


Volume 207
Published on November 2025Volume title: Proceedings of CONF-SPML 2026 Symposium: The 2nd Neural Computing and Applications Workshop 2025
Under the backdrop of the "carbon neutrality" goal, the integration of the integrated energy system (IES) and MMAI is expected to become a key research direction.Firstly, IES plays a significant role in optimizing energy allocation, promoting the intelligent transformation of energy, and enhancing energy utilization efficiency. However, it still has issues such as complexity, multiplicity, and uncertainty. Secondly, the optimization methods of traditional integrated energy systems encounter numerous problems when dealing with high-dimensional, heterogeneous, and time-varying multimodal data, including excessively high computational complexity and difficulties in handling heterogeneous data.Therefore, Therefore, the introduction of MMAI technology is required the system's ability to handle the complexity and diversity of data. This paper adopts the research approach of "theoretical analysis - architecture construction - mechanism explanation - challenge outlook" to explore the integration mechanism of multimodal AI in IES. Research has shown that MMAI can achieve efficient processing and rapid adaptation of multimodal data through a closed loop of "perception - cognition - decision - control", thereby enhancing the intelligence level of the system. However, the technological development of MMAI integrated with IES still faces multiple challenges. To address these challenges, in the future, our research efforts should be focused on the data level, algorithm level, and system level. This technology has multiple research directions, such as developing lightweight and interpretable multimodal fusion models, constructing an IES multimodal open benchmark dataset and simulation platform, and exploring new paradigms for the integration of physical mechanisms and data-driven approaches.



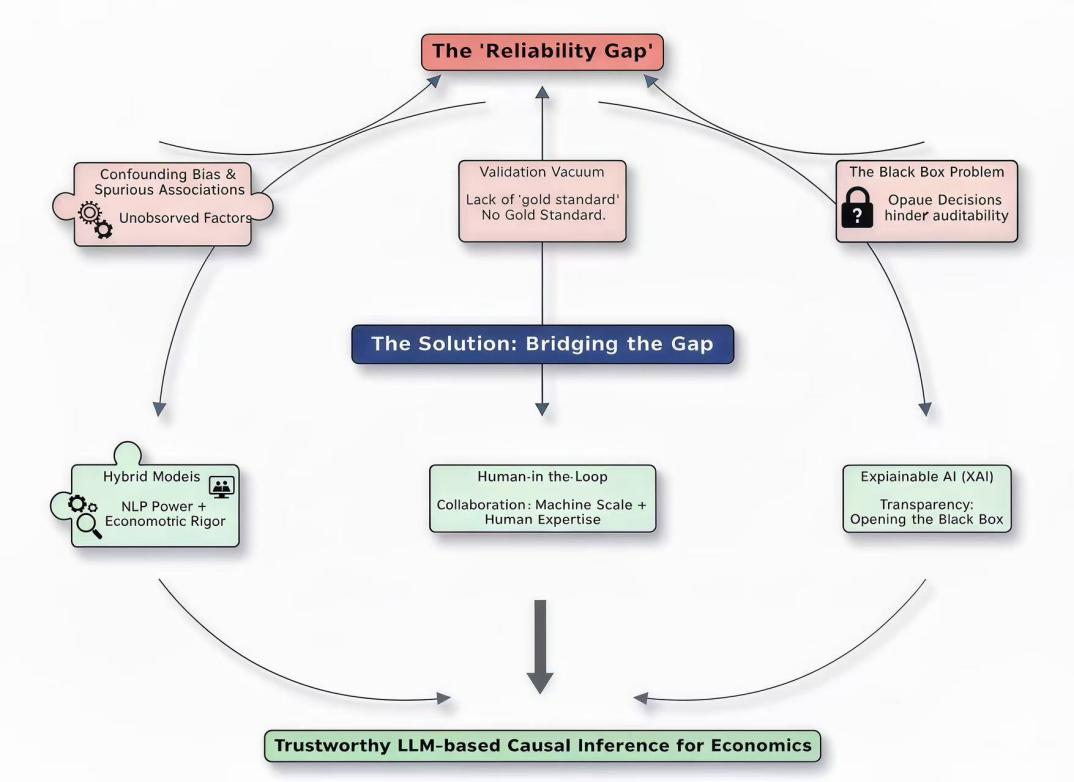
Large Language Models (LLMs) are driving a paradigm shift in economic causal inference, thereby enabling the direct quantification of causal effects from unstructured text. However, this transformation comes with a significant reliability gap. Existing approaches, whether using text as a proxy, extracting causal chains, or treating LLMs as world models, are constrained by three interconnected challenges: persistent confounding, a lack of robust validation standards, and limited interpretability. Through a review of more than 30 studies in text analysis, causal science, and computational economics, the results show that, unless the reliability gap is directly addressed, LLMs are likely to remain promising black boxes and cannot yet serve as reliable tools for policy analysis or scientific discovery. To enhance credibility, research efforts should go beyond exploring model capabilities, and reliability can be improved via a multi-pronged approach involving hybrid models, human-machine collaboration, and Explainable AI (XAI). Consequently, the paper aims to guide this critical transition and future research to develop reliable and accountable LLMs for economics.
