


Volume 86
Published on August 2024Volume title: Proceedings of the 6th International Conference on Computing and Data Science
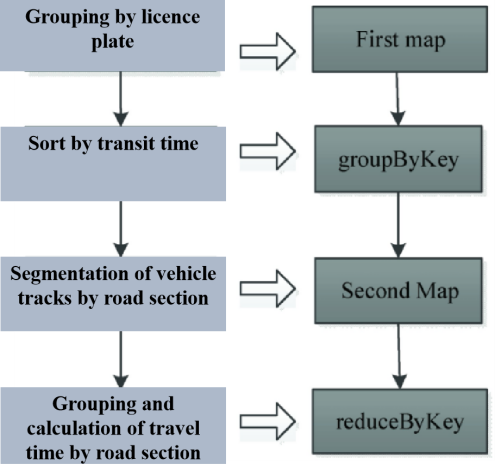
Spark and flink have made great strides in big data processing in recent years. Although the current spark can process a large amount of data at the same time, it still has a lot of shortcomings in the transparency, credibility, and practicality of the model. This paper provides a comprehensive overview of how to tackle the performance bottlenecks, insufficient model interpretability, and lack of regional adaptability faced by Spark and Flink in big data processing. It discusses the introduction of interpretable algorithms such as SHAP and LIME to enhance the transparency and user trust of neural network models. Then it discusses how to combine time-aware transfer learning and Geographic Information Systems (GIS) technology to enhance the technology generalization and adaptability of Spark machine learning models. Time-aware transfer learning uses historical data’s temporal evolution to ensure models perform well in new time periods or scenarios, while GIS technology enables more precise predictions and analyses based on geographical data, enhancing spatial adaptability. Lastly, the study explores hybrid processing strategies by integrating Apache Flink, Kafka Streams, and Spark batch processing frameworks. This approach not only facilitates efficient real-time data processing and detailed analysis but also enhances the model’s flexibility and processing capabilities in complex data scenarios. By integrating these techniques, it is possible to improve the efficiency and effectiveness of big data processing frameworks in addressing complex real-world challenges, thereby advancing technology and application development in related fields.



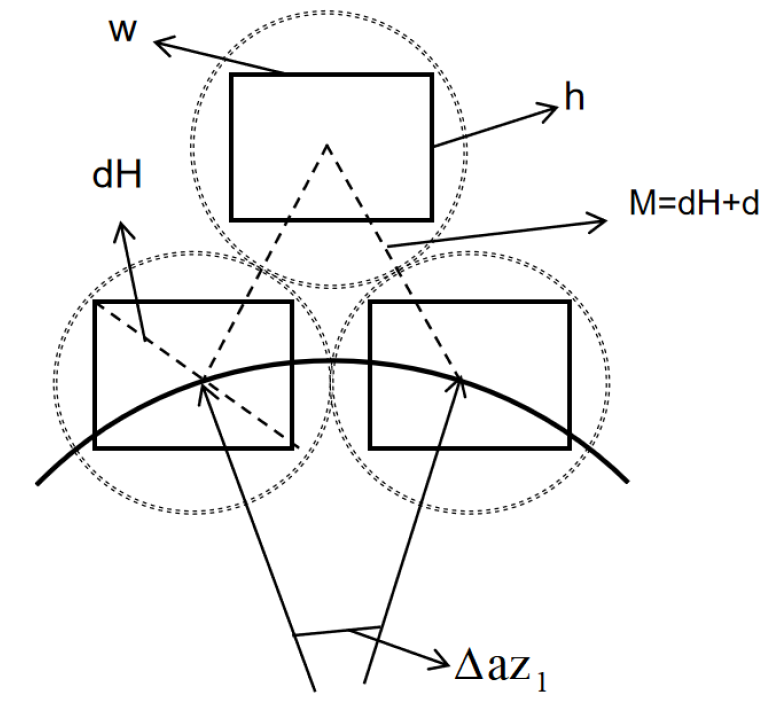
In today’s society, non-renewable resources are becoming increasingly precious, making the utilization and conversion of renewable resources more critical. Heliostat fields play a significant role in the actions taken by various countries to achieve ”carbon peaking” and ”carbon neutrality.” How can the installation and arrangement of heliostats maximize the annual average thermal power output per unit mirror area while achieving the rated power? This paper establishes an efficiency calculation model based on the flat-plate projection-Monte Carlo algorithm and an optimization design model of heliostat fields based on the gravitational search algorithm. The research progresses from shallow to deep, investigating methods to maximize the output thermal power under different constraints. First, it addresses the issue of maximizing the average thermal power output per unit mirror area under fixed heliostat field parameters and rated power conditions. Next, it solves the problem of maximizing the annual average thermal power output per unit mirror area under varying heliostat sizes and installation heights, with fixed rated power. Finally, it points out that the models established in this paper are applicable to complex real-world situations and can effectively improve the thermal efficiency of heliostat fields.

