


Volume 88
Published on October 2024Volume title: Proceedings of the 6th International Conference on Computing and Data Science
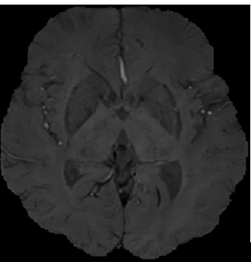
Cerebral microbleeds (CMB) is an important type of cerebral microbleeds. In recent years, many studies have proved that CMB can not only cause vascular dementia, but also increase the risk of stroke. Therefore, detection of CMB is of great clinical significance for balancing antithrombotic therapy and risk assessment in stroke patients, and detection of CMB is of great value for diagnosis and prognosis of cranial injury. This paper mainly proposes a two-stage CMB detection framework based on deep learning, which includes the screening stage of brain microhemorrhagic candidate points and the recognition stage of brain microhemorrhagic points based on deep learning. Firstly, in the first stage, we screened CMB candidate points by combining rapid radial transformation and threshold segmentation, and excluded a large number of background regions and obvious non-CMB regions. Then, in the second stage, the two-channel images spliced by sensitivity weighted imaging (SWI) and phase diagram (Pha) were used for false positive judgment by 3D convolutional neural network to distinguish the true CMB from the CMB analog.



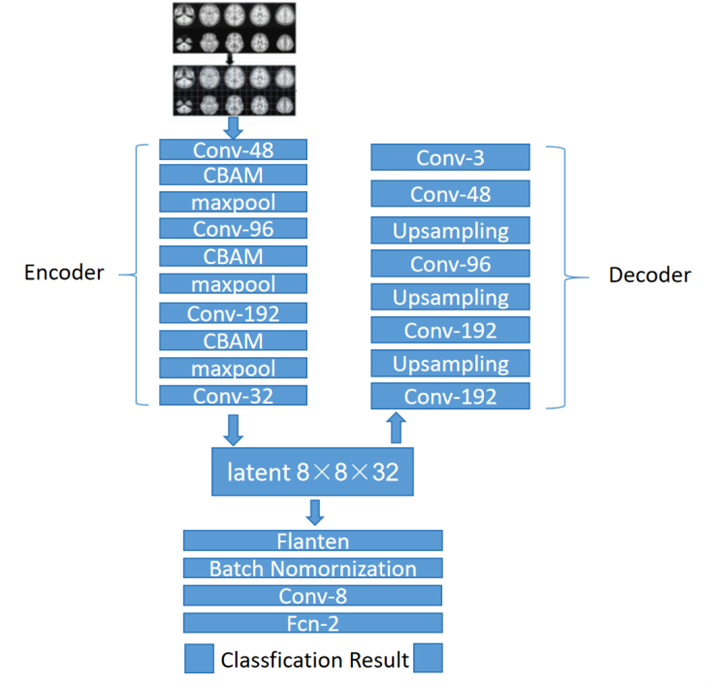
This work presents a novel method for leveraging resting-state functional magnetic resonance imaging (fMRI) data to accurately detect Attention Deficit Hyperactivity Disorder (ADHD). The proposed method integrates the Convolutional Block Attention Module (CBAM) with a lightweight Autoencoder network to effectively extract and highlight salient features within fMRI scans. By leveraging attention mechanisms, the model focuses on important local details while filtering out irrelevant information, thereby enhancing diagnostic precision. Extensive experimentation on the ADHD-200 dataset showcases the efficacy of the proposed approach, demonstrating its ability to improve classification performance significantly. Specifically, the method achieved an average accuracy of 91.7% across the NYU, 93.8% across the KKI, 86.4% across the NI, 89.1% across the PU, and 83.5% across the PU_1 datasets. This research underscores the potential of attention-based deep learning techniques in advancing ADHD diagnosis using neuroimaging data.
