


Volume 170
Published on June 2025Volume title: Proceedings of the 9th International Conference on Economic Management and Green Development
Recent advancements in artificial intelligence (AI) have fundamentally transformed credit management and risk assessment paradigms within the financial sector. Contemporary research demonstrates that machine learning algorithms, particularly deep neural networks, outperform traditional statistical methods by 18-22% in predictive accuracy metrics (F1-score) across credit scoring applications. This performance advantage stems from AI's capacity to process heterogeneous data streams - including transactional records, alternative credit data, and behavioral patterns - through sophisticated feature extraction techniques. However, the implementation of these systems introduces complex operational challenges. Foremost among these is the substantial data requirement: typical risk assessment models now train on datasets exceeding 10 million observations, raising significant concerns regarding GDPR compliance and consumer privacy protections. Equally problematic is the persistence of algorithmic bias, with recent audits revealing demographic disparities exceeding 15% in approval rates for statistically identical applicants. Emerging mitigation strategies employ multi-objective optimization during model training, incorporating fairness constraints alongside accuracy metrics. Technological solutions such as federated learning architectures and homomorphic encryption show particular promise, enabling decentralized model training while maintaining data confidentiality. The field now faces critical questions regarding model interpretability, with regulators increasingly mandating explainable AI (XAI) standards for financial decision systems. Hybrid approaches combining symbolic AI with neural networks represent a promising research direction. These developments suggest that future AI-driven risk management systems must balance three competing priorities: predictive performance, regulatory compliance, and ethical considerations - a challenge that will require close collaboration between data scientists, policymakers, and financial institutions to resolve effectively.



With the continuous expansion of credit scale and the complexity of financial risks, traditional credit default prediction models are difficult to meet the needs of accurate prediction of potential default users due to unbalanced data, low feature screening efficiency and insufficient interpretability. Based on the above problems, this paper uses the SMOTE method to deal with the problem of data imbalance, analyzes the correlation between the characteristic variables and the target variables, and finally compares the performance of the six models. Using AUC, Accuracy, precision, and recall as evaluation indicators, it was found that people who rented houses, had a history of default, had a high proportion of loans to income, had high interest rates, and had existing debts were more likely to default. In the experiment, the SMOTE-XGBoost combination has outstanding performance, which can solve the imbalance in the data set, capture more potential defaulting users, and provide a more effcient and accurate model for the financial industry.
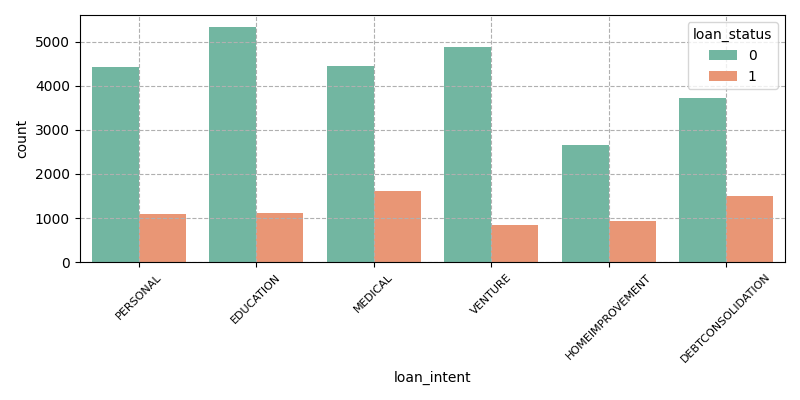
Currently, major banks are encountering significant challenges in a highly competitive environment characterized by declining interest rates and the underperformance of traditional marketing strategies. These challenges include customer churn, insufficient appeal to new customers, reduced profitability, lower marketing success rates, and increasing marketing costs. To enhance the effectiveness of bank marketing and reduce associated costs, this study leverages the bank marketing data set from Alibaba Cloud Tianchi. It introduces and analyzes key parameter concepts within the data set and performs data cleaning. After evaluating various models and employing research methodologies such as feature selection, imbalanced data handling, and correlation analysis, the XGBoost model combined with the RandomUnderSampler method for addressing data imbalance was selected. The findings indicate that, compared to traditional models, this approach achieves higher precision, recall, and accuracy rates. Furthermore, considering the primary objective of bank marketing and prioritizing recall rate, this method attains a recall rate of 84.3% for marketing customers within the data set. Consequently, this approach holds substantial significance for banks in predicting customer deposit demands and optimizing deposit marketing strategies, thereby assisting banks in reducing marketing costs and enhancing marketing success rates.