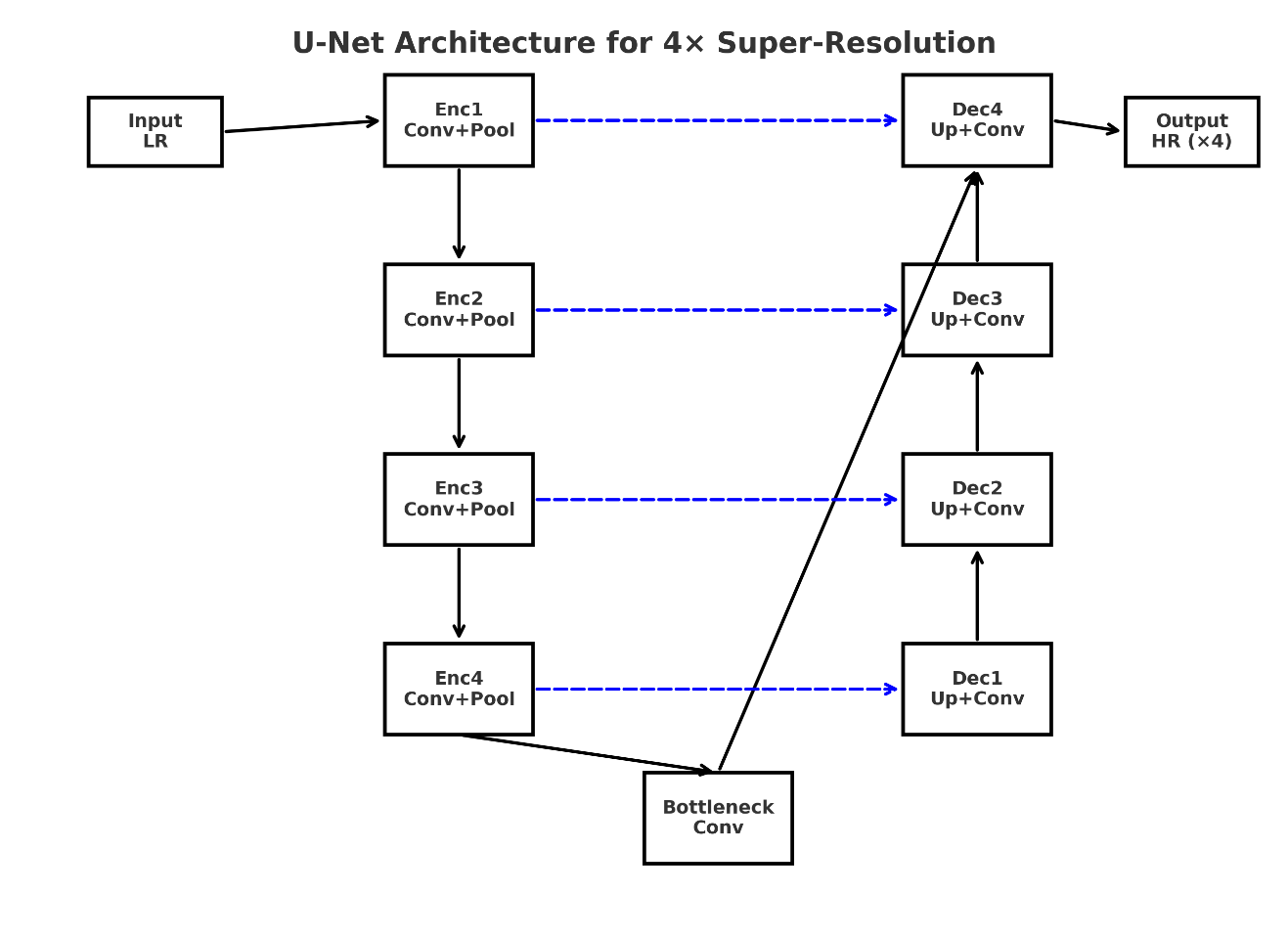
Single-image super-resolution (SR) has achieved strong performance on benchmark datasets with deep learning methods. However, applying SR to 4K images remains challenging due to GPU memory limits, inference speed, and the presence of visual artifacts at tile boundaries. A practical solution is overlap-tiling with weighted blending, which suppresses seams by smoothly merging patches. While widely used, the robustness of seamless SR under real degradations such as defocus or motion blur has not been systematically analyzed. This paper proposes a reproducible pipeline for seamless 4× SR on 4K images using a U-Net backbone combined with overlap-tiling and three weighting strategies: linear, Hann, and Gaussian. Synthetic Gaussian and motion blur with varying intensities are applied to test robustness. Extensive experiments demonstrate that larger overlaps improve seam suppression, and weighting profiles trade off differently between fidelity and runtime. Hann windows generally yield higher PSNR and SSIM, while Gaussian provides more stable results under strong blur. A Pareto analysis further highlights the balance between quality and efficiency. These findings establish overlap-tiling with proper blending as a practical and robust approach for real-world high-resolution SR applications.
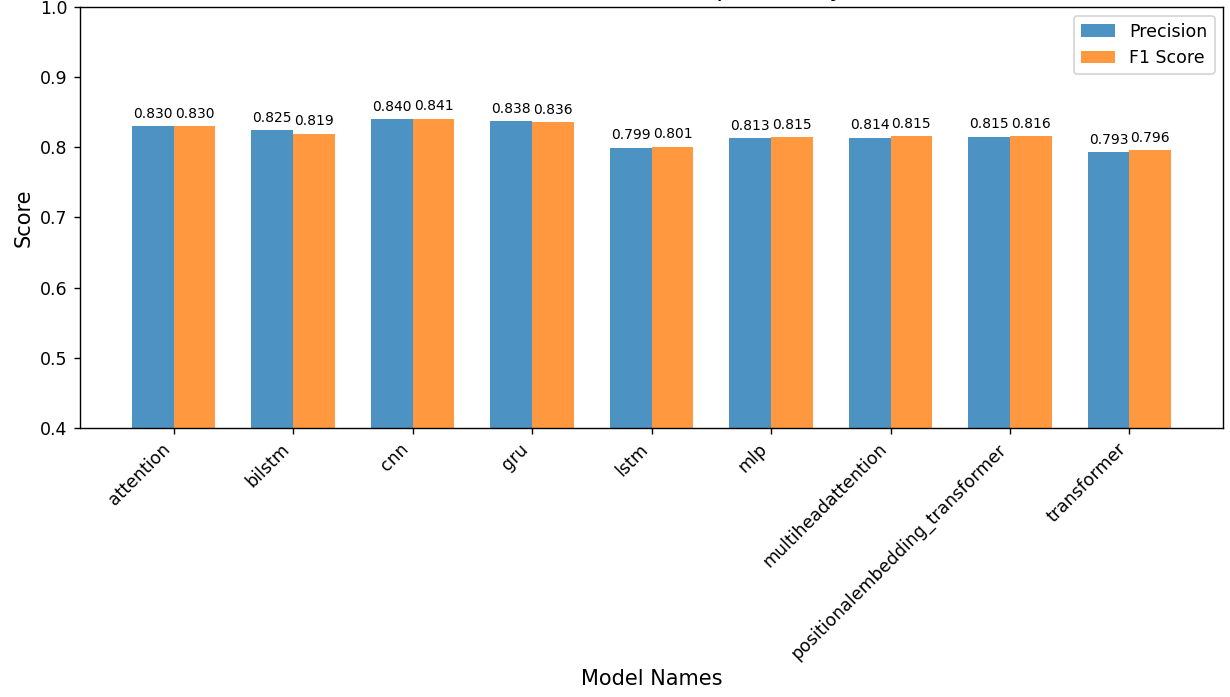