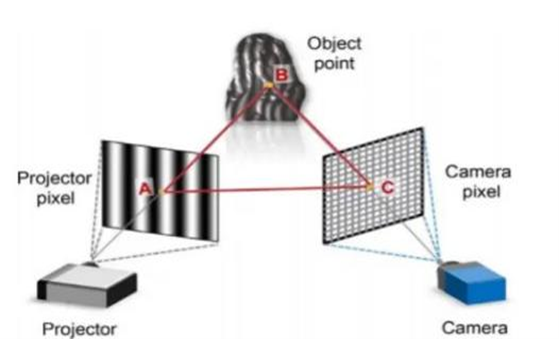
This paper investigates the impact of camera image signal processing (ISP) algorithms on stripe structured light 3D reconstruction and explores the improvement of 3D reconstruction accuracy by photon input. Existing 3D reconstruction technologies have broad applications in fields such as intelligent manufacturing, healthcare, and consumer electronics, but their high precision requirements often cannot be met by current ISP algorithms. By using handheld devices to capture images and combining key techniques such as the multi-step phase shifting method, multi-frequency phase unwrapping method, and triangulation method, this paper conducts an in-depth study on the application of photon input in 3D reconstruction. The study demonstrates that using non-visual information (RAW images) as input can significantly improve reconstruction accuracy, producing more accurate results compared to images processed by ISP. The paper also quantifies the impact of ISP processing on 3D reconstruction results by comparing the depth information and point cloud data of two sets of images. Experimental results show that disabling certain ISP algorithms, such as bilateral noise filtering (BNF), edge enhancement (EEH), and non-local means denoising (NLM), can further improve reconstruction accuracy and reduce errors. In conclusion, this paper proposes a photon image-based 3D reconstruction method that, combined with artificial intelligence technology and differentiable point cloud rendering techniques, holds promise for achieving higher precision and faster 3D reconstruction. This technology is of great significance in practical applications, particularly in the field of industrial close-range 3D reconstruction.
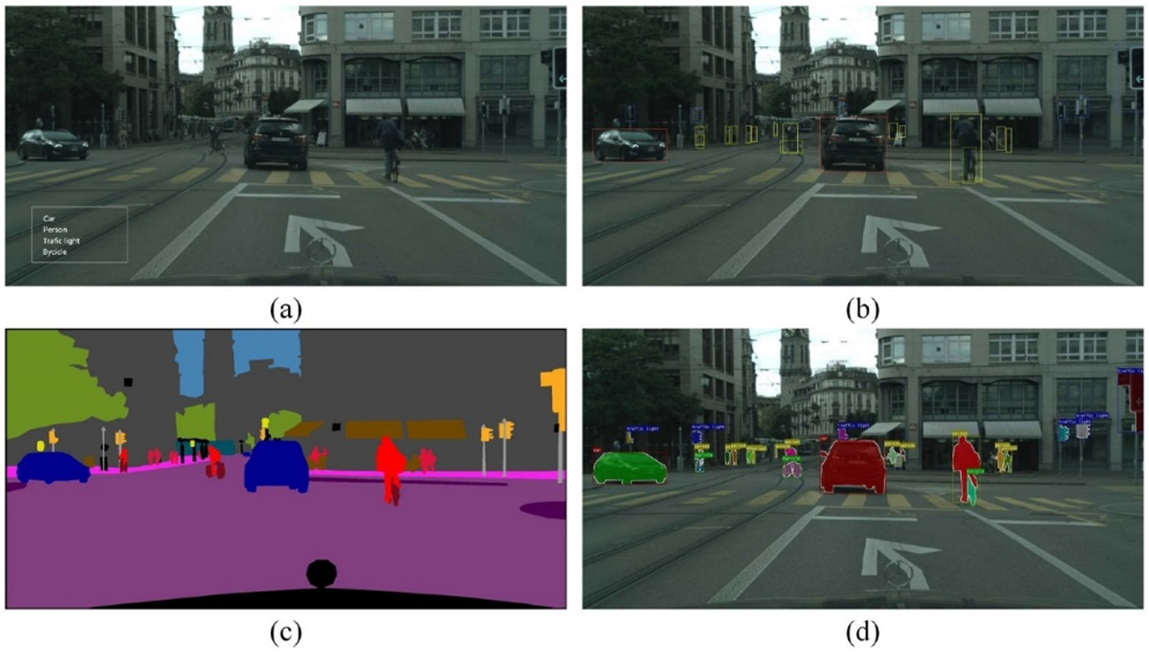
The application of computer vision analysis technology based on traditional image analysis and machine learning techniques in the field of vehicle detection is the focus of this paper. This paper fills the gap in previous research and provides a comprehensive overview and comparison of vehicle detection models based on computer vision analysis. This paper first briefly outlines the goals of vehicle recognition, evaluation indicators of models, and widely used datasets; then, it summarizes vehicle detection models based on traditional image processing techniques and machine learning techniques. Finally, the advantages and disadvantages of various models and sensors are discussed, and potential future development directions are proposed.