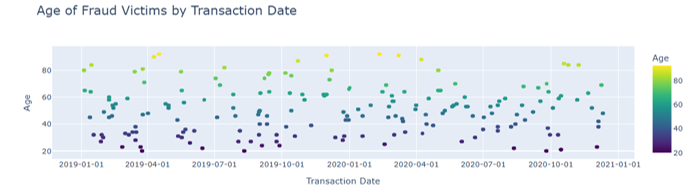
This study analyzes 14,446 credit card transaction records from the western US to build a high-precision fraud detection system. Visual methods explore relations between transaction traits and fraud. "grocery_pos" and "shopping_net" are fraud-prone; CA has more frauds, with low-value transactions. People around 50 are at higher risk. Credit card fraud, different from traditional fraud, focuses on shopping. Random forest and logistic regression work well, with random forest at 98.26% accuracy. The project uses integrated models to offer real-time detection. In the dynamic environment of financial crime investigation, the strategies adopted by fraudsters are constantly evolving, which requires continuous improvement of analytical methods. Traditional rule - based fraud detection methods often fail to adapt to evolving fraud patterns, necessitating data-driven approaches to identify complex, non-linear relationships in transaction data. This dual-focus on model comparison and visual-analytic integration distinguishes the study, offering actionable insights for combating dynamic fraud patterns. Future plans include using multidimensional data and graph neural networks for better risk control.
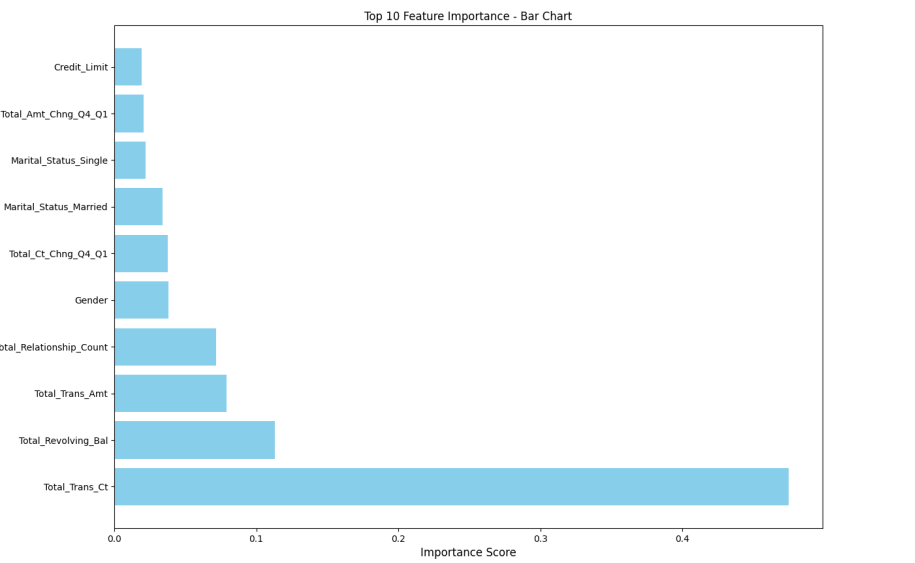
In the highly competitive banking sector, customer churn significantly impacts profitability and market share. This study develops an effective machine learning framework for predicting customer churn, combining advanced algorithms with data preprocessing techniques. The proposed approach employs Random Forest as the primary classifier, integrated with SMOTE-ENN hybrid sampling to address class imbalance, and incorporates feature selection methods to identify key predictors. Experimental results demonstrate that this combination achieves superior performance in churn prediction compared to conventional methods. The analysis reveals that customer tenure, income level, transaction frequency, and service interaction patterns are among the most influential factors affecting churn behavior. These findings provide actionable insights for banks to implement targeted retention strategies, such as personalized engagement programs and proactive service interventions. The framework offers financial institutions a data-driven tool to enhance customer relationship management, optimize resource allocation for retention efforts, and ultimately improve business sustainability. By bridging the gap between predictive analytics and practical decision-making, this research contributes to both academic knowledge and banking industry practices in customer churn management. The study's methodology and findings can be extended to other financial services and subscription-based business models facing similar churn challenges.
