and it especially demonstrates excellent performance in dealing with complexity and uncertainty of multi-country fiscal policy interactions. Validated by simulations with 12 years of quarterly data from 38 countries, the model maintains good system control and structural adaptability under five typical shock scenarios, proving the great potential of AI technology in international macroeconomic policy coordination. This study not only provides an innovative theoretical framework and practical tools for intelligent climate policy governance, but also opens up new directions for future research on learning-based international economic coordination mechanisms.
References
[1]. Yang, Tianpei, et al. "A transfer approach using graph neural networks in deep reinforcement learning." Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 38. No. 15. 2024.
[2]. Tam, Prohim, et al. "A survey of intelligent end-to-end networking solutions: Integrating graph neural networks and deep reinforcement learning approaches." Electronics 13.5 (2024): 994.
[3]. Bekri, Malek, Ronald Romero Reyes, and Thomas Bauschert. "Robust Restoration of IP Traffic from Optical Failures by Deep Reinforcement Learning and Graph Neural Networks." 2024 24th International Conference on Transparent Optical Networks (ICTON). IEEE, 2024.
[4]. Zhao, Jianyu, and Chenyang Yang. "Graph Reinforcement Learning for Radio Resource Allocation." arXiv preprint arXiv: 2203.03906 (2022).
[5]. Mu, Tongzhou, et al. "Learning two-step hybrid policy for graph-based interpretable reinforcement learning." arXiv preprint arXiv: 2201.08520 (2022).
[6]. Randall, Martín, et al. "Deep reinforcement learning and graph neural networks for efficient resource allocation in 5g networks." 2022 IEEE Latin-American Conference on Communications (LATINCOM). IEEE, 2022.
[7]. Gammelli, Daniele, et al. "Graph neural network reinforcement learning for autonomous mobility-on-demand systems." 2021 60th IEEE Conference on Decision and Control (CDC). IEEE, 2021.
[8]. Ding, Xiaosong, Hu Liu, and Xi Chen. "Deep Reinforcement Learning for Solving Multi-period Routing Problem with Binary Driver-customer Familiarity." Proceedings of the 2023 5th International Conference on Internet of Things, Automation and Artificial Intelligence. 2023.
[9]. Kim, Juhyeon, and Kihyun Kim. "Optimizing large-scale fleet management on a road network using multi-agent deep reinforcement learning with graph neural network." 2021 IEEE International Intelligent Transportation Systems Conference (ITSC). IEEE, 2021.
[10]. Amorosa, Lorenzo Mario, et al. "Multi-Agent Reinforcement Learning for Power Control in Wireless Networks via Adaptive Graphs." ICC 2024-IEEE International Conference on Communications. IEEE, 2024.
[11]. Ajagekar, Akshay, and Fengqi You. "Deep reinforcement learning based automatic control in semi-closed greenhouse systems." IFAC-PapersOnLine 55.7 (2022): 406-411
Cite this article
Ou,Y. (2025). Adaptive Countermeasure Generation for Climate Fiscal Policy Spillovers Using Deep Reinforcement Learning and Graph Neural Networks. Theoretical and Natural Science,130,25-31.
Data availability
The datasets used and/or analyzed during the current study will be available from the authors upon reasonable request.
Disclaimer/Publisher's Note
The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of EWA Publishing and/or the editor(s). EWA Publishing and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content.
About volume
Volume title: The 3rd International Conference on Applied Physics and Mathematical Modeling
© 2024 by the author(s). Licensee EWA Publishing, Oxford, UK. This article is an open access article distributed under the terms and
conditions of the Creative Commons Attribution (CC BY) license. Authors who
publish this series agree to the following terms:
1. Authors retain copyright and grant the series right of first publication with the work simultaneously licensed under a Creative Commons
Attribution License that allows others to share the work with an acknowledgment of the work's authorship and initial publication in this
series.
2. Authors are able to enter into separate, additional contractual arrangements for the non-exclusive distribution of the series's published
version of the work (e.g., post it to an institutional repository or publish it in a book), with an acknowledgment of its initial
publication in this series.
3. Authors are permitted and encouraged to post their work online (e.g., in institutional repositories or on their website) prior to and
during the submission process, as it can lead to productive exchanges, as well as earlier and greater citation of published work (See
Open access policy for details).
References
[1]. Yang, Tianpei, et al. "A transfer approach using graph neural networks in deep reinforcement learning." Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 38. No. 15. 2024.
[2]. Tam, Prohim, et al. "A survey of intelligent end-to-end networking solutions: Integrating graph neural networks and deep reinforcement learning approaches." Electronics 13.5 (2024): 994.
[3]. Bekri, Malek, Ronald Romero Reyes, and Thomas Bauschert. "Robust Restoration of IP Traffic from Optical Failures by Deep Reinforcement Learning and Graph Neural Networks." 2024 24th International Conference on Transparent Optical Networks (ICTON). IEEE, 2024.
[4]. Zhao, Jianyu, and Chenyang Yang. "Graph Reinforcement Learning for Radio Resource Allocation." arXiv preprint arXiv: 2203.03906 (2022).
[5]. Mu, Tongzhou, et al. "Learning two-step hybrid policy for graph-based interpretable reinforcement learning." arXiv preprint arXiv: 2201.08520 (2022).
[6]. Randall, Martín, et al. "Deep reinforcement learning and graph neural networks for efficient resource allocation in 5g networks." 2022 IEEE Latin-American Conference on Communications (LATINCOM). IEEE, 2022.
[7]. Gammelli, Daniele, et al. "Graph neural network reinforcement learning for autonomous mobility-on-demand systems." 2021 60th IEEE Conference on Decision and Control (CDC). IEEE, 2021.
[8]. Ding, Xiaosong, Hu Liu, and Xi Chen. "Deep Reinforcement Learning for Solving Multi-period Routing Problem with Binary Driver-customer Familiarity." Proceedings of the 2023 5th International Conference on Internet of Things, Automation and Artificial Intelligence. 2023.
[9]. Kim, Juhyeon, and Kihyun Kim. "Optimizing large-scale fleet management on a road network using multi-agent deep reinforcement learning with graph neural network." 2021 IEEE International Intelligent Transportation Systems Conference (ITSC). IEEE, 2021.
[10]. Amorosa, Lorenzo Mario, et al. "Multi-Agent Reinforcement Learning for Power Control in Wireless Networks via Adaptive Graphs." ICC 2024-IEEE International Conference on Communications. IEEE, 2024.
[11]. Ajagekar, Akshay, and Fengqi You. "Deep reinforcement learning based automatic control in semi-closed greenhouse systems." IFAC-PapersOnLine 55.7 (2022): 406-411