


Volume 134
Published on July 2025Volume title: The 3rd International Conference on Applied Physics and Mathematical Modeling
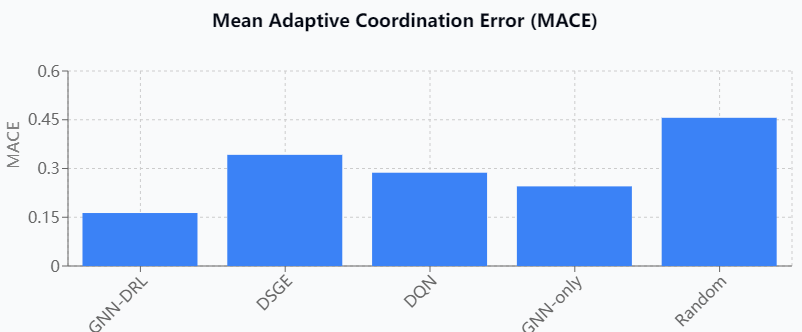
Against the backdrop of accelerating global climate change and advancing green transitions, national fiscal instruments deployed by countries, such as carbon taxes, green subsidies and public investment, are increasingly generating unintended cross-border spillover effects, undermining the macroeconomic stability and fiscal space of other countries through trade linkages, capital flows and regulatory arbitrage, and creating complex interdependencies that challenge traditional economic coordination. While traditional dynamic stochastic general equilibrium models and extended IS-LM frameworks provide some insight into cross-border policy interactions, their rigidity, equilibrium focus, and reliance on static assumptions prevent them from adequately capturing the adaptive, nonlinear, and high-dimensional nature of real-world fiscal dynamics. Combining advances in artificial intelligence techniques of graph neural networks and deep reinforcement learning, the study proposes a framework for generating adaptive policy responses to climate fiscal spillovers, which simulates state behavior in a multi-intelligence policy system and dynamically generates context-aware and forward-looking policy responses. A cross-country fiscal impact network is constructed by using empirical fiscal data from IMF and OECD sources, and model performance is evaluated in scenarios involving carbon tax spillovers and green subsidy competition. This study advances the learning paradigm of international macroeconomic coordination and provides a robust and scalable tool for smart climate policy governance.



A patient-centric digital-twin architecture that fuses ontology-grounded knowledge graphs with structural causal inference is presented to simulate the five-year evolution of type 2 diabetes mellitus and cardio-renal comorbidities. A harmonised health-information-exchange corpus comprising 12 318 adults, 22.7 million encounter rows and 7.4 million laboratory records (2010 – 2024) was mapped to a 168 402-node, 1 217 965-edge graph aligned to SNOMED-CT. Counterfactual trajectories under 17 therapeutic bundles were generated by a differentiable do-calculus engine nested inside a temporal graph transformer, producing 1 000 Monte-Carlo roll-outs per patient. External validation on an independent 2 975-subject cohort yielded a dynamic concordance index of 0.842, an integrated Brier score of 0.091 and a calibration-in-the-large of –0.013, surpassing recurrent neural and mechanistic baselines by 18.5 % and 11.2 % respectively. Sensitivity analyses confirmed robustness to 24 % MCAR missingness and ±15 % hidden-confounding bias. The findings demonstrate that knowledge-graph-driven causal twins deliver granular, well-calibrated forecasts and quantitatively rank preventive strategies, paving the way for learning-health-system deployment in chronic-disease management.
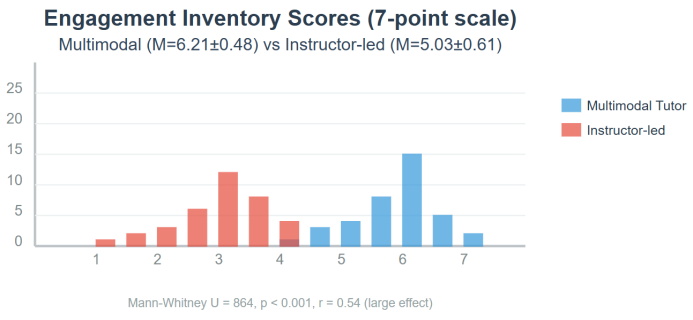
Adaptive multimodal generation now enables artificial interlocutors that perceive speech, gaze, and gesture simultaneously and adjust feedback within milliseconds. Leveraging these advances, the present study engineers and validates a learner-adaptive system that fuses wav2vec-based speech recognition, a vision transformer for non-verbal cues, and a diffusion-avatar prompt engine trained through reinforcement learning with human fluency rubrics as reward. One hundred twenty intermediate English learners (B1–B2) practised with the agent or a teacher-led communicative syllabus for twelve weeks. Fine-grained telemetry captured 63 948 utterances, 5.7 million prosodic frames, and 173 hours of video frames. Mixed-effects growth modelling shows the AI group improved words-per-minute by 48.6 wpm (95 % CI = 42.4–54.8), mean-length-of-run by 3.91 syllables (CI = 3.34–4.48), and reduced filled-pause density by 6.3 pauses per 100 words (CI = 5.1–7.5), outperforming controls on all endpoints (p < 0.001). Learner diaries corroborate quantitative gains, citing lower anxiety and heightened prosodic experimentation. Findings evidence that synchronising cross-modal analytics with real-time generative feedback yields substantial fluency dividends and offer design principles for scalable AI-assisted speaking tutors.