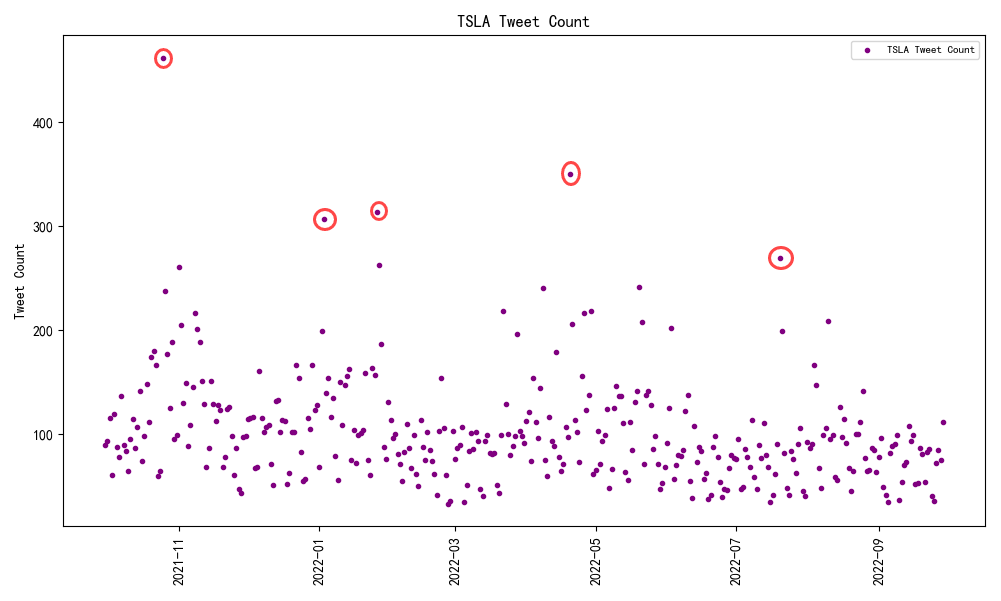
This study aims to explore the impact of social media sentiment on stock price fluctuations.A dataset from Kaggle was used, which contains tweets related to the 25 most followed stocks on Yahoo Finance from September 30, 2021 to September 30, 2022,along with stock market prices and trading volume data corresponding to those dates and stocks.X was selected as the primary subject of investigation in terms of social media,by analyzing the number of tweets during the corresponding period, the sentiments expressed, and the rise or fall of the associated company stocks mentioned in those tweets,to investigate whether a correlation exists between social media sentiment and stock price changes.The results show that there is a correlation between tweet sentiment scores and stock price movements,where positive sentiment scores are strongly correlated with stock price increases, and negative sentiment scores are strongly correlated with stock price decreases.However, the influence of sentiment on stock prices is limited; although there is a certain positive relationship, the fluctuations are large and sentiment alone is insufficient as an independent predictive indicator,and needs to be analyzed in conjunction with other key factors. These results suggest that the intensity of social media sentiment has a certain impact on stock price rises and falls.These findings provide a new perspective for understanding the factors behind stock price changes and offer important references for investor decision-making.