The field of Natural Language Processing (NLP) currently has a bright future, but it still faces challenges due to a series of issues such as language complexity, data resources and limitations. Therefore, this paper starts with the classic sentiment analysis problem. Based on the IMDB movie review dataset, by evaluating the original dataset, the semantic contradiction set obtained by filtering the original data, and the easily confused dataset obtained by training the large prediction model with prompt words, this paper systematically estimates the basic performance of a series of models including CNN, LSTM, BiLSTM, GRU, MLP, Attention, Multi-HeadAttention, Transformer, and PositionalEmbedding+Transformer. With this in-depth study, the basic generalization ability, anti-interference ability, and fine-grained semantic understanding ability of the model are studied. Comparison of the original test set and the semantically contradictory set shows that each model has excellent basic generalization capabilities. The GRU demonstrates the strongest interference resistance in the semantically contradictory set, while the LSTM demonstrates the best fine-grained semantic understanding in the easily confused set. Combining the scores of indicators across the test sets, the Attention model demonstrates the most comprehensive overall performance. This research reflects the potential for further development of RNN and its variants and suggests the possibility and potential of models such as the RNN+Attention model.
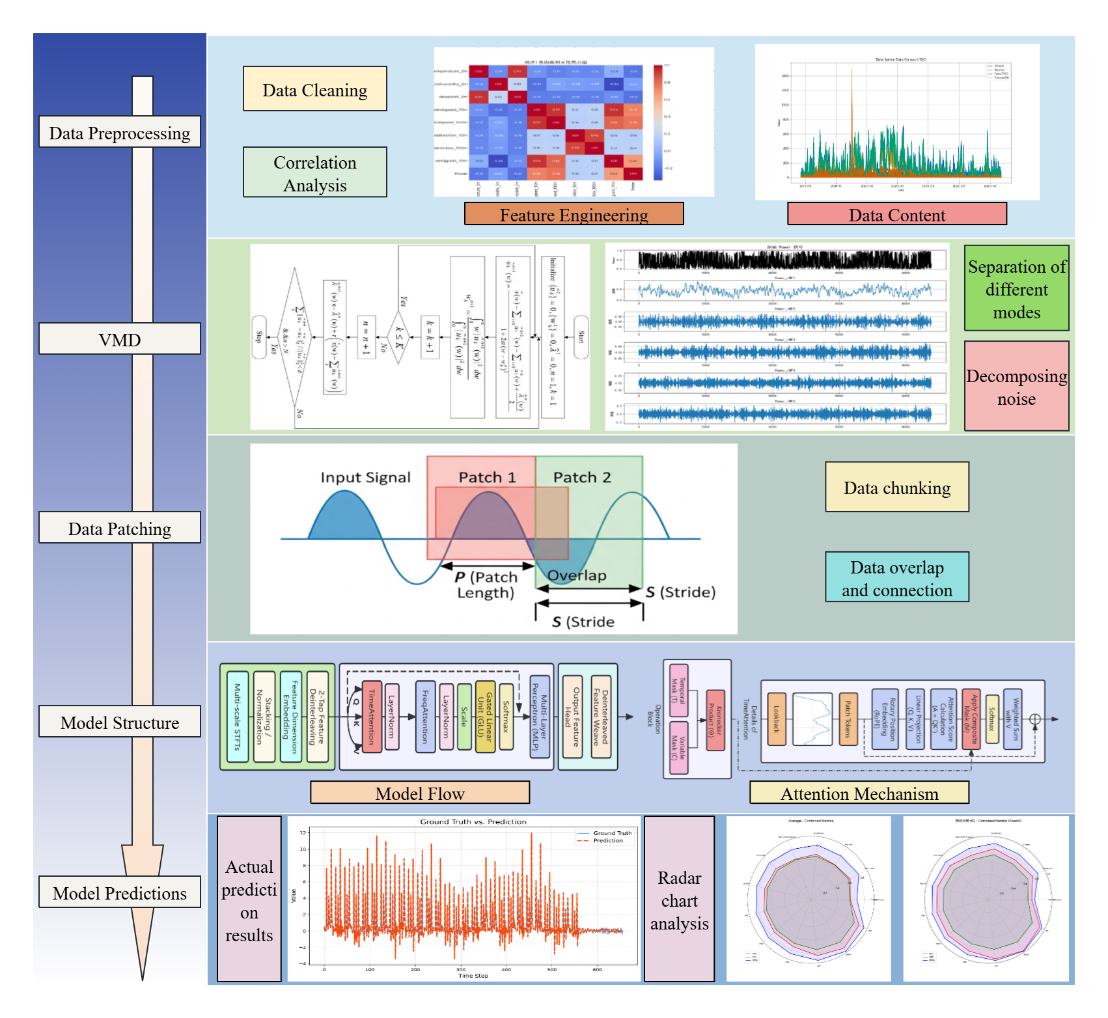
