


Volume 158
Published on May 2025Volume title: Proceedings of CONF-SEML 2025 Symposium: Machine Learning Theory and Applications
This paper systematically investigates the co-evolution of adaptive optimization algorithms and deep learning architectures, analyzing their synergistic mechanisms across convolutional networks, recurrent models, generative adversarial networks, and Transformers. The author highlights how adaptive strategies—such as gradient balancing, momentum acceleration, and variance normalization—address domain-specific challenges in computer vision, natural language processing, and multimodal tasks. A comparative analysis reveals performance trade-offs and architectural constraints, emphasizing the critical role of adaptive optimizers in large-scale distributed training and privacy-preserving scenarios. Emerging challenges in dynamic sparse activation, hardware heterogeneity, and multi-objective convergence are rigorously examined. The study concludes by advocating for unified theoretical frameworks that reconcile algorithmic adaptability with systemic scalability, proposing future directions in automated tuning, lightweight deployment, and cross-modal optimization to advance AI robustness and efficiency.



This paper systematically analyzes multivariate methods for high-dimensional matrix computation and their optimization strategies for applications in finance. At the level of high-dimensional computation, it focuses on the technical characteristics of direct methods, iterative methods , and randomized algorithms , which reveal their efficiency gains in financial derivatives pricing, risk matrix modeling, and other scenarios. For serverless architecture, the study focuses on its core advantages of elastic scaling and on-demand billing, through parallel task slicing and cost optimization, while analyzing the limitations of its stateless design on the adaptation of iterative algorithms and the constraints of cold-start latency on high-frequency trading. In addition, the article delves into the special challenges of financial modeling, including the cubic complexity pressure of high-dimensional operations, real-time conflicts of missing data interpolation, and privacy compliance requirements, and discusses hybrid architectures (serverless with local GPU synergy) and middleware (Redis, AWS Step Functions) as the current transitional solutions for balancing efficiency and state. The research also addresses the challenges of nonlinear dynamic modeling and interpretability requirements for machine learning-driven models, providing a multidimensional analytical framework for technology adaptability.
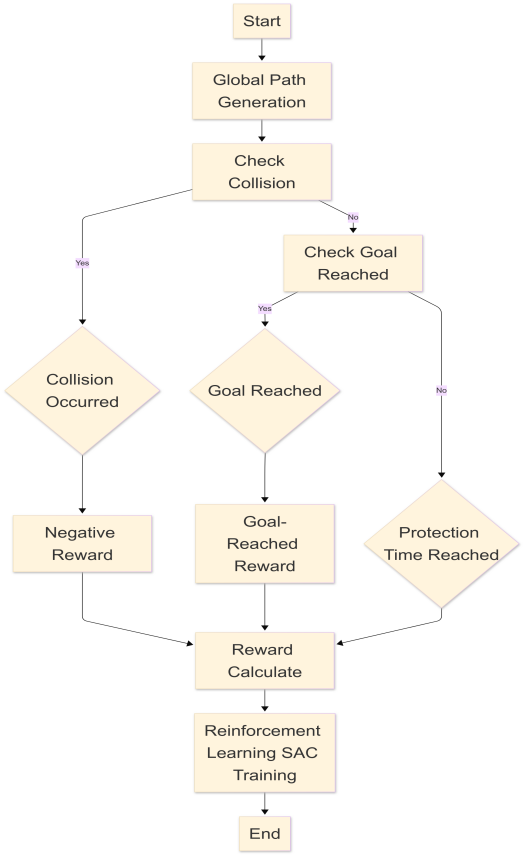
In automated factories, dynamic obstacle avoidance and trajectory planning of robotic manipulators are critical to achieving safe and efficient operations. However, traditional obstacle avoidance methods, such as the artificial potential field, element decomposition, viewable, Voronoi diagram, and probabilistic road map, face many challenges in dealing with complex dynamic environments, such as target unreachable and local minimum problems. A new dynamic obstacle avoidance and trajectory planning framework based on the Soft Actor-Critic (SAC) algorithm is proposed in this paper to address these problems. The framework combines the fast-scaling random tree (RRT) algorithm for global path planning and the SAC algorithm to optimize the local path to adapt to the changes in the dynamic environment. Specifically, the simulation uses Python to construct a URDF (Unified Robot Description Format) model of an open-source robot arm. It applies the SAC algorithm to the model's dynamic obstacle avoidance trajectory planning. The simulation results show that the proposed framework combining RRT and SAC algorithms achieved a high success rate in reaching the target point. This method can effectively find the right trajectory in a complex dynamic environment.