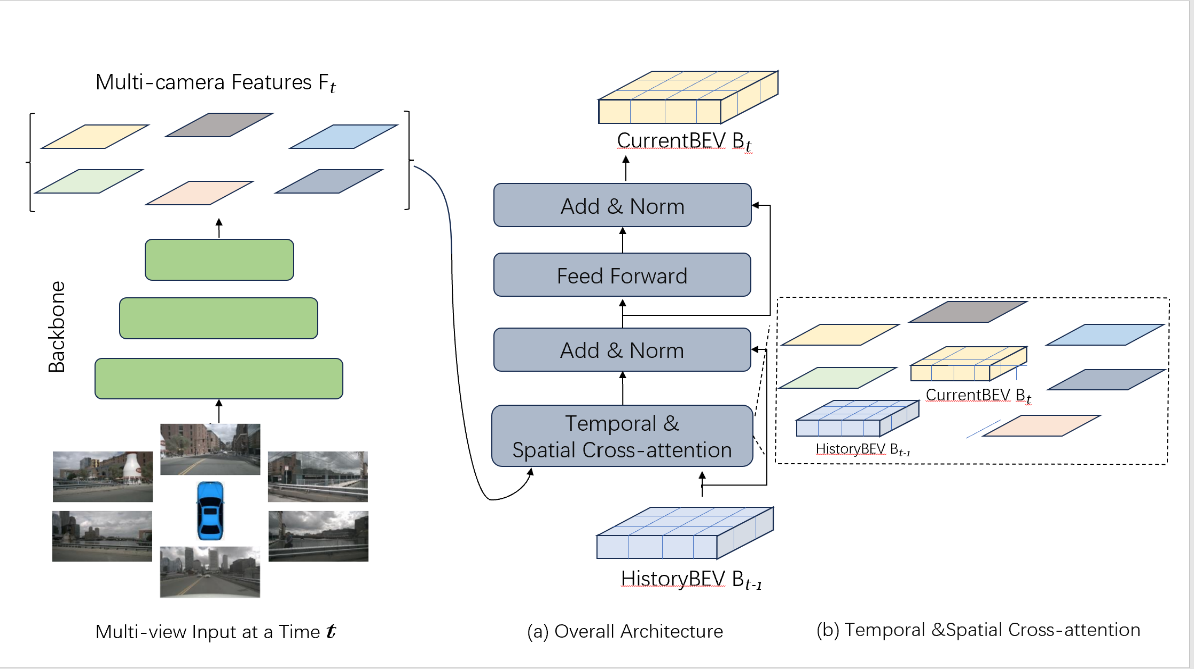
This paper presents a novel 3D object detection algorithm designed for Bird's Eye View (BEV) scenarios, which significantly improves detection capabilities by integrating spatial and temporal features. The core of our approach is the spatial-temporal alignment module that efficiently processes information across different time steps and spatial locations, enhancing the precision and robustness of object detection. We employ a temporal self-attention mechanism to capture the motion information of objects over time, allowing the model to correlate features across various time steps for identifying and tracking moving objects. Additionally, a spatial cross-attention mechanism is utilized to focus on spatial features within regions of interest, promoting interactions between features extracted from camera views and BEV queries. Our method also implements temporal feature integration and multi-scale feature fusion to enhance detection stability and accuracy for fast-moving objects and to capture multi-scale context information, respectively. The model employs an enriched feature set post alignment for 3D bounding box prediction, ascertaining the position, dimensions, and orientation of objects. We conducted experiments on two public datasets for autonomous driving – nuScenes and Waymo Open Dataset, demonstrating that our method outperforms previous BEVFormer and other state-of-the-art methods in terms of detection accuracy and robustness. The paper concludes with potential future directions for optimizing the BEVFormer model's performance and exploring its application in broader scenarios and tasks.
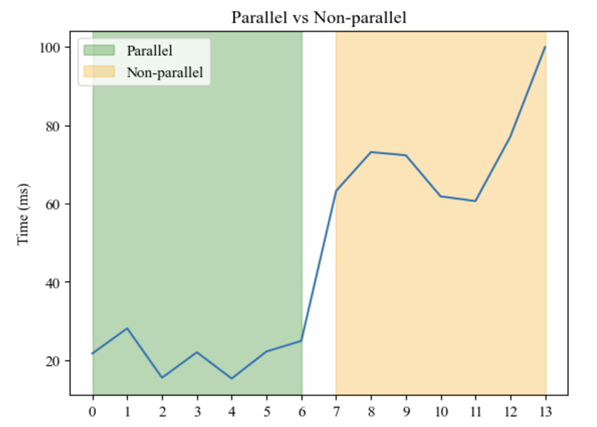
In the context of the current era of big data, traditional Hadoop and cluster-based MapReduce frameworks are unable to meet the demands of modern research. This paper presents a MapReduce framework based on the AliCloud Serverless platform, which has been developed with the objective of optimizing word frequency counting in large-scale English texts. Leveraging AliCloud's dynamic resource allocation and elastic scaling, we have created an efficient and flexible text data processing system. This paper details the design and implementation of the Map and Reduce phases and analyses the impact of vCPU and memory specifications, as well as parallel resource allocation on system performance. Experimental results show that increasing vCPU specifications significantly improves processing capacity and execution efficiency. While the impact of memory specifications is relatively minor, it can positively influence performance in specific scenarios. Parallel processing markedly enhances system performance. Experiments on "Harry Potter and the Sorcerer's Stone" validate the framework's performance across various configurations. This study offers valuable insights for the design and optimization of serverless-based MapReduce frameworks, as well as suggesting future enhancements. These include the implementation of advanced parallel computing strategies, improved error handling, and refined data preprocessing, which collectively aim to boost system performance and stability.