Accurate long-term wind power forecasting is crucial for ensuring stable power system operation and promoting renewable energy integration. However, existing forecasting models are often limited in their performance when processing wind power series due to inherent no stationarity and noise. They also face challenges such as inefficient modeling of long-sequence context and insufficient ability to capture long-term dependencies. To address these issues, this paper proposes a hybrid forecasting framework based on variational mode decomposition (VMD) and block-wise temporal attention (Time Attention). First, VMD is used to decompose the original highly volatile power series into a series of stationary and more regular intrinsic mode components (IMFs), effectively suppressing noise and reducing modeling complexity. Furthermore, a sequence-wise block-wise strategy is introduced to convert long series into local block token inputs, thus overcoming the context length limitations of traditional Transformers and enhancing the model's ability to capture long-term trends. Finally, a novel Time Attention mechanism is designed to explicitly model intra-module temporal dynamics and inter-modal correlations through hierarchical masks, enabling deeper feature extraction. To validate the effectiveness of the proposed framework, we conduct a comprehensive comparison with 12 mainstream baseline models on two public datasets. Experimental results show that in the task of predicting the next 96 time steps on Dataset 1, the mean squared error (MSE) of our model is reduced by 27.7% compared to the second-best Informer model, fully demonstrating the excellent capabilities and application potential of this framework in improving the accuracy and robustness of long-term wind power forecasting.
The Transformer architecture has transformed natural language processing (NLP) by enabling efficient sequence modeling through self-attention and embedding techniques. However, its ability to adapt to domain-specific data, such as protein sequences, introduces both unique computational challenges and opportunities. As the sequence space increases, the understanding of architectural differences is crucial for improving model efficiency and generalization. This study aims to investigate the fundamental differences between protein language models (PLMs) and traditional text-based language models (LLMs), highlighting their modeling principles, embedding structures, and attention mechanisms. By reviewing and analyzing the relevant literature, the methods adopted by PLMs and LLMs are explored, emphasizing their unique features. The results reveal that PLMs, with their sparse attention mechanism and highly linearly separable embeddings, demonstrate superior capabilities in processing long sequences for pattern extraction, while language models focus on semantic dependencies. These differences reveal the potential for cross-domain optimization, helping to improve the application of Transformers in sequence analysis and generation.