Policy gradient (PG) methods are a fundamental component of deep reinforcement learning (DRL), particularly effective in continuous and high-dimensional control tasks. This paper presents a structured review of PG algorithms, tracing their development from basic Monte Carlo methods like REINFORCE to advanced techniques such as asynchronous advantage actor-critic (A3C), trust region policy optimization (TRPO), proximal policy optimization (PPO), deep deterministic policy gradient (DDPG), and soft actor-critic (SAC). These methods differ in terms of policy structure, optimization stability, and sample efficiency, addressing core challenges in policy learning through gradient-based updates. In addition, this review explores the application of PG methods in real-world domains, including autonomous driving, financial portfolio management, and smart grid energy systems. These applications demonstrate PG methods’ capacity to operate under uncertainty and adapt to complex dynamic environments. However, limitations such as high variance, low sample efficiency, and instability in multi-agent and offline settings remain significant obstacles. The review concludes by outlining emerging research directions, including entropy-based exploration, model-based policy optimization, meta-learning, and Transformer-based sequence modeling. This work aims to offer theoretical insights and practical guidance to support the continued advancement and application of policy gradient methods in reinforcement learning.
With the rapid development of global e-commerce and online payments, the number and complexity of fraudulent transactions have increased significantly, bringing serious economic losses and a crisis of trust to financial institutions and consumers. This paper systematically reviews the characteristics, detection methods and research progress of fraudulent transactions. Firstly, the characteristics of fraudulent transactions are analyzed from the aspects of time, place, transaction mode and technical means. Secondly, the advantages and disadvantages of traditional detection methods (such as rule-based and statistical analysis) and emerging technologies (such as machine learning and deep learning) and their application effects are reviewed. Finally, the limitations of current research in data imbalance, model complexity and multi-type fraud detection are discussed, and future research directions are proposed, including data enhancement techniques, integrated learning frameworks and privacy protection strategies. The research of this paper aims to provide theoretical support and practical guidance for the academic and industrial circles, and promote the further development of the financial security field.
In recent years, with the rapid development of intelligent transportation, Reinforcement Learning (RL), as an adaptive decision-making method, has gradually permeated into various levels of Autonomous Driving (AD). Therefore, this paper reviews the latest advances in the application of RL in AD. In terms of high-level decision-making and behavioral planning, RL, combined with visual-language models, imitation learning, multi-stage training, and autoregressive trajectory planning, systematically improves planning accuracy and task success rates. At the motion control level, the synergistic optimization of deep reinforcement learning (DRL) based continuous control strategies and robust control methods enhances performance in path tracking, dynamic obstacle avoidance, and multi-sensor information fusion. Meanwhile, end-to-end autonomous driving leverages novel frameworks such as closed-loop RL, World Model (WM), and multimodal decision fusion, effectively narrowing the gap between simulation and real-world environments while achieving significant improvements in safety and smoothness. Additionally, the paper discusses the limitations of RL applications, including data dependency, training efficiency, safety, and interpretability. Furthermore, it explores the future prospects for achieving more intelligent autonomous driving systems through strategies such as meta-learning, transfer learning, adversarial training, and human-machine collaboration.