This study introduces a novel robotic system designed to aid individuals with Autism Spectrum Disorder (ASD) in enhancing their social communication and interaction skills. Incorporating advanced artificial intelligence, sensors, and image recognition technologies, the robot simulates human social interactions and provides tailored feedback, aiming to improve the quality of life for individuals with ASD. Through a detailed examination of hardware design, software functionalities, and data processing mechanisms, this paper evaluates the system's practical applications and identifies ongoing challenges and potential improvements. The findings suggest that while the robotic system significantly enhances social interaction and learning for autistic individuals, challenges such as technological adaptability, cost, and physical design require further innovation. This research contributes to the field of assistive technologies by offering insights into how robotic systems can be optimized to meet the unique needs of the autism community, thus paving the way for more effective therapeutic tools.
High-frequency trading is derived from programmatic trading and market maker mechanisms, and unlike low-frequency trading, it uses ultra-high-speed computers to acquire and analyze high-frequency trading data in the market, so as to identify price change patterns and quickly execute trades to complete the change of hands. In this work, we focused on optimizing high-frequency trading strategies using deep reinforcement learning. Specifically, we employ a dual deep Q network model, which consists of two deep neural networks that are used to generate action value estimates and provide target action values, respectively. The advantage of this structure is that it reduces bias in the estimation process, thereby improving the stability and efficiency of learning. The input layer of the model receives multi-dimensional features of market data, such as price, volume, order depth, etc., which are normalized and then fed into the network. The hidden layer includes multiple layers of fully connected layers to enhance the nonlinear representation of the model and the ability to handle complex market dynamics. We have also introduced batch normalization and dropout layers in the network to prevent overfitting merges and improve the generalization ability of the model. Eventually, the output layer generates action values corresponding to each possible trading action, deciding to buy, sell, or hold a position. In the experimental analysis, this study verifies the superiority of the proposed model in processing high-frequency trading data and executing trading decisions by comparing it with traditional trading strategies and other machine learning methods.
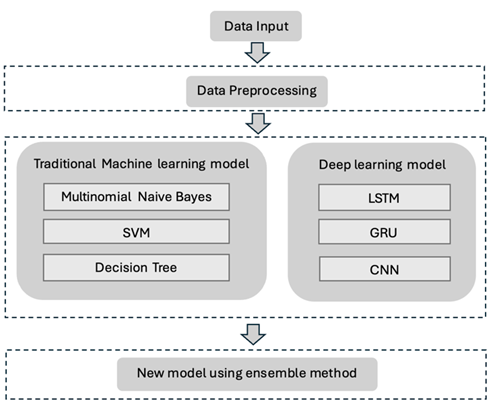
Social media provides people with a platform to share their experiences and perspectives, and text is the most common way as either posts or comments. Much emotion-related information, such as mental state and attitude, can be revealed through texts. As a result, text-based emotion analysis plays an important role. This paper aims to propose a new classification model using the ensemble learning method, which can classify the emotions detected from the text into six classes, including joy, fear, surprise, love, sadness, and anger. Multiple base models are trained at the first stage, including traditional machine learning models (Multinomial Naive Bayes, SVM, and Decision Tree) and deep learning models (CNN, LSTM, and GRU). Then, a new ensemble model using the stacking method is developed. The stacking of deep learning models and SVM has achieved the best classification performance, where the accuracy and F1 score are 0.8875 and 0.8410, respectively. The evaluation metrics demonstrate the effectiveness and robustness of the new ensemble model for this emotion classification task.
This paper establishes a calculation model for the coverage width and overlap rate of a multi-beam survey line system [1], and optimizes the multi-beam bathymetric survey plan for marine areas. Through the dynamic programming algorithm, a reasonable survey line plan is designed based on the actual marine area depth. The research content includes: Model Establishment: Construct a calculation model for coverage width and overlap rate, determining the coverage width and overlap rate at each position. Three-Dimensional Space Model: Using the survey vessel as the origin and combining marine area information, solve for the coverage width at different angles. Shortest Survey Line Plan: Using the dynamic programming algorithm, determine the shortest survey line plan, with the dynamic transfer equation determined by the overlap rate index. The total length of the survey line in this plan is calculated to be 114,824 meters. Specific Survey Line Plan Design: Using sea depth data and cubic spline interpolation to complete the discrete point plane, construct approximate width and slope. Under the condition of relaxing the overlap rate to 5%-30%, the shortest survey line length is obtained as 398,059 meters, with a missing survey area ratio of 0%, and the total length of parts with an overlap rate exceeding 20% is 25,759 meters, accounting for 6.4%. This study provides theoretical basis and calculation methods for optimizing multi-beam bathymetric survey plans.
