







1. Introduction
Singular Value Decomposition (SVD) is a fundamental matrix factorisation technique in linear algebra, generalizing eigenvalue decomposition to non-square and non-symmetric matrices. It decomposes any real or complex matrix into one or more matrices whose size is less than the original one A of size m×n into three matrices, providing deeper insights into structural properties such as rank, nullity, and geometric transformations [1]. SVD has wide applications in different areas, such as signal processing, data compression, machine learning, and computer vision. It is particularly valuable for solving least squares problems, reducing dimensionality, and reducing noise on datasets. It also finds applications in principal component analysis (PCA), search algorithms, and image processing. This paper discusses the mathematical foundations of SVD, its geometric interpretation, existence, and uniqueness [2]. The differences between SVD and eigenvalue decomposition and some practical use of it in python are discussed. The real-world use, the applications of SVD, such as image compression and reductions of data dimensionality are also discussed.
As for basic concepts:
1. Symmetric Matrix: A matrix A is called symmetric when it is equal to its transpose.
Example: A =
2. Eigenvalue Decomposition: A symmetric n×n matrix ‘A’ having ‘n’ real eigenvalues and an orthonormal basis of eigenvectors can be expressed as:
Here, V is the matrix with columns as eigenvectors, and Λ is the diagonal matrix with eigenvalues as diagonal elements. This is called eigenvalue decomposition [3].
3. Singular Value Decomposition: This is a generalisation of eigenvalue decomposition with the requirement that the matrix is not necessarily symmetric or even square. A matrix 'A' can be represented in the form of a matrix factorization of order m × n [4]. It is a linear algebra method of decomposition of a real or complex matrix into three matrices
Before studying it in detail, an exploration of the components of Singular Value Decomposition (SVD) is presented.
2. Geometric interpretation of SVD
The SVD is geometrically seen as the fact that the image of the unit sphere under any m x n matrix is a hyperellipse [5]. The SVD is applicable to both real and complex matrices. However, in describing the geometric interpretation, it is usually assumed that the matrix is real.
The term "hyperellipse" represents an unfamiliar way of describing m-dimensional ellipses within their generalized format. A hyperellipse in
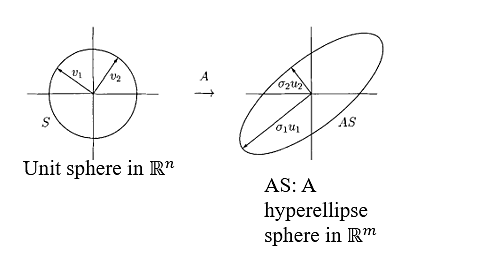
Let A ∈
Let
Let
Let
Then,
Now, if
For simplicity, let's assume
Definition 1: The singular values are the lengths of the
The convention is:
Definition 2: The
Definition 3: The
3. Reduced SVD
Consider
Consider
So,
AV =
Now, since V is an orthogonal matrix then:
A =
4. Full SVD
It is given that
Then
Hence,
This is the full
For non-full rank matrices, i.e.,
and
when
5. Application of SVD
5.1. Image compression
An image is depicted as a matrix where every element corresponds to pixel values.
SVD is applied to decompose the image matrix A into three matrices U, Σ, and





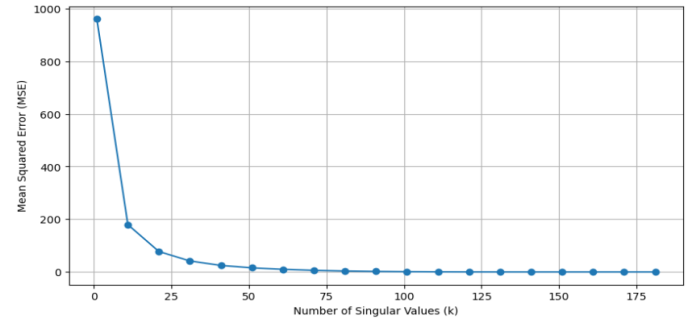
Result: The Figure 3 shows the Mean Squared Error of image restorations against the number of singular values (k) employed in Singular Value Decomposition (SVD). It points to a steep drop in MSE as k is raised from a low value, reflecting considerable improvement in image quality (as shown in Figure 4). The MSE stabilizes as k continues to rise, implying that there are diminishing gains in image quality improvement. Hence, an optimal k value is 175, where image quality meets compression efficiency.