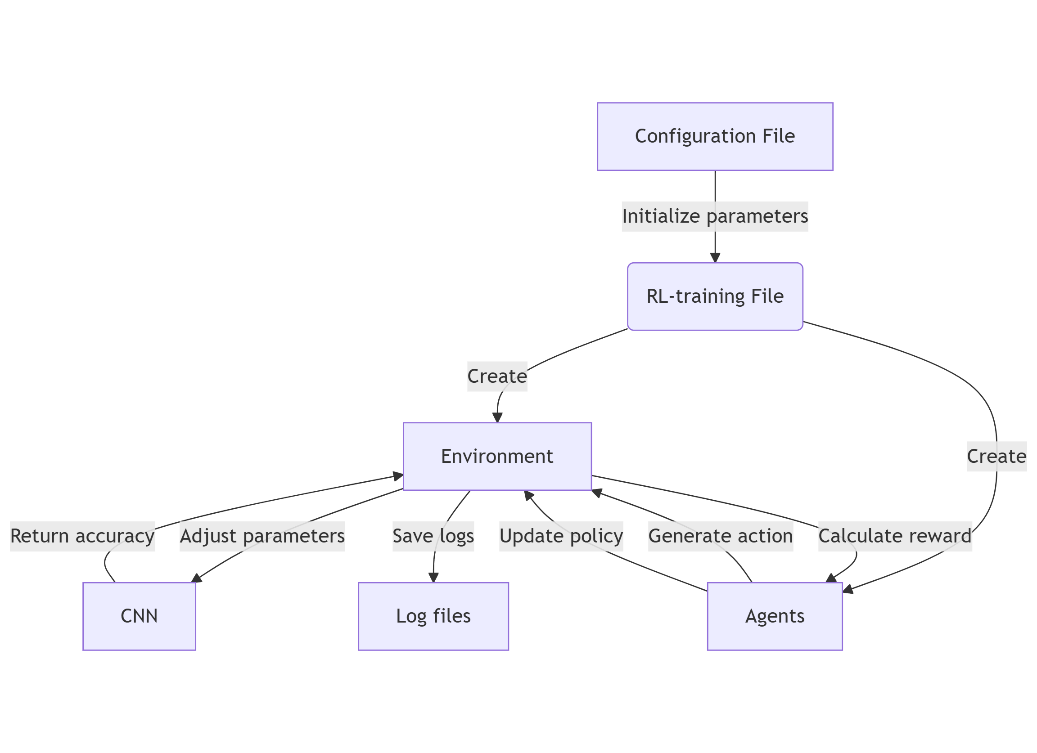
Emotion, as a unique attribute of human beings, is an important research direction of human-computer interaction by using the developed artificial intelligence technology. Although the existing research has reached a high accuracy, the efficiency problem has not been completely solved. Aiming at the time-consuming and labor-consuming problem of hyperparameter optimization in traditional deep learning, this paper proposes an automatic parameter adjustment method combining reinforcement learning (RL) and revolutionary neural network (CNN). Based on the DEAP data set, a lightweight 2d-cnn model is constructed by using the temporal and spatial characteristics of EEG signals, and the super parameters such as dropout probability and batch size are dynamically optimized by using the proximal strategy optimization (PPO) and deep deterministic strategy gradient (DDPG) algorithms, respectively. Experiments show that the reinforcement learning driven parameter adjustment method significantly improves the performance of the model: PPO and DDPG respectively improve the accuracy of CNN from 69% to 71%, and DDPG achieves the optimal results in fewer training rounds. In addition, the parameter trajectory analysis shows that agents tend to increase the batch size and reduce the dropout probability to balance the risk of feature retention and overfitting. This study verifies the potential of reinforcement learning in hyperparameter optimization, and provides a new idea for automated optimization of complex models. Future work will be extended to higher dimensional parameter space and multimodal data fusion scenarios.
