


Volume 193
Published on July 2025Volume title: Proceedings of ICEMGD 2025 Symposium: Innovating in Management and Economic Development
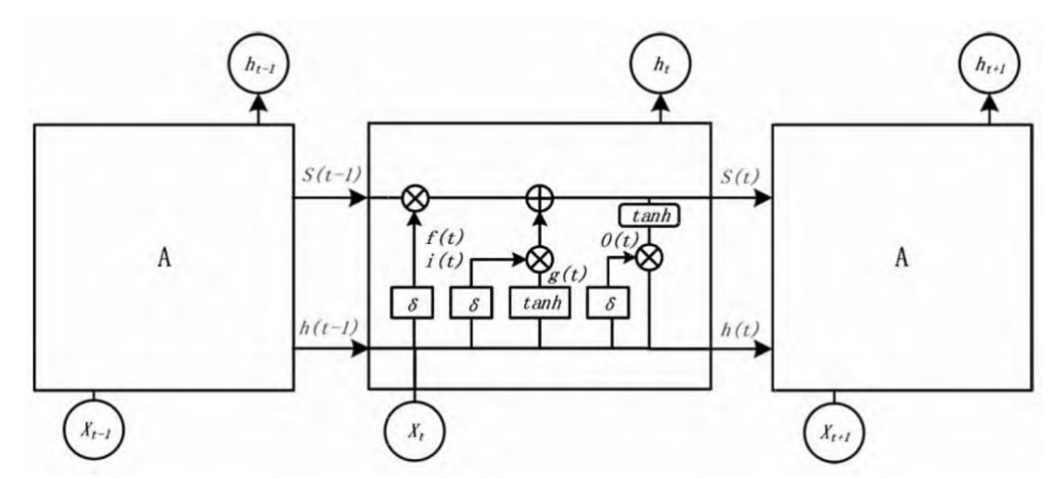
It is difficult to predict stock prices due to volatile financial markets and various economic factors. However, useful effective predictive techniques can offer great assistance to analysts and investors, and therefore much research keeps being conducted in this area. This study analyzed the predictive capabilities of two popular deep learning met...

 Export citation
Export citation
Under the dual challenges of fintech evolution and digital transformation, commercial banks face increasing limitations in traditional marketing prediction methods, which struggle with static customer profiling, low data utilization, and poor adaptability to real-time demands. This study addresses these gaps by proposing an XGBoost-based predictive...
Export citationClimate change has been one of the most pressing issues of this century, and it requires urgent and concerted global action. In the meantime, technology has become a critical tool in mitigating and adapting to its impacts. This essay, through a method of literature review, explores how various technological innovations, such as renewable energy, ca...
Export citation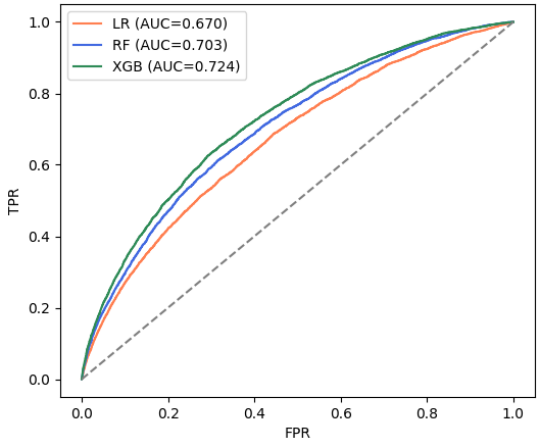
With the rapid development of consumer finance, personal credit business is becoming increasingly active in the financial market, but it is also accompanied by significant credit risks.How to use big data methods to achieve efficient and accurate default prediction has become a core issue in the field of credit risk control.This article takes the H...
Export citationThis paper compares the financial performance, market strategies and positioning of the four key players in the competitive athletic apparel industry; Nike, Lululemon, Under Armour, and Athleta, The Gap. This study evaluates how each business creates and preserves its competitive advantage in the market where rapid changing consumer demand occurs t...
Export citationNansha Economic and Technological Development Zone, as a key strategic platform within the Guangdong-Hong Kong-Macau Greater Bay Area (GBA), serves as a vital engine for regional economic growth and industrial upgrading. This paper delves into the integration pathway of “port logistics—port-proximate industry—technological innovation” in Nansha and...