5.2. Data dimensionality reduction
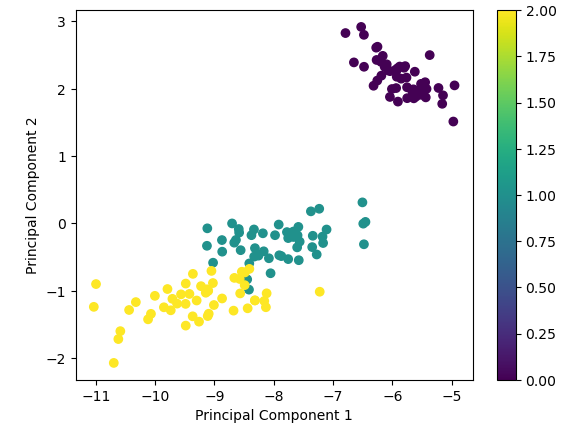
Use SVD to perform dimensionality reduction on a dataset for visualization or further analysis.
SVD compressed the 4D data down into 2D while keeping an important structure.
It works:
1. Exploring high-dimensional data: According to Chiu [8], humans do not have the 3D vision and SVD enables to see that.
2. Use how to improve results for machine learning (SVM, k-NN), and reduce noise.
6. Limitations and conclusion
SVD turns out to be a useful and an universal tool from linear algebra, and can provide a sound, robust tool set to analyze and manipulate matrixes. As a result SVD will allow us to decompose a matrix into orthogonal and diagonal components and to give a geom SD interpretation of linear transformations and characterise linear transformations (rank, nullity, principal directions of variation). The application of eigenvalue decomposition is permitted only to square matrices, and their extensions, whereas SVD can be applied to any matrices (square, nonsquare, symmetric or asymmetric) and is therefore very convenient to use in modern computational mathematics. The Singular Value Decomposition (SVD) exhibits remarkable practicality, finding applications in diverse domains such as image compression, noise reduction, data analysis, and dimensionality reduction. Python-based implementations have demonstrated that SVD can effectively reduce the dimensionality of high-dimensional data while preserving a substantial amount of information, minimizing significant information loss. It is concluded that SVD is central to numerical linear algebra and to data science, and provides an efficient way to obtain solutions to difficult engineering, machine learning, and scientific computing problems. This approach is likely to remain relevant in the world, where there’s big data processing, as it can identify meaningful patterns of the data and is stable in computing. This demonstrates that the advancements will make the use and efficacy of SVD applicable and efficient in new fields.
Singular Value Decomposition (SVD) is a powerful technique to solve matrix problems but is computationally expensive (O(min(mn², m²n)) complexity), noisy and memory constraint for large datasets[9][10]. In addition, it does not work well with nonlinear structures. Several aspects of future research regarding scalable SVD using parallel and randomized methods and robust variants that are resistant to noise remain for future investigate. Other nonlinear extraction approaches (integration with deep learning) can be combined with adaptive rank selection techniques to determine the superior dimensionality reduction. The applications of quantum SVD include large scale computations and could be federated learning and biomedical signal processing. The appropriate of these limitations will enhance SVD’s efficiency and will extend its reach in information technology and data science.
References
[1]. Carroll, J. D., & Green, P. E. (1996). Decomposition of Matrix Transformations: Eigenstructures and Quadratic Forms. Mathematical Tools for Applied Multivariate Analysis (Revised Edition), 194-258. https: //doi.org/10.1016/B978-012160954-2/50006-8
[2]. Wei, T., Ding, W., & Wei, Y. (2024). Singular value decomposition of dual matrices and its application to traveling wave identification in the brain. SIAM Journal on Matrix Analysis and Applications, 45(1), 634-660. https: //doi.org/10.1137/23M1556642
[3]. Hui, J. (2019). Machine Learning — Singular Value Decomposition (SVD) & Principal Component Analysis (PCA). Medium. https: //jonathan-hui.medium.com/machine-learning-singular-value-decomposition-svd-principalcomponent-analysis-pca-1d45e885e491
[4]. Kuttler, K. (2021). A First Course in Linear Algebra. Brigham Young University. https: //openlibrary-repo.ecampusontario.ca/jspui/bitstream/123456789/896/2/Kuttler-LinearAlgebra-AFirstCourse-2021A.pdf
[5]. Trefethen, L. N., & Bau, D. (2021). Numerical linear algebra. Society for Industrial and Applied Mathematics. https: //www.stat.uchicago.edu/~lekheng/courses/309/books/Trefethen-Bau.pdf
[6]. Lloyd, N. T., & David, B. (1997). Numerical linear algebra. Clinical Chemistry, iii edition, UK: Society for Industrial and Applied Mathematics.
[7]. Sauer, T. (2011). Numerical analysis. Addison-Wesley Publishing Company.