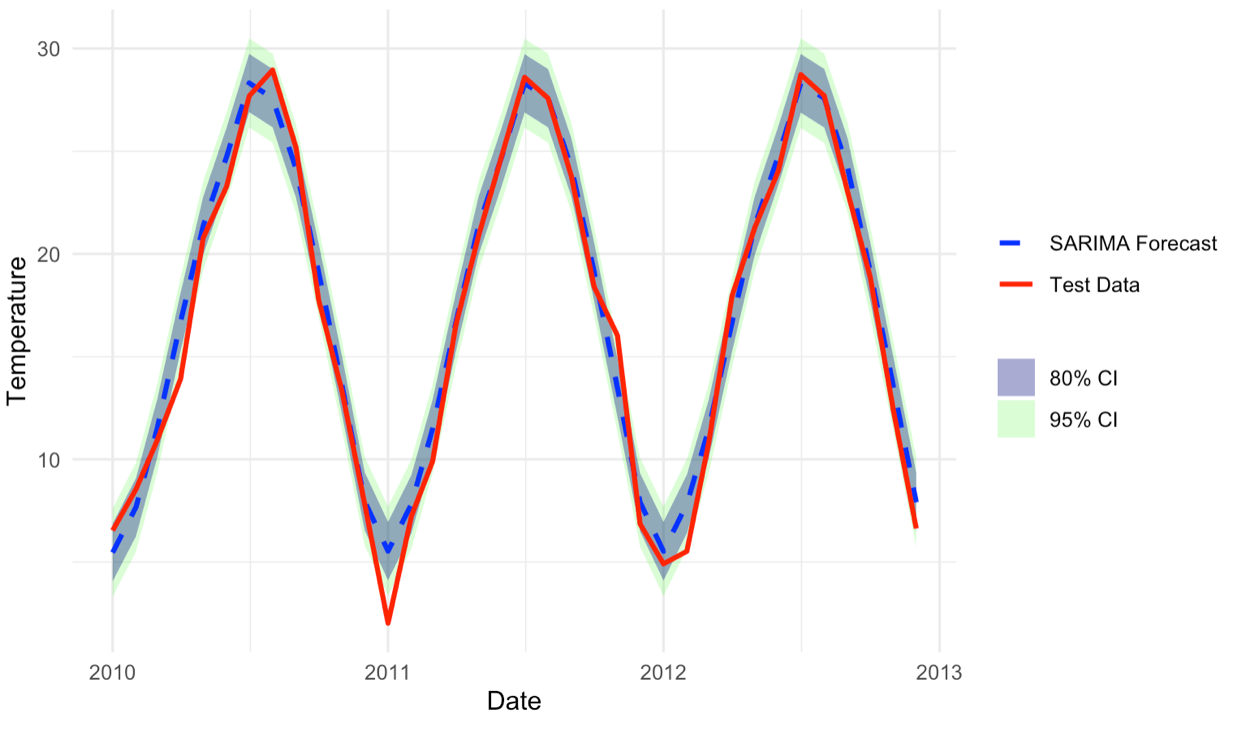
This study employs the Seasonal Autoregressive Integrated Moving Average (SARIMA) model to analyze and forecast China’s monthly average temperature data from January 1990 to December 2010, using data from 2011 to 2013 as the test set. The objective is to explore temperature trends and provide a scientific basis for short-term temperature forecasting. Compared with the standard ARIMA model, SARIMA is more effective in modeling data with seasonality. Since the original dataset meets the stationarity requirements, it was directly used for model fitting. The model parameters—including autoregressive, moving average, seasonal autoregressive, and seasonal moving average terms—were automatically selected using R code to ensure accurate fitting of the temperature time series. The results show that the SARIMA model effectively captures both seasonal fluctuations and long-term trends in temperature, yielding reliable short-term forecasts. The final model, , achieves a Mean Absolute Percentage Error (MAPE) of 8.37% on the test set, meeting the expected level of predictive accuracy. The model's forecasting capability offers valuable support for climate policymaking, adaptive strategies to climate change, and sustainable development planning.
