







1.Introduction
The rapid development of technology in various sectors of society has laid a solid foundation for breakthroughs in the fields of natural language processing and knowledge graphs, while also providing new methods for language teaching. The research on Chinese spoken language teaching assessment algorithms and models aims to design effective algorithms and models for assessing Chinese spoken language teaching by integrating natural language processing and knowledge graphs, thereby improving the quality of teaching and assessment.
This study includes the construction of natural language processing algorithms suitable for Chinese spoken language, integrating principles of linguistics, psychology, and education into the knowledge graph to promote learners’ oral performance and progress. The core innovation lies in combining natural language processing with knowledge graphs to enable the system to understand language more deeply, facilitating the use and learning by learners, and further achieving personalized teaching. The model design can dynamically adapt to learners’ progress, provide immediate feedback, and optimize teaching methods and learning processes. This approach not only enhances the efficiency of Chinese teaching but also offers new perspectives and tools for the teaching of other languages.
2.Related Work
Numerous scholars have conducted research related to natural language processing. For example, Li Xueqing discovered natural language generation technology through his research, utilizing artificial intelligence and linguistic methods to automatically generate understandable natural language texts [1]. Zhao Jingsheng further mentioned in his study that natural language processing is a core technology of artificial intelligence, with text representation being its foundational work, crucial for the quality and performance of processing systems [2]. Expert in knowledge graph research, ZHANG Ningyu, found through research that knowledge graph completion can make the knowledge graph more comprehensive [3].
Regarding knowledge graphs, Jiang Yi more clearly stated that as a graph-based structured knowledge representation method, knowledge graphs focus on how to construct large-scale, high-quality knowledge graphs [4]. Moreover, JI Lei emphasized the wide application of knowledge graphs in new data semantic analysis models, noting that the demand for data security is continually increasing [5]. FU Feife’s research was more targeted. He discovered through his research that text recognition is a universal image understanding technology, significant for applications such as information retrieval, license plate recognition, and autonomous driving [6]. Finally, YAN J Z found that text recognition is a challenging research direction but holds important application value [7].
Through the research findings of these scholars, it is not difficult to see that the application of natural language generation technology, the core nature of text representation, and the construction and completion of knowledge graphs have made significant progress in advancing the fields of artificial intelligence and language processing, providing strong support for multiple domains such as data semantic analysis and information retrieval.
3.Chinese Spoken Language Teaching Assessment System Based on Natural Language Processing and Knowledge Graphs
3.1.Advantages of the Knowledge Graph in Chinese Spoken Language Teaching Systems
Knowledge graphs, an important research topic in knowledge graph construction, natural language processing, and knowledge engineering fields [8], are semantic network technologies that help organize and express knowledge. With the development of globalization, translation, as a bridge for language communication, has become increasingly important in cross-cultural exchanges and international cooperation. Knowledge graphs include the integration and analysis of linguistic resources. In translation teaching, professional terminology and knowledge in different fields are crucial factors. To build multilingual knowledge graphs, multilingual control efforts are required. In translation, cultural differences and idiomatic expressions of countries and regions are very important. Therefore, to better assist students in understanding and translating culturally related content, knowledge graphs must contain culturally relevant information. The construction of knowledge graphs can also integrate translation cases and experiences, distill best practices and experiences in translation, and provide practical advice to students. To enhance the efficiency and quality of translation teaching, modern technologies such as artificial intelligence and natural language processing can be widely applied.
On the other hand, the automatic retrieval and translation of terminology promote accurate and fluid translation. The extraction and translation of terminology are important steps in the translation process. Knowledge graphs can automate this process, improving the efficiency and accuracy of translation. By constructing domain-specific knowledge graphs, it is possible to automatically extract terms contained in texts and provide corresponding translations. This is very convenient for translation work in specific fields such as medicine, law, and technology.
In recent years, the natural language processing capabilities of large language models have continuously improved [9]. However, the application of natural language processing and knowledge graphs in the design of Chinese spoken language teaching assessment algorithms and models requires consideration of multiple aspects. Firstly, it is necessary to choose technologies that can deeply understand the linguistic characteristics of Chinese, including different accents and tones in spoken Chinese. Secondly, knowledge graphs are indispensable in this process; they can store and organize a vast array of language learning resources and help users better understand students’ language use, thereby providing customized learning suggestions and feedback based on the specific needs of students.
