


Volume 112
Published on December 2024Volume title: Proceedings of the 5th International Conference on Signal Processing and Machine Learning
Employee turnover is getting more and more attention in the human resources field. Unexpected turnover of employees is blamed for the loss of work handover. As a result, predicting whether employees would leave has become a crucial problem. This research aims to exploit a method combining particle swarm optimization with a support vector machine to address the employee departure prediction problem. In this study, the particle swarm optimization algorithm is used to optimize the parameter selection of the support vector machine to improve the performance of the latter. Moreover, employee information of a dataset is subject to correlation analysis before being transformed into standardization form to accelerate convergence and improve the accuracy of the support vector machine. Eventually, the support vector machine combined with particle swarm optimization is of best performance in accuracy score, precision score and F1 score, respectively reaching 0.873, 0.947 and 0.784. In conclusion, this method addresses the employee turnover prediction problem effectively which also provides a new direction for applying swarm intelligence algorithms.



In recent years, the production scale of robots has become larger and larger, involving all aspects of society. Many industries are beginning to introduce robots and use them to better development and production. At the same time, autonomous driving is also a promising research direction, which is expected to reach 8 million autonomous vehicles by 2030, and the passenger car market will account for about 13% of total passenger miles. Autonomous driving will also bring many benefits to people, such as freeing up an average of 50 minutes of extra time for drivers per day, which can reduce accidents by more than 90%. Whether it is a robot or a self-driving car, the most important and critical goal is to ensure that the target task can be completed safely and quickly. Simultaneous localization and mapping (SLAM) technology can better help robots achieve this goal. In this paper, laser SLAM, visual SLAM and laser-visual SLAM algorithms are introduced, and then some related applications are shown. Finally, the future development prospect of SLAM should pay more attention to multi-sensor fusion algorithm.
In the contemporary digital era, the accelerated dissemination of data and pervasive interconnectivity have emerged as pivotal drivers of social advancement. The increasing demand for high-performance satellite-terrestrial communications systems, which are vital for achieving seamless global coverage, presents a significant challenge. The advent of 6G technology offers a promising avenue for addressing the current limitations of satellite-terrestrial communications. This paper presents a comprehensive review of the potential applications of 6G technology in satellite-terrestrial communication systems, with a particular focus on its capacity to transform these systems. By achieving seamless global connectivity, 6G technology is positioned to address the limitations of current communication technologies and enhance communication speeds, reliability, and efficiency. This research indicates that the integration of satellite and terrestrial communication networks through 6G not only improves the overall efficiency and coverage of the communication network, but also addresses existing challenges such as limited coverage, high latency and scarce spectrum resources. As research and development progresses, it will be essential to facilitate the widespread adoption and evolution of 6G technology in satellite-terrestrial communications through strengthened global cooperation and standardisation.
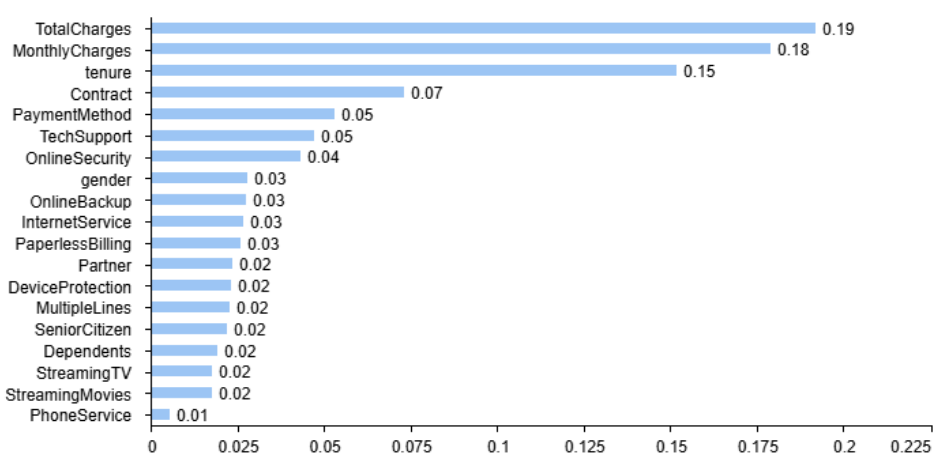
Businesses are seeking to retain existing customers and reduce the cost of acquiring new customers. Therefore, customer churn rate prediction becomes an effective way to solve this problem. This study uses a dataset on telco customer churn to explore the application of multiple linear regression and random forest models in predicting customer churn. By analyzing various customer attributes, including service types, account details, and monthly fees, this paper aims to identify key factors contributing to churn. The random forest model outperformed multiple linear regression in terms of accuracy and stability, achieving an accuracy rate of 79.18% on the test set. However, the R^2 of the multiple linear regression is 0.275. The goodness of fit of the data set is low, but most of the 19 variables are statistically significant. Therefore, this study can further improve the prediction accuracy by changing the data set or combining hybrid models and deep learning technology. Our findings suggest that customer satisfaction, service usage, and total charges are significant factors in predicting customer churn. This paper can provide companies with valuable insights to improve customer retention, enhance customer experience, optimize customer relationships, reduce marketing costs, etc.
