


Volume 211
Published on December 2025Volume title: Proceedings of CONF-SPML 2026 Symposium: The 2nd Neural Computing and Applications Workshop 2025

With the rapid development of technology, the collaborative advancement of artificial intelligence and robotics is reshaping the global landscape and making significant, continuous changes to people's lives. The development of artificial intelligence has led to major breakthroughs in the field of robotics. This paper focuses on the progress in various daily application scenarios, such as industrial automation, medical surgery, service robots, and driverless vehicles. At the same time, it explores the current technical bottlenecks, including the integration of the two technologies, the autonomous learning of artificial intelligence, the key to technological breakthroughs, and the safety of robots under artificial intelligence. Finally, based on the trend of technological development and social needs, this paper further looks forward to future development directions, including the application of general artificial intelligence in robots, the development of human-robot interaction, the cooperation and communication of swarm robots, and the construction of an ethical governance framework. These explorations not only provide theoretical support for the academic community but also offer forward-looking references for the industrial sector and policymakers.




With the application of deep learning technology in the field of autonomous driving, convolutional neural networks, as the core technology of autonomous driving visual recognition tasks, have played a significant role in traffic sign recognition. VGG19 and MobileNetV2 have attracted widespread attention due to their high precision and efficiency. However, most of the existing studies focus on optimizing model accuracy, ignoring the security risks that models face when confronted with adversarial attacks in real autonomous driving scenarios. Therefore, in this study, the speed limit 30 label and speed limit 60 label of the German Traffic Sign Recognition Benchmark (GTSRB) dataset were used as the model training datasets. After data preprocessing, adversarial samples were generated using the FGSM algorithm. Observe the changes in the model's recognition confidence and comparatively study the robustness of the model under adversarial attacks. Finally, it was found that the robustness of VGG19 against FGSM adversarial attacks was significantly better than that of MobileNetV2. The significance of this study lies in filling the gap in the comparison of model robustness under adversarial attacks in the field of autonomous driving, providing a basis and reference for future model selection and safe deployment.
With the widespread application of machine learning, particularly deep learning models, in the field of cybersecurity, the intelligence of spam filtering systems has been continuously enhanced. Deep learning classifiers, with their advantages such as character-level feature learning and semantic invariance, have become the preferred choice for deployment. However, these models rely on surface text features, making them vulnerable to adversarial attacks. As a result, they exhibit significant vulnerability when facing carefully constructed text adversarial attacks. Text adversarial attacks, through covert modifications such as synonym substitution and character perturbation, can mislead the model to misjudge malicious emails, leading to risky spam emails such as phishing and fraud passing through the defense system. This study first elaborates on three attack methods, namely character-level attack, word-level attack, and sentence-level attack. Secondly, it introduces the existing limitations of spam email attacks and then this study comprehensively reviews the key findings in the existing research results: deep learning models generally have a high attack success rate (ASR). The aim is to provide a theoretical basis for building a more robust next-generation spam email filtering system.