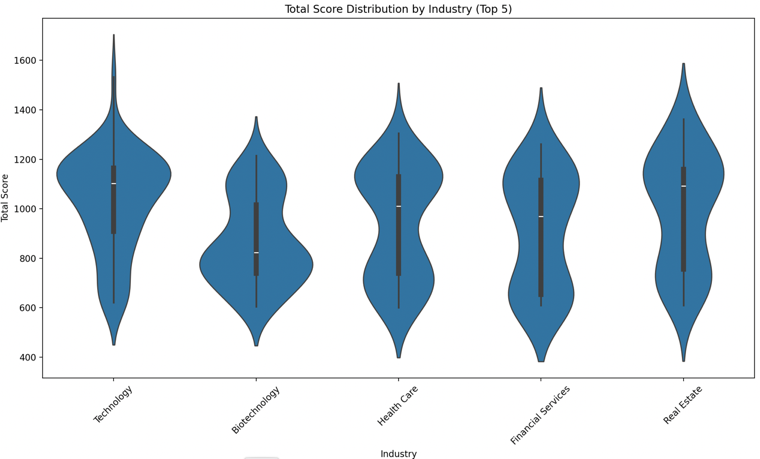
This study proposes a dynamic assessment framework based on gradient boosting model optimization, which aims to address the core challenges of inefficient modeling of discrete features, insufficient model dynamics, and algorithmic ethical risks in ESG ratings. The dynamic feature engineering by integrating the embedding layer and adaptive sub-boxing, combined with incremental learning and integration strategies, significantly improves the characterization efficiency of high-dimensional sparse features and the real-time response capability of the model. Blockchain technology is introduced to ensure data credibility, and the model robustness is strengthened by Stacking and SMOTE to provide technical support for risk pricing and compliance decision-making of green financial instruments. The empirical results show that the optimized framework has significant advantages in terms of dynamic adaptability, feature processing efficiency, and ethical constraints, which promote the scale application of ESG assessment technology in complex financial scenarios. Its dynamic data flow integration and Stacking integration strategy significantly improve the accuracy of portfolio risk management and help financial institutions optimize ESG investment strategies.
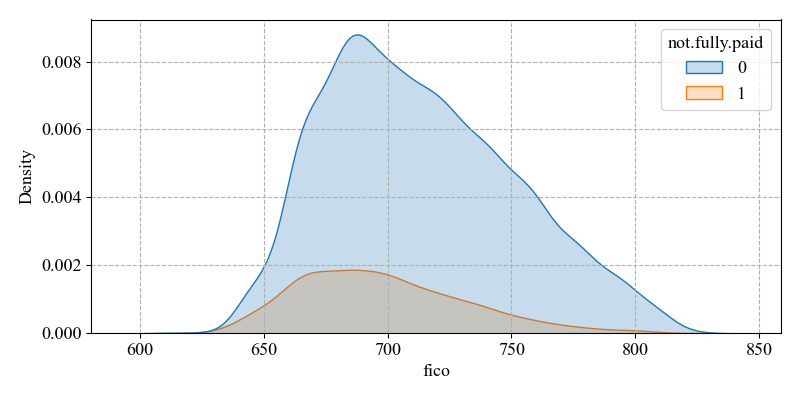
In order to reduce the risk of default, machine learning techniques are relied upon to build models to predict defaults. This study focuses on the problem of default prediction in the credit market, based on the Lending Club dataset. And based on feature screening and relevance ranking, the features related to default are obtained and again analysed in detail with knowledge of economics. A variety of machine learning models LogisticRegression, DecisionTreeClassifier, RandomForestClassifier, GradientBoostingClassifier, XGBoost, AdaBoost, Bagging were also used for training and comparison, followed by further optimisation of model performance through data balancing methods such as SMOTE, ADASYN, RandomOverSampler, RandomUnderSampler, SMOTEENN, SMOTETomek. The study discovered that loan interest rate, the number of times the borrower has been queried in the last six months, the credit score, and the monthly installments owed by the borrower had a strong effect on the target variable and were able to make a good prediction of defaults. The GBDT model based on boosting algorithm is trained better. And it is further improved with the balance of RandomOverSampler which has the most significant optimisation results. This study will focus on the above aspects to improve the accuracy of credit default prediction so as to improve credit risk prevention and control.