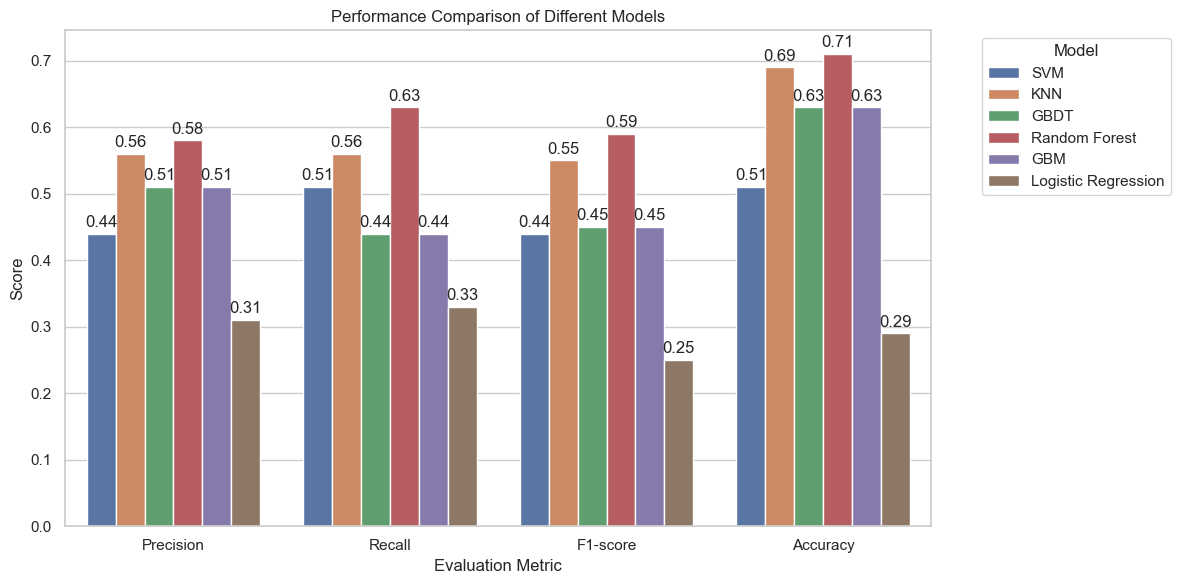
The evaluation of credit risk has become an indispensable element within the financial sector. This research aims to conduct a comparative examination of several machine learning model's performance in predicting credit risk. This research uses comprehensive metrics to give a comparative examination of six machine learning models, including Random Forests (RF) and Support Vector Machines (SVM). The features used in the training of these models were screened by a combination of Random Forest feature importance and Recursive Feature Elimination (RFE) to ensure model accuracy. After comparing the model results, the study concluded that the Random Forest model combined with RFE performed the best among all the risk columns with an accuracy of 0.71. KNN was the next best with an accuracy of 0.69. Logistic regression was the worst performer among the six models with an accuracy of only 0.29. In the study of this paper, the imbalance of the dataset categories resulted in a weak identification of moderate risk categories. It shows that the model is not well adapted to the dataset with imbalanced categories. The paper validates the viability of machine learning in credit risk by offering useful advice on how it may be applied. To further enhance prediction performance, future studies could investigate the combination of more advanced data-balancing strategies and deep learning approaches.