Large-scale language models (LLMs) have a huge scale, but they have encountered difficulties in improving social productivity, mainly due to their high cost and increasing demand for a large number of computing resources. Knowledge refining plays a key role in bridging the gap between model performance and operational efficiency, and also strengthens these two aspects. This technology refines the functions of GPT-3.5 and other models into miniature models that can be run locally at controllable cost. It can not only enable small and medium-sized enterprises and research institutions to use high-performance large-scale language models, but also ensure data security. Classical knowledge extraction framework uses label softening to achieve knowledge transfer between teacher and student models. According to the logical steps of teacher-student model alignment (similar to GPT-4), this paper mainly focuses on making the student model learn from the teacher model adaptively. This method enables the student model to get a compact model quickly, which not only absorbs the fine knowledge of the teacher model, but also reduces the consumption of computing resources and data. The existing CoT distillation methods ignore the variability of samples and the learning dynamics of student models. In this paper, an adaptive chain distillation method is proposed, so that small models can avoid the problem of reasoning sensitivity and focus on learning difficult samples. Although this will weaken its ability to analyze complex problems, we introduce an adaptive reasoning mechanism including soft prompt fine-tuning module and do experiments to verify it.
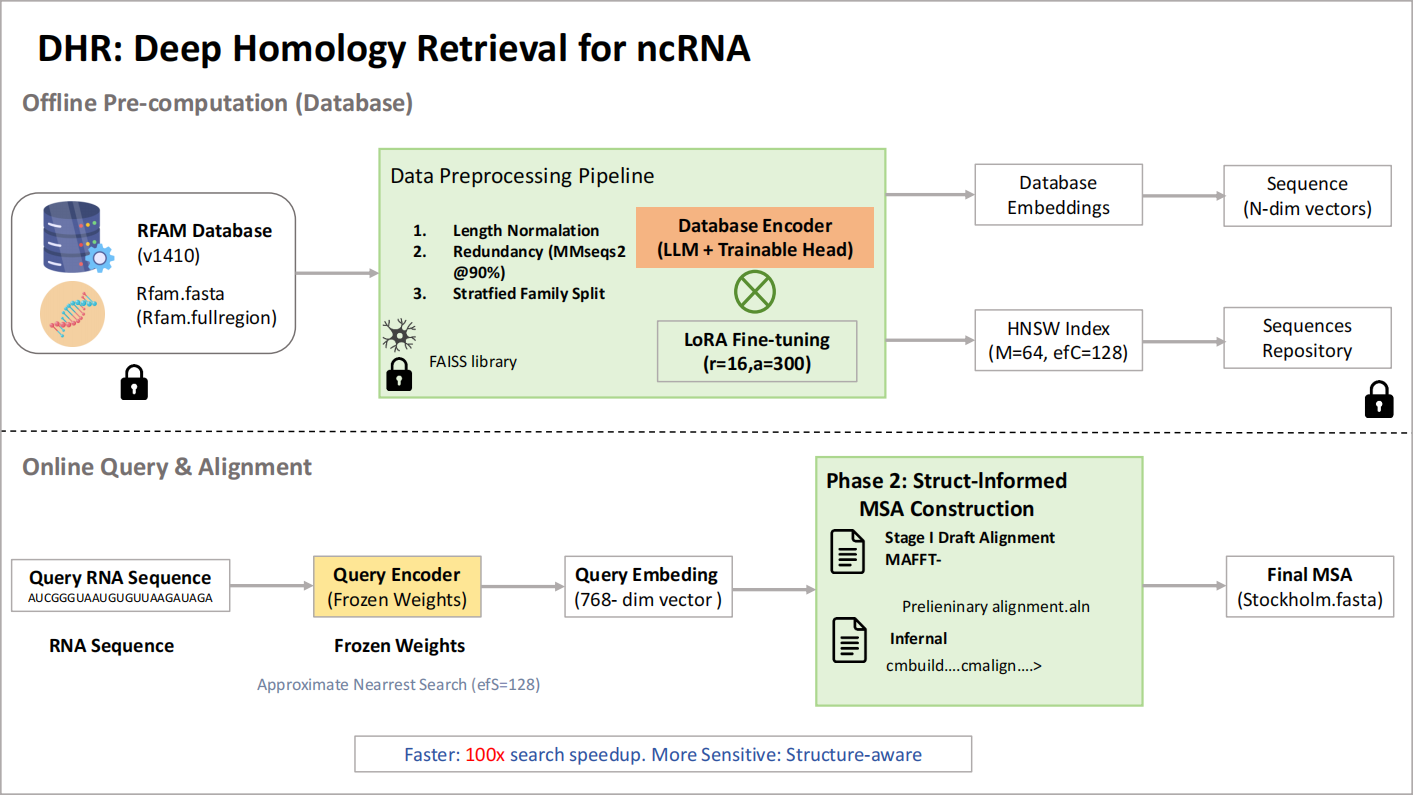
RNA’s growing therapeutic impact demands fast, structure-aware comparative analysis. Existing search tools trade speed for sensitivity: sequence-only methods are rapid but miss distant, structure-conserved homologs, whereas covariance-model pipelines are accurate but slow. We present a two-stage framework that reframes RNA homology detection as geometric retrieval in a learned embedding space, followed by structure-aware multiple sequence alignment (MSA). A frozen RNA foundation model (Rinalmo) embeds sequences; a lightweight Transformer head trained with supervised contrastive learning (family-balanced sampling, clan-aware hard negatives) sculpts the space so homologs cluster and non-homologs separate. Approximate nearest-neighbor search (FAISS/HNSW) enables sub-linear retrieval from millions of sequences. Top-khits are then aligned via a hybrid pipeline—MAFFT X-INS-i seeding and Infernal covariance-model refinement—to produce structure-consistent MSAs. On a family-level split of Rfam v14.10, Our method answers a query in 0.45 s on average (∼20×faster than BLASTn;>3,500×faster than cmscan) while achieving 0.95 precision, 0.93 recall, and 0.94 F1. Using retrieved sets, the MAFFT→Infernal workflow attains SPS = 0.91 versus 0.68 for BLASTn-based sets, enabling scalable, sensitive RNA homology discovery and downstream analysis.
The fast growth of wireless communication means we need to send data reliably, even with noise and interference, which therefore makes channel coding indispensable. This paper looks at three landmark schemes that shaped modern wireless communications: Turbo codes, Low-Density Parity-Check (LDPC) codes, and Polar codes. Specifically, it explains the basic ideas of channel coding, and it discusses methods to approach the Shannon limit. After that, this paper describes the structure and decoding steps for each code. Turbo codes use parallel concatenation and iterative decoding. LDPC codes need sparse parity-check matrices and belief propagation. Also, Polar codes get reliability using channel polarization. Moreover, the codes are also compared based on their error performance, how complex they are to decode, the delay they introduce, and whether they are used in standards. The results reveal that Turbo codes work best for medium to long blocks but have problems with delay and error floors. LDPC codes perform well with long blocks and high throughput. Polar codes are useful for short blocks, even though they are harder to decode. This comparison shows that the codes complement each other and suggests that adaptive, AI-assisted coding could be a promising approach for 6G.