Natural language processing is a cutting-edge research area[10]. Theoretically, the study of natural language processing and knowledge graphs in the design of Chinese spoken language teaching assessment algorithms and models needs to integrate theories and methods from linguistics, computer science, artificial intelligence, and education. Ensuring data security and privacy protection is also an essential aspect of the model design. Moreover, the model must also consider the relevance of Chinese culture and actual language contexts, ensuring the accuracy and authority of the teaching content.
These are merely theoretical foundations; the specific situation of the system can only be reflected in actual use. A comparative analysis of mainstream knowledge graphs in Chinese spoken language teaching assessment systems is conducted, along with a comparative analysis of the support rates of various algorithms in Chinese spoken language assessment over the past few years.
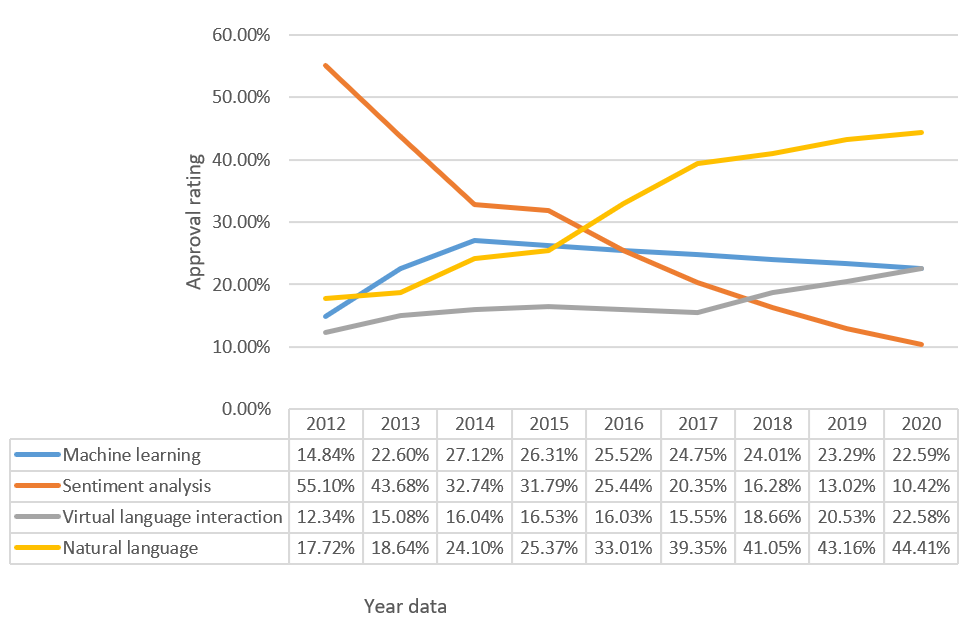
Figure 1. Support Rates of Mainstream Systems
According to the data in Figure 1, the support rates of machine learning systems, sentiment analysis systems, virtual language interaction systems, and natural language processing systems fluctuate significantly overall. The overall trend for machine learning and sentiment analysis in Chinese spoken language teaching assessment systems is declining, while virtual language interaction and natural language processing in Chinese spoken language teaching assessment systems are on the rise, with natural language processing experiencing the fastest increase in support rate.
3.2.System Model
Traditional text recognition methods rarely consider the integrity of scene vocabulary semantics, producing meaningless results when the input text images are severely deformed or under complex lighting conditions [11]. Therefore, the top priority in designing the system framework is the accuracy of user usage. Next, the smoothness of information flow is a particularly important aspect to consider. It is necessary to clearly convey the information process through graphical elements, from voice input to speech-to-text conversion, then to sentiment analysis and personalized learning paths, ensuring information fluidity and avoiding confusion for users.
In the open environment, pattern recognition and text recognition applications are constantly faced with new data, patterns, and categories, requiring algorithms capable of handling new category patterns [12]. A key emphasis in design that cannot be overlooked is ensuring the prominence of the connection between natural language processing and knowledge graphs, language models, and assessment modules in the design. These are the main components of the system, where the connection of knowledge graphs uses internet cloud data. Moreover, word vectors are one of the basic elements in most natural language processing tasks [13]. Combining these features forms the system model, as shown in Figure 2.