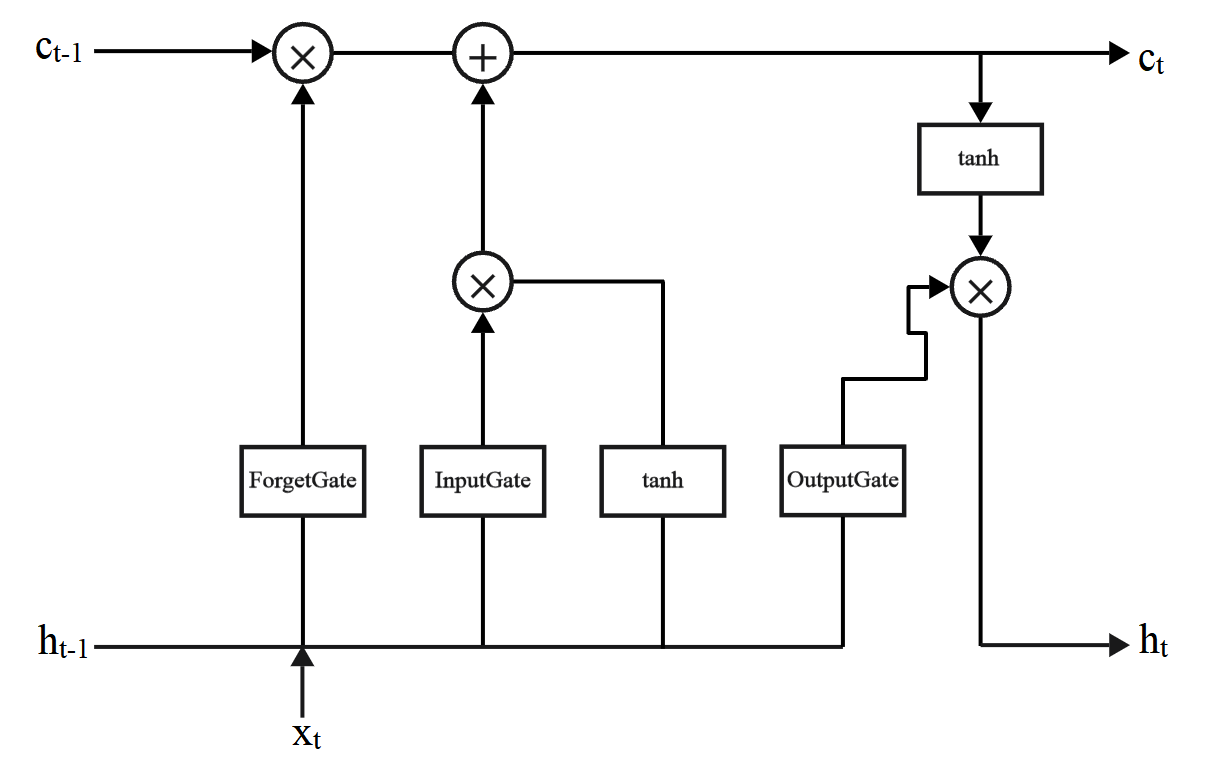
PM2.5 has serious impacts on cardiovascular and respiratory health. As people's attention to physical health increases, the issue of PM2.5 has become increasingly prominent. The goal of this research is to create a prediction model for Beijing's PM2.5 concentrations using the Long Short-Term Memory (LSTM) deep learning algorithm. This paper utilizes PM2.5 measurements from the US Embassy in Beijing and meteorological data from Beijing Capital International Airport from 2010 to 2014. The study forecasts PM2.5 concentrations via the LSTM model by integrating variables such as temperature, pressure, and wind speed. The results of this study validate the feasibility of the LSTM model in predicting PM2.5 and yield relatively good prediction outcomes. It is evident that concentrations are lower in the summer and higher in the winter. However, the prediction results are lower compared to the actual data and are not effective in predicting drastic changes caused by other influencing factors. The results provide information for the creation of more efficient air quality management plans by exposing the connections between PM2.5 and different meteorological variables.