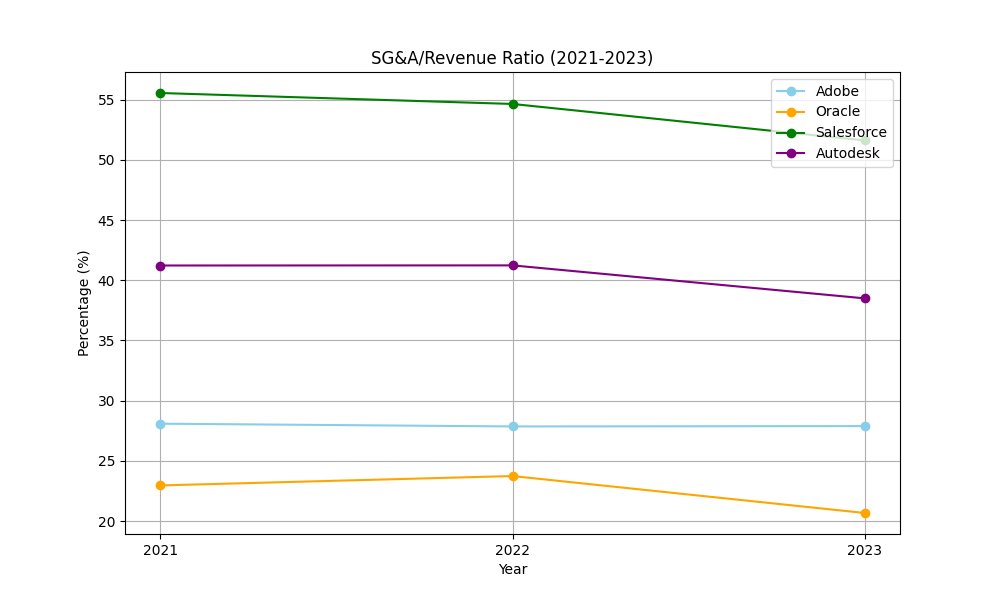
In the contemporary global economic landscape, the technology sector has emerged as a pivotal force, driving innovation and economic growth. Adobe, Oracle, Salesforce, and Autodesk stand out as prominent players, each with its own unique business models, product portfolios, and market positions. This study evaluates the investment potential of four leading software companies—Adobe, Oracle, Salesforce, and Autodesk—through a comprehensive analysis of their financial performance, competitive advantages, and external influences. Using financial metrics such as return on equity (ROE), free cash flow (FCF), and price-to-earning (P/E) ratios, alongside competitive frameworks like Porter’s Five Forces and SWOT analysis, the research identifies Adobe as the most promising long-term investment due to its stable growth and AI-driven innovation. Oracle is recommended for income-focused investors due to its dividend stability. The study also examines macroeconomic factors, such as interest rates, and regulatory pressures, like data privacy laws, that impact these firms. The findings further suggest that while each company has its strengths and opportunities, they also face distinct challenges. For instance, Adobe's high valuation and dependence on specific product segments pose risks, while Oracle must navigate the complexities of its cloud transition. Salesforce needs to manage its costs and translate investments into profitability, and Autodesk must address its narrow product focus and competition from new entrants. Limitations of this paper include reliance on historical data and assumptions about market stability. Future research could explore AI ethics and emerging competitors.