Recent advances in artificial intelligence technologies have begun to transform the gaming industry, especially in the areas of player-character interaction and narrative development. Traditionally, game stories and character relationships are predefined through scripted dialogues and sequences, which requires developers to invest a lot of time and effort. However, AI-driven approaches such as large language models (LLMs) and deep learning techniques offer a dynamic alternative that can enable more flexible, player-driven interactions and adaptive AI behaviors. This paper comprehensively reviews the current role of AI in game design from multiple perspectives, including applications in multi-agent interaction, procedural level and game content generation, and game development process optimization. In addition, this study explores the advantages and limitations of AI technology, coping with technical challenges, and ethical issues that may arise during the implementation of AI. The results are intended to provide a reference for the future application of AI in game design and provide recommendations for coping with emerging risks.
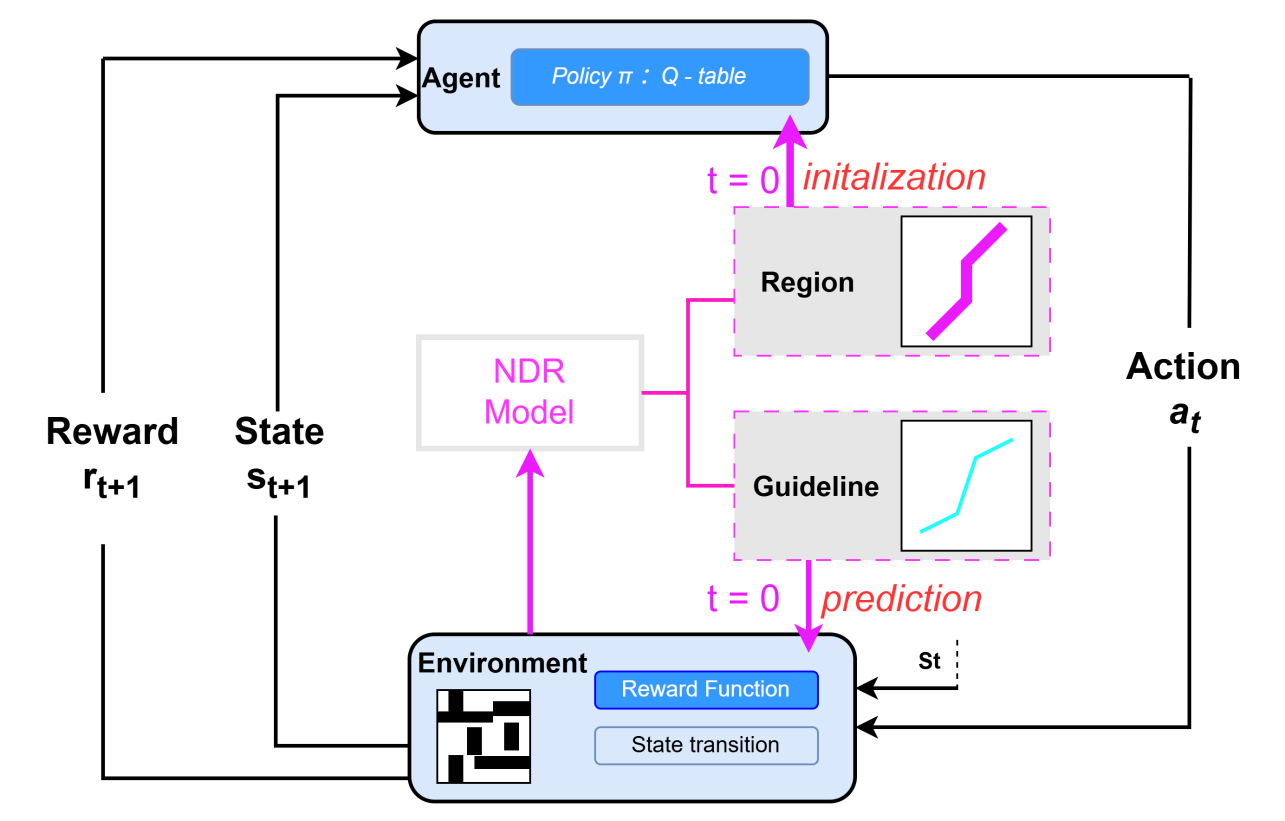
Reinforcement Learning (RL), as an essential branch of machine learning, has garnered significant attention due to its outstanding performance in complex decision-making tasks and dynamic environments, exemplified by notable achievements such as AlphaGo and DeepSeek in recent years. To provide researchers with a comprehensive perspective of current developments in this area, this paper systematically reviews RL from four distinct perspectives: fundamental theoretical frameworks, practical applications, existing limitations, and future outlook. Initially, core concepts and classical algorithms including Q-learning, SARSA, and Temporal Difference (TD) learning