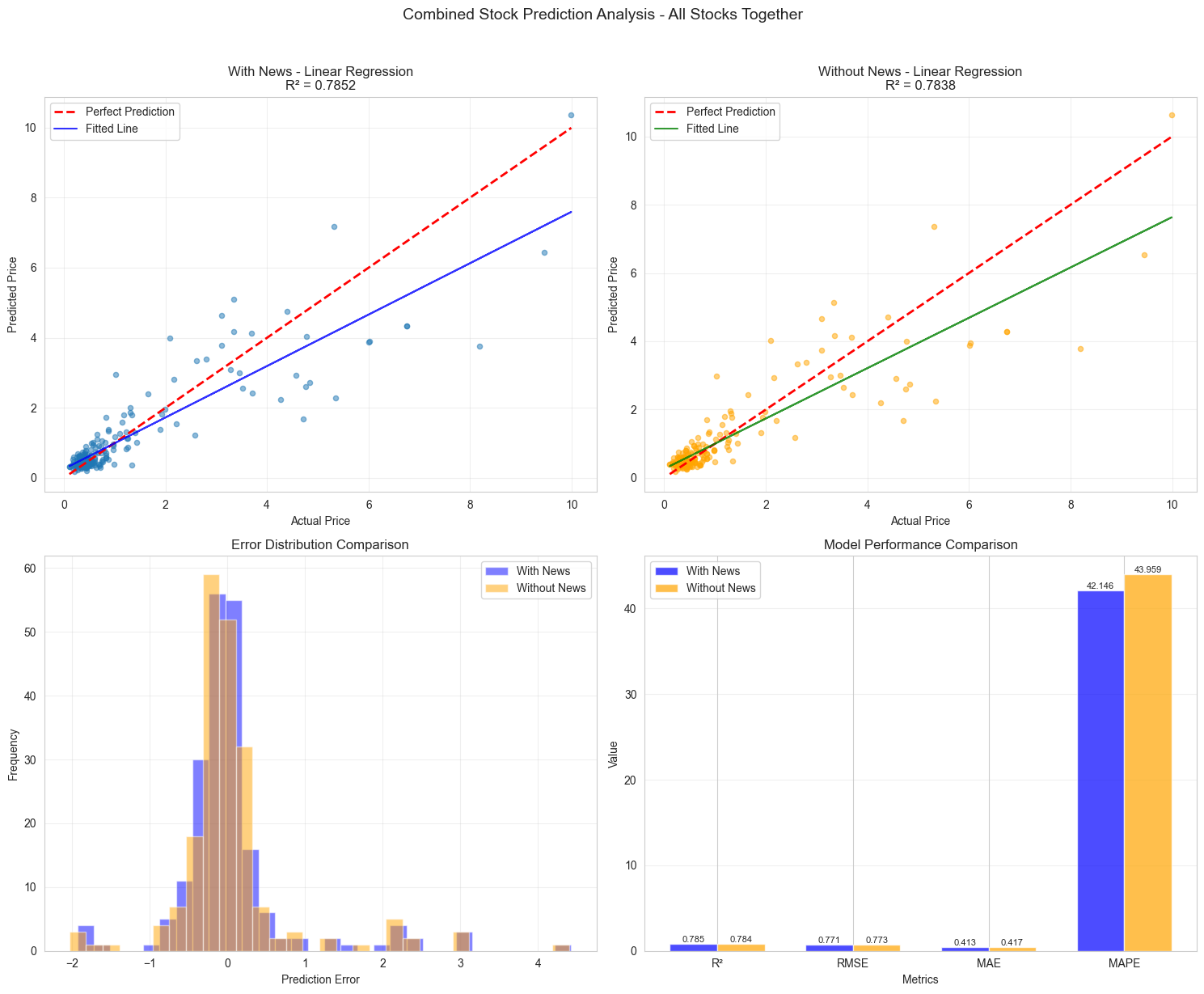
In this study, we aim to predict stock market trends based on news using a special type of AI model to confront with the chaos of the stock market and the limitations of traditional models that ignore public opinion. We developed a business-oriented sentiment labeling system based on a standard sentiment labeling system and real financial logic, which can achieve 89.0% classification accuracy. On this basis, we constructed an improved prediction model trained on multiple financial data (transaction, fundamental, news, etc.). The method is to directly integrate and test. The results show that the model has a good prediction effect, and the R^2 value on the test set is 0.80. The experimental results show that, compared with the model without news sentiment features, the model with news sentiment features is more likely to be improved, especially when the data scale is large. This work proves that the news-based artificial intelligence model with business logic can improve the prediction effect of finance and quantitative trading.