Export citation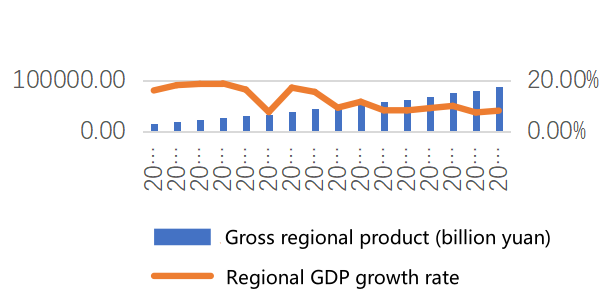
This study focuses on the prediction of the Environmental Kuznets Curve (EKC) and inflection point issues in the Yangtze River Pearl River Delta basin in the future, and conducts an in-depth analysis by comprehensively applying multiple research methods. By combing the theoretical evolution of the Environmental Kuznets Curve, this study clarifies i...
Export citation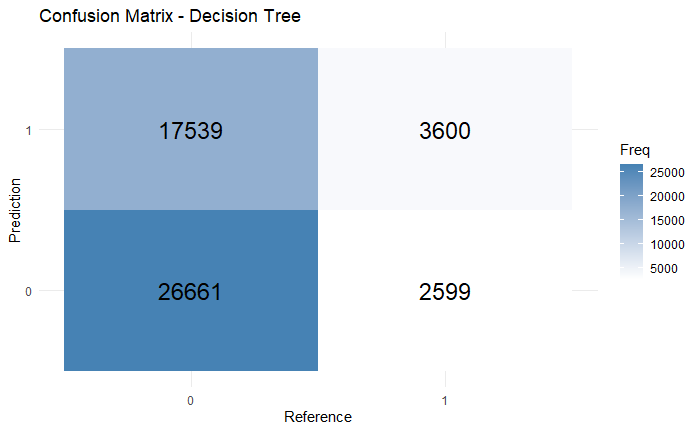
The financial market is always changing rapidly, and it is crucial for people to monitor certain activities to ensure the overall safety of transactions or exchanges. The applications of machine learning have delved into many areas include but not limited to risk management, natural language processing, computer vision etc. This paper explores the ...
Export citation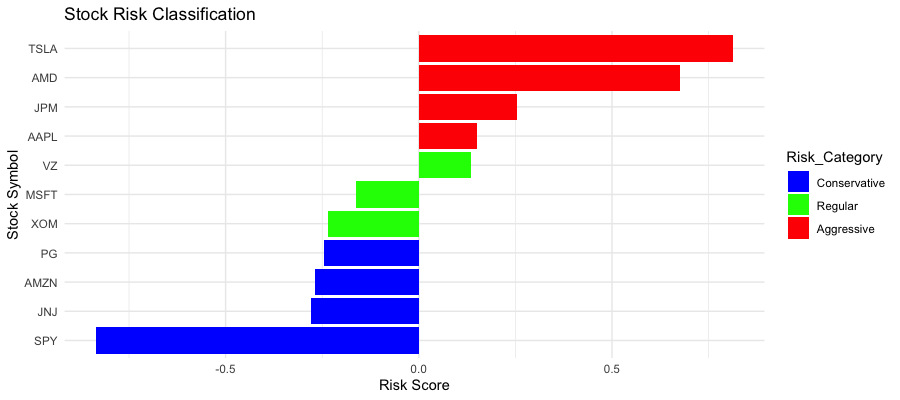
Stock market investment involves various levels of risk. This study attempts to solve the problem of classifying stocks into specific risk categories using fundamental and technical indicators. This study helps bridge the gap between theoretical classification of risks and practical trading approaches for various investment styles. The author emplo...
Export citationThe Guangdong-Hong Kong-Macau Greater Bay Area (GBA) achieves the goal of integration and sustainable development of all regions through the creation of comprehensive smart cities. Leveraging the smart city effect plays a crucial role in the development of the GBA. However, the key to creating a good smart city in each region lies in whether the re...
Export citation- 1
- 2
- 3
- 4