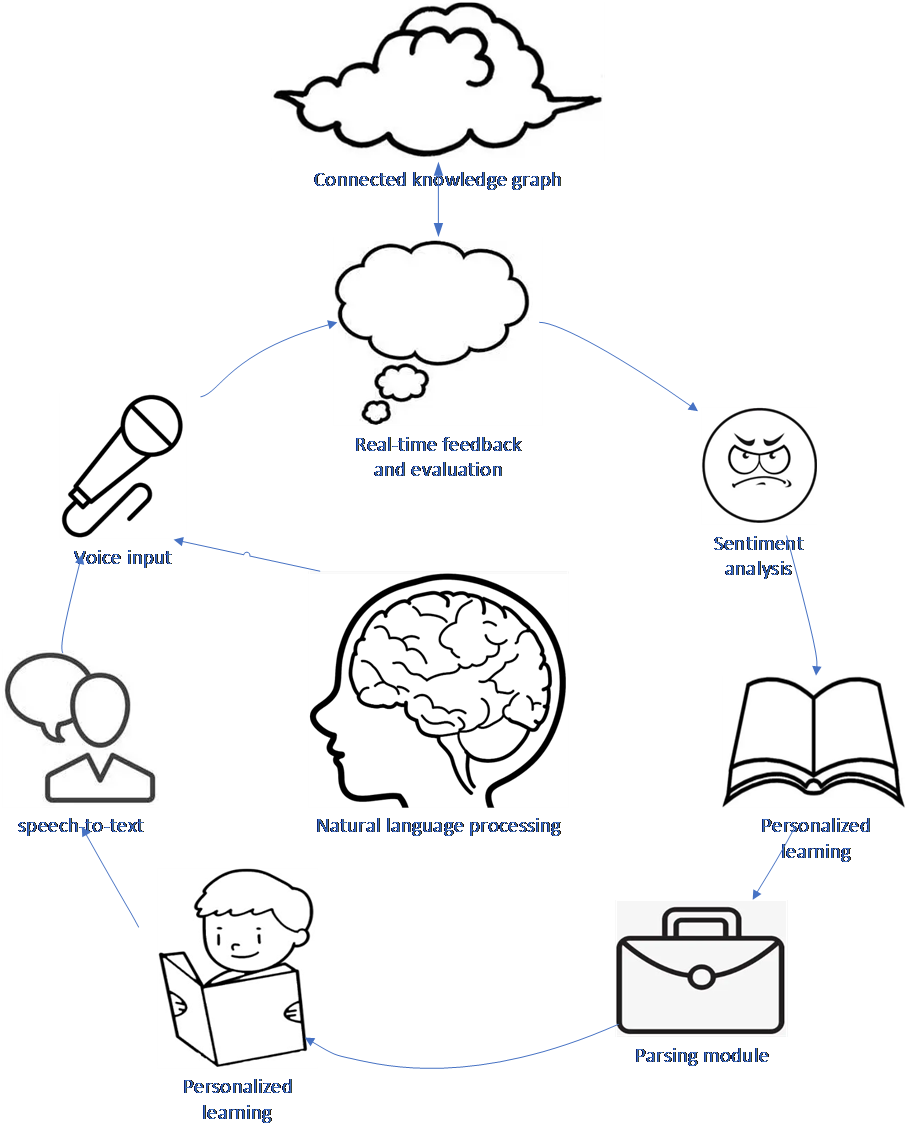
Figure 2. System Framework
The real-time feedback and evaluation modules within the system framework of Figure 2 can provide users with instant evaluation and feedback functions, thereby improving user experience. The framework of Figure 2 can ensure to some extent that the system’s design meets user expectations and effectively conveys the working principle of the system.
An important part of the system framework is text recognition, which involves text classification. Through text recognition, the system can process texts more accurately, as calculated by Equation (1)
\( W=\frac{L×G}{X} \ \ \ (1) \)
In Equation (1), W represents the predicted result for a given document, L represents the given document type, G represents the prior probability, i.e., the probability that the document belongs to a certain category, and X represents the probability of the document’s occurrence. Equation (1) allows for the calculation of approximate prediction results, making the system’s analytical operations more efficient.
After calculating the predicted probability of a given document, it is immediately necessary to calculate the conditional probability under a multinomial model to refine document analysis, as calculated by Equation (2)
\( C=\frac{S+1}{Z+B}\ \ \ (2) \)
In Equation (2), C represents the probability of a word appearing in a category, S represents the number of documents in the corpus that contain the word and belong to that category, Z represents the total number of words in all documents of that category in the corpus, and B represents the total size of the vocabulary in the corpus. Equation (2) allows for further classification based on the vocabulary in the documents, thus making Chinese spoken language teaching more detailed.
4.System Testing Experiment
4.1.Accuracy Experiment
The experiment randomly selected one Chinese spoken language teaching institution teacher to conduct teaching assessments using the Chinese spoken language teaching assessment algorithm and model based on natural language processing and knowledge graphs (Group A), while three teachers chose the machine learning system (Group B), sentiment analysis system (Group C), and virtual language interaction system (Group D). The institution’s teachers tested the average accuracy rates predicted by each algorithmic system over a period of one month. After the experiment concluded, the data were integrated and analyzed by the experimenters.