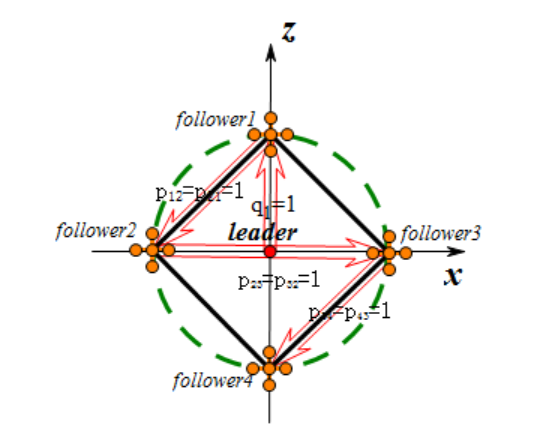
This paper addresses the formation control system for multi-quadcopter UAVs, proposing a control strategy based on finite-time stability theory. It designs position controllers with a dual power structure and attitude controllers combined with non-singular terminal sliding mode to achieve fast convergence and high-precision tracking. Through Lyapunov stability analysis, the paper proves the finite-time convergence of the control strategy. Simulation experiments validate the method's excellent performance in formation establishment, maintenance, and complex trajectory tracking, demonstrating rapid convergence, high precision, and strong disturbance rejection capabilities. This research provides theoretical and technical support for cooperative control of multi-quadcopters.
With the development of the Internet and the continuous improvement of the information disclosure mechanism of the securities market, individual investors have more and more ways to obtain investment information, including company research reports from analysts. However, analysts have mixed qualifications and publish a huge number of reports. For retail investors, how to analyze and distinguish these reports and make informed investment decisions based on them has become the key to profiting in a securities market where information is asymmetrical and risks and opportunities coexist. This is a priority that every retail investor should prioritize. In recent years, machine learning has become increasingly widely used in the financial sector, especially in the prediction of return on investment. In this work, a most advanced machine learning model Transformer is used, which is widely used in a variety of scenarios due to its advantages in processing sequence data. The Transformer model can effectively process and analyze large-scale financial time series data through the self-attention mechanism to capture subtle fluctuations and potential correlations in the market. We designed a Transformer-based architecture to combine multi-source data such as market macroeconomic indicators, stock trading data, and social sentiment analysis for comprehensive learning. Experimental results show that the model significantly improves the accuracy of investment return prediction and provides investors with efficient analysis tools.
With the rapid development of online social networks, the research on group decision-making in social networks has attracted extensive attention. Social networks facilitate interaction and behavior between individuals, businesses, and organizations. However, traditional group decision-making methods often ignore the social relationships between group members and fail to fully consider the impact of these relationships on subgroup division. In this work, we propose a novel model approach that combines graph neural networks and deep learning techniques to capture and analyze complex relational structures in social networks. The model uses node features and edge features to optimize the group decision-making process and effectively evaluate the influence between individuals through multi-layer network embedding and aggregation operations. Experimental analysis results show that the proposed method performs well in improving the accuracy and efficiency of decision-making, and significantly improves the quality of decision-making.
Alzheimer's Disease (AD) causes memory decline beyond normal aging and is the most common cause of dementia. Early detection and intervention can delay the progression of AD and alleviate symptoms. However, high expense, insensitivity, and inconvenience are among various deterrents to traditional diagnosis methods. Dementia impacts more than 55 million people globally, with this number set to double every 20 years. Much of this increase will be in low- and middle-income countries which often lack the resources for early diagnosis. Recently speech has emerged as an effective digital biomarker for AD detection. However, most studies in this area are limited to English speech due to lack of suitable data in other languages. This study aims to construct a speech-based classifier (VoiceAD) that can be trained on English data and still maintain its performance on other languages. Acoustic features were extracted from English, Spanish, and Greek data from DementiaBank with the eGeMAPS v2.0 feature set. Subsequently, an Extra Trees model was employed for classification. VoiceAD’s performance for English and Greek surpassed that of the baseline model and model incorporating only demographic data while the Spanish performance was lower due to task effect. In addition, VoiceAD’s satisfactory generalizability and interpretability positions it as a promising candidate for clinical applications. It can be implemented as a free screening tool such as a mobile application to monitor AD risk. VoiceAD’s crosslingual applicability can its enable worldwide deployment, especially in settings where traditional methods of diagnosis are less attainable.