With the virtue of large language models (LLMs) being applied in a growing number of fields, from text generation to medical support and financial analysis, the issue of "hallucination" has gained more and more recognition. For the given instances, "hallucination" can be explained with respect to artificial intelligence outputs that imitate coherent and convincing statements regardless of the underlying fact. Continuity of such lapses not only can undermine credibility in LLMs, but also may catalyze problems in numerous strategies, such as law, health care, or education. This paper provides a critical analysis of the currently available methods of preventing hallucinations in LLMs by outlining the retrieval-augmented generation (RAG) technique, verification frameworks, and planning-based strategies. The paper particularly deals with the TruthX reformulation displayed at ACL 2024, which essentially means redefining the meaning of factualism via representation editing. This dialogue is rounded off by stressing the ongoing problems and future growth routes, while suggesting that multiple methods, human cooperation, and efficient representation control altogether can lay the foundation for many more faithful and traceable language models.
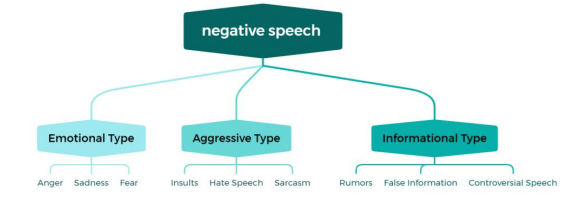
With the increasingly prominent role of social media in information dissemination and social interaction, its anonymity and openness have also led to the gradual prominence of negative speech, which has adverse effects on individual psychology and social stability. Traditional manual moderation models struggle to meet practical needs due to limitations like the vast volume of negative speech and the potential psychological harm to moderators. With automation, real-time processing, and scalability, Natural Language Processing (NLP) serves as a crucial tool for identifying negative language. This paper examines the concept, characteristics, and categories of negative speech on social media, offering a comprehensive analysis of the NLP frameworks employed in negative speech detection, including methods for text representation, feature extraction, and the practical applications of various models. Through a review of existing studies, this paper highlights key optimizations in various methods, identifies substantial limitations and issues in current technologies, and presents key findings on future development trends, informing research and applications in negative speech detection on social media.
Large language models (LLMs) excel at reasoning and generation but remain susceptible to factual hallucinations. This survey categorizes recent progress around the timing of intervention: First, through retrieval augmentation and explicit reasoning during generation; second, through post-hoc verification and self-correction after generation. Regarding the former, this survey reviews IRCoT, SELF-RAG, ReAct, and Atlas, highlighting how combining retrieval with thought chaining can reduce multi-layer errors and improve answer grounding in knowledge-intensive question answering. Regarding the latter, this study examines RARR, Chain-of-Verification (CoVe), CRITIC, and Reflexion, which explore evidence, generate verification questions, or revise outputs through repeated criticism while minimizing stylistic bias. This work also summarizes detection and evaluation practices (e.g., SelfCheckGPT, FACTSCORE) that quantify attribution, support, and completeness. Across various approaches, this study analyzes effectiveness, computational cost, latency, and robustness to noisy retrieval, identifying failure modes such as retrieval dependency, ungrounded verification, and domain-shift gaps. This survey provides practical guidelines: for constrained question answering and multi-step reasoning, a combined retrieval-and-reasoning approach is most effective; whereas post-hoc validation is more suitable for long-form generation and reporting, and for citing external sources. Finally, this work proposes open problems: a unified cost-aware controller that can adjust intervention frequency; stronger evidence attribution; richer benchmarks beyond open-domain question answering; and a clearer trade-off between efficiency and realism for more reliable and scalable hallucination suppression.