The orchard has always been an important scene for citrus pickers, and the existence of factors such as leaf occlusion and color similarity always lead to the difficulty of robot recognition. Based on a citrus image dataset collected from actual orchard scenes, we extract image features and build a mathematical model to identify and count the number of oranges in each image, and show the distribution of apples in the entire dataset. Firstly, this paper establishes a model based on HSV method, focusing on recognizing yellow citrus. Secondly, with the further analysis of the data set, it is found that the cyan citrus exists. Therefore, this paper defines the empirical HSV range of two kinds of citrus at the same time and introduces contour processing to optimize the model. In order to accurately distinguish the immature citrus from the leaves with similar colors and the citrus occluded by leaves, this paper uses more detailed color threshold setting and morphological operation, and makes the eccentricity of the contour less than 0.85. At the same time, considering the size and overlap of citrus, morphological operations such as dilation and erosion and contour detection techniques are applied to further improve the recognition ability of the model. Finally, the experimental results show that the average accuracy of the established model reaches 92.1%, which has a good recognition effect on citrus.
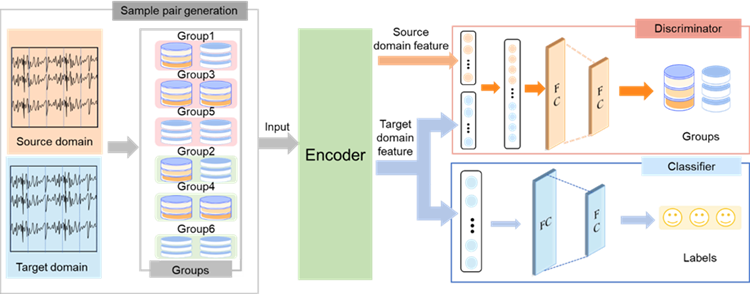
With the development of cognitive computing and intelligent media communication, recognizing the user’s emotion using electroencephalography (EEG) has garnered increasing attention. However, building a cross-subject emotion recognition model with good generalization performance is really difficult. To achieve remarkable performance, a label-refined domain adversarial neural network is designed and EEG samples are subdivided into 6 groups according to the differences in users' brain activities under different movie stimuli. Based on the experiment of SEED and SEED-IV datasets, the classification accuracy of our method reaches 93.35±4.14% and 84.08±6.01%, achieving the state-of-the-art performance. Experiments show that using different movie stimuli to refine labels can achieve efficient cross-subject emotion recognition.
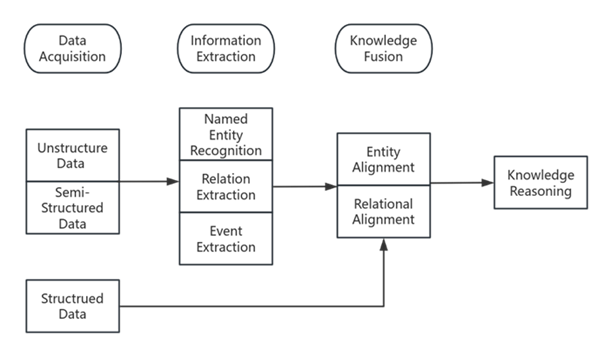
A large amount of drug and disease research knowledge is scattered in unstructured literature data, presenting significant challenges in text mining within the field of biomedicine. These challenges include handling professional knowledge, integrating related knowledge, and disambiguating different meanings of the same words. Therefore, constructing a biomedical knowledge graph can significantly save expert human resources and make efficient use of medical literature resources. This review paper aims to summarize the construction methods used during the development of Biomedical Knowledge Graphs. It also outlines the latest models and frameworks, such as BioBERT and LSTM+CRF, highlighting their contributions and applications. In addition, this paper points out the limitations of current biomedical knowledge graphs, such as scalability issues and the need for large annotated datasets. To address these limitations, it proposes the use of Apache Spark for improved processing capabilities and transfer learning to enhance model performance and adaptability in diverse biomedical contexts.