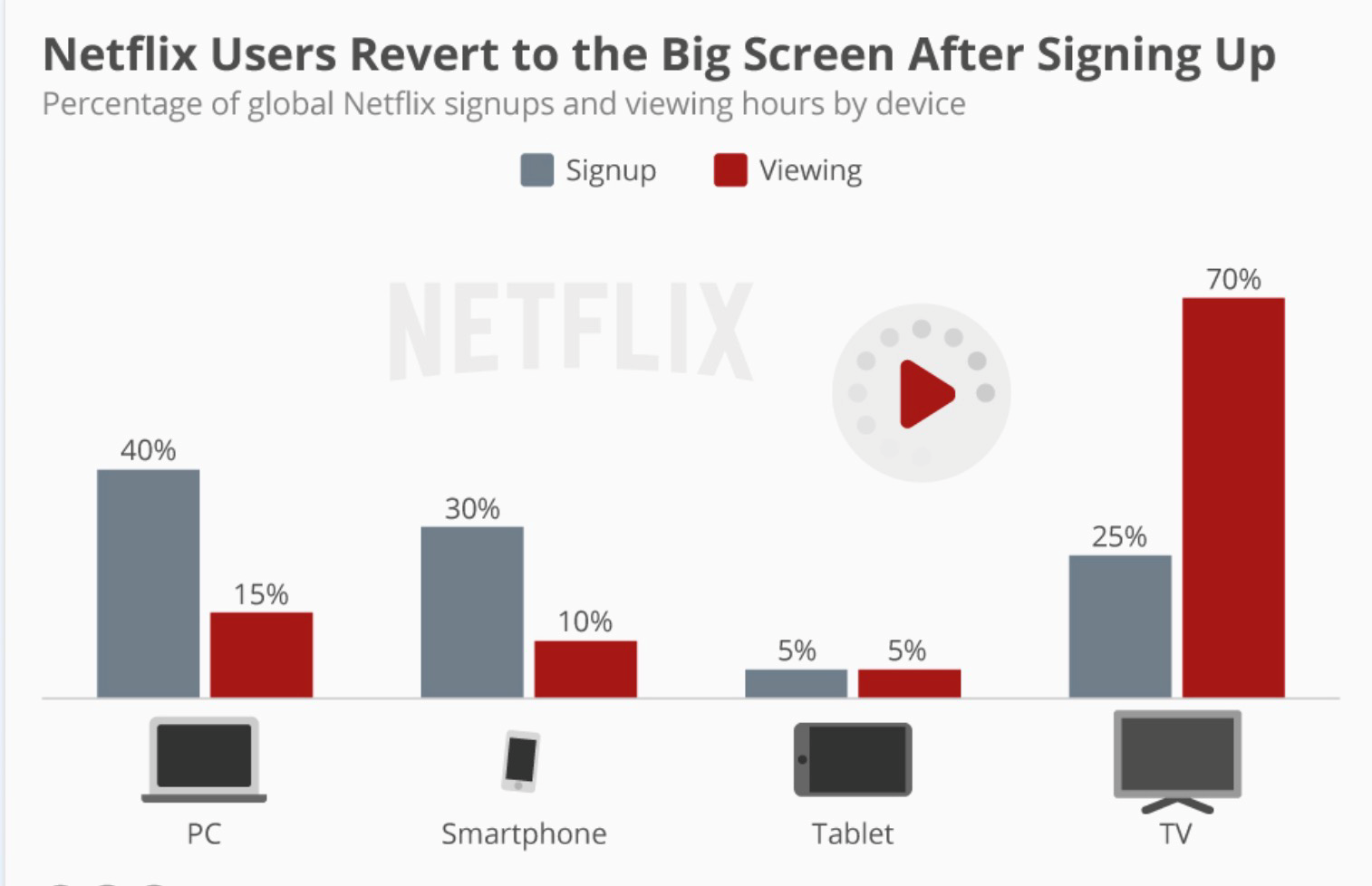
The application of artificial intelligence (AI) continues to expand across various industries, especially in enhancing user experience and optimizing business processes. Through deep learning and machine learning algorithms, companies are able to analyze user behavior data and provide personalized recommendations, which effectively improve customer satisfaction and loyalty. This data-driven approach enables businesses to stand out in a highly competitive market. This paper explores the key role of machine learning-based personalized recommendation systems in improving user experience and highlights the importance of behavioral data-driven UI design for business success. Research shows that successful recommendation systems not only rely on advanced technology applications, but also need to deeply understand user needs to optimize user interface design and promote effective user interaction. As technology continues to advance, personalized recommendation systems will become more intelligent, and companies should actively explore these innovative ways to increase user engagement and brand loyalty to achieve sustainable business growth.