Figure 3. Experiment Data on System Accuracy
Analysis of the experimental data from Figure 3 reveals that the accuracy rate of the Chinese spoken language teaching assessment system based on natural language processing and knowledge graphs far outstripped the others, reaching as high as 98.05%, the highest among the groups in the experiment. The accuracy rates of the other algorithmic Chinese spoken language teaching assessment systems were all below 89.23%, with error rates all above 10.77%, and the highest reaching 30.38%.
4.2.Personalized Teaching Assessment Experiment
Students are individuals, and in educational assessments, accuracy alone is far from sufficient. Only by fully leveraging educational intelligence can we meet the personalized development needs of students. However, fully understanding students and providing personalized learning takes time, and the concept of personalization is somewhat subjective. Therefore, this system’s personalized assessment experiment chose to use teaching assessment satisfaction for the experiment, which lasted six months. The experiment personnel and venue were the same as the last experiment, but due to objective factors affecting this experiment, only the sentiment analysis system (Group B) was used for a comparative experiment (Group A was the Chinese spoken language teaching assessment system based on natural language processing and knowledge graphs). In the end, the satisfaction of students and teachers was collected monthly to judge the effectiveness of the system’s use.

Figure 4. Data from the Personalized Experiment
Analysis of the experimental data from Figure 4 shows that the personalized satisfaction rate of the Chinese spoken language teaching assessment system based on natural language processing and knowledge graphs started at 57.23% and increased monthly. By the sixth month of the experiment, it had reached as high as 98.12%. The sentiment analysis Chinese spoken language teaching assessment system started at 61.24%, slightly higher than Group A, but by the sixth month, it was at 70.27%, far lower than the Chinese spoken language teaching assessment system based on natural language processing and knowledge graphs. This indicates that in personalized teaching assessments, the Chinese spoken language teaching assessment system based on natural language processing and knowledge graphs has a significant advantage.
5.Conclusion
The design of the Chinese spoken language teaching assessment algorithm and model based on natural language processing and knowledge graphs innovatively introduces evaluation methods and organically integrates natural language processing and knowledge graph technologies. This method provides Chinese learners with precise and personalized assessment tools, enhancing the quality of teaching and learning. It not only promotes the personalized development of education but also lays the foundation for the future development of similar technologies. In the future, systematized spoken language will further optimize teaching methods and learning experiences, promoting the development of Chinese education globally. This trend may lead to broader applications of language learning technologies in the future, providing students with a better learning experience and thus advancing the process of the whole world learning Chinese.
References
[1]. Li Xueqing, Wang Shi, Wang Zhujun,et al. Overview of natural language generation [J]. Journal of Computer Applications, 2021, 41(5):1227-1335.
[2]. Zhao Jingsheng, Song Mengxue, Gao Xiang, Zhu Qiaoming. Research on text representation in natural language Processing [J]. Journal of Software, 2022, 33(1):102-128.
[3]. ZHANG Ningyu, Xie Xin, Chen Xiang, Deng Shumin, Ye Hongbin, Chen Huajun. Low resource knowledge graph completion method based on knowledge collaborative fine-tuning [J]. Journal of Software, 2022, 33(10):3531-3545.
[4]. Jiang Yi, Zhang Wei, Wang Pei, ZHANG Xinyue Mei Hong. Construction method of knowledge graph based on Internet swarm intelligence [J]. Journal of Software, 2022, 33(7):2646-2666.
[5]. JI Lei, Zhang Zhimin, Wang Xinyi, et al. Security analysis of Knowledge graph Embedding [J]. Software Engineering and Applications, 2023, 12(6): 844-850.
[6]. FU Feifei. Research on scene text recognition Algorithm [J]. Fujian Computer, 2020, 36(4):1-4.
[7]. YAN J Z. Research on character recognition algorithm in curriculum learning methods. Fujian Computer, 2020, 36(4):18-22.
[8]. Luo Meiqiu, Zhang Chunxia, Peng Cheng, et al. Knowledge graph completion based on analytic graph embedding and weighted graph convolutional networks [J]. Science China: Information Science, 2022, 52(11):2037-2057.
[9]. Wu Junhong, Zhao Yang, Zong Chengqing. Capability analysis and future prospects of ChatGPT [J]. Science Foundation of China, 2023, 37(5):735-742.