are clearly introduced, establishing a solid theoretical foundation. Then, practical implementations of RL are elaborated within three representative fields: path planning, voltage control and game theory, highlighting their significance and effectiveness through literature analysis. Moreover, this paper critically analyzes the limitations of current RL techniques, such as low sample efficiency, unstable training processes, and insufficient generalization. Finally, potential research directions, including hybrid learning paradigms and multi-agent collaborations, are proposed to inspire future advancements. The insights provided in this review aim to stimulate further theoretical innovation and practical breakthroughs in reinforcement learning.
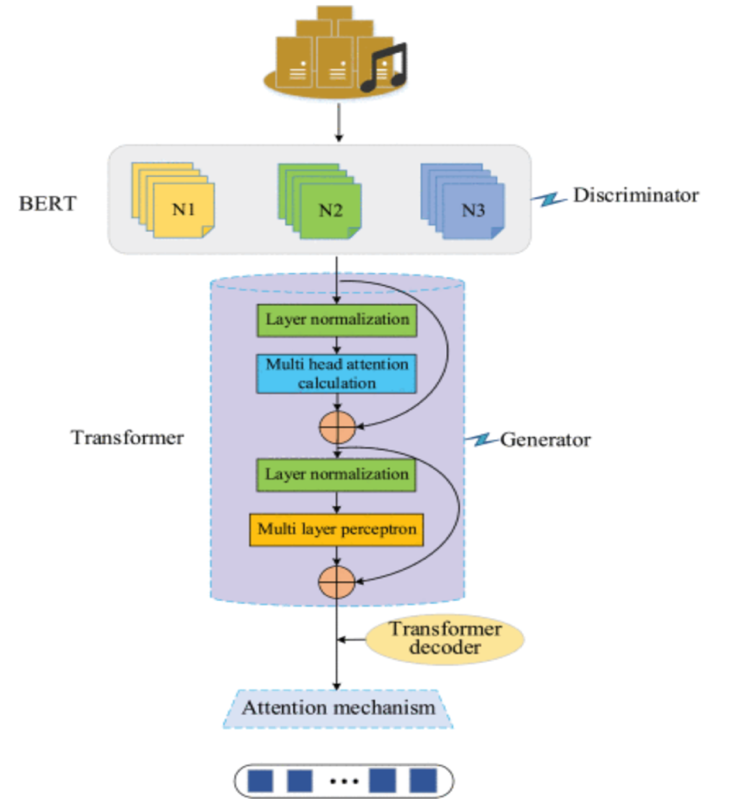
As a matter of fact, AI techniques has witnessed tremendous rapid development especially among recent years with the boosting of the GPU ability. Among various application fields, AI-assisting music composition has become widely investigated contemporarily. Amidst the burgeoning technological landscape, AI has penetrated music composition in various fields. With this in mind, this paper delves into the state-of-art AI scenarios for music creation with various situations. To be specific, it covers revealing AI models' capacity to generate diverse pieces but also their struggles in emulating human-like emotional depth. According to the analysis, the realization principles for different models, applications in different situations as well as limitations and prospects are demonstrated and evaluated. Overall, these results shed light on guiding further exploration of AI composing music. At the same time, this study offers new tools and paves the way for future research of music composition based on the state-of-art AI models in this evolving field.