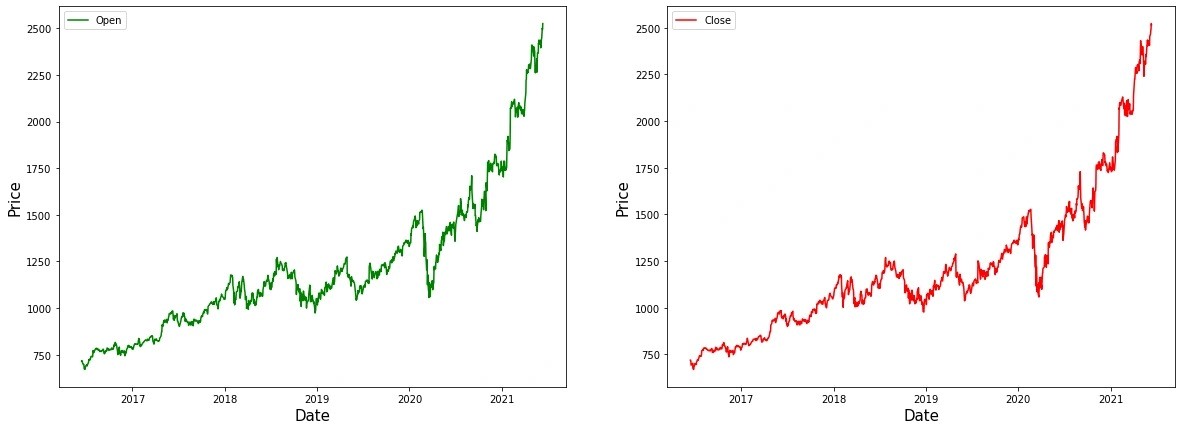
In the Artificial Intelligence development market in recent years, the atmosphere felt by the financial field will be relatively strong, and some, especially in the deep learning model, widely exist in the performance of complex financial data, which has certain advantages. Therefore, as one of the most prominent models of deep learning, LSTM neural network models are just good at processing some complex financial data of the rest of the time series, such as stock price prediction and trading strategy, optimization, and so on. However, in the actual application process, the stock price prediction of such models still has certain data quality, historical data market fluctuations, complex, non-linear data and other related factors, so there are certain challenges and development space in the process of processing.Nevertheless, by properly addressing these issues and combining them with best practices, LSTM algorithms are a powerful tool to help uncover underlying patterns in financial markets and optimize trading decisions.
Smart wearable devices have transformed how individuals track health and manage daily activities, providing real-time insights into vital signs and convenient fitness monitoring. Yet, these advancements come with challenges, including data privacy risks, measurement accuracy concerns, and potential over-reliance for health decisions. This study aims to balance the promise of health benefits and lifestyle convenience against these challenges. Limitations include evolving data security standards and measurement technologies, suggesting that future smart wearables should prioritize user safety through enhanced security and more robust health metrics.
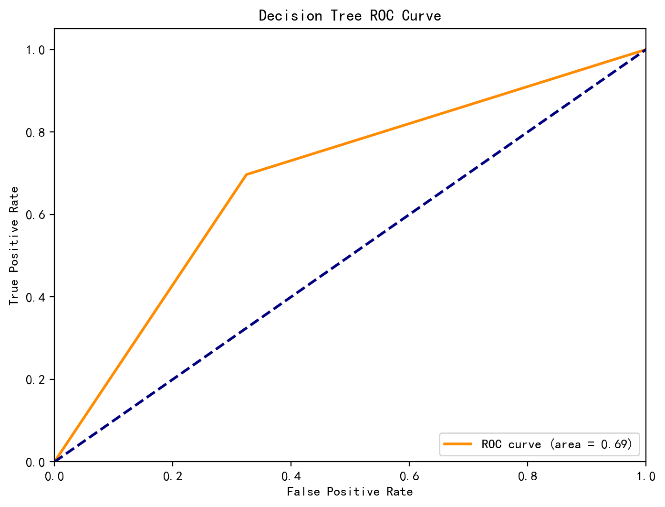
This study investigates the factors influencing student engagement and performance in online science education through the application of machine learning models, specifically Random Forests, Decision Trees, and Support Vector Machines (SVM). With the rapid growth of online education, understanding students' adaptability and learning behaviors has become increasingly critical. A systematic analysis of features such as study duration, daily study habits, and demographic factors revealed significant insights into their impact on academic achievement in science subjects. The Random Forest model outperformed others in classification accuracy, achieving an accuracy of 81%. The findings emphasize the importance of tailored educational strategies that foster consistent study practices and address the unique needs of diverse learners, ultimately enhancing learning outcomes in online science education.