[10]. Li Yachao, Jiang Jing, Dai Yugang. Exploration and Summary of experimental teaching of natural Language Processing [J]. Information and Computer, 2020, 32(16):228-230.
[11]. Lou Celi, TONG Minglei, Xue Liang. Natural scene character recognition based on subword coding [J]. Radio Engineering, 2023, 53(8):1800-1806.
[12]. Yang Chun, Liu Chang, Fang Zhiyu, et al. Open set character recognition technology. Journal of Image and Graphics, 2023, 28(6):1767-1791.
[13]. Zhang Le, Zhu Yalin. Lexical information acquisition in natural language: an improved skip-gram model [J]. 2021, 28(2):19-26.
Cite this article
Ma,X.;Hu,Y.;Li,M. (2024). Design of assessment algorithm and model for Chinese spoken language teaching based on natural language processing and knowledge graph. Theoretical and Natural Science,36,20-26.
Data availability
The datasets used and/or analyzed during the current study will be available from the authors upon reasonable request.
Disclaimer/Publisher's Note
The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of EWA Publishing and/or the editor(s). EWA Publishing and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content.
About volume
Volume title: Proceedings of the 2nd International Conference on Mathematical Physics and Computational Simulation
© 2024 by the author(s). Licensee EWA Publishing, Oxford, UK. This article is an open access article distributed under the terms and
conditions of the Creative Commons Attribution (CC BY) license. Authors who
publish this series agree to the following terms:
1. Authors retain copyright and grant the series right of first publication with the work simultaneously licensed under a Creative Commons
Attribution License that allows others to share the work with an acknowledgment of the work's authorship and initial publication in this
series.
2. Authors are able to enter into separate, additional contractual arrangements for the non-exclusive distribution of the series's published
version of the work (e.g., post it to an institutional repository or publish it in a book), with an acknowledgment of its initial
publication in this series.
3. Authors are permitted and encouraged to post their work online (e.g., in institutional repositories or on their website) prior to and
during the submission process, as it can lead to productive exchanges, as well as earlier and greater citation of published work (See
Open access policy for details).
References
[1]. Li Xueqing, Wang Shi, Wang Zhujun,et al. Overview of natural language generation [J]. Journal of Computer Applications, 2021, 41(5):1227-1335.
[2]. Zhao Jingsheng, Song Mengxue, Gao Xiang, Zhu Qiaoming. Research on text representation in natural language Processing [J]. Journal of Software, 2022, 33(1):102-128.
[3]. ZHANG Ningyu, Xie Xin, Chen Xiang, Deng Shumin, Ye Hongbin, Chen Huajun. Low resource knowledge graph completion method based on knowledge collaborative fine-tuning [J]. Journal of Software, 2022, 33(10):3531-3545.
[4]. Jiang Yi, Zhang Wei, Wang Pei, ZHANG Xinyue Mei Hong. Construction method of knowledge graph based on Internet swarm intelligence [J]. Journal of Software, 2022, 33(7):2646-2666.
[5]. JI Lei, Zhang Zhimin, Wang Xinyi, et al. Security analysis of Knowledge graph Embedding [J]. Software Engineering and Applications, 2023, 12(6): 844-850.
[6]. FU Feifei. Research on scene text recognition Algorithm [J]. Fujian Computer, 2020, 36(4):1-4.
[7]. YAN J Z. Research on character recognition algorithm in curriculum learning methods. Fujian Computer, 2020, 36(4):18-22.
[8]. Luo Meiqiu, Zhang Chunxia, Peng Cheng, et al. Knowledge graph completion based on analytic graph embedding and weighted graph convolutional networks [J]. Science China: Information Science, 2022, 52(11):2037-2057.
[9]. Wu Junhong, Zhao Yang, Zong Chengqing. Capability analysis and future prospects of ChatGPT [J]. Science Foundation of China, 2023, 37(5):735-742.
[10]. Li Yachao, Jiang Jing, Dai Yugang. Exploration and Summary of experimental teaching of natural Language Processing [J]. Information and Computer, 2020, 32(16):228-230.
[11]. Lou Celi, TONG Minglei, Xue Liang. Natural scene character recognition based on subword coding [J]. Radio Engineering, 2023, 53(8):1800-1806.
[12]. Yang Chun, Liu Chang, Fang Zhiyu, et al. Open set character recognition technology. Journal of Image and Graphics, 2023, 28(6):1767-1791.
[13]. Zhang Le, Zhu Yalin. Lexical information acquisition in natural language: an improved skip-gram model [J]. 2021, 28(2):19-26.