[8]. Chiu, C. H., Koyama, Y., Lai, Y. C., Igarashi, T., & Yue, Y. (2020). Human-in-the-loop differential subspace search in high-dimensional latent space. ACM Transactions on Graphics (TOG), 39(4), 85-1. https: //doi.org/10.1145/3386569.3392409
[9]. Schmidt, D. (2020). A Survey of Singular Value Decomposition Methods for Distributed Tall/Skinny Data. arXiv preprint arXiv: 2009.00761v1 [cs.MS]. Retrieved from https: //arxiv.org/abs/2009.00761v1
[10]. Golub, G. H., & Van Loan, C. F. (2013). Matrix Computations (4th ed.). Johns Hopkins Studies in the Mathematical Sciences. The Johns Hopkins University Press. Retrieved from https: //math.ecnu.edu.cn/~jypan/Teaching/books/2013%20Matrix%20Computations%204th.pdf
Cite this article
Zhao,X. (2025). Singular Value Decomposition. Theoretical and Natural Science,125,54-59.
Data availability
The datasets used and/or analyzed during the current study will be available from the authors upon reasonable request.
Disclaimer/Publisher's Note
The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of EWA Publishing and/or the editor(s). EWA Publishing and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content.
About volume
Volume title: Proceedings of CONF-APMM 2025 Symposium: Multi-Qubit Quantum Communication for Image Transmission over Error Prone Channels
© 2024 by the author(s). Licensee EWA Publishing, Oxford, UK. This article is an open access article distributed under the terms and
conditions of the Creative Commons Attribution (CC BY) license. Authors who
publish this series agree to the following terms:
1. Authors retain copyright and grant the series right of first publication with the work simultaneously licensed under a Creative Commons
Attribution License that allows others to share the work with an acknowledgment of the work's authorship and initial publication in this
series.
2. Authors are able to enter into separate, additional contractual arrangements for the non-exclusive distribution of the series's published
version of the work (e.g., post it to an institutional repository or publish it in a book), with an acknowledgment of its initial
publication in this series.
3. Authors are permitted and encouraged to post their work online (e.g., in institutional repositories or on their website) prior to and
during the submission process, as it can lead to productive exchanges, as well as earlier and greater citation of published work (See
Open access policy for details).
References
[1]. Carroll, J. D., & Green, P. E. (1996). Decomposition of Matrix Transformations: Eigenstructures and Quadratic Forms. Mathematical Tools for Applied Multivariate Analysis (Revised Edition), 194-258. https: //doi.org/10.1016/B978-012160954-2/50006-8
[2]. Wei, T., Ding, W., & Wei, Y. (2024). Singular value decomposition of dual matrices and its application to traveling wave identification in the brain. SIAM Journal on Matrix Analysis and Applications, 45(1), 634-660. https: //doi.org/10.1137/23M1556642
[3]. Hui, J. (2019). Machine Learning — Singular Value Decomposition (SVD) & Principal Component Analysis (PCA). Medium. https: //jonathan-hui.medium.com/machine-learning-singular-value-decomposition-svd-principalcomponent-analysis-pca-1d45e885e491
[4]. Kuttler, K. (2021). A First Course in Linear Algebra. Brigham Young University. https: //openlibrary-repo.ecampusontario.ca/jspui/bitstream/123456789/896/2/Kuttler-LinearAlgebra-AFirstCourse-2021A.pdf
[5]. Trefethen, L. N., & Bau, D. (2021). Numerical linear algebra. Society for Industrial and Applied Mathematics. https: //www.stat.uchicago.edu/~lekheng/courses/309/books/Trefethen-Bau.pdf
[6]. Lloyd, N. T., & David, B. (1997). Numerical linear algebra. Clinical Chemistry, iii edition, UK: Society for Industrial and Applied Mathematics.
[7]. Sauer, T. (2011). Numerical analysis. Addison-Wesley Publishing Company.
[8]. Chiu, C. H., Koyama, Y., Lai, Y. C., Igarashi, T., & Yue, Y. (2020). Human-in-the-loop differential subspace search in high-dimensional latent space. ACM Transactions on Graphics (TOG), 39(4), 85-1. https: //doi.org/10.1145/3386569.3392409
[9]. Schmidt, D. (2020). A Survey of Singular Value Decomposition Methods for Distributed Tall/Skinny Data. arXiv preprint arXiv: 2009.00761v1 [cs.MS]. Retrieved from https: //arxiv.org/abs/2009.00761v1
[10]. Golub, G. H., & Van Loan, C. F. (2013). Matrix Computations (4th ed.). Johns Hopkins Studies in the Mathematical Sciences. The Johns Hopkins University Press. Retrieved from https: //math.ecnu.edu.cn/~jypan/Teaching/books/2013%20Matrix%20Computations%204th.pdf